
はじめに
こんにちは!住まい領域アナリティクスエンジニアの半谷です。
住まい領域では、dbtを使ったデータマート開発をチーム体制で進めております。
最近では新入社員や異動者、時にはインターン生など、新規メンバーが加わる機会も増えてきており、「SQLは書けるんだけどdbtは初めてで、、、」という方にレクチャーする機会も増えてきました。新規参入者でもすぐに技術キャッチアップして即戦力として活躍してもらえるように、スムーズにオンボーディングできる環境整備をチームで進めてきました。
今回の記事では、その取り組みをご紹介します。ぜひご一読ください。
本記事は、データ推進室 Advent Calendar 2024 18日目の記事です
オンボーディングの全体像
開発経験のない新卒社員でも問題なくキャッチアップできるよう、SQLの基礎からオンボーディングしています。最終的には、後述するdbt best practices guideやチーム内で蓄積した開発Tipsまで含め習得してもらい、既存メンバーと遜色ないスキルレベルを目指してもらいます。
- SQL(今回は紹介から割愛)
- dbt core CLI
- dbt best practices guide
- dbt packages
- チーム内で過去に決めた開発指針
- その他、開発Tips
今回の記事では、その中でもdbtに関するオンボーディング内容に特化してご紹介したいと思います。
チュートリアルの整備
dbtに限らずどんな技術でも、理解を深めるためには実際に自分の手を動かして使ってみるのが効果的です。
dbtにも 公式チュートリアル は用意されてはいますが、以下のような課題がありました。
- 英語に慣れていないメンバーには心理的ハードルが高い
- dbt best practicesなど踏み込んだ内容には触れられておらず情報が不十分
そこでチーム独自のdbtチュートリアルを作成し、社内ドキュメントツール上で公開して新規メンバーに挑戦してもらっています。
項目
項目としては以下を用意し、代表的な機能を一通り習得できるようにしています。
- 環境構築
- とりあえず、dbtを動かしてみる
- staging層を実装する
- Jinjaを使って楽に実装する
- パッケージを追加する
- テストを実装する
- ドキュメントを作成する
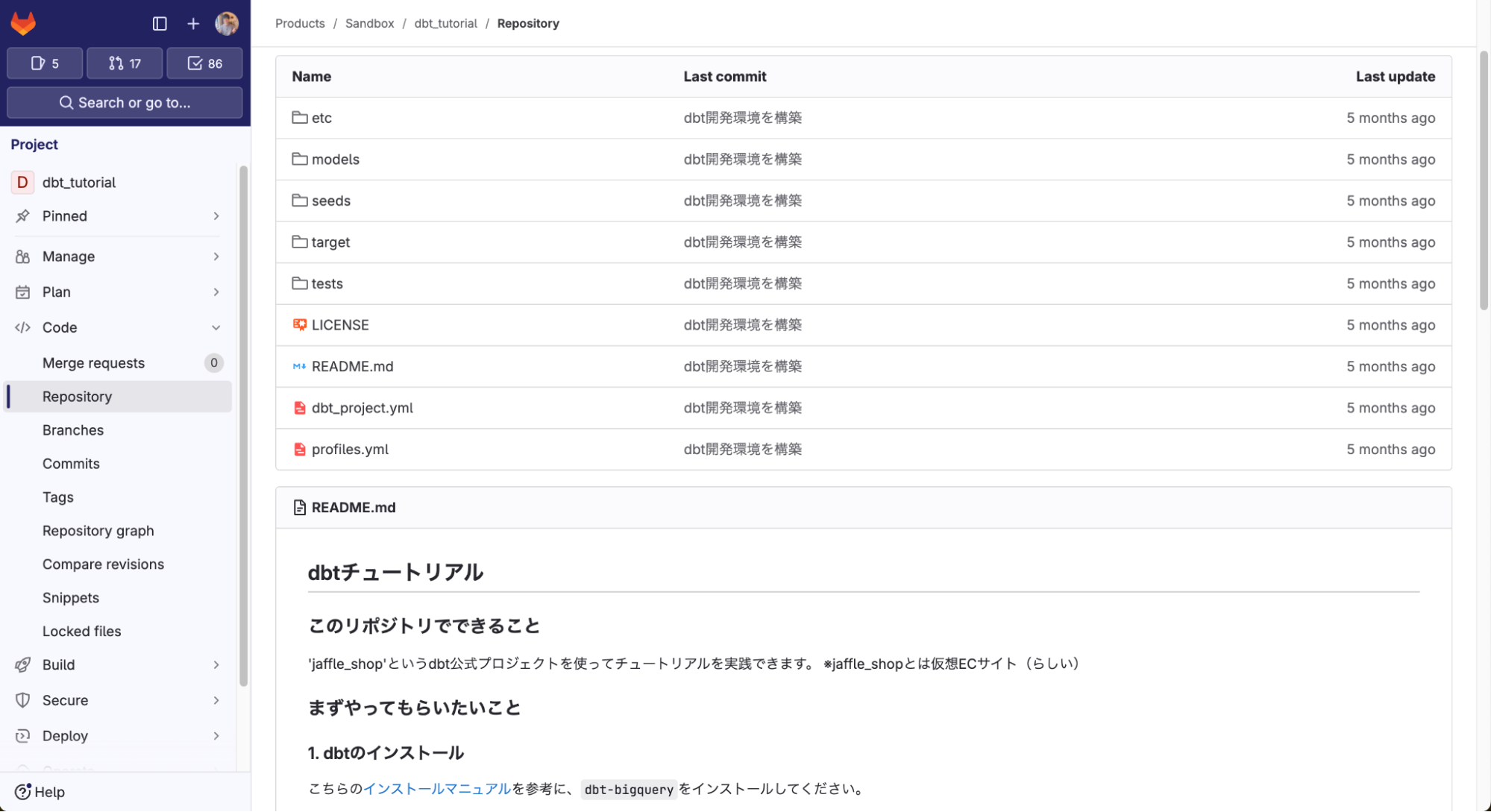
環境構築
初学者の最初の躓きポイントとして環境構築があります。
スムーズに環境構築ができるよう、サンプルコードやサンプルデータ、BigQueryへの接続設定ファイルなど、コマンド実行に最低限必要なファイル群を全て社内GitLab上にリポジトリとして用意しています。
このリポジトリを各自ローカルPCにクローンすれば誰でもすぐにdbtを試すことができます。
「ただのチュートリアル」で終わらせないために
チュートリアルの各項目で実践してもらう内容は、基本的にはdbt公式チュートリアルと同じように、架空ECサイトを題材としたデータ加工です。
しかし「とりあえず一通りのdbtコマンドは触ったことある!」というだけでは実際のマート開発現場では不十分なので、公式チュートリアルの内容+αの情報を盛り込んでいます。
dbt best practices guide
dbtを使ってマート開発する際、「dbt modelってどう階層分けすれば良いんだっけ?」「dbt model名称とかカラム名称ってどう決めたら良いんだっけ?」など迷うシーンが度々あります。
そんな時の手引きとして、dbt公式が best practices guides を用意してくれているので、特に重要な内容をピックアップして掲載しています。 例えば「3. staging層を実装する」では、そもそもなぜstaging層を用意すべきかをbest practices guidesを紐解きながら解説しています。
# なぜstagingモデルをつくるのか
## データソース側の変更を吸収できるので、保守性が上がる
稀に、データソース側でカラム名称などが変更されることがあります。
例えばraw_paymentsテーブルのカラムamountがpayment_amountに変わるとか。
そんな時、もしデータマート上の各処理が直接ソーステーブルを参照していると、
amountを参照していた全箇所を修正する必要があります。
一方で、もしデータソースと一対一対応でstagingモデルを作成していれば、
カラム名の修正対応をする箇所はstg_payments一つで済みます。
データソース側の変化にRobustになる上でも、stagingモデルを作成しておきましょう!

dbt packages
dbtには開発を効率化するパッケージが様々用意されており、特に使用頻度の高いものを掲載しています。
例えば「6. テストを実装する」では、コード自動生成パッケージであるcodegenを使ってdbt yamlを楽に作成する方法を紹介しています。
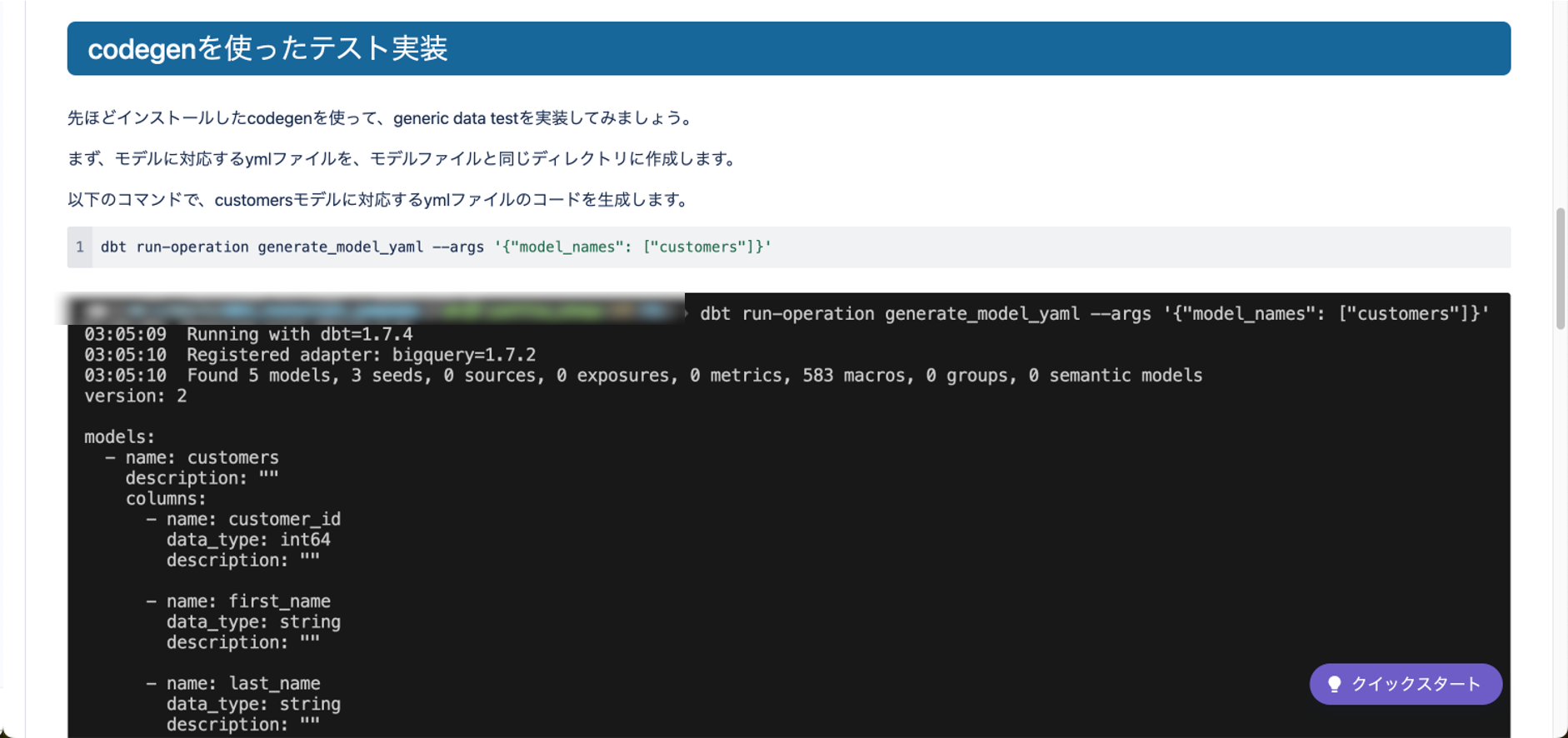
# codegenを使ったテスト実装
先ほどインストールしたcodegenを使って、generic data testを実装してみましょう。
まず、モデルに対応するymlファイルを、モデルファイルと同じディレクトリに作成します。
以下のコマンドで、customersモデルに対応するymlファイルのコードを生成します。
> dbt run-operation generate_model_yaml --args '{"model_names": ["customers"]}'
その他、Tips
その他にも、普段開発している中で気づいたTipsは随時追記し、知見として蓄積しています。
例えば「7. ドキュメントを作成する」では、
- dbt docsを静的htmlとして出力する方法
- dbt開発に便利なVScode拡張機能
など、知っていると地味に役立つコンテンツを載せています。
# Tips:ドキュメントを静的htmlで生成する方法
以下のコマンドで、静的htmlファイルとしてドキュメントを出力できます。
> dbt docs generate --static
ファイルとして他人にドキュメントを渡したい時や、GCS上などでホストしたい時に便利です。
開発指針のドキュメント化
一通りのチュートリアルを完了して「さあ本格的に開発着手するぞ!」となっても、「このdbtモデルにどんな名前を付けたら良いかな?」「どんなテストを実装したら良いかな?」など迷うシーンは多々あります。
そこで、チュートリアルにて取り上げているdbt best practices guideに加えて、チーム内で決めた開発指針をGitLabのwiki上にドキュメント化しています。途中からチームに参加したメンバーも「他の人はこんな時どうしているんだろう?」を確認することができます。
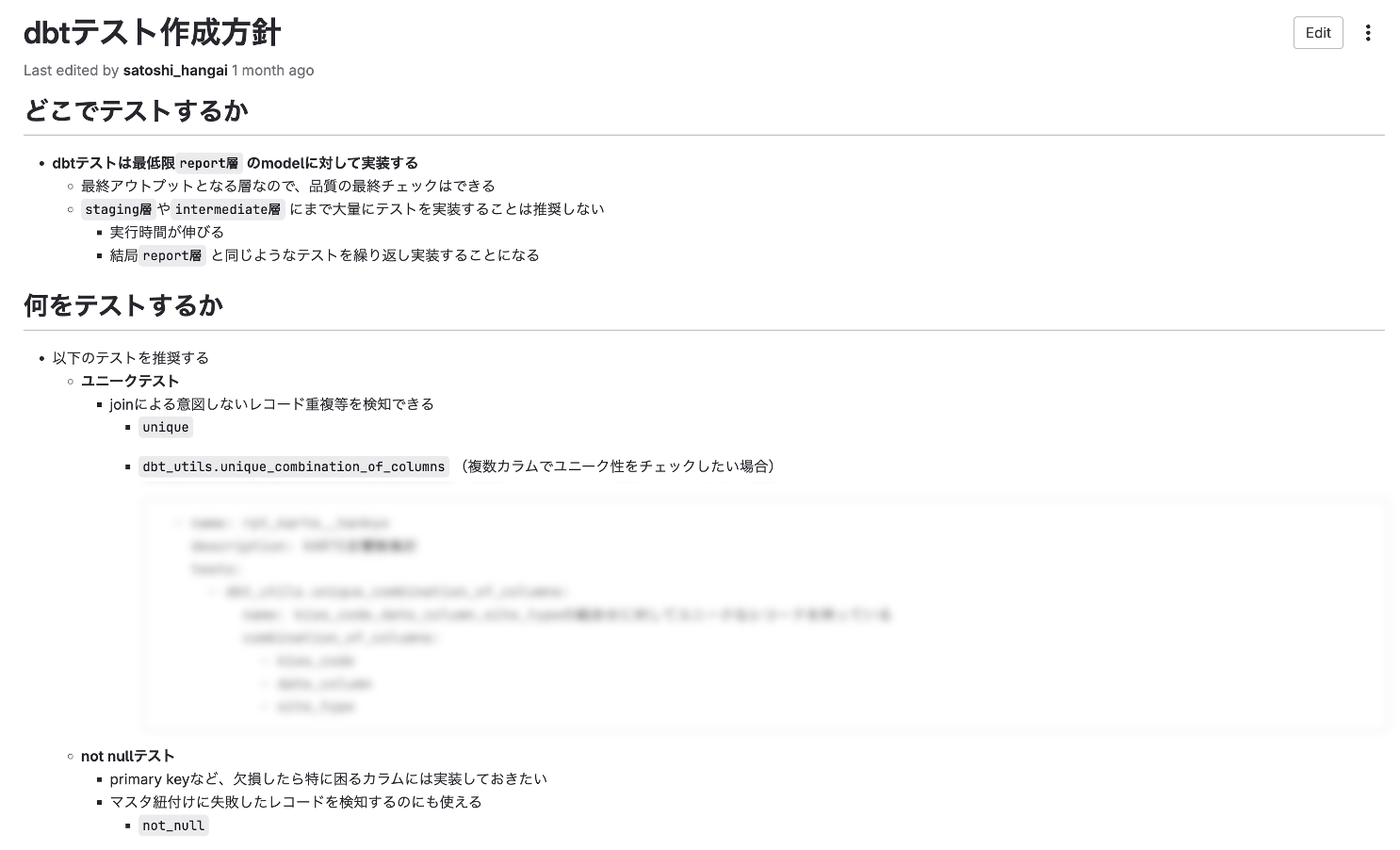
# dbtテスト作成方針
以下のテストを推奨する
* ユニークテスト
* joinによる意図しないレコード重複等を検知できる
* unique
* dbt_utils.unique_combination_of_columns(複数カラムでユニーク性をチェック)
* not nullテスト
* primary keyなど、欠損したら特に困るカラムには実装しておきたい
* マスタ紐付けに失敗したレコードを検知するのにも使える
* not null
最後に
今回ご紹介した取り組みによって、新規メンバーのオンボーディングにかかる時間・負担が大幅に削減されたことを実感しています。最近の事例では、これまで開発経験のないインターン生が半日もかけずチュートリアルに取り組んだだけで、staging/intermediate/mart層を意識したデータマートを作成してくれました。 開発の中で得られる知見を継続的にdocs化するなど、日々の地道な積み重ねがチームの資産に繋がっていくのだと実感しました。

アナリティクスエンジニア
半谷 聡
リクルート入社2年目。住まい領域でデータマート開発など担当
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


