
[技術紹介]
Kaggleの火山コンペで12位、金メダルを獲得しました
Mar 25, 2026

[技術紹介]
AIエージェントの公開仕様の現状のまとめとこれから
Dec 17, 2025

[技術紹介]
BigQueryから「ほどほどの」行数を効率的にダウンロードするPython実装について
Dec 15, 2025
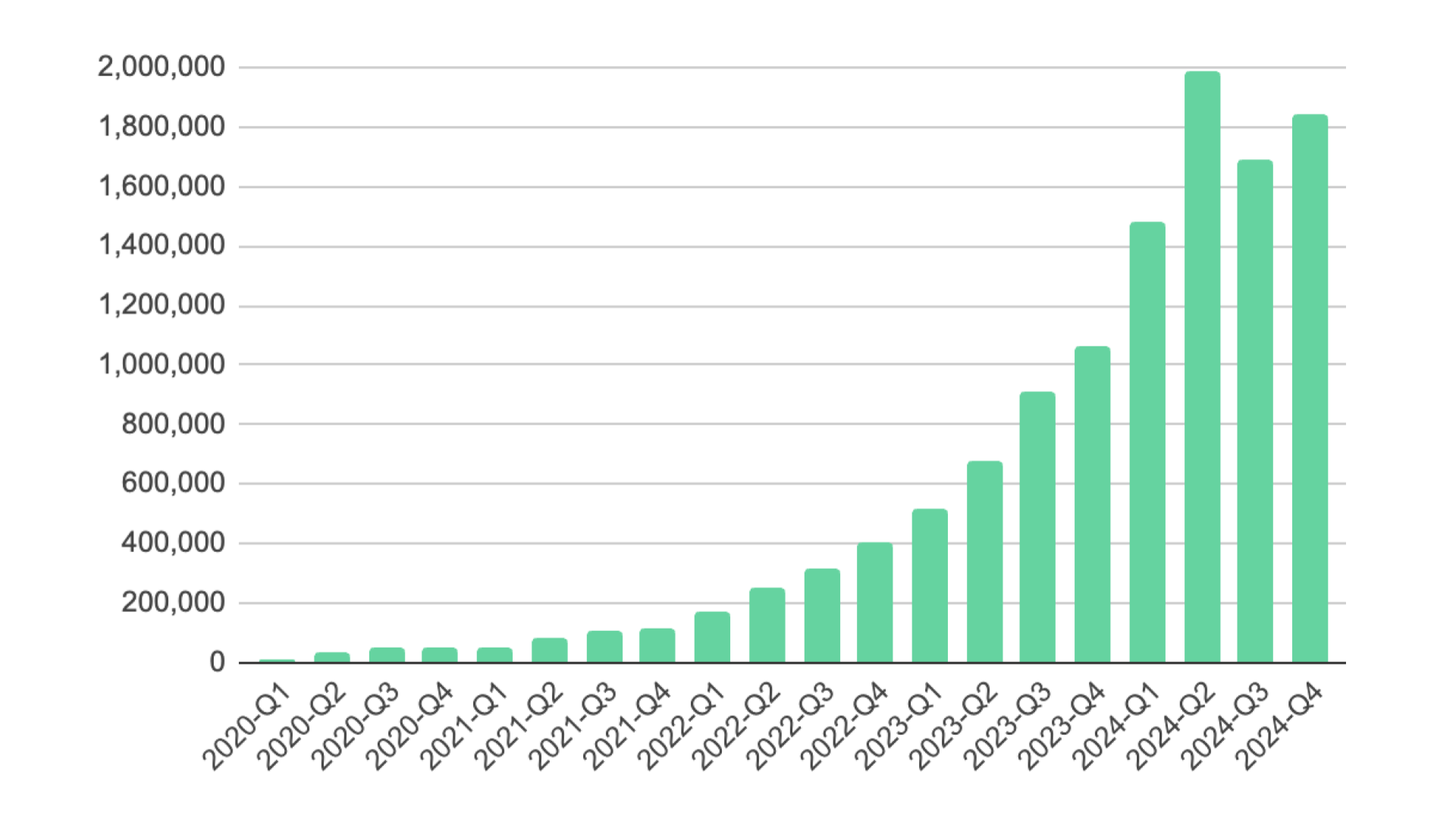
[技術紹介 事例紹介]
AIエージェントによるプロダクト運用の自動化 - 社内横断プロダクト Crois におけるAIOpsの実践
Dec 5, 2025

[技術紹介 事例紹介]
分散型と集中型の両輪アプローチで実現するクラウドコスト最適化:内製データ基盤CroisのFinOps実践事例
Aug 21, 2025
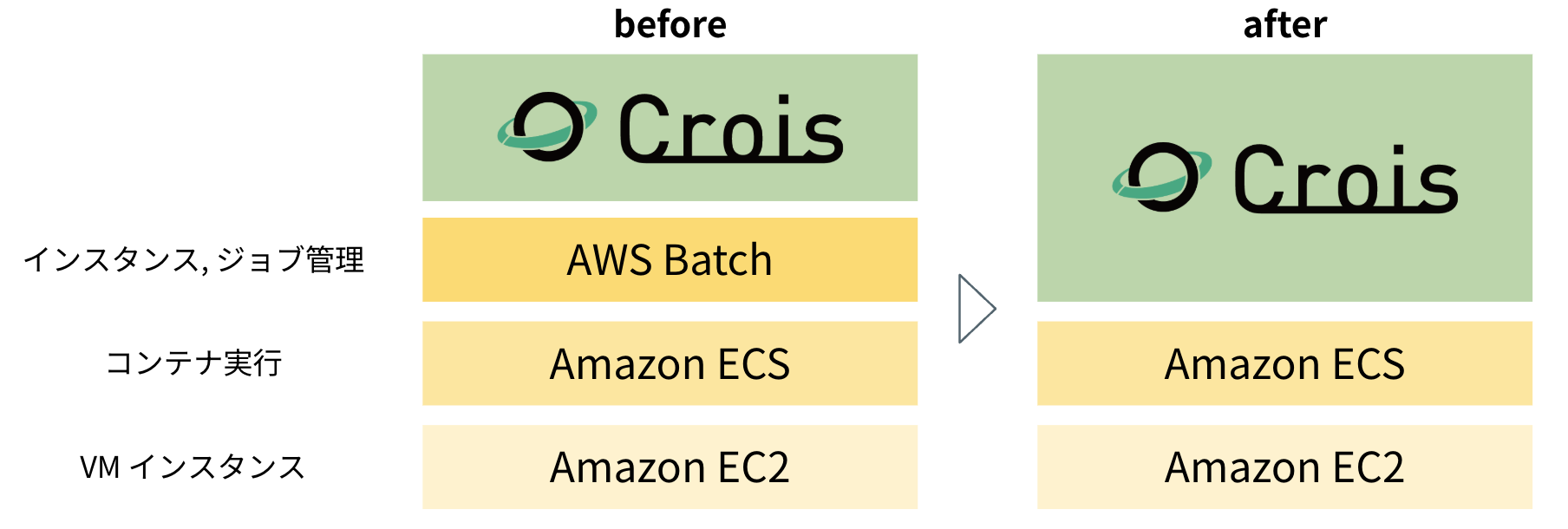
[技術紹介 事例紹介]
AWS Batch の制約を乗り越える - ECS on EC2 の直接制御による高速・柔軟なコンテナジョブ実行基盤の開発
Aug 20, 2025

[技術紹介]
実推薦モデルにおける有効なオフ方策評価手法の特定(半熟仮想株式会社との共同研究)
Apr 7, 2025
[技術紹介]
データモデリングでよく利用するBigQuery SQLのクエリパターン
Dec 24, 2024
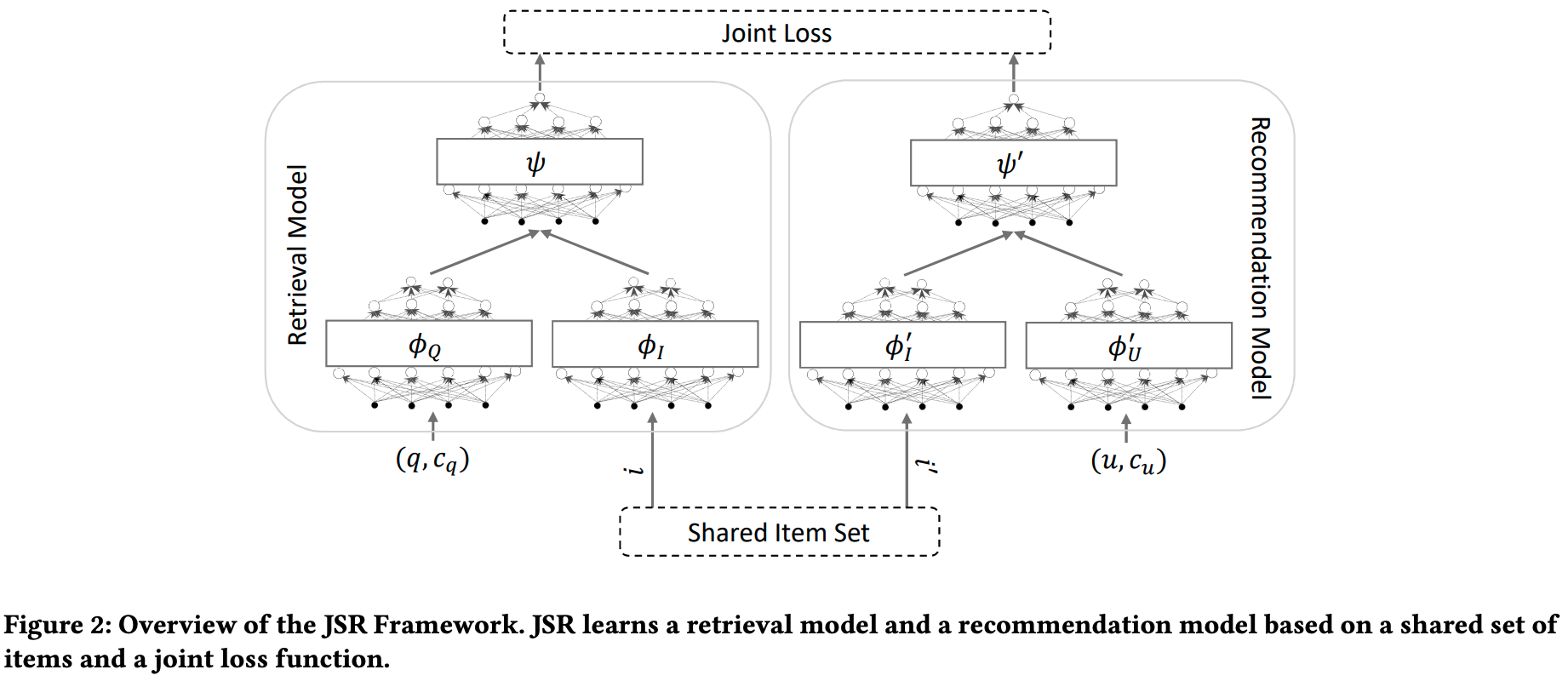
[技術紹介]
検索&推薦の統合モデルに関する研究動向
Dec 23, 2024
[技術紹介]
QCon SF 2024参加レポート
Dec 20, 2024

[技術紹介]
Microsoft Ignite 2024 in Chicago
Dec 19, 2024

[技術紹介]
最適化モデリング入門@新人研修
Dec 18, 2024

[技術紹介 事例紹介]
Tableau Server から Tableau Cloud への大規模お引越しプロジェクト
Dec 16, 2024
[技術紹介]
dbt coalesce 2024参加記
Dec 13, 2024

[技術紹介 事例紹介]
AWS Innovate にて内製データ基盤 Crois のプラットフォームエンジニアリングの取り組みを発表しました
Dec 11, 2024

[技術紹介]
KDD 2024 参加報告
Dec 2, 2024
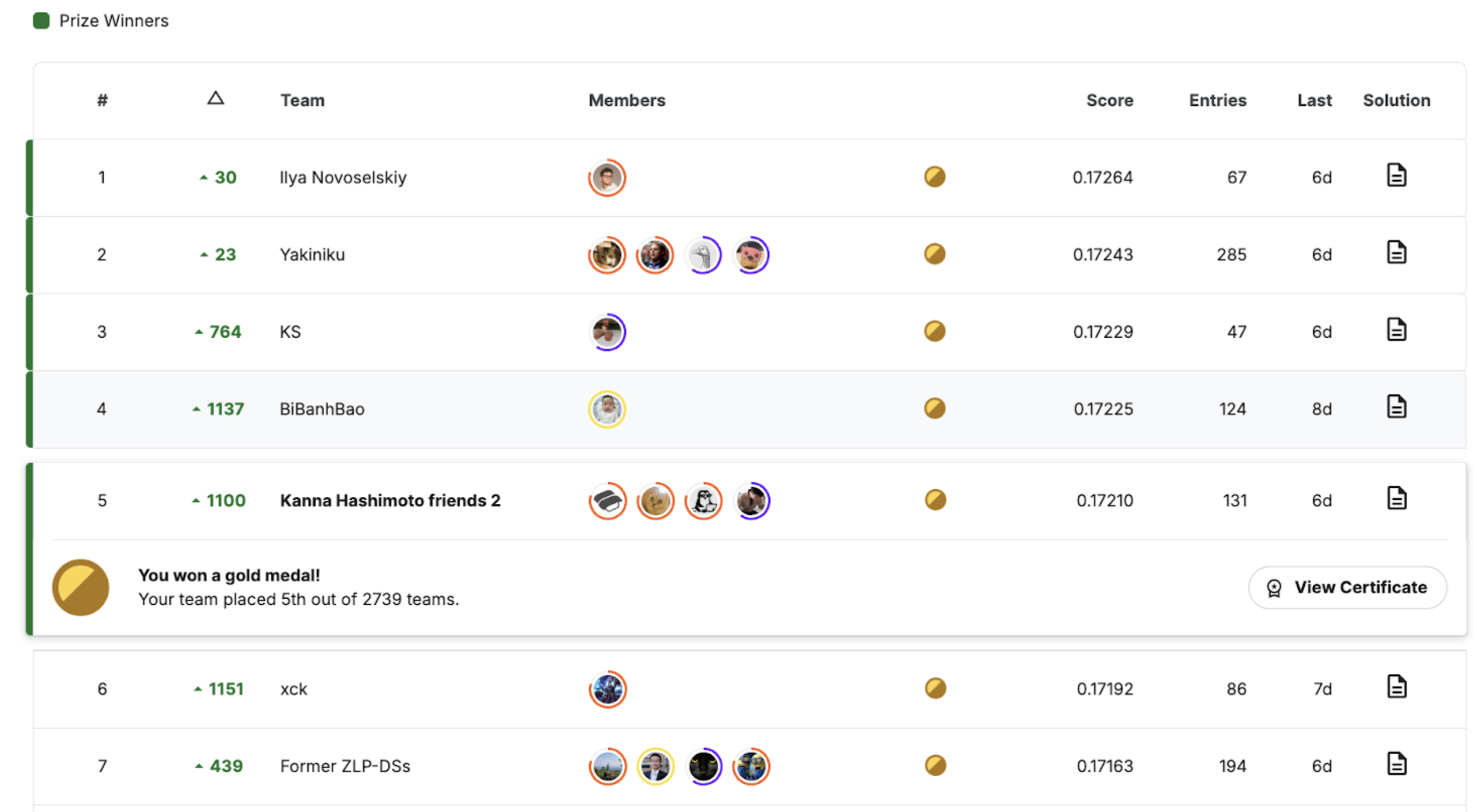
[技術紹介]
kaggleのISIC 2024で5位、金メダルと賞金1万ドルを獲得しました
Oct 2, 2024

[技術紹介]
KaggleのLLM 20 Questionsで金メダルを獲得しました
Sep 13, 2024

[技術紹介]
TerraformでSnowflakeからGCSへのデータ連携を実現
Sep 4, 2024
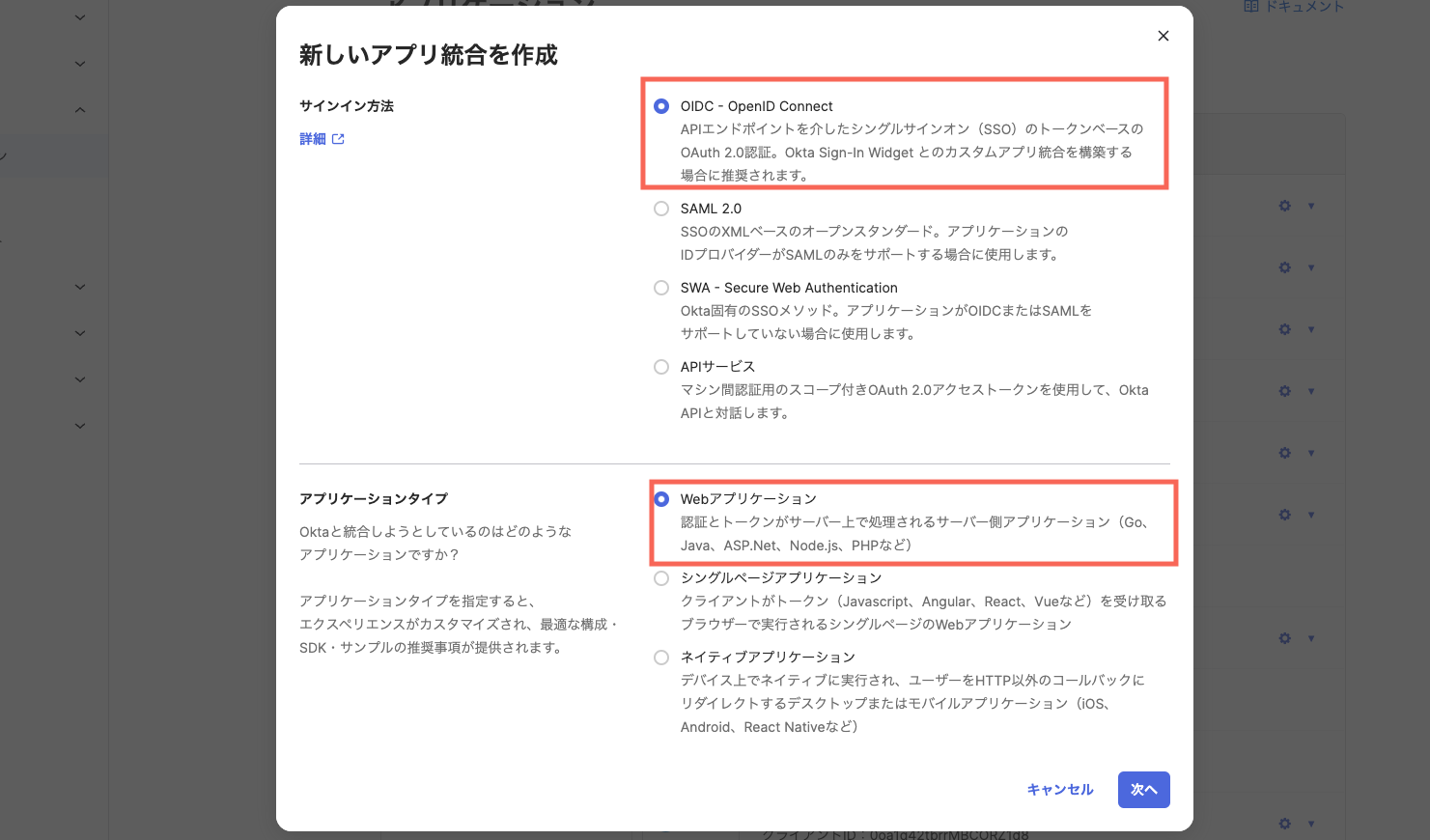
[技術紹介 事例紹介]
Oktaを利用した認証認可の統合について
Aug 21, 2024