はじめに
こんにちは。機械学習エンジニアの田中健斗 ( kent0304 ) です。まなび領域のスタディサプリで機械学習プロダクト・データ基盤の開発をしています。
この記事では、スタディサプリの英検エッセイ自動採点プロジェクト、通称ライティングフィードバック (以下「ライティングFB」という) における、LLMを活用した評価フロー改善の取り組みについて紹介します。
本記事は、データ推進室 Advent Calendar 2024 23日目の記事です
ライティングFB
リクルートが提供するスタディサプリは、小学1年生から大学受験生、社会人まで利用することができるオンライン学習サービスです。一般ユーザー向けのtoCサービスと、企業や学校向けのtoBサービスの両方を展開しており、特に中学・高校向けには「スタディサプリ ENGLISH 英語 4 技能コース」という英語4技能を学習できるコースを提供しています。なお、本サービスをご利用いただくにあたり当社が取得した情報は厳重に管理しており、プライバシーポリシー内で規定している範囲内での活用としております。今回は、このコースに含まれるライティングレッスンのフィードバック (FB) 機能の評価フローについて詳しく説明します。
2024年4月、スクールENGLISHのライティングレッスンでは、文法・語彙採点機能を新たにリリースしました。従来は構成観点からの簡単な採点のみでしたが、この機能追加により、ユーザーが入力した英文の文法誤りやスペルミスを自動で検出して修正することが可能になりました。その結果、ユーザー一人ひとりに合わせたFBを提供できるようになっています。

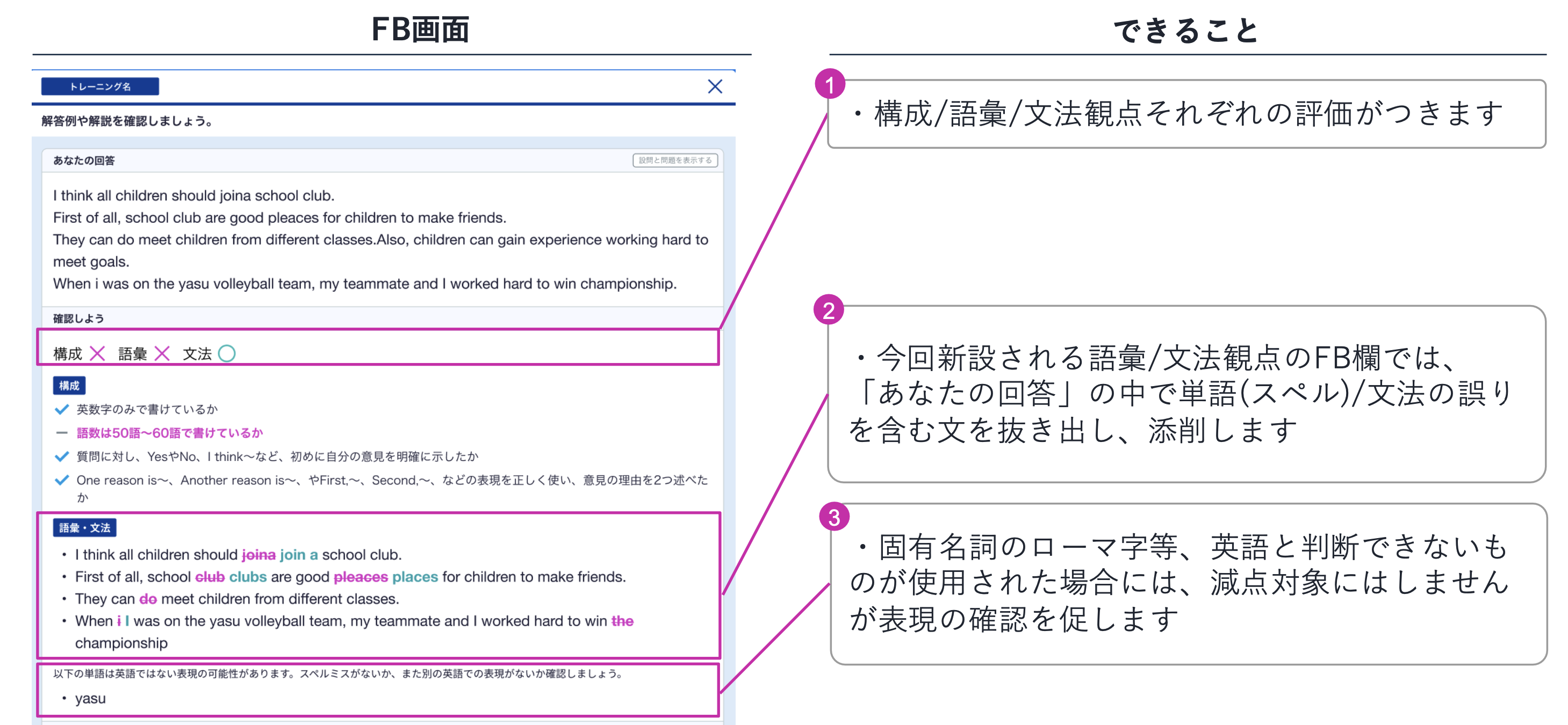
この自動採点機能は、自然言語処理のタスクの一つである「文法誤り訂正」技術を活用しています。具体的には、誤りを含む文とその訂正文からなるパラレルコーパスを深層学習モデルに学習させることで実現しています。
チームで抱えていた課題
文法・語彙採点機能リリース直前は、文法誤り訂正モデルの精度向上に注力していました。アップデートしたモデルは、リリース前に厳格な評価を行うことが不可欠です。これは、生徒に直接FBを提供するサービスであるため、モデルの出力には高い信頼性が求められるからです。モデルをアップデートする際、例えばファインチューニングを行うと、性能が大きく変化する可能性があり、これまで訂正できなかった誤りが訂正できるようになることもあれば、逆に以前は訂正できていた誤りが訂正できなくなる場合もあります。そのため、本プロジェクトでは、事前に構築した評価データを用いてモデルの出力を網羅的に検証することで、リリース前に十分な品質を確保することを目指しました。しかし、当時チームで進めていた評価には大きく3つの課題がありました。
①定量評価の限界
モデルの評価には、文法誤り訂正の研究分野で代表的な参照あり評価手法であるERRANT[1]やGLEU[2]といった尺度を用いて定量評価をしていました。ERRANTは、モデルの訂正が行った編集操作がどの程度リファレンスの編集と一致するかをF値で評価するもので、GLEUは機械翻訳の評価に使われる BLEU[3]を文法誤り訂正用に改良した評価尺度です。しかし、ERRANTやGLEUといった尺度は、モデル全体の性能を数値的に把握するには有用ですが、個々の訂正結果の質を詳細に分析するには限界がありました。具体的には、ERRANTやGLEUのスコア低下がモデルの劣化によるものか、評価尺度自体が持つリファレンスとの比較に基づく限界によるものかを判断することが困難でした。そのため、スコア低下箇所を特定し、実際に目視で確認・評価することで問題の有無を判断する必要がありました。この作業はモデルのアップデートごとに大量の評価データに対して必要となるため、大きな負担となり、迅速なリリースサイクル実現の障壁となる可能性がありました。
②評価フローの標準化
私たちのチームでは、モデル評価フローの標準化に課題を抱えていました。各データサイエンティストが使用する開発環境や評価環境が異なり、Vertex AI Workbenchのノートブックを利用するメンバーもいれば、GCEのVMインスタンスで作業するメンバーもいました。当初は評価スクリプトも個別に管理していたため、使用するライブラリのバージョンの違いにより、評価結果に差異が生まれることさえありました。そして出力した評価結果はファイルに書き出し、英文添削の専門家のいるチームに共有し、確認しあう運用をしていたので、評価結果の共有や比較に手間がかかるだけでなく、評価フローの透明性も低く、ミスが発生しやすい状況でした。さらに、この煩雑な作業で十分な品質を確保するには時間もかかり、チーム全体の生産性を下げていました。そのため、評価フロー基盤を整備し、標準化を実現することが急務でした。

③アノテーションコストの制約
モデルの性能を正しく評価するためには、適切な量の評価データが必要です。スタディサプリの文法誤り訂正モデルのリリース直前評価では、過去の回答ログから抽出した400文を評価データとして使用しました。このデータ量は、モデルの評価において一定の妥当性を確保するために慎重に選択された規模です。とはいえ、モデルの性能をより網羅的に、そして多角的に評価するためには、より大規模なデータセットが理想的だと思っています。
しかし、評価データには、対応する正解の訂正例(リファレンス)を用意する必要があるため、データの数が増えるほどアノテーションコストが増大するという課題がありました。リファレンス作成には英文添削の専門知識が必要で、人手による作業が不可欠です。さらに、モデル開発の過程では、「このタイプの誤りにも対応できるか?」といった検証ニーズが随時発生します。このような場合、都度、新たな評価データとリファレンスを作成する必要があり、継続的なコスト負担が生じます。アノテーションコストの制約は、文法誤り訂正モデルの評価データ作成における課題であり、より大規模で多様なデータセットによる網羅的な評価を実現するための改善が必要でした。
LLMを用いた評価
理想の自動評価を設計
前章で述べたように、既存の評価尺度では、モデルの出力の良し悪しを数値でしか把握できず、問題点の特定や改善に時間がかかるという課題がありました。この課題を解決するため、LLMを用いた、より人間にとって解釈しやすい自動評価システムを構築することにしました。具体的には、文法誤り訂正の評価尺度SOME[4]を参考に、流暢性・文法性・意味保存性という3つの観点から、訂正文をスコアリングするシステムを設計しました。それぞれの観点は以下のとおりです。

これらの3つの観点のうち、どれか一つでも低いスコアだった場合は、その原因を明確にする必要があります。そこで、低いスコアが出た際には、LLMにその理由を説明させるようにしました。これにより、問題点の特定と改善策の検討がスムーズに行えるようになり、結果として、より迅速なモデルの改善とリリースサイクルの実現を目指します。
プロンプト改善とメタ評価
次に、この新たに設計したLLMベースの評価尺度が、実際にどれほど正確に文法誤り訂正モデルを評価できるのかを検証する必要がありました。評価システム自体の評価、いわば「メタ評価」を行うため、LLMによる自動評価結果と人手による評価結果の相関関係を分析することにしました。先行研究[5]を参考に、相関が高いほど自動評価システムの信頼性が高いと判断できます。
このメタ評価を実施するために必要なデータは、誤りを含む入力文、システムによる訂正文、そしてそれらに対する人手評価スコアです。幸いなことに、文法・語彙採点機能リリース前に、様々なバージョンのモデルの出力に対して人手評価を実施していました。これらの既存データを利用し、メタ評価用のデータセットを構築しました。
具体的には、このデータセットは35個のサブセットから構成され、各サブセットには、誤りを含む入力文、システムによる訂正文(複数文)、そして訂正文に対する1~3段階の人手評価が含まれています。(イメージ図参照)

作成したメタ評価データセットを用いて、様々な評価プロンプトを作成し、LLMによる自動評価と人手評価の相関を計測するという実験サイクルを回しました。人手評価は総合的な1つのスコアである一方、LLMによる評価は3つの評価軸(流暢性・文法性・意味保存性)で出力されるので、3つのスコアの最小値を人手評価との相関計測に使用しました。
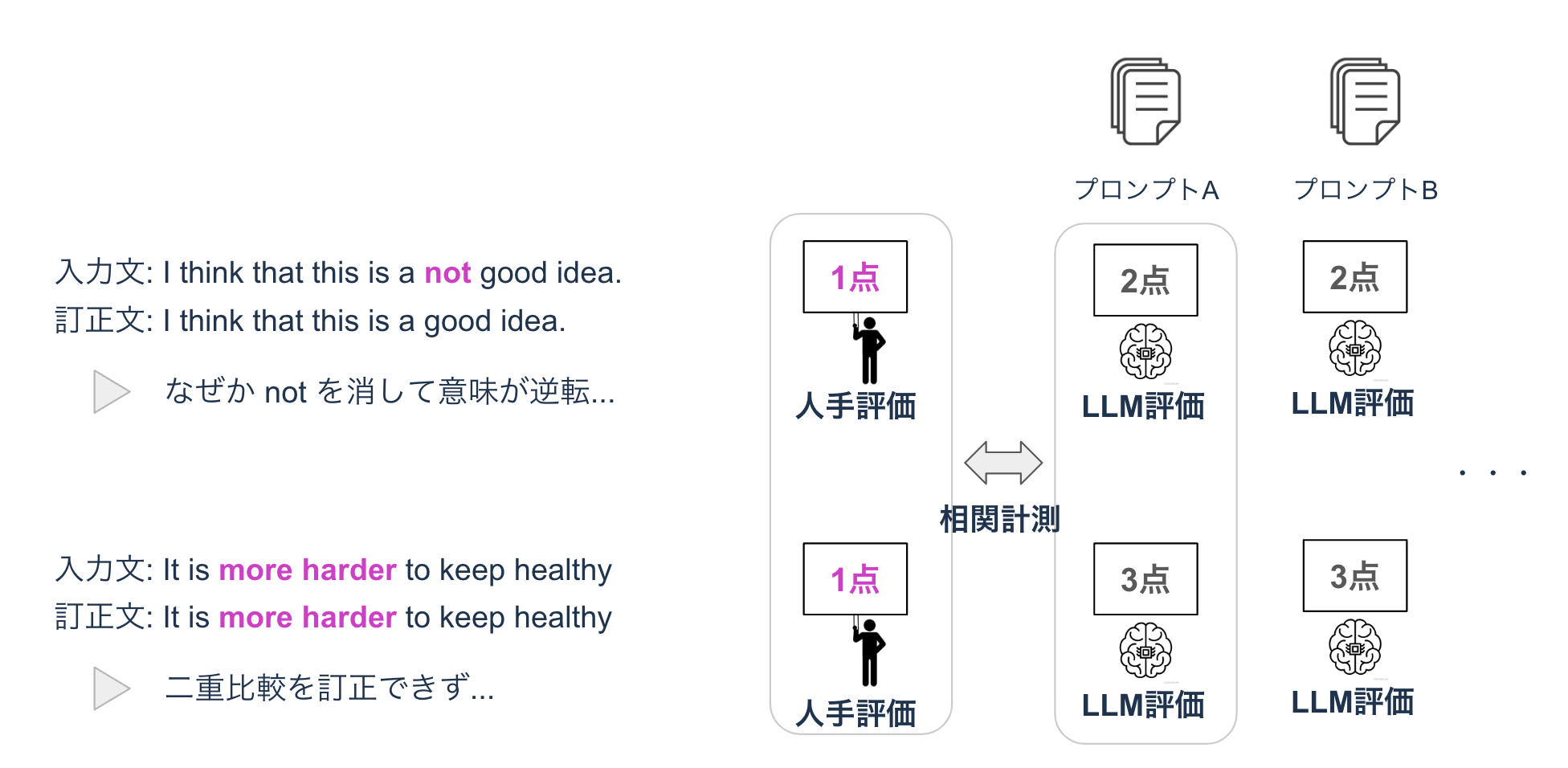
最終的に磨き上げたプロンプトの人手評価との相関は以下の表の通りになりました。
| 評価尺度 | γ (ピアソンの相関) | ρ (スピアマンの順位相関) |
|---|---|---|
| SOME | 0.379 | 0.345 |
| Gemini Flash | 0.728 | 0.733 |
| Gemini Pro | 0.669 | 0.661 |
この表から、Gemini FlashとGemini Proを用いたLLMベースの評価尺度は、既存の評価尺度SOMEと比較し、人手評価との相関が高いことがわかります。この結果を受けて、自動評価システムとして十分な信頼性を有すると判断しました。
一方で、興味深いことに、一般的に高品質な出力が得られるとされるGemini ProよりもGemini Flashの方が高い相関を示しました。この理由としては、Gemini Flashが、今回作成したメタ評価データセットの特性に合致していた可能性が考えられます。今回のメタ評価のような比較的単純なタスクにおいては、Gemini Proの高度な言語理解能力が必ずしも有利に働かなかったのかもしれません。また、今回のメタ評価データセットは比較的小規模であったため、Gemini Proの性能を最大限に引き出せなかった可能性も否定できません。
メタ評価実験を通し、LLMベースの評価尺度の信頼性が確認できました。今回は、費用の観点からGemini Flashを採用し、次章で紹介する評価フローに組み込んでいきます。
評価フロー
先述の通り、ライティングFB開発チームでは、モデル開発を担当するデータ部と英文添削の専門家が集まるコンテンツ部が協力して採点品質を担保できるよう、モデル出力の評価を一部人力で行っています。ここに新しく設計したLLMベースの自動評価を取り込んで、新しい評価フローを構築しました。このフローでは、LLM (Gemini) を活用した自動評価と、スプレッドシートによる結果共有を組み合わせることで、モデルの出力に対するシームレスな評価・連携を実現しています。具体的な流れは以下の通りです。
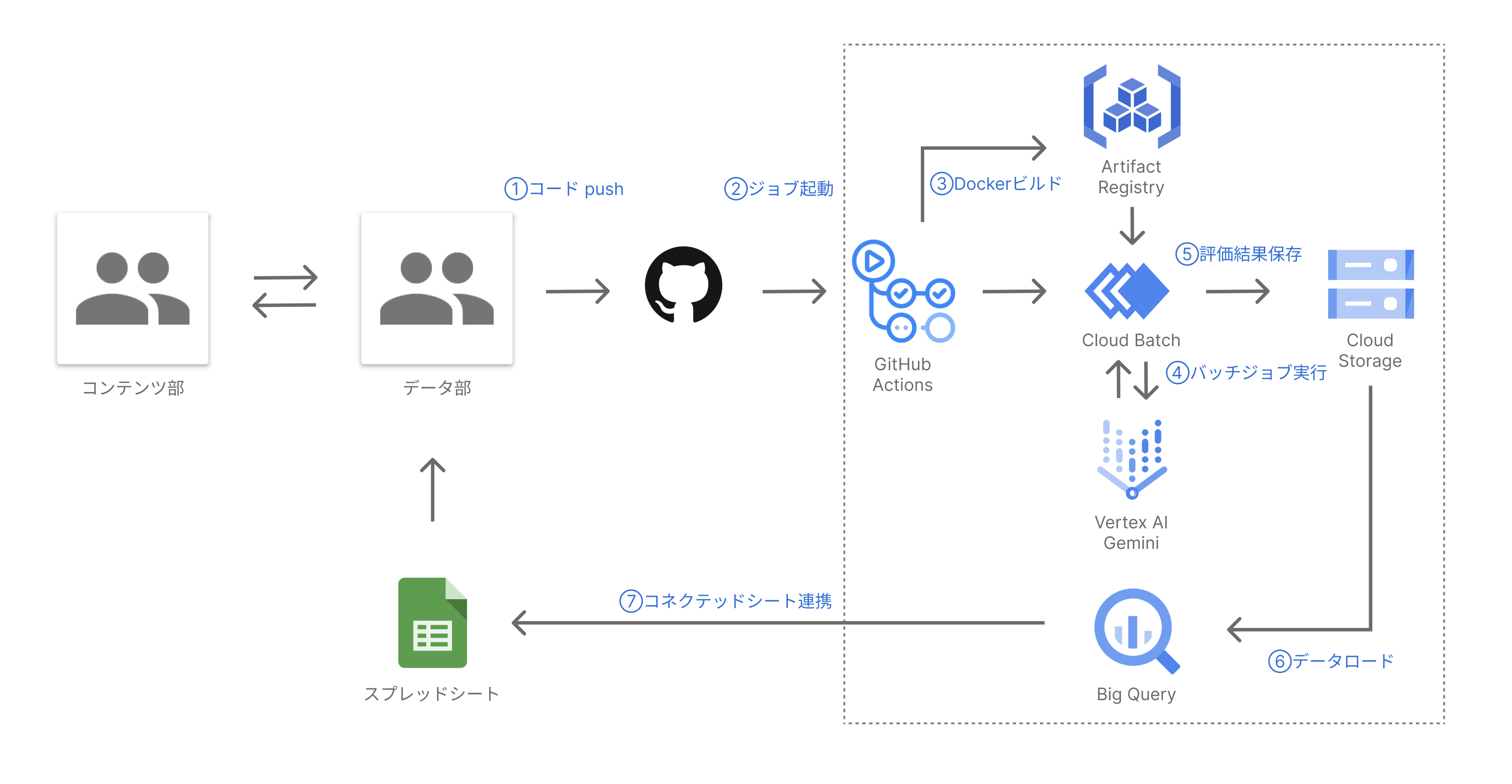
- コードpush
- データサイエンティストや機械学習エンジニアがモデルの改修を行い、GitHubにコードをpushします。
- ジョブ起動
- 作成されたPull Request(PR)に特定のラベルを付与します。このラベル付与がトリガーとなり、後続の評価ジョブが自動的に起動する仕組みになっています。
- Dockerビルド
- GitHub Actions上でDockerイメージをビルドし、Artifact Registryにプッシュします。これにより、常に最新版のモデルが評価に使用されることが保証されます。
- バッチジョブ実行
- Cloud Batchジョブが起動し、Artifact Registryから取得した最新モデルを用いて生成されたシステム訂正文を、LLM(Gemini)が評価します。
- 評価結果保存
- LLMによる評価結果はtsv形式でCloud Storageに書き込まれます。
- BigQueryへのデータロード
- Cloud Storageに保存されたtsvファイルは、BigQueryにロードされます。BigQueryを用いることで、評価結果の集計や分析を容易に行うことができます。
- コネクテッドシート連携
- BigQueryにロードされた評価結果テーブルは、スプレッドシートと連携されます。これにより、データ部だけでなくコンテンツ部も容易に評価結果を確認、共有できます。
上図は評価フローを視覚的に表したものであり、データがどのように流れていくかをわかりやすく示してみました。開発者によるコードのプッシュから、最終的にコンテンツ部がスプレッドシートで確認するまで、全てのプロセスが自動化されていることがわかるかと思います。
この刷新された評価フローにより、開発者の行った変更が瞬時にスプレッドシートに反映されるため、データ部とコンテンツ部間での迅速な情報共有が可能になりました。結果として、モデル出力に対する迅速かつ効率的な評価体制が確立され、モデル改善のサイクルを大幅に短縮することが可能となりました。 また、評価フローが自動化・標準化されたことで、人為的なミスを減らし、評価結果の信頼性向上にも繋がっています。
また、具体的な運用フローは以下の図の通りです。モデルのfinetuneを実施した際や、モデルの構造を大きく変え、出力結果への影響見込みが大きい場合は、データ部だけでなく、コンテンツ部にもレビューをもらう運用を実施しています。
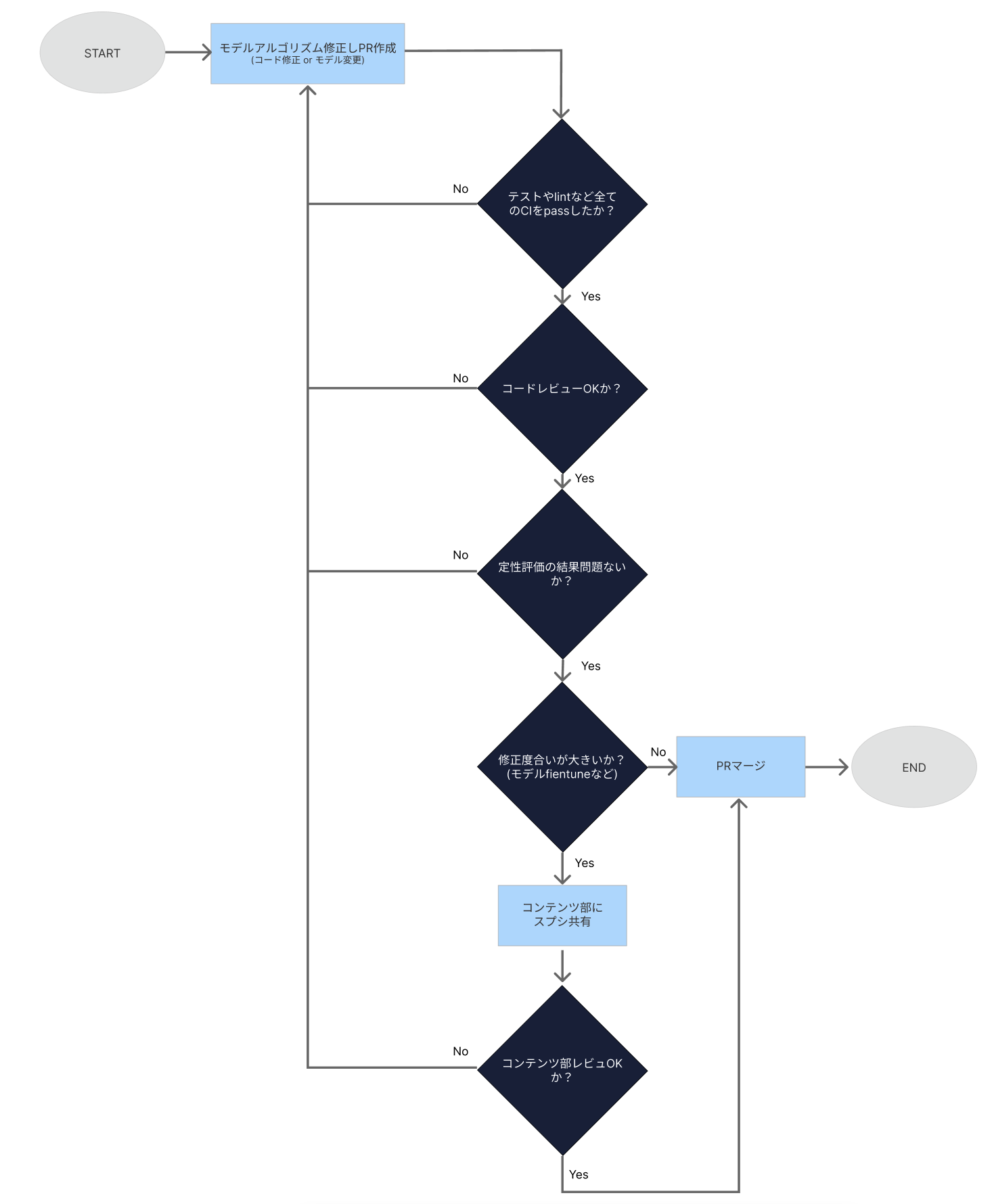
この新しい評価フローは、私たちのチームが効率的に高品質なライティングFB機能を開発・提供していく上で、非常に重要な役割を担っています。
今後やっていきたいこと
今回改善したモデルデプロイ前の評価の仕組みは、訂正文リファレンスのアノテーションが不要なため、稼働中のモデル出力の監視にも応用できると考えています。現状は日々のログを基にSOMEを用いて全体的なモニタリングを行っているのですが、より解釈性の高いLLM(Gemini)を用いた自動評価を導入することで、モデルの改善点をより的確かつ迅速に特定し、対応できるようになると思っています。一方で、今回導入したLLM評価の精度はまだ完璧ではありません。スコアがブレたり、誤った評価をすることもあり、信頼性に課題が少し残っているので、引き続き改善していこうと思っています。
スタディサプリでは、今後さらに多くの生成AIを活用したサービスをリリース予定です。これらのサービスに対しても、今回開発したLLM評価の仕組みを適用することで、高品質なサービス提供を実現していきます。
おわりに
本記事では、スタディサプリの英検エッセイ自動採点プロジェクト(ライティングFB)における、LLMを活用した評価フロー改善の紹介をしました。これまで課題となっていた定量評価の限界、評価フローの標準化の難しさ、そしてアノテーションコストの制約を、LLMを用いた自動評価とスプレッドシート連携による効率的なシステムによって改善しました。これにより、データ部とコンテンツ部間のシームレスな連携を可能にし、高速でモデルを改善する土壌を整えることができました。
スタディサプリでは、今後も生成AI技術を積極的に活用し、学習効果の向上に貢献する様々なプロダクト開発を進めていきます!
参考文献
- Christopher Bryant, Mariano Felice, and Ted Briscoe. Automatic annotation and evaluation of error types for grammatical error correction. In ACL, 2017.
- Courtney Napoles, Keisuke Sakaguchi, Matt Post, and Joel Tetreault. Ground truth for grammatical error correction metrics. In IJCNLP, 2015.
- Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. Bleu: a method for automatic evaluation of machine translation. In ACL, 2002.
- Ryoma Yoshimura, Masahiro Kaneko, Tomoyuki Kajiwara, and Mamoru Komachi. SOME: Reference-less submetrics optimized for manual evaluations of grammatical error correction. In COLING, 2020.
- Masamune Kobayashi, Masato Mita, and Mamoru Komachi. Revisiting Meta-evaluation for Grammatical Error Correction. In TACL 2024.

スタディサプリ 機械学習エンジニア
Kento Tanaka
スタディサプリのデータプロダクトやデータ基盤開発をしています。EDMと旅が好きです。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら