
要約
- Hugging Face にリクルートの組織ページを作りました
- 誤字脱字検出モデルを開発し、Hugging Face Hub に公開しました
- テストデータに対する指摘箇所&種類ラベル正解率は70%以上を実現しています
はじめに
みなさんこんにちは、データ推進室 データテクノロジーラボ部 R&Dグループの桐生です。私は2023年1月に中途でリクルートへ入社し、現在は自然言語処理を中心としたR&Dを担当しています。
さて、みなさんはタイポ(誤植)をしたことがありますか?PCやスマートフォンで文章を作成する際、きっと誰もがタイプミスや誤変換などを経験していると思います。自分ではしっかりとチェックしているつもりでも、意外と後からミスが見つかったりしますよね。
そんなあなたに朗報です!深層学習アルゴリズムを用いて誤字脱字検出モデルを開発し、そのモデルをHugging Face Hubへ公開しました。
説明なんてどうでもいい、さっそくモデルを試してみたい!
という方はこちらからどうぞ!→
recruit-jp/japanese-typo-detector-roberta-base
Hugging Face
Hugging Faceをご存知でしょうか?Hugging Faceは、機械学習モデル/フレームワークやその他のリソースを提供するオープンソースのプラットフォームおよびコミュニティです。Hugging Faceが提供するTransformersというライブラリは特に有名で、自然言語処理分野を中心に多くの機械学習エンジニア/データサイエンティストに使われています。
Hugging Faceには機械学習モデルを公開・共有できるプラットフォーム"Model Hub"があります。個人・学術機関・企業を問わず、多くのユーザーがモデルを公開しており、Hugging Faceは2023年時点でモデル公開プラットフォームのデファクトスタンダードであると言っても差し支えないでしょう。
そして今回のモデル公開に際し、Hugging Faceにリクルートの組織ページを作成しました!今後についてもR&Dで得た知見や成果を世の中に広めるべく、成果物の公開を進めていきたいと考えています。
https://huggingface.co/recruit-jp
誤字脱字検出モデル
さて前置きが長くなりましたが、今回公開した誤字脱字検出モデルについて紹介します。
モデル概要
本モデルはシンプルに言えば入力文の文字ごとに誤字脱字の種類と確率を出力するモデルと表現できます。入力した文章のどの部分がどのように誤っていそうか指摘してくれる仕組み、ということです。なお、指摘した部分をどのように修正すればよいか、という提案まではしませんので人間が出力結果を見て適切な修正を施す必要があります。
本モデルで指摘できる誤字脱字の種類は以下の通りです。こちらは後述する学習データセットのラベルをそのまま利用しています。
| id | label | meaning |
|---|---|---|
| 0 | OK | 誤字なし |
| 1 | deletion | 1文字の抜け |
| 2 | insertion_a | 余分な1文字の挿入 |
| 3 | insertion_b | 直前の文字列と一致する2文字以上の余分な文字の挿入 |
| 4 | kanji-conversion_a | 同一の読みを持つ漢字の入れ替え(誤変換) |
| 5 | kanji-conversion_b | 近い読みを持つ漢字の入れ替え(誤変換) |
| 6 | substitution | 1文字の入れ替え |
| 7 | transposition | 隣接する2文字間の転置 |
| 8 | others | その他の入力誤り |
推論の例
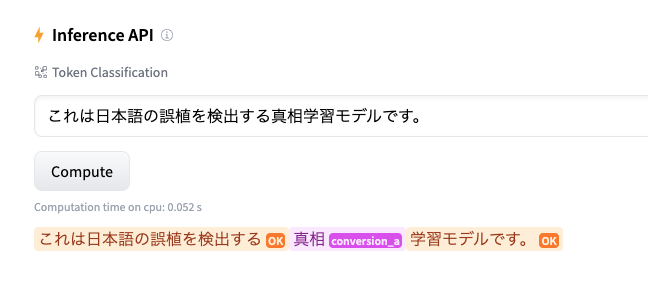
まずは入力文に対してどんな結果が得られるかを試してみましょう。こちらの例ではHugging FaceのモデルページにあるWidgetを使っています。これは自身で推論環境を用意することなくWeb UIで気軽にモデルの推論を試せる、とてもありがたい機能です。(短時間のうちに何回も推論すると制限にかかってしまうので、その場合は時間を空けてみてください)
-
OK (誤りなし)

-
deletion (文字の抜け)

-
insertion (余分な文字の挿入)

-
kanji_conversion (漢字の誤変換)

-
substitution (文字の誤り)

-
transposition (文字の転置)

いかがでしょうか?文脈に従って、それぞれ誤字脱字を指摘できているのがお分かりいただけると思います。
それでは次に本モデルの詳細についてご紹介します。
ベースモデル
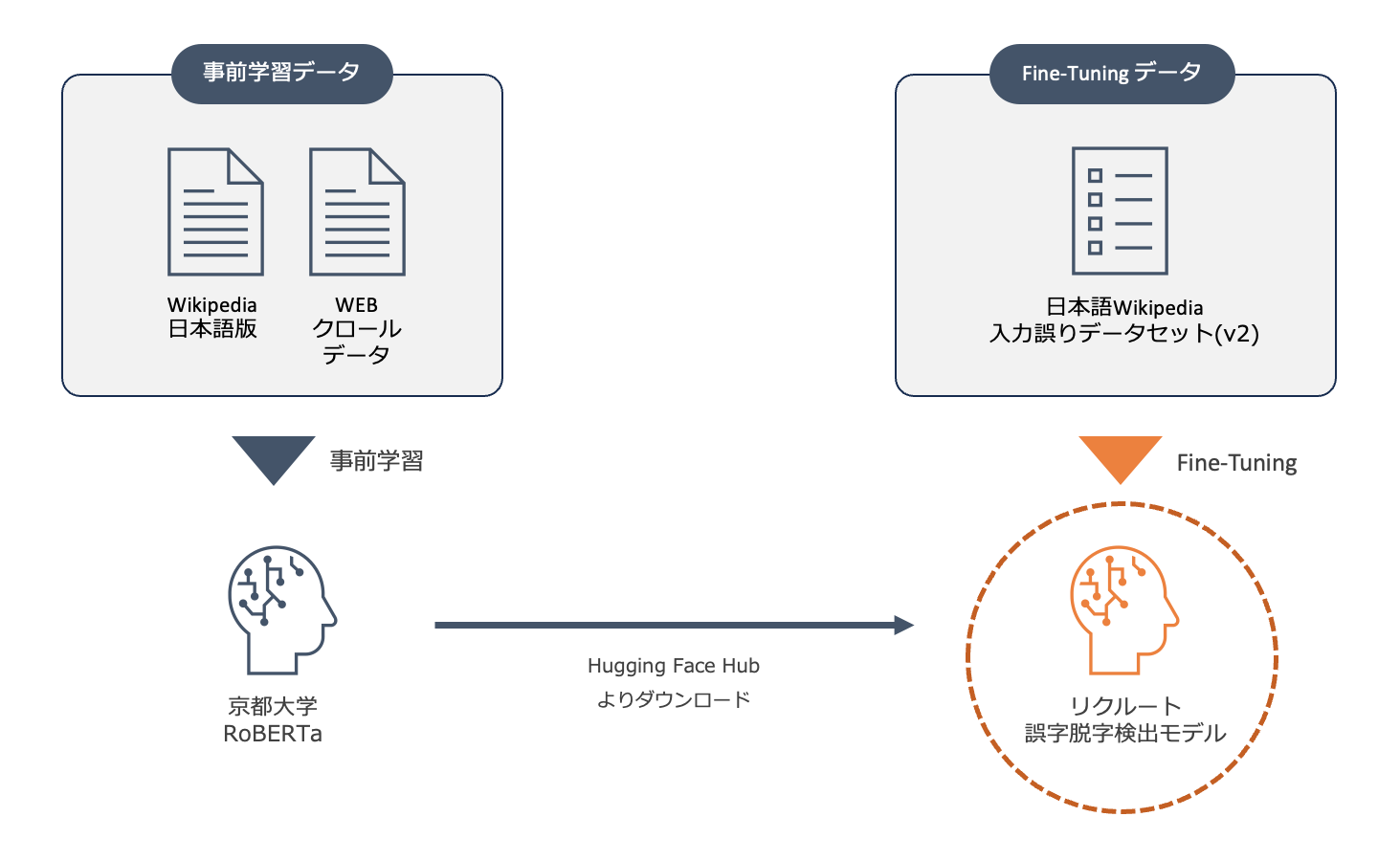
本モデルは事前学習済みのRoBERTa[1]をFine-Tuningすることで誤字脱字検出のタスクを実現しています。ベースモデルには 京都大学大学院情報学研究科知能情報学コース言語メディア研究室 より公開されている ku-nlp/roberta-base-japanese-char-wwm を利用しました。このモデルは名前の通り入力シーケンスを文字単位でトークン化する仕様となっています。
今回このモデルをベースモデルに選定した理由は以下の通りです。1
- 誤字脱字検出は単語の前後関係や文脈を考慮して推論する必要があるため、双方向Encoderモデルが好ましい
- 誤字脱字はTokenizerの語彙に含まれていない未知語となることが想定され、その対策として文字単位でのトークン化に対応したモデルが好ましい
- RoBERTaは事前学習の際、MLMの実行時にトークンに対するMASK処理を動的に行なっているため、トークン間の関係性について問うタスクについてはBERTよりも高い性能が期待される
Token classification
本モデルはToken classificationという下流タスクにフィットするようにFine-Tuningを施してあります。 Token classificationは、自然言語処理のタスクの一つで、テキスト内の各トークンに対して特定のラベルを割り当てる問題です。これは、文章内の各単語や部分文字列に対して特定のカテゴリや属性を推論するためのものであり、テキストデータの構造理解や重要な情報を抽出するのに役立ちます。
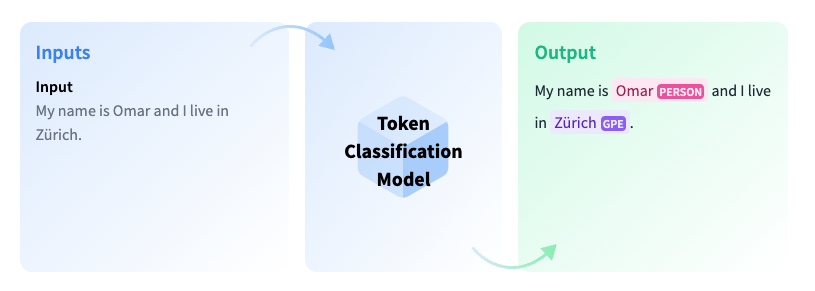
典型的な応用例としては、固有表現抽出(Named Entity Recognition, NER)があります。NERでは、テキスト内の各単語に対して、それが人名、組織名、地名などの特定の種類のエンティティに属しているかどうかを予測します。構造化されていないテキストデータから特定の情報を抽出し、それらを表形式データに整形してその後の処理をしやすくするといった活用方法があります。下図はToken classificationのイメージです( Hugging Faceの解説ページ より引用)
今回はこのToken classificasionを応用し、トークンごとに誤字脱字種類のラベルを割り当てることによって結果的に誤字脱字の検出を実現しています。
学習データ
モデルの学習には京都大学大学院情報学研究科知能情報学コース言語メディア研究室が公開している 日本語Wikipedia入力誤りデータセット(v2) を利用しています。このデータセットはWikipedia日本語版の編集履歴よりマイニングされたものです。マイニング方法の詳細については公開元の論文( 日本語Wikipediaの編集履歴に基づく入力誤りデータセットと訂正システムの改良 )をご参照ください。
データセットはtrain/test/goldと3つの区分に分けられておりtrainセットには約70万件のサンプルが含まれています。今回はこちらを訓練データに用いました。 レコードの形式と内容は以下サンプルのようになっており、原文・修正後の文に加え、修正対象の文字と誤り種類も含まれています。
{
"page": "11",
"title": "日本語",
"pre_rev": "3586520",
"post_rev": "3590455",
"pre_text": "日本語の文は動詞が最後に来るようになっているが、形容詞で終わことも多い。",
"post_text": "日本語の文は動詞が最後に来るようになっているが、形容詞で終わることも多い。",
"diffs": [
{
"pre_str": "終わ",
"post_str": "終わる",
"pre_bart_likelihood": -46.97,
"post_bart_likelihood": -19.37,
"category": "deletion"
}
],
"lstm_average_likelihood": -2.37
}
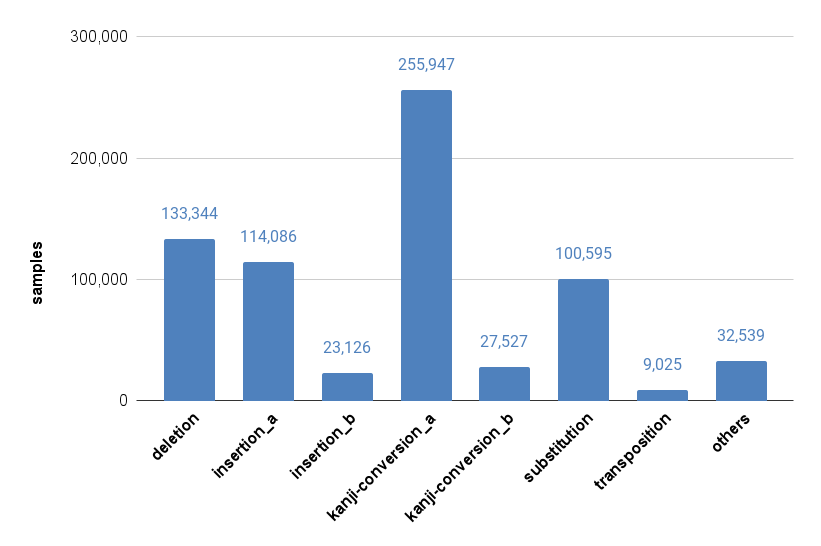
種類ラベル(json内では"category")ごとのサンプル数は以下の通りです。表を見るとラベル間のサンプル数に大きな差異があることがわかります。最もサンプル数が多いkanji-conversion_aは25万件を超えているのに対し、transpositionは1万件を下回っています。一方、漢字誤変換の検出はトークンの組み合わせが無数に存在することからタスクの難易度が高いことに対して、転置は対象をひらがなに限ることからトークンの組み合わせはある程度限定でき、比較的簡単なタスクと考えられます。このように、各ラベルのサンプル数とタスク難易度の両方にばらつきがあるデータとなっています。
| label | サンプル数 | 全体に占める割合 |
|---|---|---|
| deletion | 133,344 | 19.2% |
| insertion_a | 114,086 | 16.4% |
| insertion_b | 23,126 | 3.3% |
| kanji-conversion_a | 255,947 | 36.8% |
| kanji-conversion_b | 27,527 | 4.0% |
| substitution | 100,595 | 14.4% |
| transposition | 9,025 | 1.3% |
| others | 32,539 | 4.7% |
そしてToken classificationの学習に利用できるよう、このデータを以下の手順で前処理しています。
- 修正前の文と修正対象の文字から誤り箇所を特定
- 修正前の文を文字単位でトークン化、単語IDに変換
- 各単語IDに対してclass labelを付与
また、誤りが含まれる文のみを訓練データとして与えてしまうと誤りのない文に対する誤検出率が極めて高くなったことから、修正後の文(誤りのない文)も訓練データに含めて学習を実施しました。
性能評価
モデルの性能評価は日本語Wikipedia入力誤りデータセットのtestセットを利用しました。testセットはtrainセットと同様の手法で収集されたサンプルが約5,000件収録されています。
誤字脱字検出の性能
まず誤り検出の性能について説明します。先述したとおり本モデルはToken classificatonを応用して誤字脱字の検出を行います。指摘内容を決定づける要素としては「どのトークンが誤っているか」を示す指摘箇所と「どんな誤りをしているか」を示す種類ラベルの2つが存在します。 今回は指摘箇所のみが正解の割合と、指摘箇所と種類ラベルの両方がともに正解の割合を計測しました。なお指摘箇所については、誤りと指摘した区間に真の誤りが入っている場合に正しい、とみなしています。
まず全体的な性能を示します。
| ケース数 | 指摘箇所正解率 | 指摘箇所&種類ラベル正解率 |
|---|---|---|
| 5,438 | 76.3% | 72.3% |
指摘箇所のみ正解率と比較して、指摘箇所と種類ラベル両方の正解率は4ポイントの差があります。指摘箇所が合っていたものは、ほとんど種類ラベルも正解していると言い換えられるでしょう。また、ラベルは異なったものの箇所を正しく指摘できたのは75%以上の割合となっており、文章中になんらかの誤字脱字が存在するということが高い割合で指摘できていると言えます。
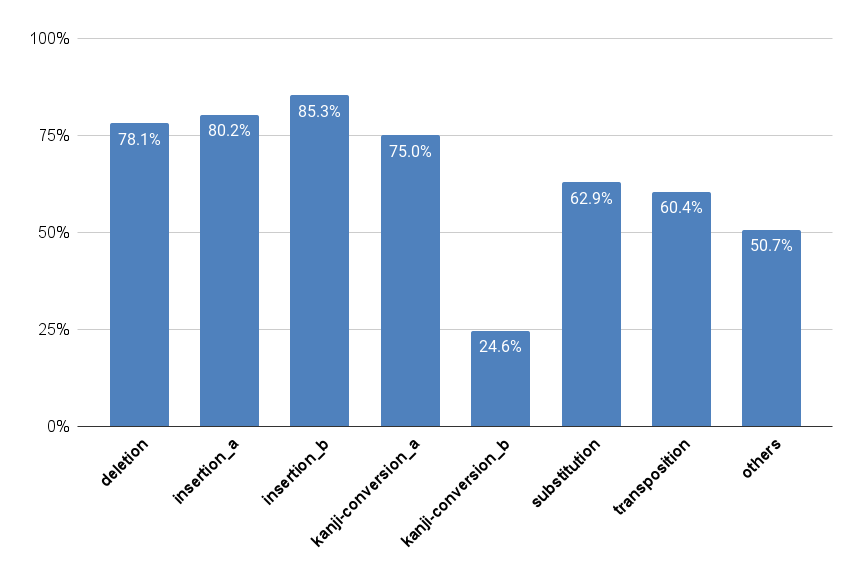
次に指摘箇所&種類ラベル正解率について、ラベルごとの分布を示します。
| label | meaning | ケース数 | 正解率 |
|---|---|---|---|
| deletion | 1文字の抜け | 1,038 | 78.1% |
| insertion_a | 余分な1文字の挿入 | 1,091 | 80.2% |
| insertion_b | 直前の文字列と一致する 2文字以上の余分な文字の挿入 |
231 | 85.3% |
| kanji-conversion_a | 同一の読みを持つ漢字の入れ替え(誤変換) | 1,830 | 75.0% |
| kanji-conversion_b | 近い読みを持つ漢字の入れ替え(誤変換) | 211 | 24.6% |
| substitution | 1文字の入れ替え | 779 | 62.9% |
| transposition | 隣接する2文字間の転置 | 53 | 60.4% |
| others | その他の入力誤り | 205 | 50.7% |
最も高い性能を示したのはinsertion_aおよびinsertion_bの衍字(えんじ)でした。これは文中に不自然なトークンが挿入されていることを指摘するものです。特に興味深いのはinsertion_bがtrainセット内に3.3%しか含まれていなかったにも関わらず、最も正解率が高くなっているという点です。事前学習の時点でトークンの自然な並びを十分に学習しており、それが余分なトークンを検出するという下流タスクに役立ったのかもしれません。
一方でkanji-conversion_bはtrainセット内に4%しか含まれておらず、かつ特に低い性能になっています。ラベルの定義には近い読みを持つ漢字という条件が含まれており、これがタスクを難しくする要因になっていると考えられます。本モデルの訓練データには漢字の読みを含めていませんので、漢字の読みに関する手がかりがなく、kanji-conversion_aと混同してしまっているものと考えられます。もっとも、人間にとっては漢字の誤変換があると理解できれば、それを修正できるはずなので実用上はそれほど問題にならないかもしれません。
誤りのない文に対する誤検出率
次に誤検出率について説明します。いくらモデルの誤り検出性能が高くても、誤りのない文章に対してまで過剰に指摘をしてくるようではユーザー体験が良くありません。そこで誤りのない文に対する誤検出率についても確認しました。testセットの修正後の文(誤りのない文)を入力とし、1箇所でも誤りと指摘したトークンが存在する場合には誤検出と基準を設けて誤検出率を計測しました。
評価結果は以下の通りとなりました。
| ケース数 | 誤検出率 |
|---|---|
| 5,438 | 12.1% |
これはtestデータに対して1割強の誤検出をしてしまうということになります。しかし、言い換えれば誤りのない文に対しては9割がたスルーしてくれるということです。この性能を高いと見るか低いと見るかはこのモデルを利用するユースケース次第になるでしょう。機械学習モデルを活用する限り、できるだけ誤字脱字を漏らしたくない場合には誤りのない文に対する誤検出をある程度許容する必要がありますし、誤検出を抑制したい場合には誤字脱字の検出力を妥協する必要があります。
幸いなことに、本モデルは誤り種類のラベルごとに確率を出力するよう設計されています。本記事での性能評価は最も確率が高いラベルをモデルの予測ラベルとしていますが、実運用では出力確率に閾値を設け、一定以上の確率を示すときに誤字脱字として扱うなどといった外回りの工夫が考えられます。このモデルが実世界の課題にフィットするよう、ユースケースに合わせてちょうどよい閾値を探ってみてください。
学習データセットの元論文で「入力誤り訂正システム」による誤り検出の性能が示されており、内部的には本モデルとの性能比較を実施しています。ただし以下の理由で比較をすることがフェアと言えないのではないかと考え、本記事にはその結果を記載しておりません。
- 論文中のモデルが「誤り訂正モデル」であることに対し、本モデルが「誤り検出モデル」であること
- 評価データがgoldセットという区分を用いており誤り種類のラベルがないこと(誤りの有無のみ)
より良いモデルに向けて
さて、ここまでモデル学習と性能評価を説明しました。本モデルに関する紹介はここで一区切りとなるのですが、最後に現状見えている課題と、さらに良いモデルにしていくための展望を示したいと思います。
誤字脱字が複数箇所にある場合、その全てを適切に検出できない場合がある
-
訓練データが1文に1箇所の誤字脱字が含まれることを前提としているため、複数トークンに誤字脱字のラベルを割り当てるように学習されていません。現状、検出漏れを防ぐには誤字脱字検出 → 人間が修正 → 再度誤字脱字検出というように都度推論を実行する必要があります。
-
この課題に対しては、1つの文章に誤字脱字が複数含まれるようにオリジナルの訓練データを加工したり、誤りのない文から誤字脱字を生成するデータ拡張が有効と考えています。

現実世界で発生する誤字脱字の種類をカバーしきれていない
-
検出できる誤字脱字の種類が訓練データの種類ラベルに依存しており、その枠に収まらない誤字脱字は検出できないケースがあります。例えば、ローマ字タイピングでは文中に全角アルファベットが混入することはよくあるケースですが、訓練データの種類ラベルとしては存在しません。
-
この課題に対しては新たにラベルを定義し、その定義に沿うように新規の訓練データ/評価データを準備する必要があります。例に挙げたアルファベットの混入であれば機械的にデータを作成することができます。

誤字脱字の検出だけでなく、修正提案もしてほしい
- 指摘箇所と誤り種類の検出だけでなく、どのように修正すれば自然な文になるかを教えてくれる方がよりユーザー体験が良くなるはずです。
- この課題は私がもっとも取り組みたいと考えているテーマです。 日本語Wikipediaの編集履歴に基づく入力誤りデータセットと訂正システムの改良 にはEncoder-DecoderモデルであるBART[2]を応用した入力誤り訂正システムが提案されています。この手法に限らず、EncoderモデルのLMヘッドをうまく活用することで、誤字脱字の修正提案ができないか検討していきたいと考えています。
おわりに
ここまでお読みいただきましてありがとうございました。
本記事ではHugging Faceにリクルートの組織ページを作成した件、そして誤字脱字検出モデルの開発・公開について紹介しました。今後につきましてもR&Dで開発したモデルをHugging Face Hubに公開していく予定です。ぜひご期待ください。
一緒に働きませんか?
当社では、様々な職種のエンジニアを新卒・中途ともに募集しております。ご興味のある方は、以下の採用ページをご覧ください。
参考文献
[1]: Liu, Y., Ott, M., Goyal, N., et al. (2020) RoBERTa: A Robustly Optimized BERT Pretraining Approach. https://arxiv.org/abs/1907.11692
[2]: Mike Lewis, Liu Y., et al. (2019) BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension https://arxiv.org/abs/1910.13461
-
本モデルでは開発時期の都合からベースモデルにRoBERTaを採用しましたが、現在はさらに新しいアーキテクチャであるDeBERTaを文字単位のトークン化に対応させたモデルも公開されています。(https://huggingface.co/ku-nlp/deberta-v2-base-japanese-char-wwm) ↩︎

自然言語処理分野のR&Dを担当
桐生佳介
好きな料理はペンネアラビアータ、好きなキーボードはHHKBです
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


