
はじめに
突然ですが、「基盤モデル」または英語で「foundation model」という言葉を聞いたことはあるでしょうか?基盤モデルとは、「大量・多様なデータから高い汎化性能を獲得したAI」のことで、2021年にスタンフォード大学のワーキンググループによって命名されました。基盤モデルは単体で従来のAIには解けなかった多様なタスクを解けることから、「AIにパラダイムシフトをもたらす」などとして研究者の間で注目を集めています。
本記事では、この「基盤モデル」について、執筆時点での定義、性質、具体例、課題と将来の展望をまとめたいと思います。
基盤モデルとは
改めて「基盤モデルとは何か」を説明しましょう。基盤モデルを命名した論文" On the Opportunities and Risks of Foundation Models “では、次のように定義されています。
A foundation model is any model that is trained on broad data at scale and can be adapted (e.g., fine-tuned) to a wide range of downstream tasks
すなわち、基盤モデルとは「大量かつ多様なデータで訓練され、多様な下流タスクに適応(ファインチューニングなど)できるモデル」のことです。具体例としては、大量のテキストデータで学習することで感情分析や質問応答など多数のタスクで使えるようになった BERT や、加えて翻訳などの生成系タスクもできる GPT-3 、大量の画像・説明文ペアで学習することでゼロショット画像分類ができるようになった CLIP などが挙げられます。
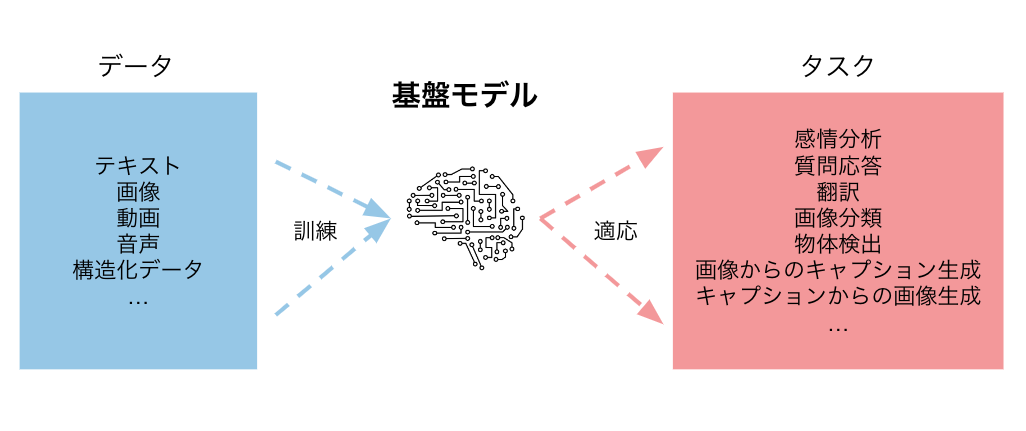
基盤モデルは、ただ大量のデータで学習しただけのAIとは質的に異なります。従来のAIといえば、解きたいタスクごとにデータセットを用意(しばしば人力のラベリングを伴う)し、適切なアーキテクチャのモデルを設計・訓練する必要があり、その開発・運用コストが実用上の制約となることが多くありました。また、目的のタスクに特化させたモデルは分布外データに対する予測性能が著しく低くなる傾向があり、この問題も実用化を妨げていました。これに対し、基盤モデルでは、タスクごとに集めるデータは少量で十分で、目的のタスクに特化させないため分布外データに対する予測性能も頑健です。特に、前述のGPT-3の登場以降、タスクの内容を自然言語で記述して入力に含めることで、オープンエンドなタスクに数例の訓練サンプルで適応(in-context learning)できるモデルが増えています。
| タスクごとに必要なデータの量 | タスクごとのモデリング | 分布外データへの頑健性 | |
|---|---|---|---|
| 従来のAI | 大 | 個別に実施 | 弱い |
| 基盤モデル | 小 | 適応するだけ | 強い |
基盤モデルはその性能について、ある重要な経験則が知られています。それはスケーリング則(scaling law)です。スケーリング則によると、基盤モデルの性能は、以下の3変数のべき乗則に従います1:
- 訓練ステップ数
- データセットのサイズ
- パラメータ数
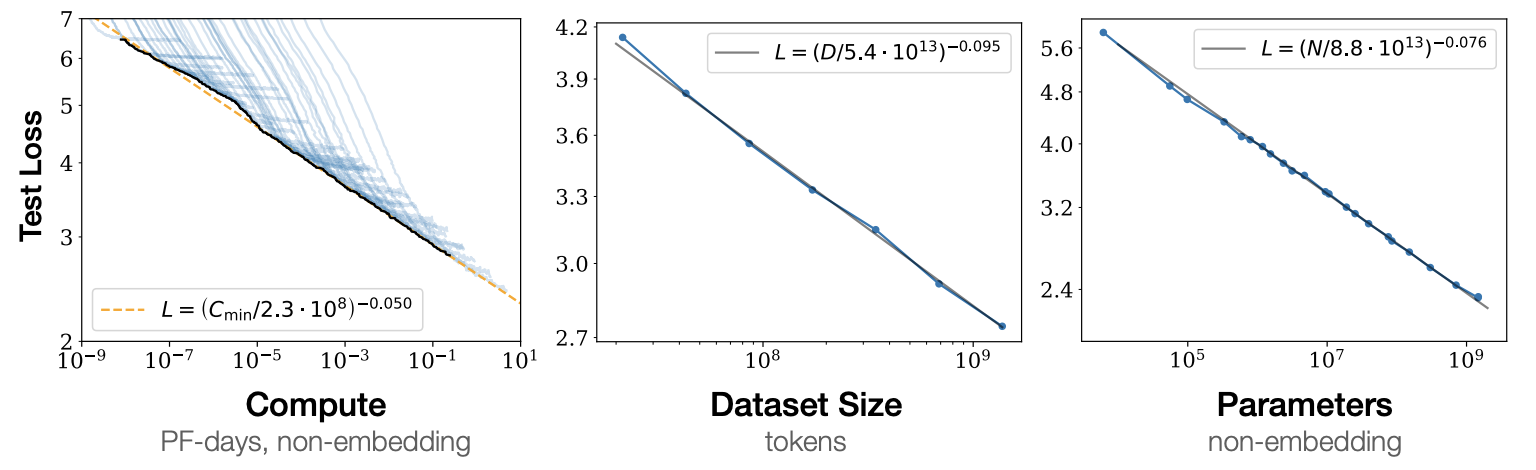
つまり、これら3変数を大きくすればするほど基盤モデルの性能が向上するということです。これは最高性能のAIを開発する上で重要な指針となり、研究機関は競って深層モデルを大規模化しています。例えば、言語モデルのパラメータ数は1年ごとに10倍のペースで伸びています。
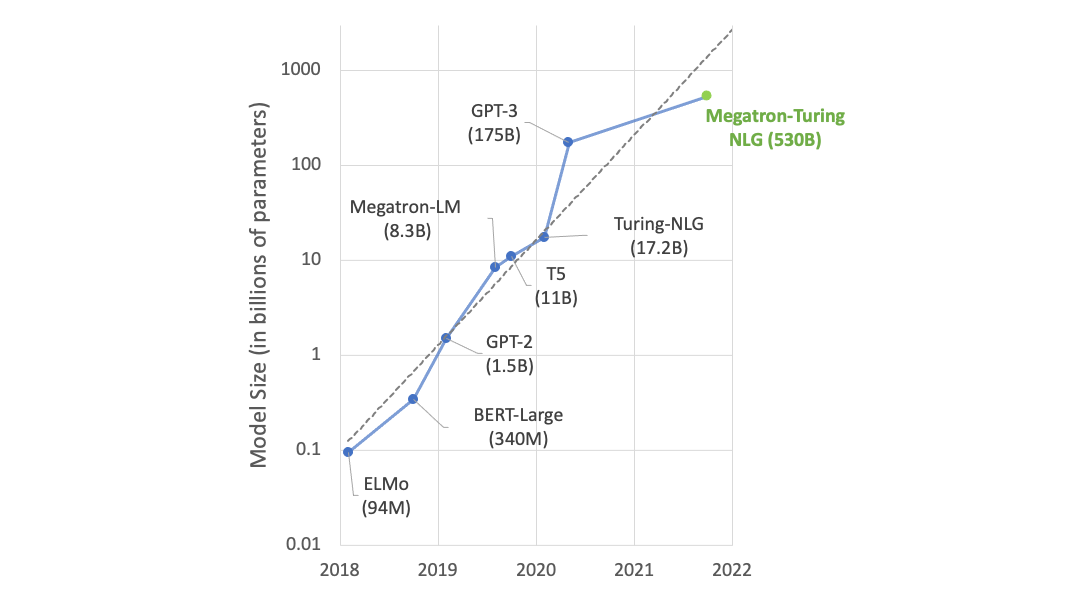
もちろん、それに応じて性能も向上しています。それまでに解けなかったタスクがモデルを大きくするだけで解けてしまうということは、最近では珍しくありません。2022年5月に発表された言語モデル「PaLM」のフルモデルは BIG-bench で初めて人間の平均スコアを超えました。
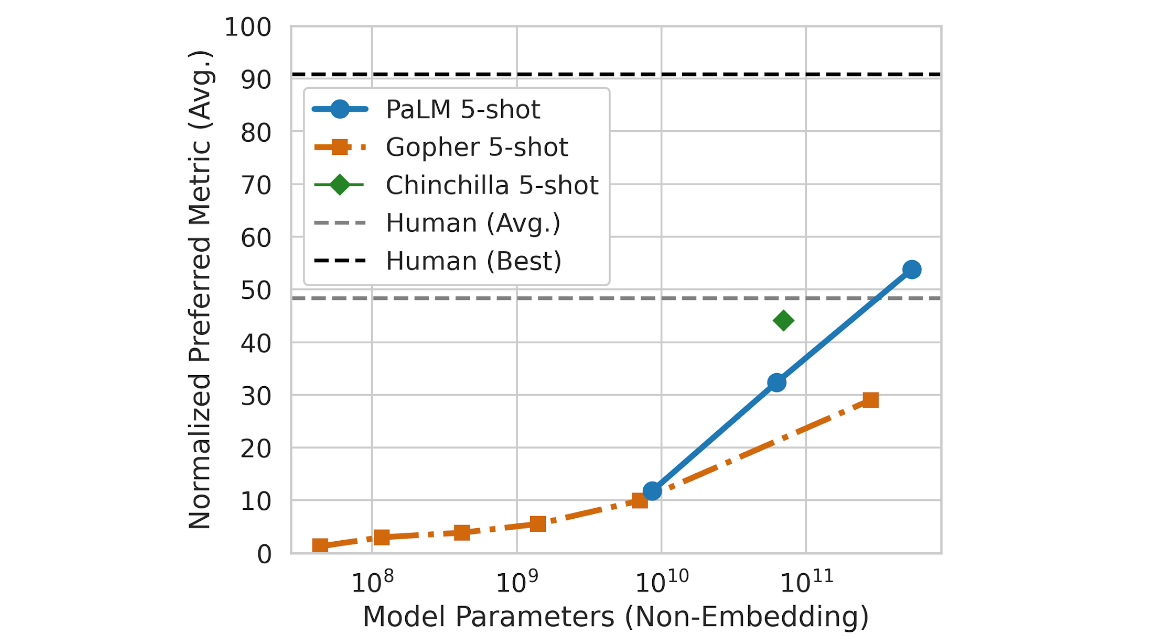
そして2022年6月現在、スケーリング則の適用限界は未だ見つかっていません。このように、AI開発のパラダイムは「タスクごとに専用のモデルを開発する」から「最強のモデルを1つ作って使い回す」へと移りつつあります。「最強のモデル」は具体的にどのようなことができるのでしょうか?次の節では、代表的な基盤モデルをいくつか紹介します。
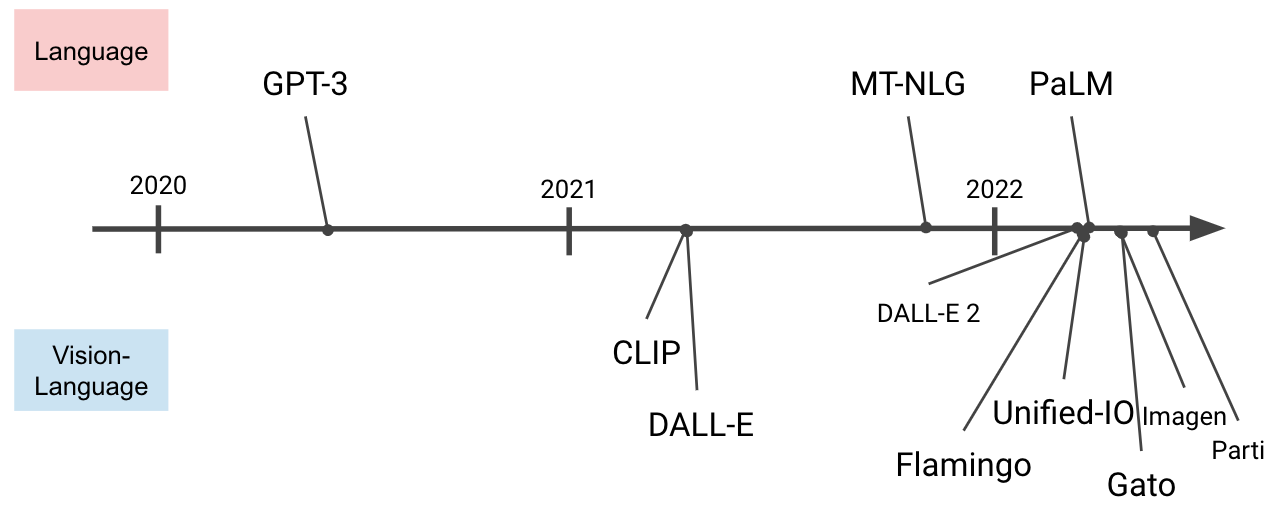
代表的なモデル
基盤モデルは大まかに「言語(language)」を扱うものと「視覚・言語(vision and language)」を扱うものとに分けられます。視覚(vision)は画像と動画の両方を指す言葉です。
ちなみに、視覚単体の基盤モデルとしては、ImageNetのクラス分類で訓練された ConvNeXt や自己教師学習で訓練された DINO などが挙げられます。しかし、視覚単体のモデルは「自然言語によるタスクの説明」を受け取れないため、GPT-3などのように「単一のモデル、追加の学習なしでオープンエンドなタスクを解ける」ようにはできません。言語を扱える基盤モデルと比較すると制約がかなり大きいので、本記事ではこれ以上掘り下げません。
以降、いくつかの代表的な基盤モデルを「言語」と「視覚・言語」に分けて紹介します。本記事では「何ができるか」に軸を置いて紹介するので、詳細に関心をお持ちになった方は論文などをご参照いただくようお願いいたします。
言語
2018年に発表された大規模言語モデル「 BERT 」は、基盤モデル(当時この言葉はありませんでしたが)にとって重要なマイルストーンでした。BERTは下流タスクでのファインチューニングを必要としますが、その汎化性能の高さから産業界や別の研究分野でも活用され、大規模言語モデルへの注目を一挙に集めました。
2020年に登場した GPT-3 はBERTよりも3桁多いパラメータを持ち、前述のin-context learningにより多様なタスクを解くことで人々を驚かせました。in-context learningでは、モデルに入力文だけでなく「タスクの説明」と「いくつかの入出力例」をセットにして渡します。下図は、英仏翻訳のタスクで"cheese"という単語について予測させるときの例です。

感情分析や文書要約がしたければ、タスクの説明の部分をそのように変更するだけです。訓練データを集める必要はありません。このような仕組みで、GPT-3は文章生成、翻訳、文書分類、質問応答などから果ては四則演算や簡単なプログラミングまでをこなしてしまいます。
GPT-3のようなモデルを所与とすると、予測精度は訓練データでも特徴量でもモデルでもなく、モデルに与える説明文や入出力例によって決まってきます。予測精度を上げるためには、モデルにとってわかりやすい説明文や入出力例を与えることが大事だということです。そのような工夫のことを、(特徴量エンジニアリングに対して)「プロンプトエンジニアリング(prompt engineering)」と呼びます。
2022年に登場した PaLM ではできることの範囲がさらに広がり、因果関係や常識の理解を要する難しいタスクも解けるようになりました。さらに、入出力の例を示す際に思考過程を含めることで、それまでは解けなかった問題を解けるようになるということも報告され、その人間らしい挙動に注目が集まっています。

視覚・言語
視覚・言語を扱う基盤モデルは、インターフェイス(入出力が視覚・言語のどちらに対応しているか)によって分類することができます。個々のモデルの紹介に入る前に、以下に分類表を示します。次の段落以降はこの表を見ながら読んでいただくとわかりやすいかと思います。
| 名前 | 入力 | 出力 |
|---|---|---|
| CLIP | 視覚、言語 | ベクトル |
| DALL·E | 言語 | 視覚 |
| Imagen | 言語 | 視覚 |
| Parti | 言語 | 視覚 |
| Flamingo | 視覚、言語 | 言語 |
| Unified-IO | 視覚、言語 | 視覚、言語 |
| Gato | 視覚、言語、数値 | 視覚、言語、数値 |
さて、視覚・言語を扱う基盤モデルとしては、2021年の CLIP がブレイクスルーでした。CLIPはテキストと画像を同じ特徴空間に写像する2つのエンコーダからなります。CLIPを使うと、次のようにして任意の画像分類問題を追加の学習なしで解くことができます。まず、各候補クラスを文章の形式(例:「犬の写真」)にした後、テキストエンコーダに入力します。次に、分類したい画像を画像エンコーダに入力します。最後に、画像から得られたベクトルと候補クラスたちから得られた複数のベクトルとのコサイン類似度を計算し、最も類似度が高いクラスを出力結果とします。
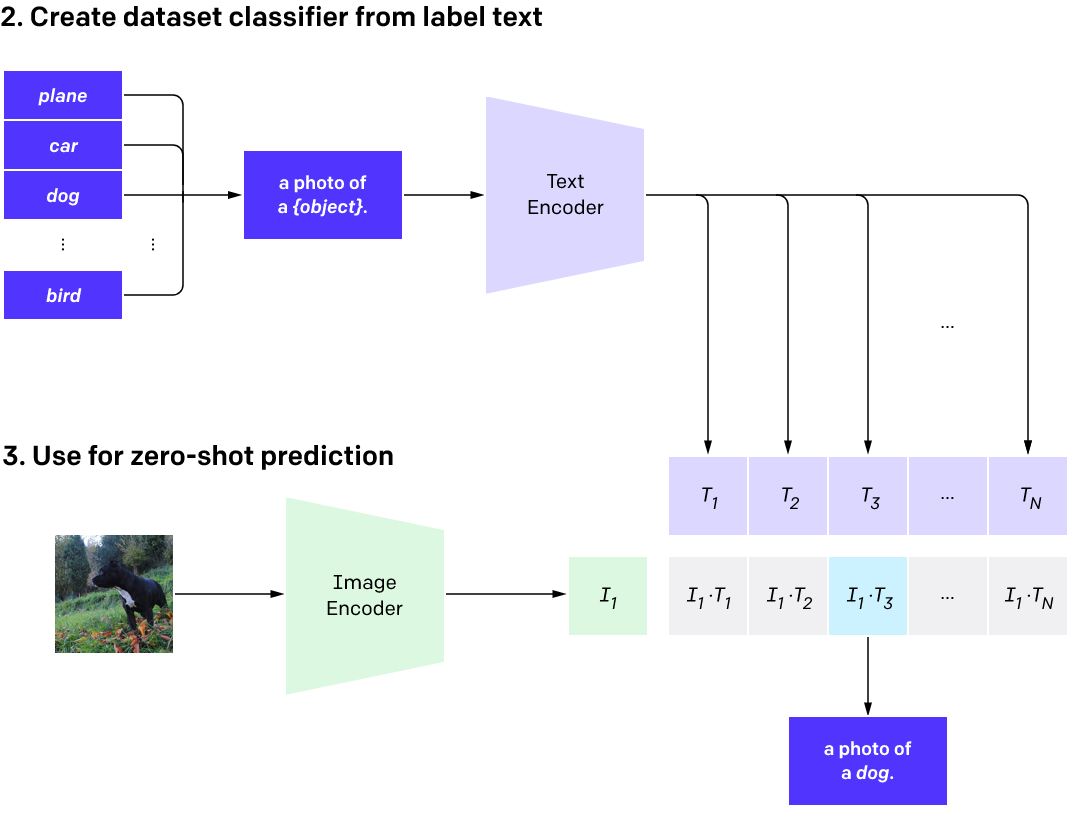
CLIPは画像とテキストというモードの異なる情報を意味的な近さによって結びつけることを可能にしました。CLIPを教師のようにして使うことで、テキストから画像を生成するモデルを訓練することもできます。その最初の例が DALL·E です。DALL·Eは、入力されるテキストを忠実に再現するような画像を生成するモデルです。DALL·Eの後には DALL·E 2 、 Imagen 、 Parti といった改良版が考案され、執筆時点で最新のImagenは下図のような画像を生成できます。「世界広しといえども、こんな画像は存在しないだろう」というような難しいクエリ文でも忠実に再現しています。

ちなみに、記事末尾に表示されているプロフィール画像は DALL·E mini に"An illustration of a seahorse and a raccoon standing together.“という文を入れて生成したものです。
2022年に登場した Flamingo はCLIPと異なり、文章を出力します。そのため、画像分類に限らず、OCRや動画像に基づく質問応答のようなフリーテキストで回答するタスクも解くことができます。
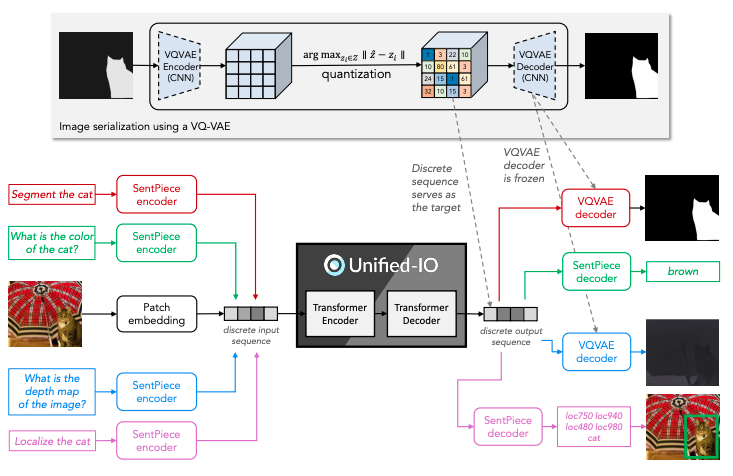
Unified-IO はデコーダ部分に工夫がなされており、画像を出力とするタスクに対応しています。画像を出力とするタスクとは、例えば深度推定、セマンティックセグメンテーション、テキストからの画像生成などです。
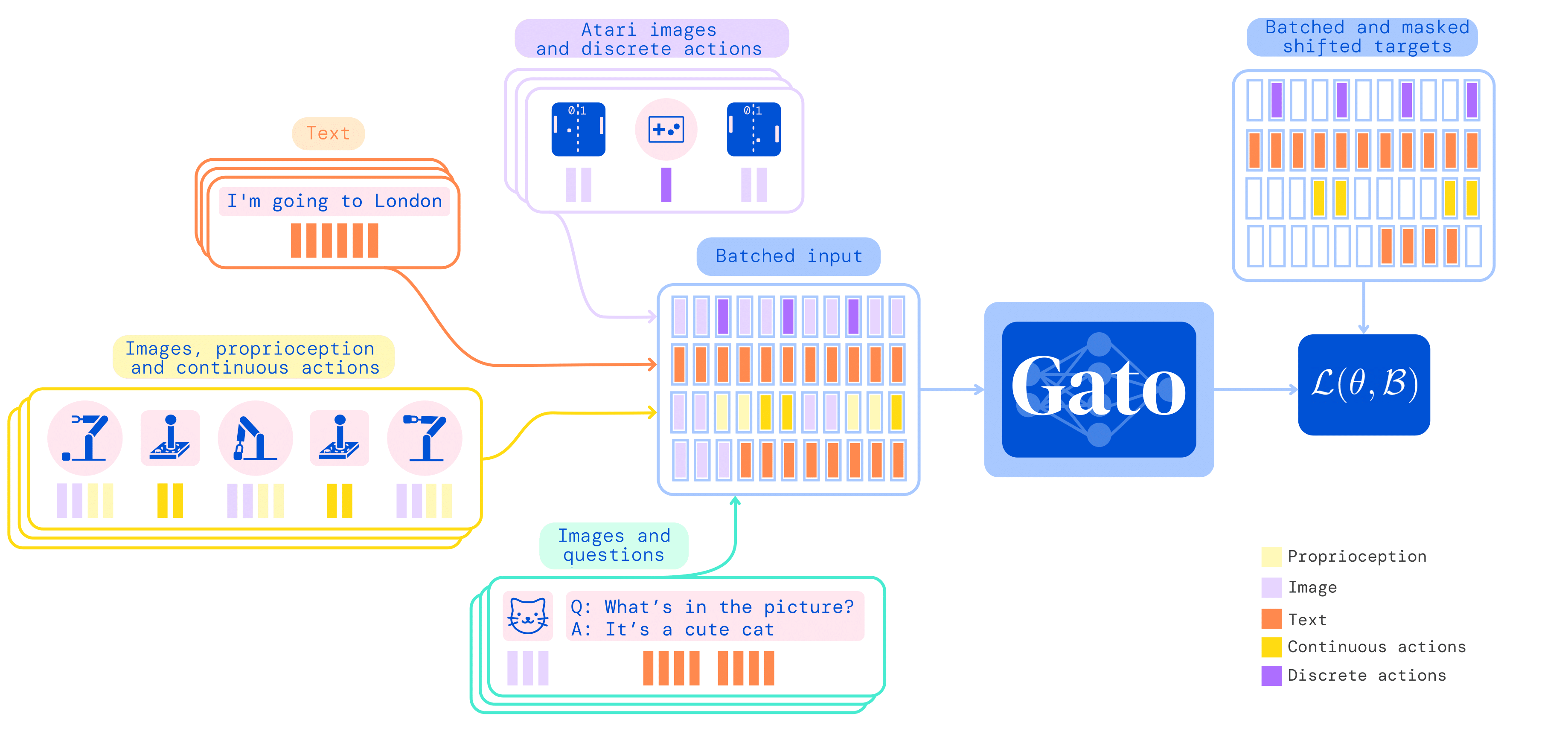
さらに数値(連続および離散)も取り扱えるようにしたのが Gato です。Gatoは、ロボットハンドの操作から画像のキャプション生成までを1つのモデル(同じ重み)で解くことができます。言語や視覚情報を理解できるロボットの実現へと歩みを進めた研究です。
活用事例
基盤モデルはAIにできることを一段と押し広げる、夢のある技術ですが、中にはすでに実用化されている例もあります。
GPT-3を開発したOpenAIは、同モデルを有償APIとして提供しています。これを利用したサービスは多数あります。OthersideAIが提供する HyperWrite は、ユーザが入力する文の一部を元にメールや文書を完成させます。 Viable はユーザフィードバックを要約して可視化するサービスで、分析者の質問に答える形でレポートを作成してくれます。
GitHub Copilot は「AIプログラマー」とでも呼ぶべきサービスで、周りのコンテキストから自動でプログラムを生成します。AIとしては、GitHubで公開されているソースコードでGPT-3をファインチューニングした Codex が採用されています。
また、AIによって生成された画像が新聞や雑誌の表紙を飾る事例も見かけるようになりました。 The Economist は MidJourney のAI、 Cosmopolitan はDALL·E 2の生成画像をそれぞれ採用しました。
日本でも、 LINE や rinna や ELYZA といった企業が日本語版の大規模言語モデルの開発を行っており、実サービスでの活用に向けた取り組みが進められています。
課題
基盤モデルは発展途上の技術なので、これから解決しなければならない課題も多数あります。まず、基盤モデルはデータセットに含まれる有害な表現や偏見をそのまま学習・出力してしまいます。また、データセット(多くはWeb上から収集される)に含まれにくい少数者の声は無視されます。これらの問題は従来のタスク特化型AIにも共通しますが、モデルの大規模化で解決される単純な問題ではないという点、また基盤モデルは様々な場面で使い回すことが想定されている点から、特筆すべきものです。
悪用を防ぐための仕組みも必要です。基盤モデルは悪意を持った人の手に渡れば、フェイクニュースで世論を操作したり、新しいコンピュータウイルスを作成したりといったことが大規模かつ容易にできてしまいます。不適切な出力や悪用への対策ができていない状態で基盤モデルの社会実装を推し進めてしまうと、社会に大きな混乱をきたすリスクがあります。そのため、近年では基盤モデルを開発した研究機関がそのモデルやソースコードを公開しない(論文という形でのみ成果を公開する)流れができています2。
他にも、新しい技術の登場とともに様々な課題が指摘されています。基盤モデルの総合的な性能を評価するための適切なベンチマークが不足していること、学習のために膨大なエネルギーを消費すること、研究が資金力のある一部の機関による寡占状態となっていることなどです。ここで挙げた課題については、冒頭で紹介した論文” On the Opportunities and Risks of Foundation Models “で詳しく議論されているので、興味のある方はご参照ください。
終わりに
基盤モデルは今後のAI研究において重要な役割を占める技術ですが、データ収集が大変であったり、作成するためのコストが高かったりするためにGoogleやMicrosoftなどごく一部の大企業によって研究開発が寡占されている現状があります。昨今の成果の秘匿化の流れもあり、AIの「脱民主化」(開発者や受益者が一部の集団に偏っていくこと)が問題視されています(そのような問題意識から、企業が成果を公開する例もあります3)。
一方で、最近はOpenAI CLIPを用いて収集された、画像とテキストのペアの大規模データセット LAION-5B が公開され、大規模なモデル学習の下地が徐々に整ってきているようにも思えます。計算資源に関しても、 Tensorflow Research Cloud などを利用することにより個人レベルで基盤モデルを作成することが可能になりつつあります4。 BigScience のような有志の企業・研究機関からなるプロジェクトも「民主化」の流れの一つだと言えるでしょう。
ここまで述べてきたように、基盤モデルは大きな可能性を秘めると同時に様々な課題を抱えてもいます。これらの課題の中には、一握りの研究者が取り組めば解決するという性質のものではなく、様々なバックグラウンドを持った研究者・実務家が力を合わせて解決していくような性質のものも多く含まれています。
この記事が基盤モデルに携わる人を増やすきっかけとなり、そして基盤モデルがもたらす利益を人類全体が享受できるようになる一助となれば幸いです。
参考資料
記事中で言及したものに加えて、以下の資料を参考にしました。
- Stanford Center for Research on Foundation Models
- Huge “foundation models” are turbo-charging AI progress | The Economist
- 自然言語処理技術の進化:AI による「ことば」の処理から汎用AI へ 最新の動向について
一緒に働きませんか?
弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。
-
他の変数がボトルネックにならない範囲において成立します。 ↩︎
-
AI academics under pressure to do commercial research | Financial Times ↩︎
-
記事中でも紹介している DALL-E mini はTensorflow Research Programを利用して作られた個人プロジェクトだったようです。 ↩︎

機械学習エンジニア
Shion Honda, Hidehisa Arai
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


