
はじめに
機械学習エンジニアの長谷川麟太郎です。普段は住まい領域でデータ分析や機械学習のモデル作成などを担当しています。
データ推進室では、有志のメンバーで論文を読む活動(通称「論文読むじろう」)があります。具体的な取り組みの内容については、 前回のパートの記事 を参考にしていただければと思います。 自分もメンバーの一員として、普段の業務で扱うことが多いレコメンド関連のテーマを中心に論文を読んでいます。
今回の記事では検索と推薦を一つのモデルで処理可能な統合モデルについて、幾つかの論文を取り上げつつ紹介しようと思います。
本記事は、データ推進室 Advent Calendar 2024 21日目の記事です
多くのプラットフォームでは検索のモデルと推薦のモデルは別々に開発されることが多いです。しかし、モデルをそれぞれのデータでしか学習できないこと、モデルを別々に開発することがメンテナンスのコストや技術的負債に繋がってしまうという課題があります。 これらの課題を解決するために、検索と推薦の統合モデルの手法が近年注目されつつあります。 本記事では、統合モデルとして初めて提案された手法や、ユーザの検索と推薦の遷移に着目しTransformerを利用する手法、そして実際に企業で運用され有効性も検証された手法などをいくつか紹介します。
個々の解説は概要にとどめるため、詳細に興味を持たれた方は原典に当たっていただければと思います。 また、本記事で用いる図は断りのない限り論文から引用したものです。
Joint Modeling and Optimization of Search and Recommendation (DESIRES'18)
| 項目 | 内容 |
|---|---|
| タイトル | Joint Modeling and Optimization of Search and Recommendation |
| URL | https://arxiv.org/abs/1807.05631 |
| 発表年 | 2018 |
| 会議 | Proceedings of the First International Conference on Design of Experimental Search and Information Retrieval Systems |
| 著者グループ | University of Massachusetts Amherst |
| 著者 | Hamed Zamani and W. Bruce Croft |
まず、最初に紹介するのはJSR(Joint modeling and optimization of Search engines and Recommender systems)という手法です。 自分の知る限りではこちらの論文が、検索と推薦の統合モデルの概念を初めて提唱した論文になっています。
検索エンジンと推薦システムは別々に運用されることがほとんどです。しかし、両者の目的は、「人々が適切なときに必要な情報を得られるように支援すること 1 」と共通しており、JSRは検索と推薦を統合的にモデル化・最適化することで、それぞれの性能向上を目指したものになっています。
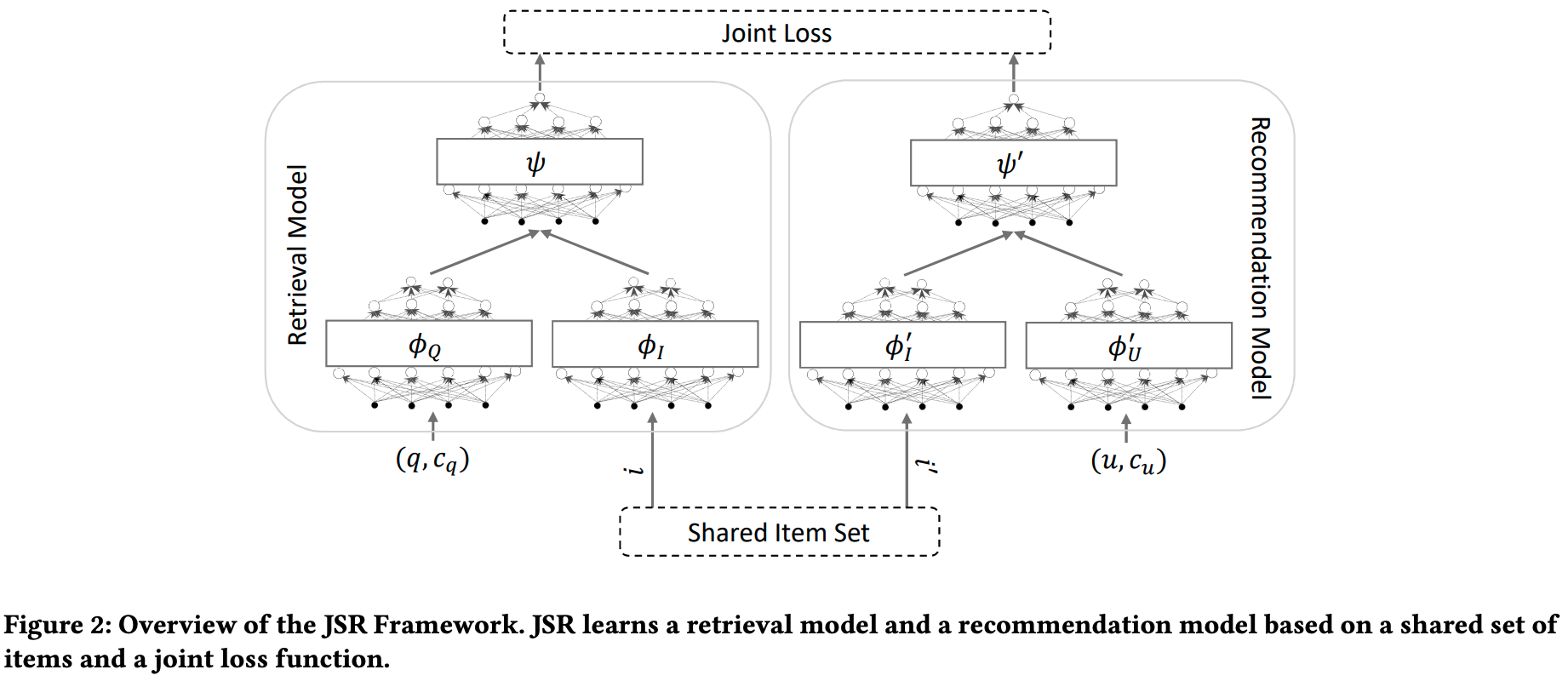
JSRは比較的シンプルなネットワーク構成になっています。検索用のモデルでは、クエリ$q$とクエリコンテキスト$c_q$のペアに対するアイテム$i$のスコアを計算します。クエリコンテキスト$c_q$はクエリにまつわる情報を含み、ユーザのプロフィール、過去の検索履歴、セッション情報、位置情報などから構成されます。 推薦用のモデルでは、ユーザ$u$とユーザコンテキスト$c_u$のペアに対するアイテムiのスコアを計算するものとなっています。ユーザコンテキスト$c_u$はユーザにまつわる情報を含み、最近のユーザのアクティビティ、ユーザの状態などから構成されます。 JSRの評価実験では、簡単のためこれらの情報は入力されず、クエリとユーザIDのみが使用されています。
アイテムの表現はIDベースの埋め込みから作成し、検索用のモデルと推薦用のモデルで共有されます。両方のシナリオで同時に学習を行うことで、より正確なアイテム表現を獲得できる、というのがJSRのメリットです。 実験では、Amazon Productのデータを用いて評価を行い、個別に学習した場合よりも大幅な性能向上を実現しました。
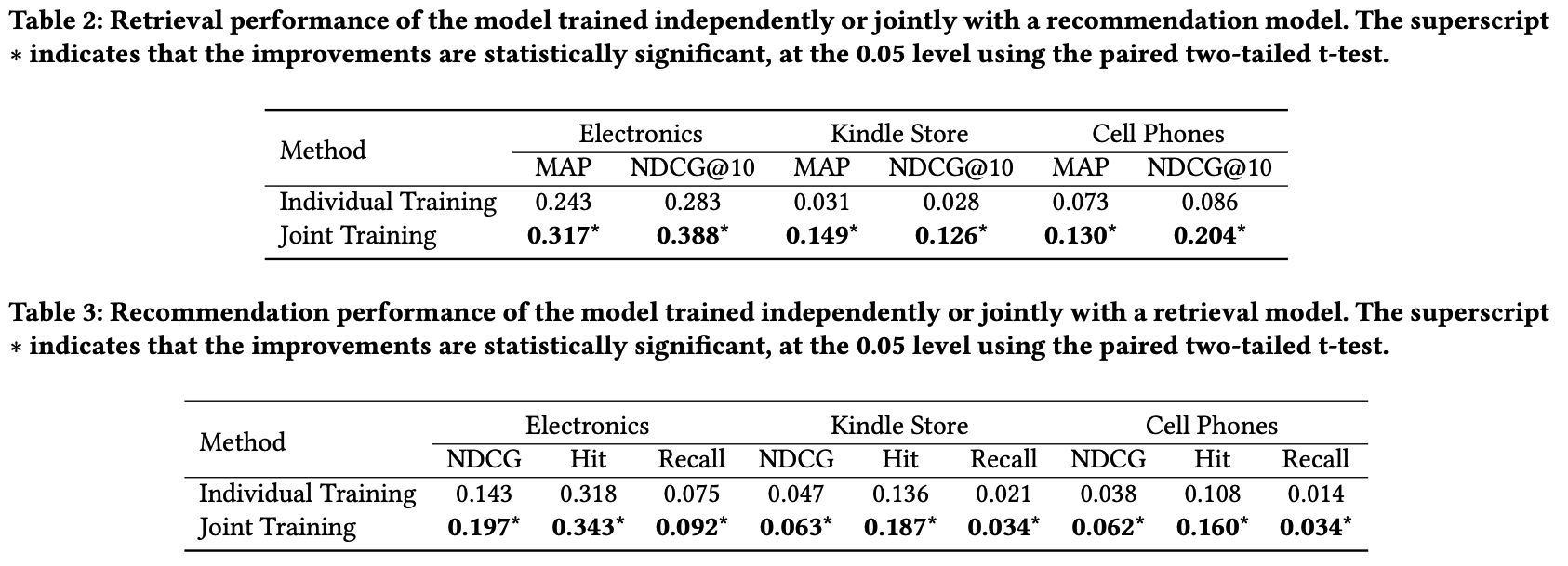
さらに、統合モデルの学習は、過学習の抑制にも効果があることを示唆しています。
以下の図は、推薦データのみで学習した場合(赤)と、両方のデータで学習した場合(青)の推薦タスクにおける損失曲線を示しています。損失の値は、推薦データのみで学習した場合の方が小さく、スコアは低いという結果から、片方のデータを用いた学習は過学習を引き起こす可能性があることを示唆しています。このように、「検索と推薦の両方のデータを用いた学習は、モデルの汎化性能を向上させる」というのが、この論文の最も重要なポイントであると感じます。
JSRはモデルがシンプルであるため、ユーザの複雑な行動系列やコンテキストなどを扱うことができないという改善点がありますが、検索と推薦の統合という新たな研究領域を切り拓いた重要な論文となっています。
UnifiedSSR: A Unified Framework of Sequential Search and Recommendation (WWW'24)
| 項目 | 内容 |
|---|---|
| タイトル | UnifiedSSR: A Unified Framework of Sequential Search and Recommendation |
| URL | https://arxiv.org/abs/2310.13921 |
| 発表年 | 2024 |
| 会議 | Proceedings of the ACM on Web Conference 2024 |
| 著者グループ | Wuhan University, Nanyang Technological University |
| 著者 | Jiayi Xie, Shang Liu, Gao Cong, and Zhenzhong Chen |
UnifiedSSR(Unified framework of Sequential Search and Recommendation)では、検索と推薦のそれぞれにおいて、ユーザの行動系列をTransformerで処理することで、アイテムのスコアを出力しています。さらに、検索のタスクではアイテムだけでなく、クエリの系列も含めて処理を行っています。
モデルの構造は下図のようになっています。推薦のタスクではアイテムの系列について、各要素の依存関係や重要なアイテムの特徴を捉えることを目的として、Self-Attentionによる計算を行います。 検索のタスクでは、アイテムの系列に加えてクエリの系列が入力となります。こちらもSelf-Attentionによる計算を行った後、アイテム系列とクエリ系列の間の関係を学習するために、Cross-Attentionによる系列情報の処理を行います。 また、検索のタスクにおいて、アイテムの系列とクエリの系列はどちらも同一パラメータを持つSiamese Networkで処理がされます。同一のパラメータを使用することで、モデルのパラメータ数を削減するだけでなく、アイテムの系列とクエリの系列が持つ共通の特徴を効率的に捉えることが可能になります。
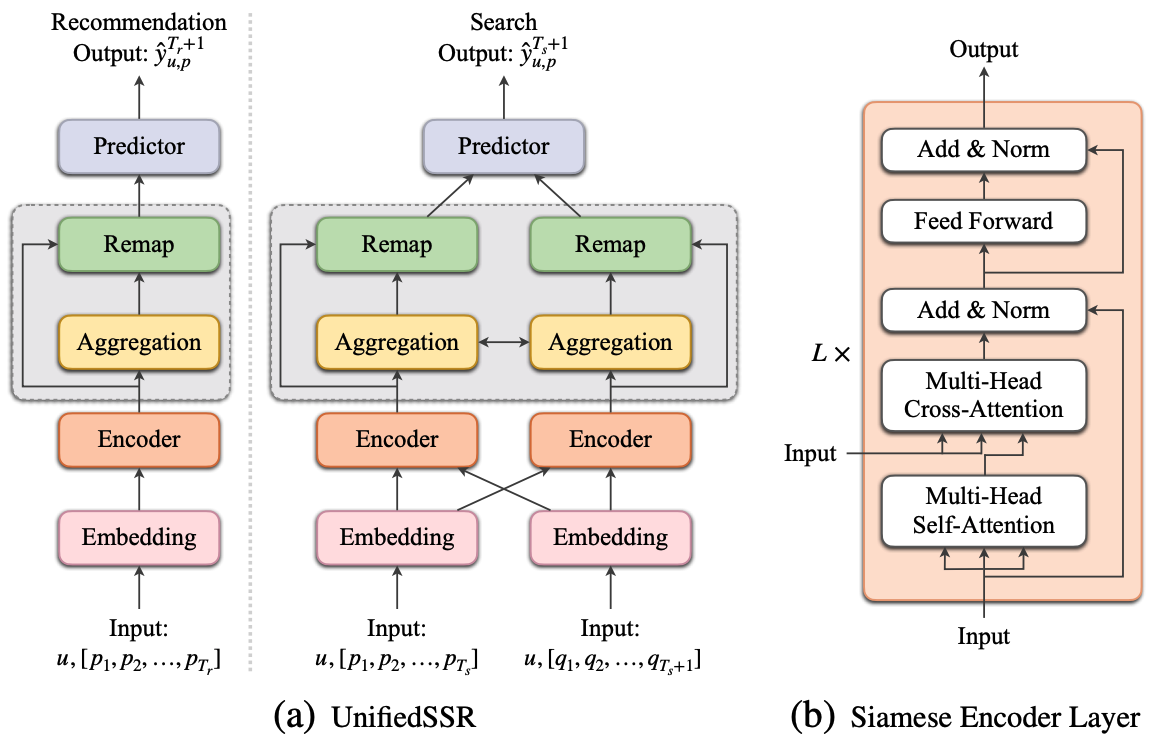
さらに、UnifiedSSRでは、入力の系列からユーザの意図の表現の学習も行います。(上図における灰色枠の箇所)。 手法としては、ユーザの行動系列をN個の区間に分割し、それぞれの区間について、アイテムの系列における意図は$\bold{I}_i^p$、クエリの系列における意図は$\bold{I}_i^q$として、区間内の埋め込みの平均を取ることで計算します。 この意図の表現については、異なる区間の表現のペアは類似度を下げ、同じ区間のアイテムとクエリのペアについて類似度が上がるように、以下の式で自己教師あり学習を行います。
$$ L_{ssl} = \sum_{n=1}^N (\text{Sim}(\bold{I}_i^p, \bold{I}_{i+1}^p) + \text{Sim}(\bold{I}_i^q, \bold{I}_{i+1}^q)) - \sum_{n=1}^N \text{Sim}(\bold{I}_i^p, \bold{I}_{i}^q) $$
区間の分割方法は、時間的に離れたものを区切る、といった方法が考えられますが、UnifiedSSRでは入力系列をもとに動的に区間を区切る方法を採用しています。
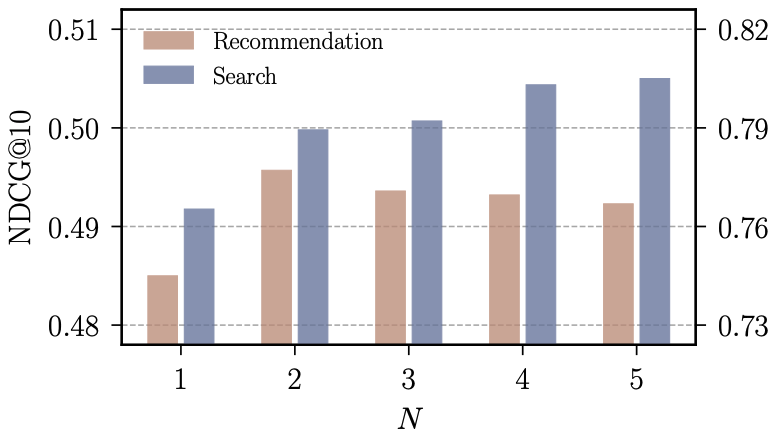
また、区間の個数に対するスコアの分布は以下のようになっています。検索タスクにおいては、区間の数を増やすほどスコアが向上しますが、推薦タスクでは$N=2$を境に性能が低下してしまい、検索と推薦のタスクにおける意図の抽出の難しさを示唆する結果となっています。
UniSAR: Modeling User Transition Behaviors between Search and Recommendation (SIGIR'24)
| 項目 | 内容 |
|---|---|
| タイトル | UniSAR: Modeling User Transition Behaviors between Search and Recommendation |
| URL | https://arxiv.org/abs/2404.09520 |
| 発表年 | 2024 |
| 会議 | Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval |
| 著者グループ | Renmin University of China, Kuaishou Technology |
| 著者 | Teng Shi, Zihua Si, Jun Xu, Xiao Zhang, Xiaoxue Zang, Kai Zheng, Dewei Leng, Yanan Niu, Yang Song |
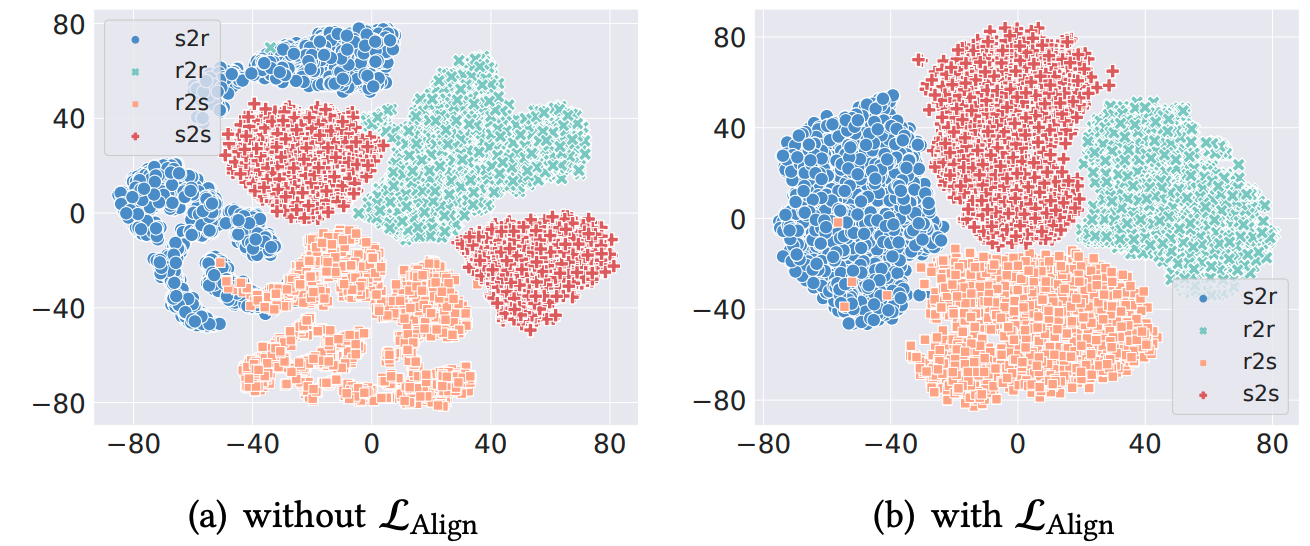
UniSAR(Unified Search And Recommendation)では、検索と推薦の間のユーザの遷移に着目することで、ユーザの正確な意図の抽出という課題に取り組んでいます。 検索と推薦の機能を提供するプラットフォームにおいて、ユーザの行動の遷移は、推薦→検索(r2s)、検索→検索(s2s)、検索→推薦(s2r)、推薦→推薦(r2r)の4タイプに分けることができます。
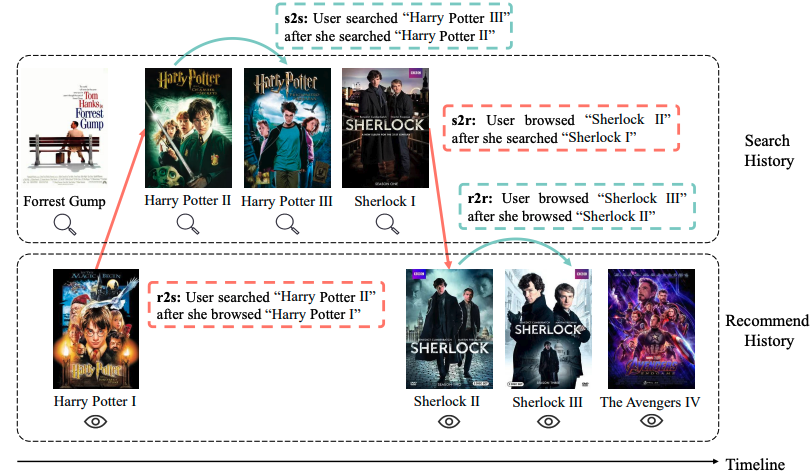
上記の4パターンについて、著者らが属する快手2のプラットフォームでは、ユーザの遷移とアイテムのカテゴリの関係に着目したとき、s2sでは遷移前と遷移後のアイテムが同一カテゴリが多く、そしてs2rやr2sでは遷移前と遷移後のアイテムが異なるカテゴリになることが多い、という傾向が見られました。 このことから、各遷移を含んだ全ての系列をモデルに入力することで、片方のタスクの系列だけでは得られない情報を活用することが可能になります。
先ほど紹介したUnifiedSSRでは、処理する系列は検索のみまたは推薦のみの系列であるため、扱える遷移のタイプはs2sとr2rのみでした。UniSARではそれらに加えて、s2rやr2sのように検索と推薦のシナリオを跨いだ遷移も考慮できる点が大きな特徴です。

UniSARのアーキテクチャの全体像は以下のようになっており、Embedding Module、Transition Modeling、Prediction Layerの三つから構成されています。
Embedding Moduleでは、ユーザの検索と推薦のPVアイテムの系列、商品、ユーザ、クエリそれぞれについて埋め込みを生成します。Transition Modeling(下図c)では、ユーザのPVアイテムの全体の系列だけでなく、検索時の系列と推薦時の系列に分割した上で、3つの各系列についてTransformerで処理を行い、遷移先が検索と推薦となるそれぞれの表現を獲得します。Prediction Layerでは、Multi-gated Mixture of Expertsというネットワーク構造に基づいて、検索と推薦それぞれのスコアを算出します。
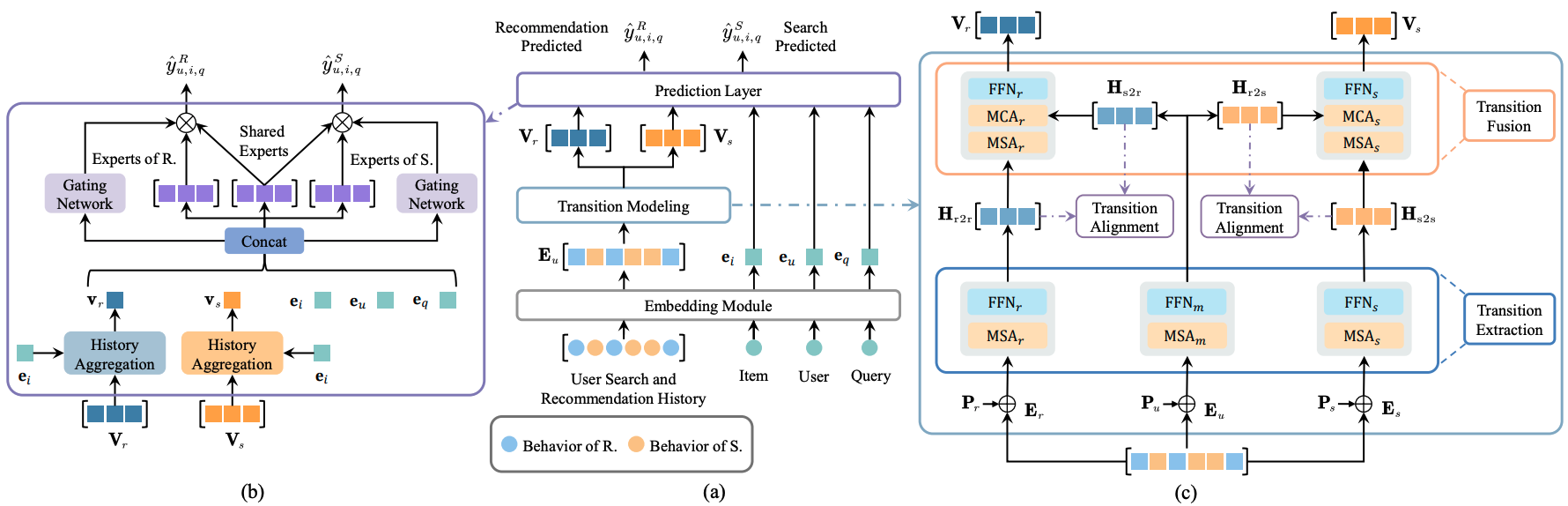
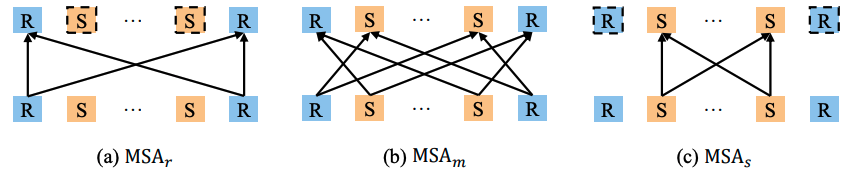
ユーザの遷移パターンに応じて行動の表現を獲得するため、r2rとs2sはそれぞれ推薦のみの系列と検索のみの系列から計算されます。s2rやr2sのようなシナリオを跨ぐ遷移については、特殊なマスクをかけてAttentionの計算を行うことで獲得します。具体的には、シナリオの前後が異なるときは1、同じときは0となるようなマスクをAttentionの計算時に入力し、最終的に得られた表現について、検索でのPVに対応する位置を取り出してr2s、推薦でのPVに対応する位置を取り出してs2rの表現を得ます。
最後のPrediction Layerでは、検索時の表現$V_s$を s2s と r2s の表現から生成し、推薦時の表現$V_r$を r2r と s2r の表現から生成します。そして、Multi-gated Mixture of Experts (MMoE) ベースのネットワークを用いて、検索用と推薦用のスコアをそれぞれ算出します。
また、このモデルでは、クエリとアイテムの表現や複数の遷移の表現を正確に得るため、以下の対照学習を行っています。
- クエリとアイテムの埋め込みの調整
- 異なる遷移表現の整列
1.クエリとアイテムの埋め込みの調整では、検索行動にはクエリが含まれる一方で、推薦行動には含まれないという、検索と推薦行動の性質の違いに対処するため、対照学習によりクエリとアイテムの表現を同じ空間に配置します。
2. 異なる遷移表現の整列では、4つの異なる遷移表現(s2s, r2r, r2s, s2r)を対照学習を用いて整列させることで、異なるシナリオからの遷移と同一シナリオからの遷移の関係を学習します。例えば、$H_{s2s}$と$H_{r2s}$は、それぞれ検索履歴における検索行動または推薦行動からの遷移を表しており、どちらも検索履歴に関連する情報を含んでいます。UniSARでは、これらの表現を正のサンプルとして扱い、対照学習を用いてそれらの表現を近づけます。
このような対照学習によって、4つの異なる遷移表現を適切に分離することが可能になり、後段のモデルでも処理しやすい表現を得ることができます。
A Unified Search and Recommendation Framework Based on Multi-Scenario Learning for Ranking in E-commerce (SIGIR'24)
| 項目 | 内容 |
|---|---|
| タイトル | A Unified Search and Recommendation Framework Based on Multi-Scenario Learning for Ranking in E-commerce |
| URL | https://arxiv.org/abs/2405.10835 |
| 発表年 | 2024 |
| 会議 | Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval |
| 著者グループ | JD.com |
| 著者 | Jinhan Liu, Qiyu Chen, Junjie Xu, Junjie Li, Baoli Li, Sulong Xu |
こちらの論文で提案されたUSR(Unified Search and Recommendation)は、著者らが所属する企業(JD.com)の7Fresh3というサービスに実際に導入され、オンライン検証でも複数の指標で性能向上を実現した手法となっています。
推薦システムにおいて、複数の異なる状況や文脈に基づいて推薦を行う手法やアプローチをマルチシナリオと呼びます。具体的には、ユーザーの行動や嗜好が異なるシナリオ(例えば、時間帯、場所、デバイス、ユーザーの気分など)によって変わる場合に、各シナリオに応じた最適な推薦を提供することを意味します。 著者らは、従来の検索と推薦のマルチシナリオモデルがシナリオ間の違いを効率的に捉えられないことを課題として指摘し、USRではシナリオごとのユーザの興味の表現と、シナリオに依存しない表現を学習可能なアーキテクチャの提案をしています。
下の図はUSRのアーキテクチャを表したものです。S&R Views User Interest Extractor Layerはシナリオごとのユーザの興味の表現を学習する層であり、S&R Views Feature Generator Layerはシナリオに依存しない表現を学習する層となっています。
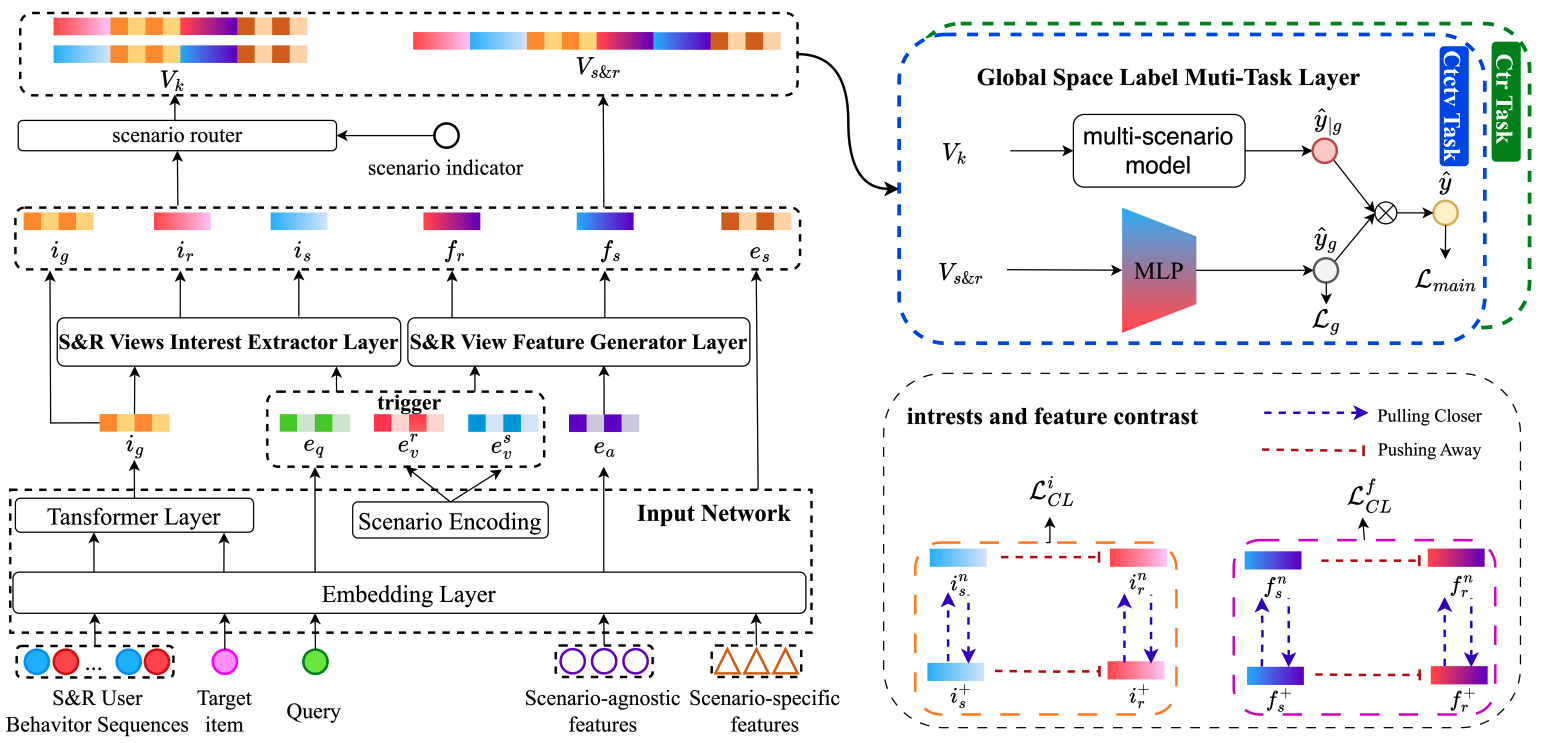
S&R Views User Interest Extractor Layerでは、ユーザの行動系列から得たグローバルな興味$i_g$から、検索の興味$i_s$と推薦の興味$i_r$を生成します。 各シナリオの興味は、以下のように各シナリオの事前知識$t_k$とグローバルな興味$i_g$から生成されます。
$$ i_s = f_{MLP}(DW(t_s\oplus i_g),i_g) $$ $$ i_r = f_{MLP}(DW(t_r\oplus i_g),i_g) $$
ここで、$DW$は、入力に基づいて動的にネットワークの重みを生成するDynamic Weightネットワーク4を表しています。
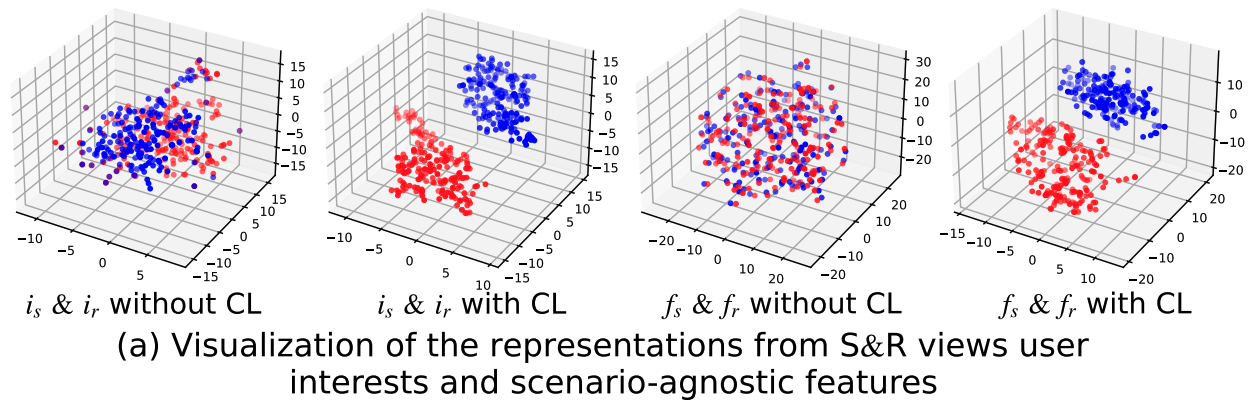
さらに、$i_s$と$i_r$の間では対照学習が行われ、同じシナリオの表現は近く、異なるシナリオの表現は遠くなるように学習されます。これにより、検索シナリオと推薦シナリオ間における表現の違いが明確になることが期待されます。
S&R Views Feature Generator Layerでは、シナリオ非依存の表現$e_a$から検索と推薦それぞれのシナリオに適した表現を生成します。 ここでは、各シナリオの事前知識$t_k$を条件として、$e_a$をスケーリングすることで各シナリオの表現を生成します。
$$ f_s = f_{MLP}(e_a \cdot sigmoid(f_{MLP}(t_s \oplus e_a))) $$ $$ f_r = f_{MLP}(e_a \cdot sigmoid(f_{MLP}(t_r \oplus e_a))) $$
$f_s$と$f_r$においても同様に、対照学習を行うことでシナリオごとの表現の違いが明確になるようにしています
実際に対照学習がないパターン(without CL)とあるパターン(with CL)を比較すると、後者がそれぞれの表現を明確に分けられていることがわかります。
また、1週間のA/Bテストを実施することでUSRはオンラインでも評価されました。ユーザのコンバージョン率(UCVR)とユーザのクリック率(UCTR)について評価を行ったところ、検索シナリオではUCVRが2.85%、UCTRが1.05%の増加、推薦シナリオではUCVRが3.35%、UCTRが1.17%増加するという結果が得られ、USRはオンラインでも有効であることが確認されました。
Joint Modeling of Search and Recommendations Via an Unified Contextual Recommender (Recsys'24)
| 項目 | 内容 |
|---|---|
| タイトル | Joint Modeling of Search and Recommendations Via an Unified Contextual Recommender (UniCoRn) |
| URL | https://www.arxiv.org/abs/2408.10394 |
| 発表年 | 2024 |
| 会議 | Proceedings of the 18th ACM Conference on Recommender Systems |
| 著者グループ | Netflix Research |
| 著者 | Bhattacharya, Moumita, Vito Ostuni, Sudarshan Lamkhede |
2024年のRecsysでは、Netflixからも統合モデルに関する研究が発表されています。この論文はExtended Abstractとして投稿されており、モデルの導入に至るまでの背景やモデリングのアプローチなどが簡単に紹介されています。
Netflixのプラットフォームでは、検索と推薦の両方の機能を持っています。しかし、それぞれのシステムは別々に開発されるため、メンテナンスコストの増大や技術的負債につながることがあります。さらに、従来の研究で示されているように、検索と推薦の両方のデータからモデルを学習することの有効性も確認されています。 こうした背景から、NetflixではUniCoRn(Unified Contextual Ranker)という統合モデルを導入し、検索と推薦の両タスクの改善を目指しています。
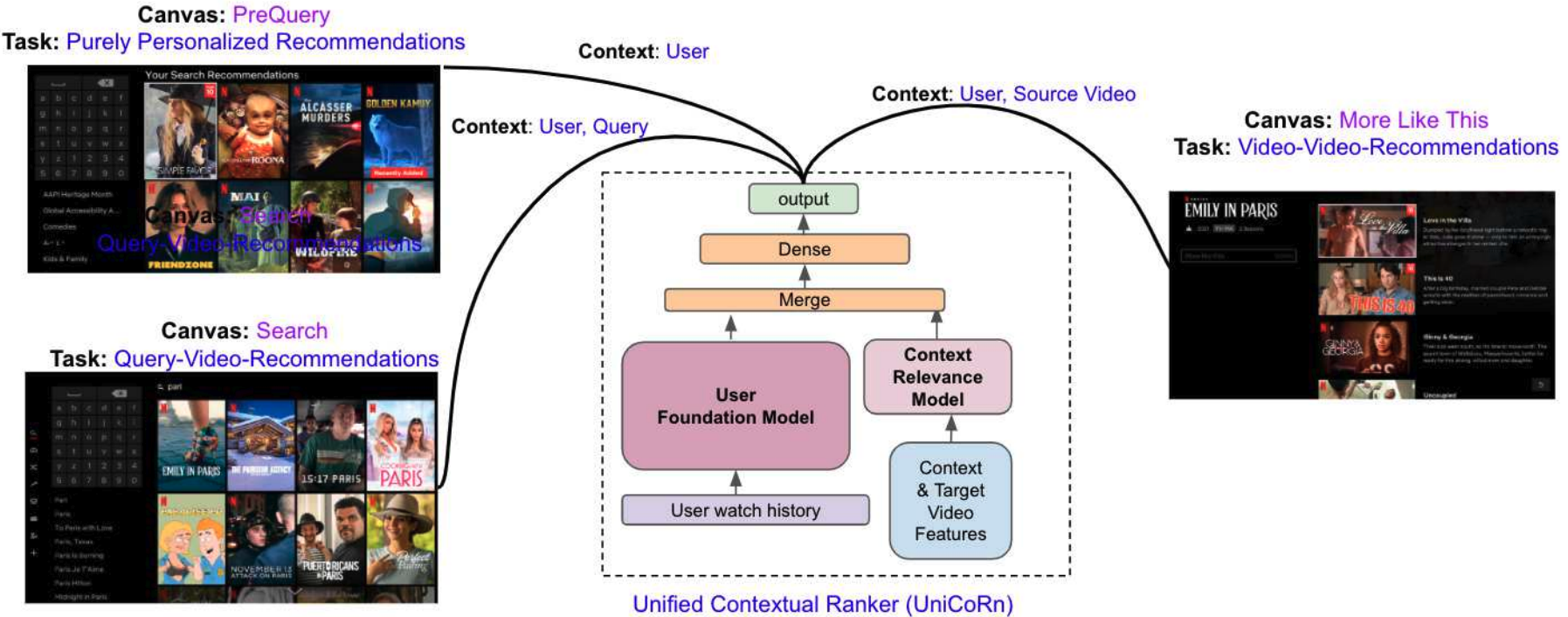
Netflixでは上図のように、検索(Query-Video-Recommendations)、動画を開いたときの推薦(Video-Video-Recommendations)、ホーム画面における推薦(Profile-Video-Recommendations)など、多くの導線が存在しますが、UniCoRnは単一のモデルでそれぞれのタスクを扱います。つまり、検索と推薦の二つだけでなく、複数の推薦シナリオにも対応可能なのがUniCoRnの特徴だと言えます。
UniCoRnは、モデルに入力するコンテキスト情報を豊富にすることで、異なるタスクに対応しています。コンテキストとは、ユーザID、クエリ、国、動画ID、タスクの識別子などを指します。一部のタスクでは欠けてしまうコンテキストに対して、null値の代入や動画名からクエリを生成するといった補完が行われています。 このように、欠落しているコンテキストを可能な限り入力に加えることは、特徴量のカバレッジが向上し、異なるタスク間の学習に有用だそうです。また、タスクの識別子のような、異なるタスクに特化した特徴の入力が、タスク間のトレードオフを学習するのに役立つ、ということも言及されていました。 できる限り多様なコンテキストを入力に含めることが、統合モデルの改善に重要だということが伺えます。
おわりに
いかがでしたでしょうか?本記事では、社内の活動で読んできた論文の中から「検索と推薦の統合モデル」というテーマで論文5本を紹介しました。 もともとはアカデミアで研究されていた手法でしたが、近年になってようやく実運用されつつある印象があります。このような知見を自組織のプロダクトにも活かしていければと思います。本記事が何かの参考になれば幸いです。
-
Nicholas J. Belkin and W. Bruce Croft. Information Filtering and Information Retrieval: Two Sides of the Same Coin? (Commun. ACM 1992) ↩︎
-
主にモバイル向けのショート動画アプリを運営する中国企業(https://www.kuaishou.com/?isHome=1) ↩︎
-
中国国内で新鮮食品の提供を行うE-commerceサービス(https://www.7fresh.com/) ↩︎
-
Bencheng Yan, Pengjie Wang, Kai Zhang, Feng Li, Hongbo Deng, Jian Xu, and Bo Zheng. 2022. APG: Adaptive Parameter Generation Network for ClickThrough Rate Prediction. In Advances in Neural Information Processing Systems. 24740–24752. ↩︎

機械学習エンジニア。住まい領域のデータの分析・モデリングなどを担当。
長谷川麟太郎
2024年4月リクルート新卒入社。趣味はテニスとKPOP。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


