
はじめに
基盤モデル がAIの新潮流となりました。基盤モデルというとやはり大規模言語モデルが人気ですが、リクルートでは、画像を扱えるモデルの開発にも注力しています。画像を扱える基盤モデルの中でも代表的なモデルのCLIPは実務や研究のさまざまな場面で利用されています。CLIPの中には日本語に対応したものも既に公開されていますが、その性能には向上の余地がある可能性があると私たちは考え、仮説検証を行ってきました。今回はその検証の過程で作成したモデルと評価用データセットの公開をしたいと思います。
公開はHugging Face上で行っていますが、それに合わせて本記事では公開されるモデルやデータセットの詳細や、公開用モデルの学習の工夫などについて紹介します。 本記事の前半では、今回公開するモデルの性能や評価用データセットの内訳、学習の設定について紹介します。記事の後半では大規模な学習を効率的に実施するための技術的な工夫について紹介します。
公開するリソースは以下です。
背景
日本語に対応しているCLIPの公開モデルは、2024年1月時点で rinna/japanese-clip-vit-b-16 と laion/CLIP-ViT-B-32-xlm-roberta-base-laion5B-s13B-b90k 、 laion/CLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90k 、そして stabilityai/japanese-stable-clip-vit-l-16 の四つが主だったものかと思います。一つ目のrinnaのモデルは CC12M を和訳したもので学習が行われており、訓練データは1200万件と少ないため十分に訓練されていない可能性があります。四つ目のstability.aiが作成したモデルもCC12MとSTAIR Captionsで学習されたものであり、学習サンプル数は比較的少ないため十分に訓練されていない可能性があります。LAIONの二つは LAION-5B で学習されているため訓練データは50億件ですが、多言語で学習をされており、日本語に特化させたモデルを作成すれば日本語が関わるタスクにおいてはこれを上回る性能を達成できる可能性があると私たちは考えました。これには、限られたモデルのキャパシティを日本語に集中させる狙いがあります。
私たちは以下のような問いを立て、それを検証するべくCLIPをLAION-2Bの日本語サブセット1億2000万件で学習させました。
- 問い: 日本語データの含有量が同じとき、多言語での訓練と日本語単独での訓練では、どちらが日本語タスクでの性能が高くなるか?
- 検証方法: モデルサイズが同じ
laion/CLIP-ViT-B-32-xlm-roberta-base-laion5B-s13B-b90kと各種タスクでの性能を比較する。 - 予想していた答え: 上述の通り限られたモデルのキャパシティを日本語に集中させることで日本語単独の方が良くなる。
- 検証方法: モデルサイズが同じ
- 問い: 視覚・言語型基盤モデルの日本語タスクでの性能を比較するとき、ImageNetを和訳した分類タスクは適切な代表タスクなのか?
- 検証方法: 各モデルの性能をImageNetで評価したスコアの列と、ImageNet以外の日本語タスクで評価した列との間で順位相関係数を取る。
- 予想していた答え: 必ずしも適切ではない。ImageNet-1kには日本のコンテキストにおいて一般的ではないカテゴリが多数存在する(例: “schipperke”(犬種)、“buckeye”(トチの実))一方で、日本のコンテキストにおいて一般的なカテゴリ(例: 寿司ネタの種類、髪型の種類)は含まれていないことから日本語タスクでの性能評価には適さないケースがあると考えられる。
学習の設定
日本語に特化させたモデルの作成を行うにあたり、問題設定が近く、予算内で実行可能で、かつ性能と再現性が高そうな OpenCLIPの多言語版 と イタリア語CLIP の事例を参考に方針を策定しました。
モデルの初期値として、画像エンコーダは laion/CLIP-ViT-B32-laion2B-s34B-b79k を、テキストエンコーダは rinna/japanese-roberta-base を使うことにしました。
両エンコーダの出力の次元数を揃えるため、テキストエンコーダの最後に線形層を追加しました。この状態で最初からモデル全体を訓練すると、勾配が不安定になり学習済みモデル部分の重みが損なわれてしまうおそれがあるため、最初しばらくはテキストエンコーダの最後の線形層のみを一定の学習率で訓練しました。これはLP-FT(linear probing then fine-tuning)と呼ばれるテクニックで、CLIPのファインチューニングでしばしば用いられます [1]。
ハイパーパラメータは、『 Deep Learning Tuning Playbook 』を参考に、以下の手順で決めました。まず、CUDA OOM(out of memory)が発生しない限界のバッチサイズを探索し、それを固定しました。今回はNVIDIA A100 40GBのGPUを8枚使用し、混合精度で計算したところ、グローバルなバッチサイズが4352となりました。次に、予算制約と1ステップあたりの時間から、訓練ステップ数を44万としました。最後に、学習が安定するようなAdamの基本学習率を探索し、2e-5としました。学習率のスケジューリングには、線形ウォームアップとコサイン減衰を組み合わせて用いました。
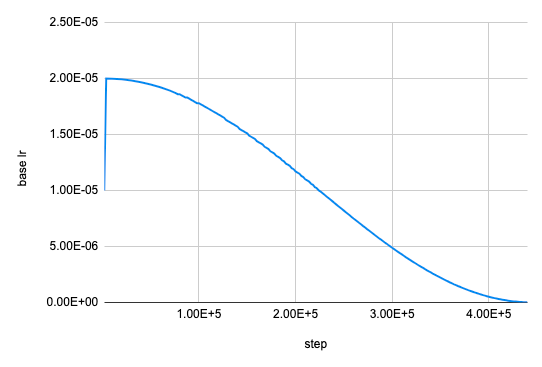
評価用のデータセットについて
日本語に特化したモデルの評価を行うにあたって、私たちは、より日本のコンテキストに適したデータセットを用いることが必要であると考えました。しかし、日本のコンテキストにおいて一般的なカテゴリを含む画像分類のデータセットは極めて少ないことがわかったため、私たちは評価用のデータセットを作成することにしました。
データセットは、 Flickr に公開されている画像を収集して作成をしました。Flickrは API を用いて画像の検索や情報取得ができるようになっており、Pythonのサードパーティ製の ラッパーライブラリ も公開されています。このライブラリを使えば次のようにして、指定の検索キーワードで指定したライセンスで公開されている画像のリストを取得することができます。
import os
from flickrapi import FlickrAPI
# Flickr APIのキーとシークレット
# https://www.flickr.com/services/api/keys/ から取得ができる
API_KEY = os.getenv("API_KEY")
API_SECRET = os.getenv("API_SECRET")
flickr = FlickrAPI(API_KEY, API_SECRET, format="parsed-json")
query = "四川料理"
# API document: https://www.flickr.com/services/api/flickr.photos.search.html
# licenseは https://www.flickr.com/services/api/flickr.photos.licenses.getInfo.html にIDとライセンスの対応が書いてある
result = flickr.photos.search(
text=query,
per_page=100,
media="photos",
sort="relevance",
extras="url_c",
safe_search=1,
license="4",
)
私たちは、このAPIを用いて日本の料理・食材101種、日本の花30種、日本の施設20種、日本のランドマーク10種の画像を取得した上で目視でクエリ内容と一致しない画像を省いた上でそれぞれを「jafood101」「jaflower30」「jafacility20」「jalandmark10」というデータセットとしてまとめました。これらのデータセットも今回公開するリソースに含まれています。
実験結果
それでは、 学習の設定 のセクションで述べた設定で行った実験の結果を見てみましょう。まず、訓練曲線を下図に示します。
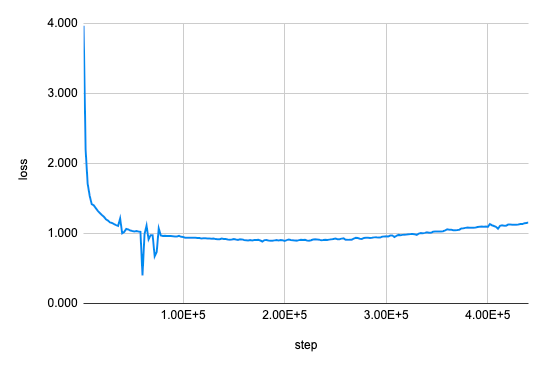
途中までは訓練誤差が順調に低下しましたが、20万ステップを過ぎたあたりから反転して上昇し始めました。学習が失敗したのではないかと疑いましたが、後で下流タスクでの精度を評価してみると、この間も精度が向上し続けていました。このことから、学習がうまく進んでいることが示唆されます。
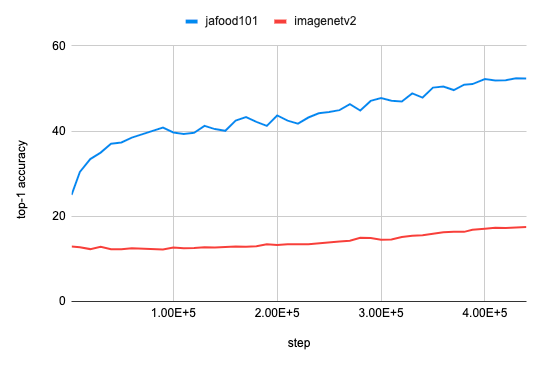
また、訓練序盤においてImageNetV2でのTop-1正解率が全く上がらなかったため、これについても失敗を疑いました。しかし、10万ステップを過ぎたあたりからスコアが急に上昇し始めました。
これらの挙動は、 OpenCLIPの訓練時のメトリクスの推移 と大きく異なっています。具体的にどの要因がこれらの違いを引き起こしたのか、その特定は難しいですが、この点についての皆様のご意見をお待ちしています。
先述の通り、ImageNetには日本のコンテキストでは一般的ではないカテゴリが多数存在する一方で、日本のコンテキストで一般的なカテゴリが含まれないため、日本語タスクにおける性能を適切に評価するためには、ImageNetのみでの評価は好ましくありません。そこで私たちは、英語圏のデータセットを日本語訳したものに加え、日本語圏のデータセットも収集・作成し、それらを用いて評価を行いました。
英語圏のデータセットを日本語訳したものとしては、
- ImageNet V2 の評価データ
- Food-101 の評価データ
を用いています。この二つのデータセットを用いて、既存の日本語CLIPモデルと私たちがファインチューニングしたものの間でゼロショット画像分類のAccuracyを比較した物が以下になります。
| imagenetv2(和訳) | food101(和訳) | |
|---|---|---|
| laion/ViT-H-14 | 0.471 | 0.742 |
| laion/ViT-B-32 | 0.326 | 0.508 |
| rinna/ViT-B-16 | 0.435 | 0.491 |
| stabilityai/ViT-L-16 | 0.481 | 0.460 |
| recruit/ViT-B-32 | 0.175 | 0.301 |
また、日本語圏のデータセットとしては、
- ETL文字データベース の手書きひらがな、カタカナ分類のデータセット
- STAIR Captions
- Flickrから収集した日本の食材・料理101種のデータセット『jafood101』
- Flickrから収集した日本のランドマーク10種のデータセット『jalandmark10』
- Flickrから収集した日本の花30種のデータセット『jaflower30』
- Flickrから収集した日本の施設20種のデータセット『jafacility20』
を用いて評価を行っています。なお、今回公開する評価用データセットは私たちがFlickrから画像を収集しアノテーションした後ろ四つのデータセットです。STAIR Captions以外のデータセットではゼロショット画像分類のAccuracyで評価を行い、STAIR Captionsでは Duet にならい、「テキストからの画像検索」「画像からのテキスト検索」のタスクを解いたときのprecision@1,5,10の平均値で評価を行いました。
| hiragana | katakana | sc-it | sc-ti | landmark | facility | flower | food | |
|---|---|---|---|---|---|---|---|---|
| laion/ViT-H-14 | 0.055 | 0.029 | 0.462 | 0.223 | 0.899 | 0.820 | 0.869 | 0.709 |
| laion/ViT-B-32 | 0.162 | 0.061 | 0.372 | 0.169 | 0.846 | 0.749 | 0.709 | 0.609 |
| rinna/ViT-B-16 | 0.014 | 0.024 | 0.089 | 0.034 | 0.656 | 0.406 | 0.592 | 0.308 |
| stabilityai/ViT-L-16 | 0.013 | 0.023 | 0.752 | 0.677 | 0.689 | 0.413 | ||
| recruit/ViT-B-32 | 0.030 | 0.038 | 0.191 | 0.102 | 0.797 | 0.676 | 0.592 | 0.524 |
結果としては、日本語特化で学習させたCLIPモデルは多言語のデータセットで学習させたLAIONのモデルには全タスクで性能が劣るという結果になってしまいました。一方で、日本語圏のデータセットにおいてはrinnaのCLIPに対してほぼ全てにおいて上回り、stability.aiのCLIPに対してもいくつかのデータセットで上回るという結果になりました。なお、stability.aiのモデルはSTAIR Captionsを学習に用いているため、STAIR Captionsにおける評価は行なっていません。
ここで最初に挙げた二つの問いについてみてみます。 まず、
- 問い: 日本語データの含有量が同じとき、多言語での訓練と日本語単独での訓練では、どちらが日本語タスクでの性能が高くなるか?
に対しての答えですが、モデルのサイズが同じであるlaion/ViT-B-32との比較の結果を見ると、いずれのタスクでも多言語で訓練されたlaion/ViT-B-32の方が良いという結果になっています。この理由については今回は分離できなかったのですが、日本語以外の言語から知識を移転させている可能性があるのではないかと考察をしています。
また
- 視覚・言語型基盤モデルの日本語タスクでの性能を比較するとき、ImageNetを和訳した分類タスクは適切な代表タスクなのか?
についてですが、LAIONのモデルはImageNetにおける評価でも日本語圏のデータセットでも私たちの作成したモデルを上回る性能を達成している一方で、rinna・stability.aiのモデルと私たちのモデルの間では、ImageNetにおける性能順位と日本語圏のデータセットにおける性能順位が逆転しています。
この結果を踏まえると、ImageNetにおける評価は、日本語タスクでの性能に対する適切な代表タスクとは言えない可能性があると考えられ、日本語タスクの評価は可能であるならば日本語圏のデータセットを用意して行うのが適切と言えるのではないかと私たちは考察しています。
大規模学習のための工夫
一筋縄ではいかないCLIPの訓練
さて、CLIPの訓練では、通常の機械学習と異なり、以下のような問題が発生します:
- 対照学習を成功させるにはバッチサイズを十分大きく(数千のオーダー)とる必要があるが、そのためにはGPU1枚だとメモリが足りない
- 処理全体のボトルネックがGPU処理ではなく画像のディスクI/Oになりやすい
- (クラウド環境で訓練を行う場合)大量の画像をダウンロードしてくる間にもGPUに課金されてしまう
これらの問題について順を追って解決策を紹介していきます。先にキーワードを挙げると、問題1は「データ並列」という仕組みを用いて解決し、問題2と問題3は「ネットワーク経由のシーケンシャルアクセス」を活用して解決しました。
なお、実装に当たっては以下のレポジトリを参考にしました。
特に、再現実装の mlfoundations/open_clip は、 公式レポジトリ では非公開の訓練コードを含んでいる貴重な実装です。 また、ソースコードと合わせて公開している学習済みモデルは公式モデルよりも高い精度を達成しており、推論のみでの利用であっても非常に有用です。
データ並列による複数GPUの活用
この項では、問題1の対策である「データ並列」について解説します。データ並列(data parallelism)とは、GPUごとに異なるバッチを配布して勾配を計算し、各GPUから集約した勾配でモデルを更新する手法です。この方法により、実効的なバッチサイズを大きくすることができます。
ちなみに、モデルが1枚のGPUに収まらないほど大きい場合には、モデルを分割して複数のGPUで訓練する「モデル並列(model parallelism)」という手法も用いることができます。モデル並列はデータ並列と組み合わせて適用することも可能です。
ここでは、PyTorchが提供するデータ並列の機能である「DistributedDataParallel」について説明します。
DistributedDataParallelとは
PyTorchが提供するデータ並列の機能には、DataParallel(DP)とDistributedDataParallel(DDP)の2種類があります。この2つの手法の違いを一言で述べると、DPはマルチスレッドを使用して並列化を行うのに対し、DDPはマルチプロセスを用いて並列化を行います。DPはDDPよりもコードの変更が少なくて済む利点がありますが、いくつかの欠点が存在します1:
- 単一ノードでしか使用できない
- GIL(global interpreter lock)の競合により、処理が遅くなる可能性がある
- 各ステップでモデルをコピーするため、処理が遅くなる可能性がある
今回の計算環境は単一ノードだったため、DPとDDPのどちらでも並列化を実現可能でしたが、GPUをより効率よく使うためにDDPを採用しました。
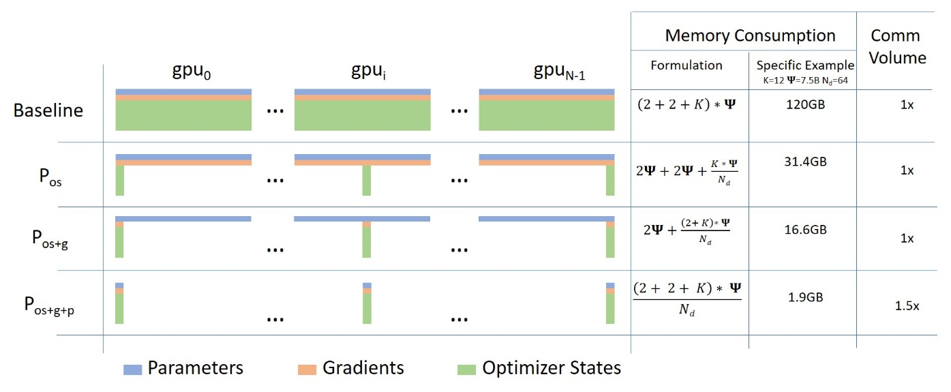
ちなみに、DPとDDPのどちらでも、各GPUがモデル全体の重みを保持します。これでは冗長だということで、メモリ節約のためにモデルの重みや勾配、最適化器の状態を分割して各GPUに分散させる ZeRO (zero-redundancy optimizer)[2] という仕組みが考案されています。今回のCLIPの訓練では必要ありませんでしたが、ZeROを使うと、1枚のGPUには収まらないほどの大きなモデルでも訓練が可能となります。ZeROは、大規模モデルの訓練を支援するライブラリである DeepSpeed の主要機能の一つです2。
DistributedDataParallelの利用
DDPを使う場合、訓練スクリプトの全体像は次のようになります。
import os
import torch
import torch.distributed as dist
import torch.distributed.nn
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def main():
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
n_gpu = torch.cuda.device_count()
mp.spawn(main_worker, nprocs=n_gpu, args=(n_gpu,))
def main_worker(rank, n_gpu):
dist.init_process_group("nccl", rank=rank, world_size=n_gpu)
model, preprocess, tokenizer = build_models(device="cpu")
torch.cuda.set_device(rank)
model.cuda(rank)
model = DDP(model, device_ids=[rank])
criterion = ClipLoss(cache_labels=True, rank=rank)
for epoch in range(CFG.num_epochs):
train_data.set_epoch(epoch)
train_loss, current_steps = train_single_epoch(
gpu=rank,
model=model,
criterion=criterion,
optimizer=optimizer,
dataloader=train_data.dataloader,
)
main関数では、main_worker関数をGPUの数だけ子プロセスとして起動します。main_worker関数のrank引数には、固有のデバイスIDが自動で割り振られます。
main_worker関数の中身は、単一GPUでの訓練ループとほとんど同じなので理解しやすいと思います。しかし、細かい注意点が2つあるため、以降で見ていきます。
まず、勾配を計算しモデルの重みを更新するtrain_single_epoch関数内で、モデルの損失を計算する際には、必ずモデルの__call__関数またはforward関数を経由するようにしてください。すなわち、以下のようにmodel(pixel_values=X_i, input_ids=X_t)を経由して損失を計算するということです。
def train_single_epoch(gpu, model, criterion, optimizer, dataloader) -> float:
model.train()
if gpu == 0:
pbar = tqdm(dataloader, desc="Train", total=dataloader.num_batches)
else:
pbar = dataloader
loss_total = 0
cnt = 0
for batch in pbar:
X_i = batch[0].to(gpu)
X_t = batch[1].to(gpu)
optimizer.zero_grad()
# ここでmodel.forward()またはmodel.__call__()を経由させる
image_features, text_features, logit_scale = model(pixel_values=X_i, input_ids=X_t)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
loss = criterion(image_features, text_features, logit_scale.exp())
loss.backward()
optimizer.step()
loss_total += loss.item()
cnt += 1
if gpu == 0:
pbar.set_postfix({"loss": loss_total / cnt})
return loss_total / cnt
この規則を破ると、GPU間で勾配が同期されなくなってしまいます。勾配が同期されないと、各GPUで保持するモデルの重みがローカルな勾配で更新されていくため、徐々に乖離していき、訓練の品質に悪影響を及ぼす可能性があります。
初期の実装段階において、私たちはimage_featuresとtext_featuresを計算するためにそれぞれget_image_features関数とget_text_features関数を用意して使っていたので、実際にこの状態に陥っていました。しかし、このバグがあっても訓練中の損失は下がっていきました(正しく実装した場合よりも下がり方が遅くなるはずです)。そのため、このバグは長らく検知されず放置されていました。このバグに気づいたのは偶然で、別のデバッグ作業のために各GPUの勾配を表示してみたのがきっかけでした。
もう一つの注意点は、対照損失の実装です。CLIPの損失関数の定義自体はそれほど難しくありませんが、ナイーブに実装すると、比較対象のアイテム数が小さくなってしまいます。例えば、グローバルなバッチサイズが1024、GPUの数が8枚のとき、理想的には1024個のアイテムを1024個の候補アイテムと比較したいところです。しかし、ナイーブな実装では比較対象の数がローカルに存在する128個だけになってしまいます。比較対象が少ないと、モデルに解かせるタスクが簡単になるため、結果として収束後の性能が低下する可能性があります。
この問題を回避するためには、対照損失の計算時にall_gather関数を呼び出すことで、GPU間でimage_featuresとtext_featuresを共有する必要があります。
def gather_features(image_features, text_features):
all_image_features = torch.cat(
torch.distributed.nn.all_gather(image_features), dim=0
)
all_text_features = torch.cat(torch.distributed.nn.all_gather(text_features), dim=0)
return all_image_features, all_text_features
こうして得られるall_image_featuresとall_text_featuresには、グローバルなバッチサイズと等しい数の特徴ベクトルが含まれています。あとは定義どおりに内積を計算すれば、理想通りの対照損失が得られます。
ただし、このとき、前述のmain_worker関数内で、GPU間通信のバックエンドとして
NCCL
を指定する必要があります。これは、all_gather関数をGPUでサポートしているのがNCCLのみだからです。詳しくは
各バックエンドの対応表
を見てください。
シーケンシャルアクセスによるデータローダーの最適化
この項では、問題2と問題3の対策である「ネットワーク経由のシーケンシャルアクセス」について解説します。
機械学習では通常、データセットからランダムな順番でデータを取り出すため、一般的なデータローダーはディスクに対してランダムアクセス(random access)を行います。しかし、ランダムアクセスではシーク時間の分だけ遅延が発生し、大規模データで並列学習をする際にはこの遅延がボトルネックになることがあります。そのため、近年の大規模学習では、ディスクの先頭から順にデータにアクセスしていくシーケンシャルアクセス(sequential access)を採用することがあります。この方法により、データローダーの効率が向上し、訓練の高速化が期待されます。なお、シーケンシャルアクセスで擬似的にランダムネスを実現するためには、現在位置から一定の数のデータをバッファに詰めておき、そこからシャッフルした上でバッチを取り出します。
このようなシーケンシャルアクセスのデータローダーを簡単に実現するライブラリとして、PyTorch向けにはWebDataset、Tensorflow向けにはTFRecordなどが存在します。ここでは、PyTorch向けのライブラリであるWebDatasetに焦点を当てて説明します。
WebDatasetとは
WebDatasetは、データセットを数百MB程度のシャード(実体はtar形式のファイル)に分割し、これらのシャードをシーケンシャルに読み込む仕組みを提供するライブラリです。
WebDatasetは、ローカルディスク上のファイルだけでなく、Amazon S3やGoogle Cloud Storageなどのオブジェクトストレージ上のファイルも参照できます。クラウド上のデータを使用する際には、大規模なデータセット(今回のケースでは約3TB)のダウンロードにかかる時間を節約できます。ネットワークを経由する場合は通信時間が追加で必要になりますが、通信はGPUでの計算と並行して行えるので、訓練時間に影響しないことが多いです。
実際、今回の実験でWebDatasetをネットワーク越しに使い、DDPと組み合わせて訓練したところ、GPU使用率は100%に到達し、I/Oボトルネックを発生させずに訓練することができました3。ただし、クラウドサービス上のファイルに対してアクセスを行う場合は、Egressの料金に注意して使用してください。
WebDatasetの利用
WebDatasetを利用するためには、まずデータセットをシャードに分割します。詳しい方法については割愛しますが、 公式ドキュメント や img2dataset が参考になります。シャード(tarファイル)の1つを展開して表示したものを下図に示します。このように、「画像ファイル」「キャプションが書き込まれたテキストファイル」「メタデータのJSONファイル」の三つ組が連番で格納されています。
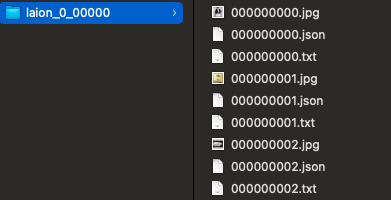
こうしてできたシャードのリストからデータローダーを作るためのget_wds_dataset関数を、抜粋して以下に示します。この関数はGPUごとに呼び出され、それぞれ異なる順番でシャードを読んでいきます(乱数シードをGPUごとに変えているため)。
import webdataset as wds
def get_wds_dataset(
input_shards,
preprocess_img,
tokenizer,
is_train,
resampled,
num_samples,
batch_size,
workers,
world_size,
epoch=0,
):
shared_epoch = SharedEpoch(
epoch=epoch
)
pipeline = [ResampledShards2(input_shards, deterministic=True, epoch=shared_epoch)]
pipeline.extend(
[
tarfile_to_samples_nothrow,
wds.shuffle(
bufsize=_SAMPLE_SHUFFLE_SIZE,
initial=_SAMPLE_SHUFFLE_INITIAL,
),
]
)
pipeline.extend(
[
wds.select(filter_no_caption_or_no_image),
wds.decode("pilrgb", handler=log_and_continue),
wds.rename(image="jpg;png;jpeg", text="txt"),
wds.map_dict(image=preprocess_img, text=MyTokenizerWrapper(tokenizer)),
wds.to_tuple("image", "text"),
wds.batched(batch_size, partial=not is_train),
]
)
dataset = wds.DataPipeline(*pipeline)
dataloader = wds.WebLoader(
dataset,
batch_size=None,
shuffle=False,
num_workers=workers,
persistent_workers=True,
)
return DataInfo(dataloader=dataloader, shared_epoch=shared_epoch)
このコードで重要なのは、データローダーのパイプラインです。まず、pipeline変数の初期化時には、PyTorchのIterableDatasetクラスを継承するデータソースを指定しています。次に、バッファの中身をシャッフルしてローカルなバッチサイズの分だけデータを取り出しています。もしここでシャッフルをしないと、シャードに追加された順番のままデータが取り出されるため、十分なランダムネスを担保できません。最後に、画像データとテキストデータにそれぞれ前処理を適用してtorch.Tensorに変換しています。
また、冒頭でshared_epochという変数を導入し、乱数シードに与えることで、シャードを読む順番をエポックごとに変えるようにしています。
以上でパイプラインの完成ですが、この部分はバグが非常に混入しやすいので、本番の訓練に入る前に、下記のような点を注意深く確認しておくべきでしょう(テストコードを書くためのアイディアを募集中です)。
- 各GPUでシャードを読む順番が異なっていること
- ローカルなバッチの中身がシャッフルされていること
- 各エポックでシャードを読む順番が異なっていること
その他の話題
さて、ここまで記事を読んで、なぜ私たちがParameter Efficient Fine Tuning(PEFT)の手法を使わずに普通のFine Tuningをしているのか疑問に思った方もいるかもしれません。
実は、Fine Tuningの裏でPEFT手法の一つであるLoRA[3]による学習を試していたのですが、学習をしても損失が期待しているほど下がらないという結果に終わってしまいました。残念ながら予算の制約内で原因究明を行うことはできなかったのですが、学習のハイパーパラメータの設定が悪かった可能性もあると考えており、今後検証していければと思っています。
LoRA
一般的なFine Tuningでは学習の際にモデルのパラメータの重みの一部または全てを更新するので、誤差逆伝播を行うために多くのパラメータについての勾配の情報を保持する必要があり、メモリの消費量が多くなってしまいます。
LoRAでは学習を行いたい層そのものを学習可能にするのではなく、学習を行いたい層の重みと同じサイズの重み行列を用意し、その重み行列のみを学習可能にします。ただし、新たに用意する重み行列は二つのより小さい行列(下図のAとB)の行列積で表現するため、一つの行列で表現するよりも学習されるパラメータ数は少なくなります。これにより学習時に保持される勾配データのサイズを減らせるためメモリの消費量を抑えることができます。
順伝播の際には、元の重み行列に新たに追加した重み行列を足し合わせるように使うため、パラメータ数は一切増えていないように見えます。したがって、推論時にはメモリの消費量増加や推論速度の低下を引き起こすことはありません。
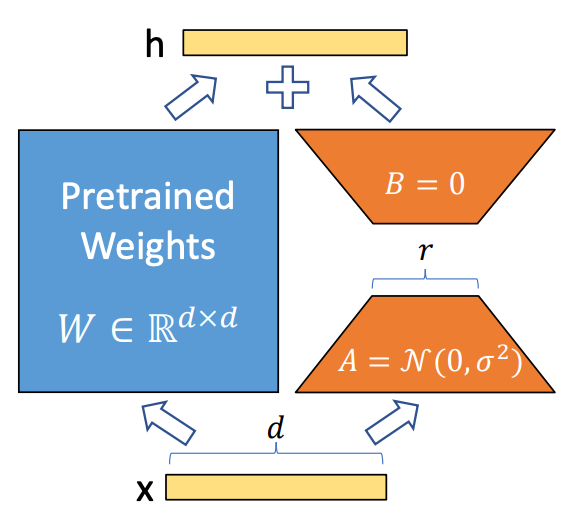
LoRAは loralib というライブラリや、そのラッパーが用意されている peft などを使うことで簡単に試すことができます。
LoRAを使った実験について
私たちは今回はloralibを用いてLoRAを使ったFine Tuningを行いました。LoRAを使ったFine Tuningを行うためには、学習させたい層をloralibに実装されている層4に置き換えてあげる必要があります。例えば線形層(Linear)を置き換えたい場合はtorch.nn.Linearからloralib.Linearに置き換えます。
私たちは次のようにして、置き換えたい層の名前を指定することでモデルの各層をLoRAの層に置き換えるようにしました。
from typing import List, Type, Union
import loralib
import torch.nn as nn
def _contains(name: str, candidates: List[str]) -> bool:
for cand in candidates:
if cand in name:
return True
return False
def _replace_layer(
model_or_module: Union[Type[nn.Module], nn.ModuleList],
names: List[str],
r: int = 16,
lora_alpha: float = 16.0,
lora_dropout: float = 0.1
) -> None:
if len(names) == 1:
module = getattr(model_or_module, names[0])
assert isinstance(module, nn.Linear)
weight = module.weight
in_features = module.in_features
out_features = module.out_features
lora_module = loralib.Linear(
in_features=in_features,
out_features=out_features,
r=r,
lora_alpha=lora_alpha,
lora_dropout=lora_dropout
)
lora_module.weight = weight
setattr(model_or_module, names[0], lora_module)
else:
if isinstance(model_or_module, nn.ModuleList):
idx = int(names[0])
_replace_layer(model_or_module[idx], names[1:], r, lora_alpha, lora_dropout)
else:
_replace_layer(
getattr(model_or_module, names[0]),
names[1:],
r, lora_alpha, lora_dropout
)
def create_lora_model(model: Type[nn.Module], replace_layer_names: List[str], lora_params: dict) -> None:
for name, mod in model.named_modules():
if _contains(name, replace_layer_names):
_replace_layer(model, name.split("."), **lora_params)
例えばreplace_layer_names = ["query", "key", "value"]という引数をcreate_lora_modelに与えると、モデルの中で"query"、"key"、"value"という名前を持った層がLoRAの層に置き換えられます。
さて、LoRAを使ったFine Tuningではどの層を学習可能にするか、という点が重要になってきます。LoRAを提案した論文では、Attentionの中の"query"と"value"のみで十分に学習ができたと書いてあるのですが、私たちの例では"query"と"value"のみではあまり損失が下がらないという結果に終わってしまいました。
「知識は全結合層に蓄積される」という仮説[4]もあるため、"dense"層も入れてLoRAでFine Tuningも行ってみたのですが、今度はメモリ消費量が大きく増加してしまい、Full Fine Tuningとほぼ変わらないリソース消費になってしまったため、検証を断念した、という結果となりました。
なぜ"query"と"value"のみの学習では損失が下がらなかったのか、"dense"層を学習した上で学習時のメモリ消費の低減の効果をうまく受ける方法はあるのか、などまだわかっていない事が多いのですが、この点についても皆さんのご意見をお待ちしております。
おわりに
この記事では公開するCLIPモデルの学習の際の工夫や試行錯誤の過程について書かせていただきました。本モデル・データセット公開が実務や研究のさまざまな場面で使われ、日本のAI活用・研究を活性化させる一助となることを願っています。
一緒に働きませんか?
当社では、様々な職種のエンジニアを新卒・中途ともに募集しております。ご興味のある方は、以下の採用ページをご覧ください。
参考文献
[1] Ananya Kumar et al. “ Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution ”. In ICLR, 2022.
[2] Samyam Rajbhandari et al." ZeRO: Memory Optimizations Toward Training Trillion Parameter Models ". 2019.
[3] Edward J.Hu et al. “ LoRA: Low-Rank Adaptation of Large Language Models ”.
[4] Damai Dai et al. “ Knowledge Neurons in Pretrained Transformers ”.
-
詳しくは PyTorchの公式チュートリアル や こちらの記事 などをご覧ください ↩︎
-
DeepSpeedを始めとする大規模学習の技術については、 Turingのテックブログ が日本語の詳しい資料として貴重です ↩︎
-
ローカルディスクから読み込む場合との比較は実施していませんが、I/Oボトルネックが発生しなかったことから、同等以上の性能を達成できたと言えます。詳しいベンチマーキングについては、 Google Cloudのテックブログ などを参考にしてください ↩︎
-
loralibでは2023年11月現在、Embedding層とLinear層、Conv層が実装されています。 ↩︎

機械学習エンジニア
Hidehisa Arai
好きな技術は深層学習、得意料理はポキサラダです。

機械学習エンジニア
Shion Honda
好きな技術は深層学習、得意料理は茄子田楽です。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


