
はじめに
こんにちは、atmaCup#16 リクルート事務局の大磯・荒居・中間・羽鳥・阿内です。
2023年12月にatma株式会社さんと共同で
atmaCup#16 in collaboration with RECRUIT
を開催し、その表彰式&振り返りを翌月1月に実施しました。
今回の記事では、データコンペティション(以下「コンペ」)開催に至るまでの経緯や準備内容、当日の様子等を6つのセクションに分けてご紹介します。
どのようにコンペが開催されたのか、気になる方はぜひご一読ください!

1. 開催のきっかけ
当社では、データ推進室で一緒に働いていただけるメンバーを新卒・中途問わず積極採用中です。
昨今の採用競争激化の中、当社データサイエンス/機械学習エンジニアリングの魅力を外部に知ってもらうために採用ブランディングの重要性を認識しており、その一案として当社が保持している膨大なデータを使用したコンペ開催はどうか?という話になりました(過去にリクルートホールディングスとしてKaggle Competitionを2度実施したことがあります。2015年実施詳細は
こちら
、2018年実施詳細は
こちら
)。
これを受け、当社にいるKaggle GrandmasterやMasterを保持するメンバーと人事担当を中心に、コンペ開催に向けての準備が始動しました。
今回は最終的に国内で開催することに決定し、atma株式会社さん主催のatmaCupという形式で実施させていただくことにしました。
2. コンペのテーマ選定
まず最初に検討したのが、コンペの題材についてです。
ここでは、どのような観点・プロセスで題材選定を行なったかについて紹介していきます。
2-1. 題材の決め方
今回運営に関わるデータサイエンティストたちはそれぞれ担当するサービスが異なっていたため、各自題材になりそうなアイデアを検討後持ち寄るという形式をとりました。
その後、出揃ったアイデアに対して
- 題材として面白いか
- サービスに親近感があるか、ビジネス課題がわかりやすいか
- タスクとして面白いか
- タスクが単純すぎないか、工夫の余地があるか
- データを用意する難易度はどうか
等の観点で意見を出し合い、最終的に残った案の中から投票で題材を確定させました。

今回選定した「じゃらんの宿レコメンド」は、上記の観点の中でも、サービスとしての親近感、タスクとしての面白さの点で最多得票を獲得しました。
2-2. タスクの詳細設計
題材が決まったのち、タスクの詳細設計に入りました。この段階ではコンペの大枠となる以下について確定させます。
- trainとtestの分割方法
- public test とprivate testの分割方法
- 評価指標
- 提出方法
- 外部データの利用可否
各項目の判断ポイントは以下のとおりです。
- trainとtestの分割方法
- 採用した案
- testデータはtrainよりも時系列的に後になるように選定
- 判断理由
- 今回は参加しやすさ(※)を考えtestデータも配布する方式を採用したので、未来のデータについての正解ラベルが利用可能な状態になることを避けるため
※ 一般的にtestデータを配布せず推論用コードを提出する方式よりも、配布したtestデータに対して予測値を付与したCSVを提出する形式の方がハードルが低い
- 今回は参加しやすさ(※)を考えtestデータも配布する方式を採用したので、未来のデータについての正解ラベルが利用可能な状態になることを避けるため
- 採用した案
- public testとprivate testの分割方法
- 採用した案
- testデータをrandom splitする方式を選定
- 採用した案
- 判断理由
- publicとprivateの時系列を前後にする方式は、shake(※)の要素を強めるため
- 一定public leaderboardに信頼性があるコンペの方が参加者が楽しめると考えたため
※ shake : public leaderboard(暫定順位表)とprivate leaderboard(最終順位表)が大きく入れ替わること
- 評価指標
- 採用した案
- Map@10
- 判断理由
- レコメンドタスクで定番であり、複数コンペで実績があるため採用
- 採用した案
- 外部データ利用
- 採用した案
- 外部データ利用は禁止とした。ただし重みが公開されている学習済みモデルは利用可能。LLMのような重みが公開されている学習済みモデルの利用は禁止だが、ChatGPT等にアドバイスをもらう行為は可能とした。
- 判断理由
- 他コンペのレギュレーションを参考に判断した
- 採用した案
上記のような大枠のルールを事前に決め、その後実際のデータ準備・検証を経てマイナーチェンジしていく方針にしました。
なおコンペに用いたデータは、個人情報保護のための加工を行い、法令や規約上利用が可能な範囲に限定しています。元データの変形を最小限に留め、ただし個人情報を保護する加工というのが実はかなり難関ポイントかつコンペの面白さを左右するため、ここには多くの議論の時間を費やしました。
3. データ検証
続いて、コンペデータに問題がないか検証した内容について紹介します。
まず当社でやったこととしては、①想定通りのデータかどうかの確認 と②ベースライン構築です。
前者に関して、コンペデータは公開にあたり匿名化などの必要な処理が加えられています。
まずは、コンペデータが要件通り(IDがtrainとtestで重複しないか、匿名化のためのサンプリング条件は満たしているか等)のデータになっていることを確認しました。
次に、ベースラインを組むことでコンペが成り立ちそうかを確認しました。
この際に、学習データの情報のみでベースラインを組んでおり、テストデータの情報も使ったベースラインは構築していませんでした(上位解法ではテストデータの情報を上手く活用することがポイントとなっていました)。
具体的には、まずrerankerモデルを用いないベースラインとして以下について検証しました。
- 地域ごとの人気宿順ルールベース
- Co-visitation Matrix
- Item2vec
次に上記により生成された候補について、rerankerを学習した時に精度が向上するかを検証しました。結果として、rerankerによる精度向上に加え候補数を増やすほど精度向上することが確認できたため、コンペとして成り立つと結論付けました。
最後にatma株式会社の取締役の山口さんには当社で作成したベースラインをお渡しし、検証を行っていただきました。
具体的には、rerankerにおける特徴量の作り込みによる精度向上や、publicとprivateのスコア相関などを確認していただきました。
山口さん自身が問題に向き合った感想として、シンプルかつ分析に慣れている人もとても楽しめそうというところで、データ検証を終えました。
4. 12月のコンペの様子
2023年12月8日からいよいよコンペが始まりました。ここでは節目節目のイベントについて紹介しつつ、コンペの模様を振り返ってみたいと思います。
2023年12月8日17:30からatmaCup#16 in collaboration with RECRUITの開会式がスタートしました。
はじめに山口さんからatma株式会社および atmaCupの説明をしていただき、当社からは問題設計にかかわったスタッフである阿内・荒居の二人がコンペの題材を説明しました。
今回のコンペのキーとなったデータの加工方法についてもここで説明がなされています。

実際の配信の様子は以下のアーカイブから確認することができます。
また、山口さんから初心者向け講座を2回にわたり開講していただきました。
講座では、データの読み込みの方法から、その時点で話題となっているdiscussionの解説、候補集合の作り方とrerankerの学習・評価の方法などを解説していただきました。
今回のコンペのテーマが推薦タスクという若干難易度が高いものだったために、この初心者講座の存在はかなり大きかったようです。
実際に懇親会などで参加者の方と話した際には、初心者講座のお陰でsubmitまでいけましたという声を聞くことができました。
実際の配信の様子は以下のアーカイブから確認することができます。
- #atmaCup 16 in collaboration with RECRUIT: 第1回初心者向け講座
- #atmaCup 16 in collaboration with RECRUIT: 第2回初心者向け講座
コンペ開催期間中はDiscussionも活発に投稿されていました。
今回はデータの作成方法がやや特殊であったこともあり、その性質について参加者間で活発な議論が行われていました。
- train_logにおいてsessionの最後のseq_noと途中のseq_noの差分を取ったときに奇数番目の宿が選ばれやすい
- 最終閲覧の宿に対する予約された宿の件数の上位から予測値を選ぶ(LB: 0.4199)
また、GNNやTwo-Towerといった難易度の高い手法もベースラインとして公開されていました。
激戦だったコンペも無事に終わり、2023年12月17日に閉会式と結果発表が行われました。
最終的にはチーム数が666、submissionが5294と大盛況と言えるコンペになったようです。
閉会式の途中でリアルタイムに計算が行われ、private score及び入賞者が発表されました。
わずか0.0001ポイントの差で優勝を獲得したのはkamiさんでした。
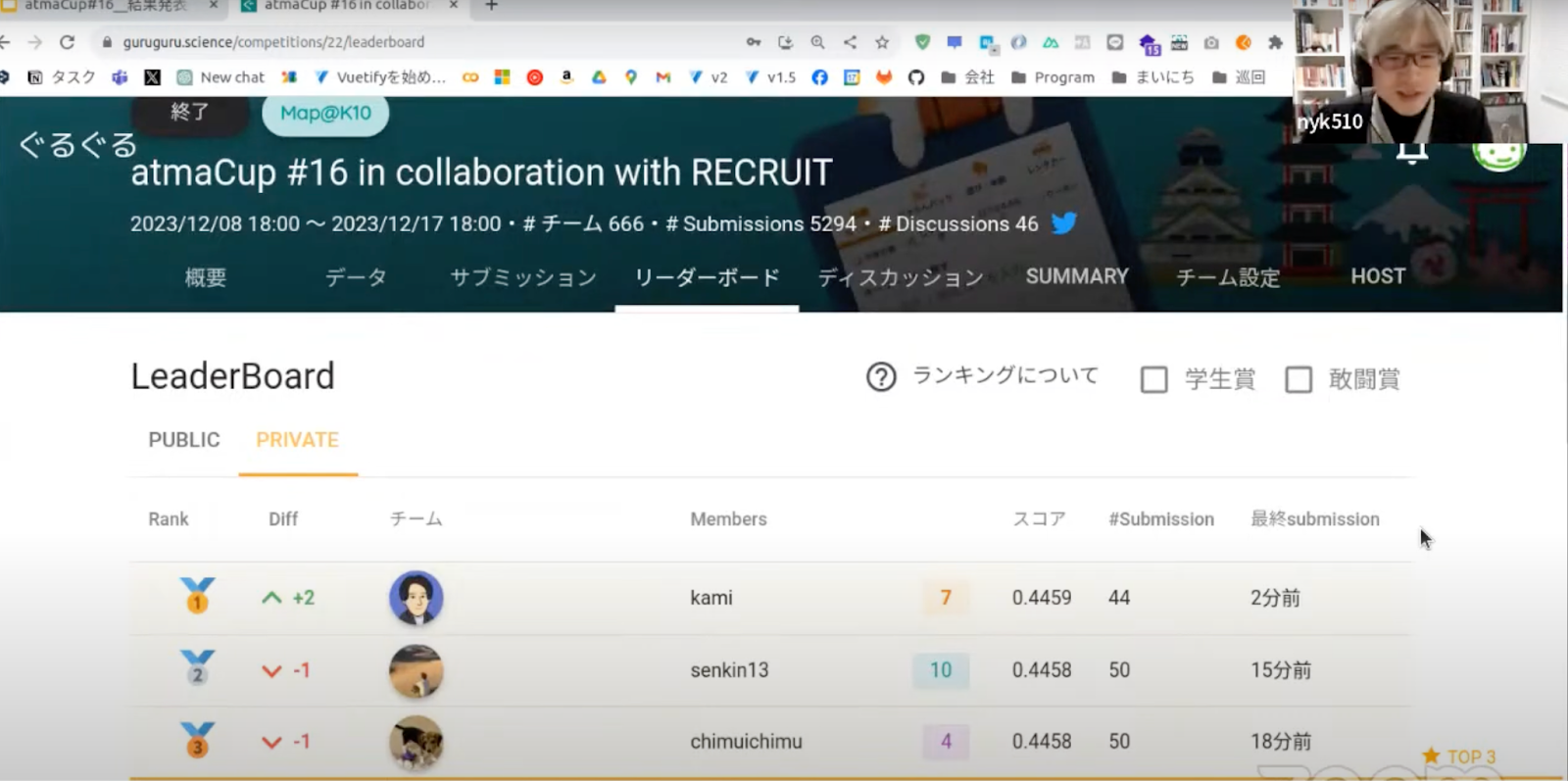
また今回のコンペでは特に上位のスコアが僅差で競り合っており、どのsubを最終提出するかによってもかなり順位が変動したようでした。
実際の配信の様子は以下のアーカイブから確認することができます。
#atmaCup 16 in collaboration with RECRUIT: 閉会式
5. 表彰式&振り返り会
今回は国内開催コンペだったこともあり、翌月1月20日には入賞された方を実際にリクルートの本社オフィスにお招きし表彰式&振り返り会を開催しました。
オフィス41階にある半円形の大ホールをメインの会場とし、Zoomでのオンライン配信は別途配信会社さんにご協力いただきました。
上位入賞の方にはatma株式会社さんにメダルを作成いただき、当社は参加者景品としてパーカーやサコッシュ、ステッカーを作成しました(パーカーの色味やデザインには問題設計にかかわったスタッフの意見も反映されています)。

表彰式&振り返り会ではatma株式会社の山口さんと当社社員の荒居の司会の進行のもと、コンペサマリに始まり、メダル贈呈、総合優勝1-3位の方の解法プレゼン、参加者の方によるLTという流れになりました。
解法プレゼン<は皆さん非常に完成度が高く、参加者からの質問も多数寄せられ、予定時間を延長する程の大盛況となりました!
その後オフィスにいらしていただいた方向けに5グループに分かれてオフィスツアーを実施し、最後は夜景が見えるフロアで懇親会となりました。
懇親会ではすし職人の握るお寿司を堪能しつつ立食形式で自由に懇親いただきました。
改めましてオフィスにお越しいただいた皆様、オンライン視聴いただいた皆様、ありがとうございました!
当日の表彰式&振り返り会は以下のアーカイブから確認することができます。
atmaCup #16 in collabolation with RECRUIT 表彰式&振り返り会
6. 最後に
参加者の方には事後アンケートにご協力いただきましたが、今回のコンペや表彰式&振り返り会を楽しんだというお声も多く、事務局一同大変嬉しく思っています。
また今回atmaCupで共催させていただくのは初の試みとなりましたが、無事に終えられたのもatma株式会社さんのご協力あってこそですので、改めて御礼申し上げます。
またレコメンドコンペとしたことで画像コンペに比べると初心者の方にはややハードルの高いコンペになったかもしれませんが、解き応えがあったという声もいただきました。
今回コンペを開催してみて気が付いた点を活かしながら、今後もリクルートのデータを使ったデータサイエンス/機械学習コンペを開催できればと思っています。(少し時間はかかるかもしれませんが)どうぞご期待ください!
なお、atma株式会社の山口さんに書いていただいた今回のatmaCupのブログ記事は こちら になりますので、ぜひご覧ください。
※以下、表彰式&振り返り会の様子を写真でご覧ください!



実際にデータ推進室メンバーが働いている執務フロアもご覧いただきました




なお、2024年2月21日には本コンペに関わったメンバーも登壇するRECRUIT TECH CONFERENCE 2024を実施します!
オンライン配信/無料ですので、ご興味ある方はぜひ
こちら
よりお申し込みください。
一緒に働きませんか?
当社では、様々な職種のエンジニアを新卒・中途ともに募集しております。ご興味のある方は、以下の採用ページをご覧ください。

人事
Haruka Oiso
HRBP、採用ブランディングなどを担当してます

機械学習エンジニア
Hidehisa Arai
好きな技術は深層学習、得意料理はポキサラダです。

レコメンドシステムの改善を担当
Yasufumi Nakama
Kaggle Competitions & Notebooks Grandmaster。

レコメンドシステムの改善を担当
Tosei Hatori
kaggleとスマブラSPが好きです

グループマネージャー
Hiromu Auchi
オセロとギターとkaggleが好きです
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


