

[データ組織]
【対談連載 第四回】「名を残す研究」の世界を飛び出し、新卒5年でシニアプロフェッショナルに。技術とビジネスを繋ぐ、機械学習エンジニアの『並走』する覚悟
Jul 29, 2026

[データ組織]
【対談連載 第三回】「なんでやるんですか?」と問う新人が役員に。徹底的な納得から始める「機会損失のない社会」への挑戦
Jul 15, 2026

[学会レポート]
JSAI2026参加報告
Jun 30, 2026

[データ組織 新人研修 25卒新人研修]
【25卒新人研修】全社検索研修
Jun 29, 2026

[データ組織]
【イベントレポート】リクルート流データ基盤塾 第3弾 ~鶴谷と学ぶ、開発現場におけるAI活用のリアル~
Jun 2, 2026

[データ組織]
【対談連載 第二回】“意味のないロジック”を勇気を持って手放す。カオスをパズルとして楽しむエンジニアが見つけた、技術で事業を動かす真の当事者意識
May 19, 2026

[データ組織]
和田卓人氏と語る、"開発現場"の未来予測 (RECRUIT TECH CONFERENCE 2026開催レポート)
Apr 28, 2026

[データ組織]
【初開催!】産学連携技術交流会レポート
Apr 10, 2026
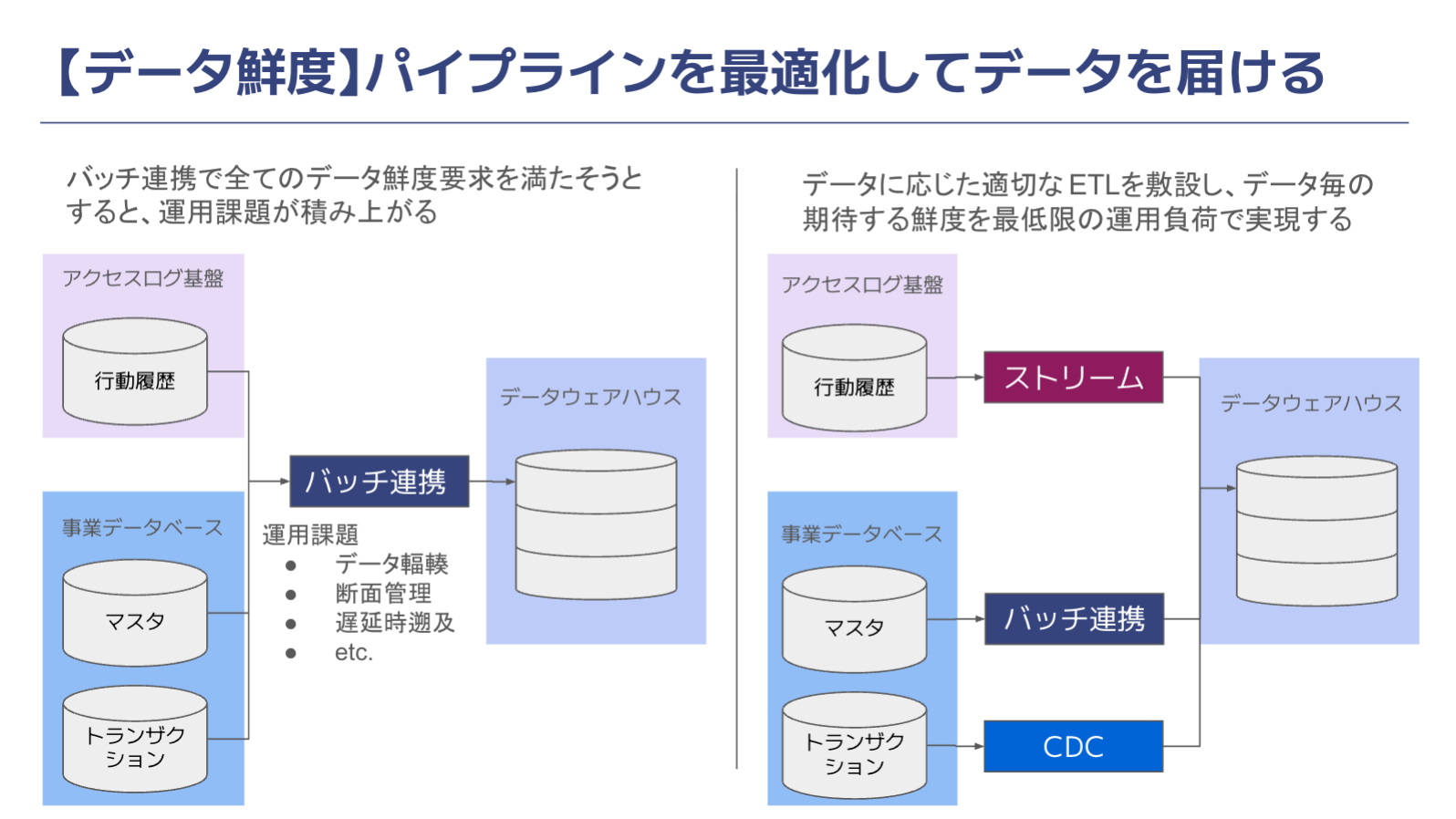
[データ組織]
レバレッジを生み出すデータ戦略:AI活用とSaaS事業を支えるアナリティクスエンジニアリング(RECRUIT TECH CONFERENCE 2026開催レポート)
Apr 9, 2026

[データ組織]
Kaggleで鍛えたスキルの実務での活かし方 競技とプロダクト開発のリアル(RECRUIT TECH CONFERENCE 2026開催レポート)
Apr 8, 2026

[データ組織]
「商いの面白さ」をデータで解き明かす。データ推進室 部長が語る、事業を伸ばすスペシャリストの在り方
Mar 30, 2026

[データ組織]
【対談連載 第一回】「結局、GPUをフル活用している時が一番楽しい」データ推進室長が紐解く、技術愛溢れるデータサイエンティストがリクルートに飽きない理由
Mar 27, 2026

[技術紹介]
Kaggleの火山コンペで12位、金メダルを獲得しました
Mar 25, 2026

[データ組織]
【イベントレポート】『ホットペッパーグルメ』を動かすデータマネジメント~アナリティクスエンジニアの挑戦と裏側~
Feb 19, 2026
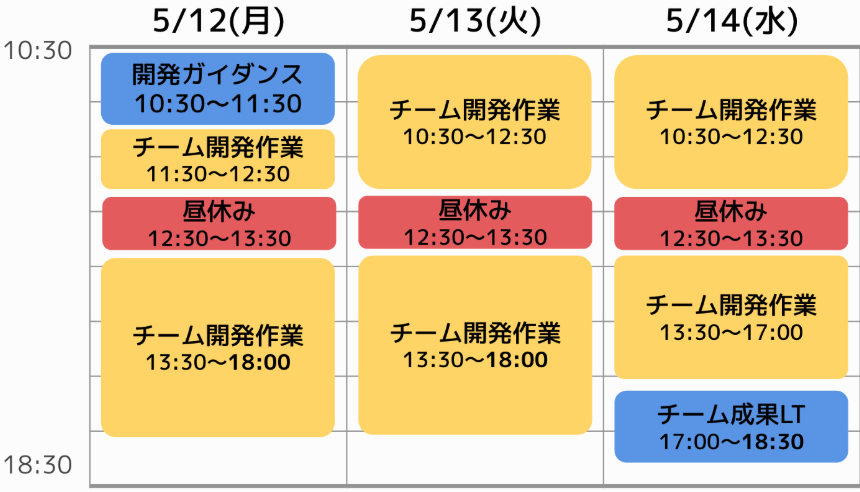
[データ組織 新人研修 25卒新人研修]
【25卒新人研修】DevOps-hands-on dev編
Feb 4, 2026

[データ組織]
社内外の垣根を超えた 初の「Data Meetup Party」開催レポート
Jan 26, 2026

[データ組織]
「ロボットに捧げた青春」を経て、データ組織の部長へ。未踏スーパークリエータが語る、技術者がビジネスを牽引する“必然”
Jan 23, 2026

[データ組織 新人研修 25卒新人研修]
【25卒新人研修】DevOps研修 Ops編
Jan 16, 2026

[データ組織]
データ推進室 アドベントカレンダー2025 振り返り
Dec 25, 2025

[事例紹介]
Google Cloud Modern Infra & App Summit '25 Fall にて、データアプリケーション開発プラットフォーム Knile の FinOps 実践について発表しました
Dec 24, 2025