AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
サンフランシスコ2日目、朝6時台の雨・風共に強い中を10kmほど走ってきました。 現地のランナーと思わしき方とも何度もすれ違ったので、これが本場のやり方、これこそがシリコンバレー、いや、ベイエリアと思いました。 そして、私の心もすっかりベイエリア・ランニングおじさん、高柳です。
現在、私はサンフランシスコで開催中の Association for the Advancement of Artificial Intelligence (AAAI) に参加しており、この記事はその2日目の参加記録になります。 1日目の記録はこちらです。
この参加報告では、現地から毎日、リアルタイムに、私が参加したセッションの様子を報告していきます!
AAAI-17 Invited Talk
ケンブリッジ大学のSteve Young教授による講演です。 ”対話システム”についての簡単なイントロダクションからはじまり、 流行りの深層学習系(CNN、LSTM)を活用したそのアーキテクチャの解説、及びその学習法(強化学習ベース)の講演ありました。
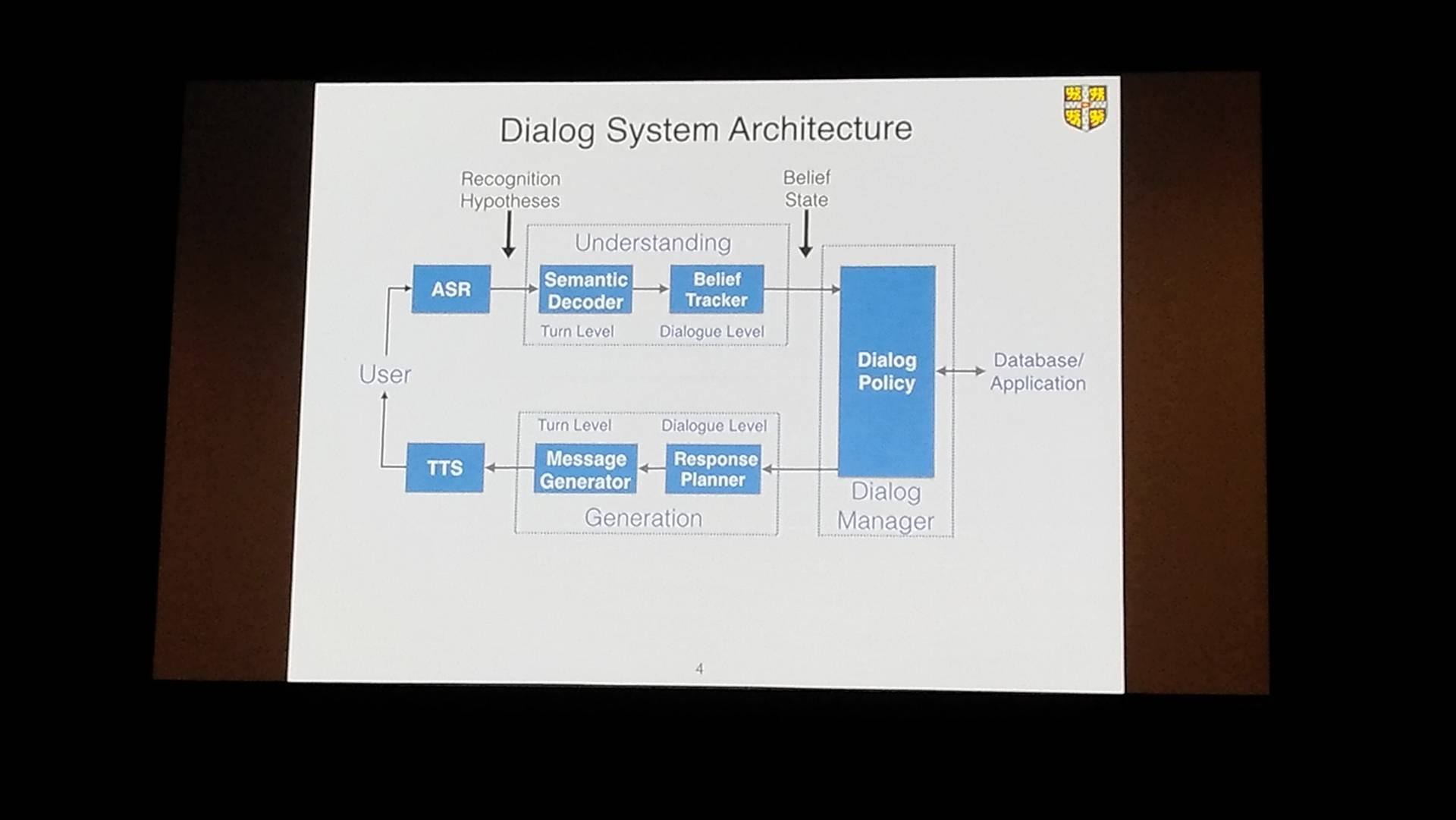

図:CNNを活用した語彙的特徴量の抽出
説明自体は非常に丁寧で、これだけ丁寧だと門外漢でもわかりやすいんだろうなと思いましたが、 英語という言語の壁と、私のNLP周りの知識が 「形態素解析してBag of Wordsから特徴量作れば大体なんとかなるんじゃないか?」 というレベルなので、詳しくは聞かないでください…
ML8: Feature Construction / Reformulation
パッと見のセッションタイトルだけ見て「特徴量づくりの実務的な話か?」と思っていたのですが、結構ガチでした。。。 話されていた内容としては、 シフト不変なカーネル(カーネル関数K(x, y)が g(x-y)と2つのベクトルの差だけで書ける)を仮定し、 高次元に値を持つ手元のデータを、ランダムに生成される低次元特徴量表現に直すRandom Featuresという手法を活用、 そこに更に(統計量の)モーメントマッチングを加えた新アルゴリズムの話や、 周波数空間でRubust主成分分析を行うことで、他の手法よりも精度よく画像からノイズを除去できるアルゴリズムが講演されていました。
ここで言うFeature Constructionというのは、機械学習エンジニアが言う”特徴量作り”ではなく、低次元表現や周波数空間での特徴量の生成(construction)と意味だろうと思われます。 うっかりうっかり。
ML11: Bayesian Learning
ロボットや人間の腕の動きは(直感的に考えて)(超)球面や(超)トーラス上に分布するので、 多変量に拡張・一般化されたvon Mises分布(円周上で定義された確率分布で、確率変数を角度の関数として表す分布モデルに使われるそうです。知りませんでした)に対して変分推定を使うことで、この動きを推定できるようなアルゴリズムを開発した話や、 欠損のあるデータ、特にその欠損がランダムでない(Missing Not At Random、MNAR)時でもうまくいく、ベイジアンネットワークをうまく動作させる学習アルゴリズムを開発したトークがありました。
欠損データの扱いについては私も不勉強なので、星野先生の「調査観察データの統計科学」あたりを再読しようかなという気になりました。
ML14: Clustering
同時刻の別セッション「ML13: Dimensionality Reduction / Feature Selection」のどちらに出ようかと相当迷ったのですが、 向こうには幾人かの同僚・知人らが行ってくれるということで、こちらをチョイス。 局所的なセントロイド(重心)を1つのクラスタに複数割り当てることで、既存の手法(Graph Regularized NMF(Cai et 2011))よりもより精度(Accuracy、Normalized Mutual Informationで測定)良く分類できるアルゴリズムの提案や、 “Multiple Kernel K-means (MKKM)“法を拡張し、より表現力を高めた手法である”Optimal Neighborhood Kernel Clustering(ONKC)”の提案や 異なるクラスタ結果比較の新たな評価指標として”Clustering Agreement Index(CAI)”を提唱するなどの発表がありました。 「提唱されたアルゴリズムでは大域解が保証されていない。数理最適化として問題があるのではないか?定式化として根本的に解いている問題に間違いがあるのではないか?」 などなど質疑応答も活発でした。
個人的には局所的なセントロイドを活用したNMFの研究が気になるので、後で追いかける予定です。
ML17: Classification and Clustering
今日はもうクラスタリング祭にしようと、またクラスタリング系のセッションへ潜り込みました。 非対称(Asymmetric)なロス関数を使って行列分解することで、スキューのある(歪んでいる)データに対しても有効な行列分解アルゴリズムの提案や、 複数のクラスタリング手法を同じデータセットに適用、それをアンサンブル学習的に結合させる際に、 効用関数とco−association行列の線形結合を目的関数にクラスタリングを統合するというクラスタリング手法の提案、 また適当なロス関数(キャップ付きLpノルム)を用いたよりロバストなSVM手法の提案など、実際に業務に使えそうなネタが盛り沢山でした。
特に、アンサンブル・クラスタリングは面白そうなので、ここを掘っていこうと思います。
AAAI-17 Invited Talk
ロンドン大学のPeter Dayan教授による講演です。 概要としては”人工知能の文脈でいう強化学習と、脳内のニューロンが物を覚える仕組みが強化学習に似ている”という話です。 この辺の類似性を例題を交えて紹介すると共に、問題設定・推定手法・環境の3つ全てが揃っていないと、 実験環境としては不適切であり正しい観察ができないなど、実証研究の在り方についても言及されていました。


図:鳩が光の点をつつくと餌が出てくるというのを学習するまでのプロセスを動画で紹介
速報につき、内容の詳細が間違っていたら是非ご指摘ください。
・・・参加2日目の現場からは以上です。
参加3日目の記事はコチラ。
ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)