
はじめに
こんにちは、アナリティクスエンジニアの林田です。
データ推進室 データマネジメント部では、情報共有やコミュニケーション活性化を目的として、今年の9月にライトニングトーク会(以下「LT会」)を開催しました。
多くの学びや気づき、コミュニケーションが生まれる機会となりました。
今回の記事では、開催の様子をご紹介します。ぜひご一読ください。
本記事は、データ推進室 Advent Calendar 2024 22日目の記事です

アナリティクスエンジニアについて
リクルートのアナリティクスエンジニアとは
アナリティクスエンジニアは、分析に使えるクリーンなデータ環境を提供し、それを実現するためにソフトウェア開発のベストプラクティスを活用して、生産性の高いデータ管理を実現することをミッションとして求められています。
リクルートの中でアナリティクスエンジニアに求められる役割は、一般的にデータアナリストやデータエンジニアとして定義される役割も包含した位置づけになっています。
アナリティクスエンジニアリングの重要性
アナリティクスエンジニアが誕生した背景には、成長し続ける事業環境に合わせてデータ活用・データを使った意思決定の重要度が増す中で、同様に進化を続けてきたデータ組織の中で生まれた技術的負債が弊害となり、提供するデータの品質担保やスピードを維持する負担が増えていることがありました。
リクルートのデータマネジメント組織はサービス・プロダクト組織に分かれて、それぞれ存在していますが、どれも以下の様な共通の課題を抱えていました。
- 要求元の分散化:活用先が増えただけでなく、サイロ化により管理の範囲が大きく広がり困難になっていること。
- 難易度の高度化:Quality・Cost・Delivery・Scopeの要求が強くなる中で、開発の効率化、生産性の向上が急務になっていること。
- データマネジメントサイクルの長期化:データソース、活用先の両面が増え続ける中で、品質担保を維持するための負担が増えていること。
今後もデータの活用フェーズが進み、いわゆる「データの民主化」が進む中で、データの理解不足、管理されていないパイプラインやSQL、ビジネスロジックの乱立などが想定され、利活用のスピードを止めずに、データ活用の負を解決していくことが求められます。
もっと知りたい方は、ぜひ以下もご覧ください。
- アナリティクスエンジニアの募集を始めました(Recruit Tech Blog)
- リクルートのアナリティクスエンジニア組織立ち上げこれまでとこれから(SpeakerDeck)
- データにまつわる“お悩み”を根こそぎ解決。リクルートのビジネスを支える影の仕事人「アナリティクスエンジニア」の素顔(はてなニュース)
なぜLT会を開催したのか
開催の経緯
あるデータマネジメントグループのメンバーからの声で、「他のデータマネジメント組織やアナリティクスエンジニアが行っていることを知りたい。取り組みについて情報交換したい。」という声が挙がっていました。
アナリティクスエンジニアは2022年から徐々に職種イメージを固めていきましたが、メンバーの中には職種理解にばらつきがありました。各組織が行ってきたことは他組織でも参考になることばかりで、リクルート横断での情報交換やナレッジ共有が非常に有意義かつ重要だと認識し、開催となりました。
開催方式
交流のしやすさを考慮し、オフライン参加をメインとして開催。参加できない方へはオンラインで参加してもらい、ハイブリット形式での開催となりました。
また、当社オフィスのオフライン会場には、飲食も準備し、参加者同士が交流しやすいカジュアルな会にしました。

トーク内容について
今回は初の開催の為、登壇者には「業務の取り組み」というテーマで発表してもらいました。
1.「複数人でデータマートを開発するTips」 発表者:山家さん
HR領域では、一つのデータマート開発プロジェクトに複数のアナリティクスエンジニアがアサインされ、複数人で分担・協力して開発しています。データマートを設計・開発・テスト・デプロイするツールとしてdbt Coreを採用しています。
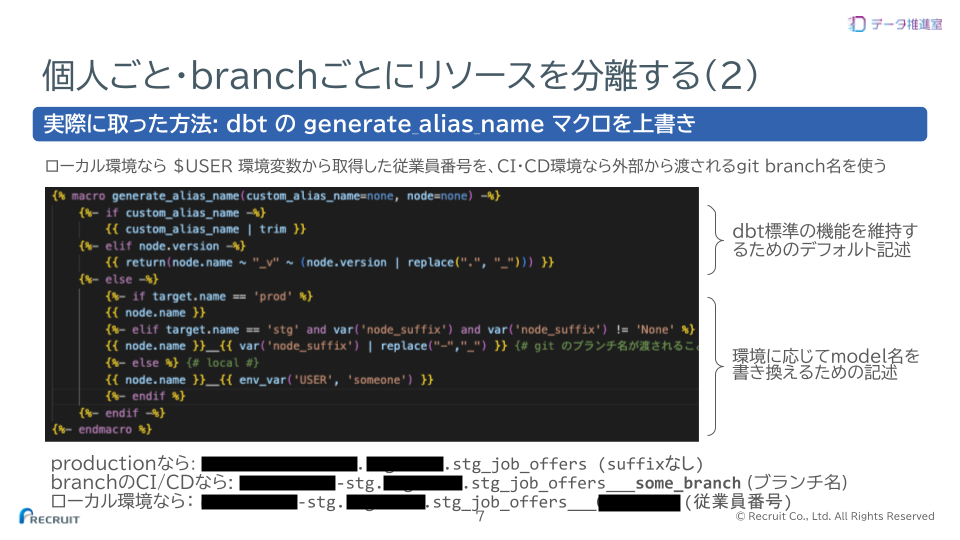
ソフトウェアの開発を複数人で分担し、一定の品質を担保しながら成果物を高頻度にデリバリーしていくには、いわゆるCI/CDが助けになります。前職の経験から、ソフトウェア開発におけるCI/CDに相当するものを、データマートの開発フローの中でより簡単に利用できると良いと考えました。主な要件は、開発メンバーが他のメンバーのタスクに影響を与えずに、変更内容のビルド・テスト・デプロイができることと、そのために、各自のPC端末やgitブランチ単位で、データ基盤(BigQuery)のリソースが分離できることです。
そこで、dbt Coreがもっている機能性(generate_alias_nameマクロ等)と、GitHub Enterprise、社内標準のワークフローエンジンCroisの動作を連動させて、branch単位や各自のローカル環境ごとにビルドやテスト、デプロイができる開発環境についてトークしました。
2.「dbtでつくるニアリアルタイムデータマート」 発表者:半谷さん
住まい領域ではカスタマ行動ログをデータ利用者が分析しやすいように加工した上で、データマートとして提供しています。必要な事前処理を済ませた上で、かつ分析に便利なカラムを何十個も追加して提供することによって、分析の負担・難易度を大幅に下げることができ、SQL初学者でもプロダクト改善に向けた分析を日常的におこなうことができます。
このマートの重要課題が「鮮度向上」でした。必要なデータ加工処理量が非常に多いため、従来は日次更新テーブルとして提供していました。しかし、カスタマ行動を迅速に捉えプロダクト改善に活かすために「当日のカスタマ行動を当日中に分析したい!」という声が日に日に高まっていました。
そこで、dbtで実装していたデータ加工ロジックを精査して遅い処理を突き止め、データ加工フローの改善やdbt macro等を駆使したロジック改善により、データ鮮度向上を実現しました。改善に向けた工夫の中で、住まい以外の領域にも横展開可能な事例を紹介しました。

3.「息切れしながら走る セルフサービスBI」 発表者:森田さん
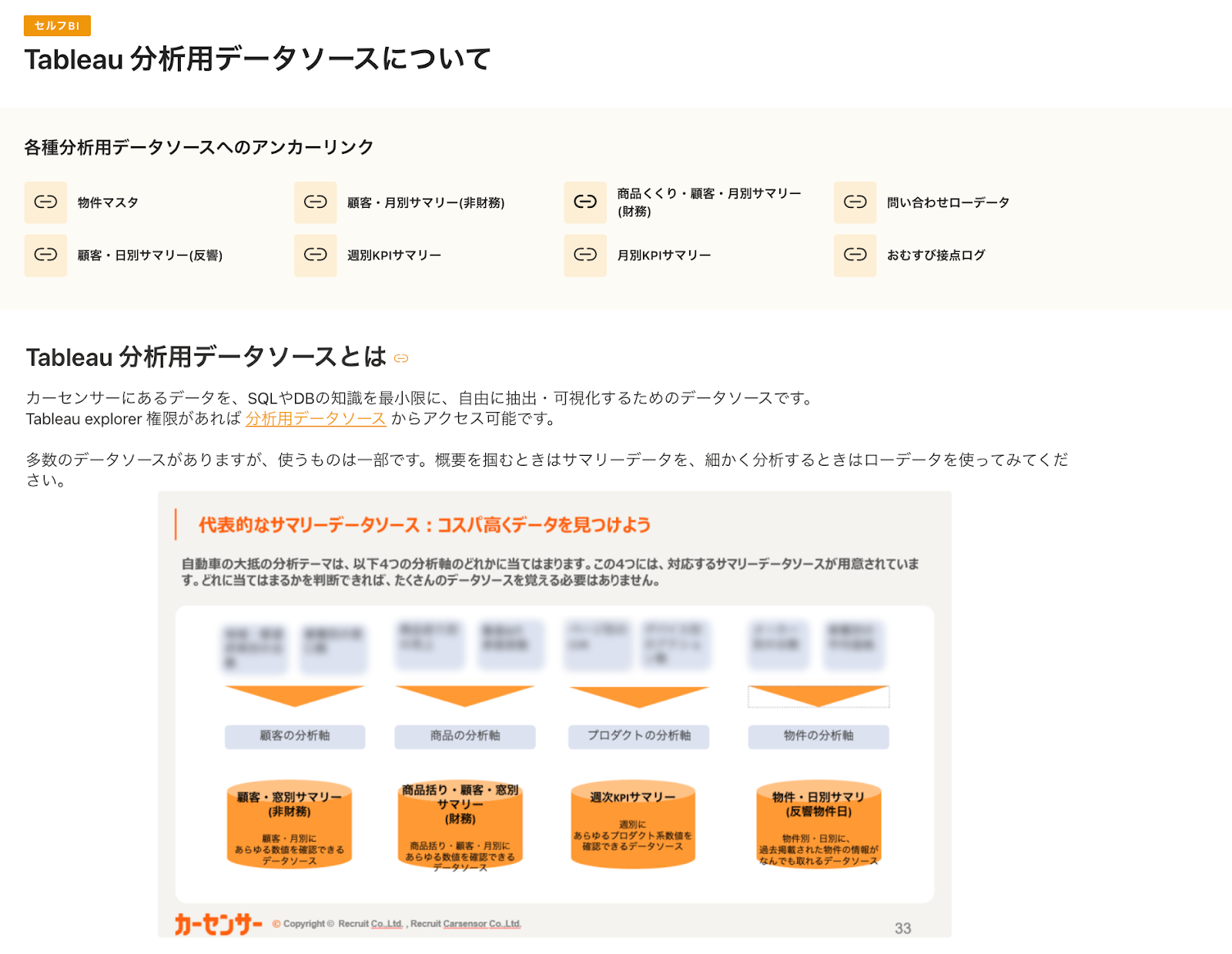
カーセンサーでは事業のデータをBigQueryに集約し、データドリブンな意思決定を支えています。このデータは様々な部署で利用され、数多くのダッシュボードが作られています。その開発と保守にBIエンジニアの工数が多く使われていました。
事業のデータを、エンジニアに頼らず、自力で抽出・モニタリングするセルフサービスBIを実現できれば、工数をかけることなく欲しい時に欲しいデータを自由に確認できるようになります。そこで、カーセンサーのアナリティクスエンジニア組織では、メタ情報の拡充からデータマートの整備、啓蒙活動まで、セルフサービスBIに必要なあらゆることに挑戦しました。データマネジメント的な取り組みは地道な活動になることも多いのですが、監査ログを活用したデータの利活用状況のモニタリングや、アクセスログを直感的に操作できるデータモデリングや、技術的なアプローチにも挑戦しました。
とはいえ、水滴が石を穿つような部分も多く、かけた労力に対して目に見える成果が得られにくいのも事実です。挑戦の結果得られた課題・反省も含め、セルフサービスBIの実現に向けた取り組みを紹介しました。
4. 「自然言語クエリと向き合いたい」 発表者:木内さん
飲食領域においては、事業やプロダクトの迅速な変化に対応するため、意思決定に必要なデータをユーザー自身がセルフで抽出し分析できるよう、メタデータやポータルの整備、分析トレーニングなどの取り組みを実施してきました。これらの集計に必要な情報を集約し、データ組織の工数を使わずとも即座にデータを取得できることを目的として、Databricks Genieを利用した自然言語による分析サポート機能の検証を行いました。
「アクティブユーザー数の定義は?」といった定義情報の確認から、「今月のアクティブユーザー数を教えて」といった集計依頼、さらには得られたデータの可視化まで、データ分析の一連の流れを一つのプラットフォーム上で実行できることから、分析体験の未来を感じることができました。
一方で、曖昧な自然言語による問い合わせに対して正確なデータを提供するためには、メタデータの拡充はもちろん、データモデルやセマンティックレイヤーの整備、様々な問い合わせパターンに対する品質検証など、データマネジメントの取り組みが不可欠です。検証を通じて得られた分析体験の進化と課題についても紹介しました。
5. 「データディスカバリー with LLM」 発表者:近藤さん
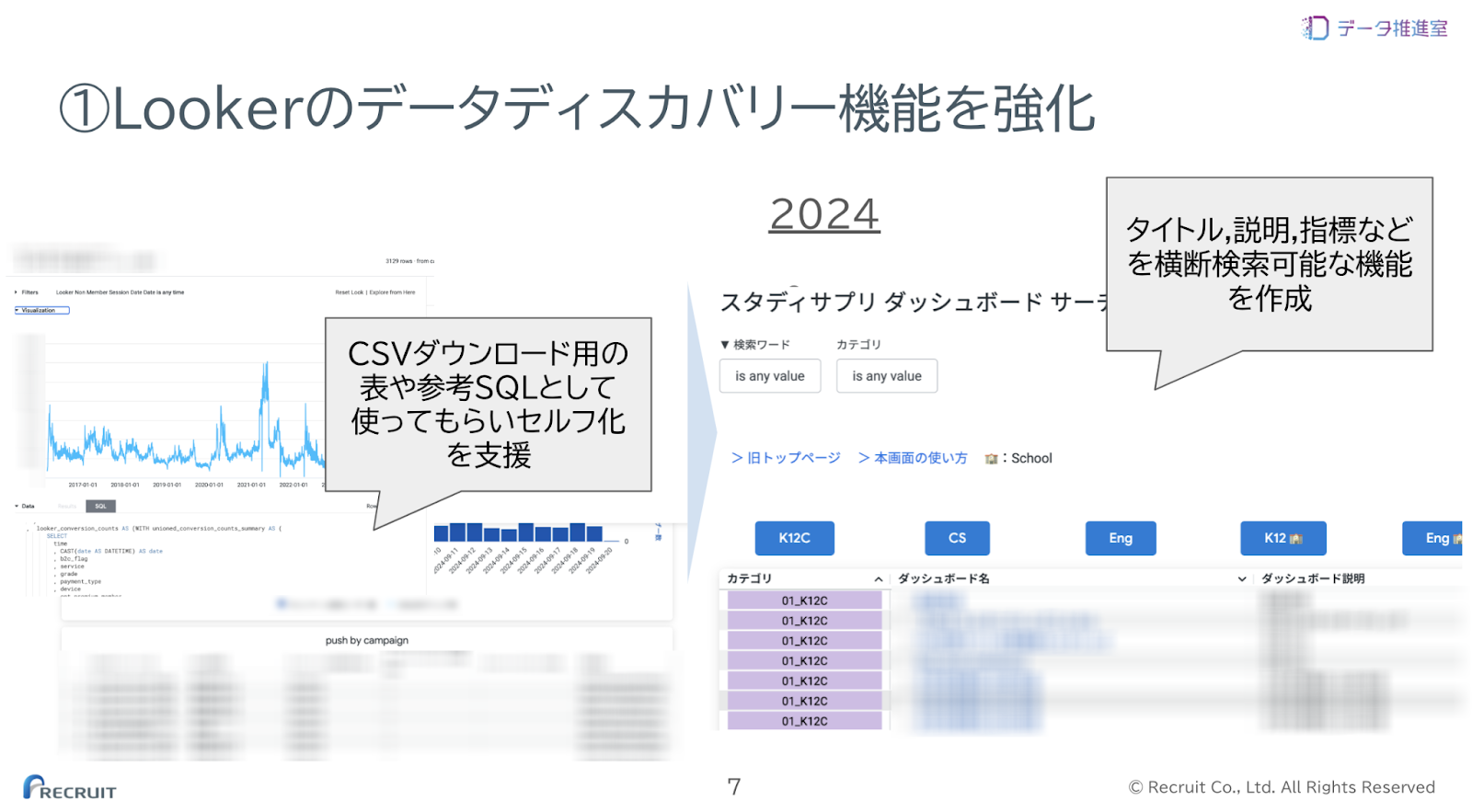
まなび領域ではDMGの理想の形として自動販売機のようなセルフ化を目指しています。これはDMGを介さずに利用者がデータを使うことができる状態です。この状態に至るまでに、利用者の欲しい形に合わせてフルスクラッチするオーダーメイド(職人)から始まり、ヒアリングはするが、既成の形を提供するテーラーメイド(コンビニ)を経由すると考えており、如何にこの過程を進ませるべきかを日々考えています。
そこに向けて、今期重視したのがデータディスカバリーです。これはデータの提供やアクセスだけでなく、発見も支援しようという取り組みです。発見を支援するソリューションとして、BIツールのトップページ検索機能の作成と、LLMを用いた様々な資材への横断検索を作成しました。様々な資材には、ダッシュボードだけでなく、過去の案件issueやテーブルメタデータも含まれています。
これらにより、利用者が我々を介さずに過去のアセットを探せる土台を整えることができました。

6.「メタデータ集約システムについて」 発表者:加藤さん
SaaS DMGでは、『Airレジ』、『Airペイ』を筆頭とした「Air ビジネスツールズ」のデータマートやモニタリングを作成・運用・管理しています。これらを効率的に運用するためにはメタ情報の有効活用が不可欠です。そのため、メタ情報を集約、管理できる仕組みが必要となります。
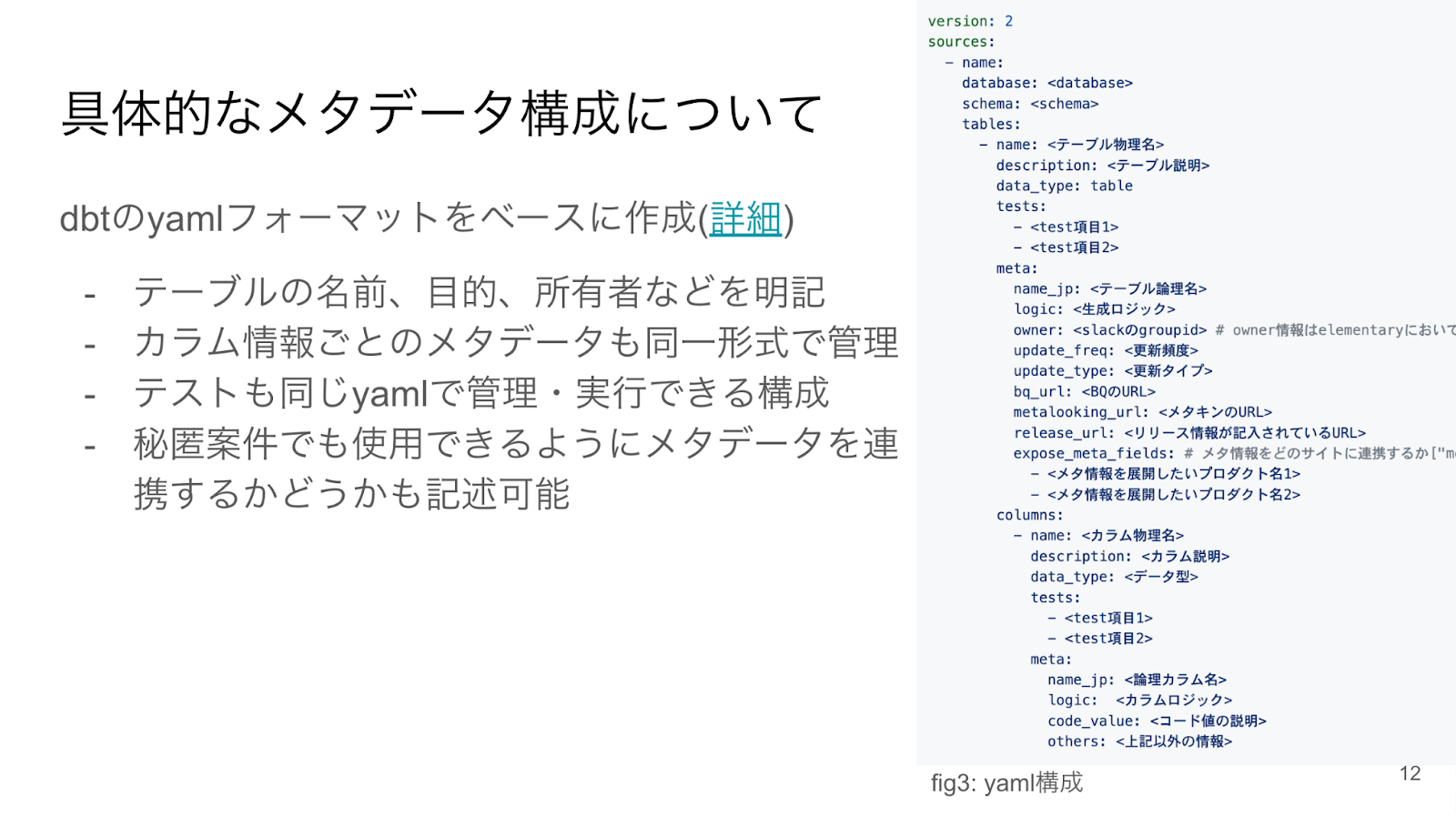
そこで「あらゆるメタデータを統一された形式で集約し、連携することで、効率的なメタデータの運用・管理を行う」というメタデータ構想をチームで掲げました。
これに基づきメタデータの要件を整理し、集約できる仕組みを構築しました。また、この形式で管理されたメタデータを有効に活用するシステム「メタモナーク」を開発しました。メタモナークにより、社内のプロダクトに必要なメタ情報が一元的に連携され、横断的な検索や閲覧が可能になりました。さらに、今後はSSOTを管理する社内プロダクトへの対応やLLMへの対応など、さらなる機能の拡充を計画しています。
データが指数的に増加する現代において、メタデータをはじめとするデータマネジメントには依然として多くの課題が存在します。しかし、私たちはデータマネジメントグループとして、データを用いた課題解決やデータ利活用の基盤を整えていきます。

以下、発表の様子です。


最後に
LT会終了後も、会場に残って組織を超えた議論を交わしたり、各組織の中でも「あの発表が良かった。うちも参考にしよう。詳しい話を聞きに行こう」という声も聞こえたりしました。
また、アンケート結果を見ても満足度が高く、定量・定性の両面で、非常に良い結果となりました。
ご興味のある方は、ぜひ採用ページもご覧ください。
アナリティクスエンジニアの採用ページ

アナリティクスエンジニア
林田 祐輝
2017 年にリクルートマーケティングパートナーズ(現リクルート)へ入社。2022年よりSaaS領域も担当に加え、まなび・SaaS領域のアナリティクスエンジニアのマネジメントを行っています。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


