
はじめに
こんにちは、リクルートでデータサイエンティストをしている松岡と大橋と長島です。
今回は、今年の8/25~8/28に開催された KDD 2024 に参加してきましたので、レポートをしていきたいと思います。
本記事は、データ推進室 Advent Calendar 2024 2日目の記事です
学会の概要
まずは松岡から学会全体の概要についてです。 KDDは、正式名称 29th ACM SIGKDD CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING で、アメリカのCS分野の学会であるACMのデータマイニング分野の分科会であり、データマイニングで最もレベルの高い国際会議とされています。 KDDに次いで、IEEEの主催するICDM も有名でこちらは今年は12月にアブダビで開催されます。
今回のKDDはサグラダファミリアやカサ・ミラといったガウディ建築で有名なバルセロナでの開催でした。

バルセロナは世界有数の観光地で中心部は非常に賑やかですが、会場であったバルセロナ国際会議場は中心部から少し離れており、ビーチも近いことからリゾート感のある雰囲気で終始リラックスして過ごすことができました。

来年はカナダのトロントで開催されるようです。

ここからは会議の内容を紹介していきます。 8/25~8/28の5日間の日程で、最初2日間はチュートリアルとワークショップ中心、後半3日間は採択論文の口頭発表やkeynote talkを中心に常に10以上のセッションが並行で進行していきます。
チュートリアルやワークショップはそれぞれ30を超えるセッション数で、特にLarge Language Model (LLM) 関連のセッションが多数あり、Retrieval-Augmented Generation (RAG) の改善手法を体系的に解説した RAG Meeting LLMs: Towards a Retrieval-Augmented Large Language Model 、 LLMのGrounding, Evaluationに関する Grounding and Evaluation for Large Language Models などのチュートリアルが盛り上がっていました。リクルートのSaaS領域でも、RAGを活用した業務改善施策を進めているため、参考にできる点が多かったです。それ以外でも、因果推論や時系列解析を基礎から近年の潮流まで解説するチュートリアルなど、幅広いトピックが扱われていました。
ワークショップも、ファイナンスやタレントマネジメント、広告といったドメインに特化したものから、Feredated Learningや因果推論といった技術領域に特化したものまで幅広く、特にその分野を代表する研究者や企業実務家の招待講演は、リクルートのデータ活用テーマ設定の参考になるものもありました。
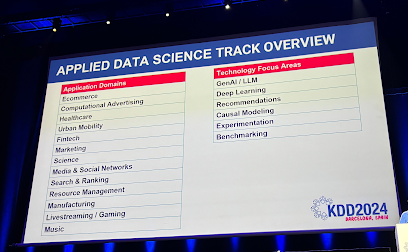
次に、採択論文の紹介です。KDD本会議の採択論文は、理論や手法研究中心のResearch Trackと実際に適用された成果や知見を含んだ研究を扱うApplied Data Science Track(ADS)に分かれています。
Research trackのword cloudをみると最も目立つのはgraphsで、それ以外にも、recommendationやtime-series、federatedなど、広範なデータサイエンスのトピックにまたがっていることが分かります.

Applied Data Science Track(ADS)はEcommerceやFintechなどの適用ドメインから、GenAI/LLM、Experimentationなど技術領域に特化したセッションに分かれていました。
個人的に印象深かったのは、 A/Bテスト実践ガイド 真のデータドリブンへ至る信用できる実験とは の著者であるRon Kohavi氏がchairを務めるExperimentationセッションです。会場も超満員な中、最後に講演者全員参加で、発表やA/Bテストに関するQAが実施され、多くの質問が飛び交うなど関心の高さが伺えました。
ベストペーパー & Keynotes 紹介
ここではResearch Trackとapplied data science trackのベストペーパーを紹介します。
Research Trackのベストペーパー
CAT: Interpretable Concept-based Taylor Additive Models
まずは、Research Trackのベストペーパーです。 解釈可能な予測技術として、一般化加法モデル(GAM)の各特徴の非線形関数をニューラルネットワークで学習する手法が提案されていますが、多くのモデルパラメータを必要とし、過学習しやすいことが指摘されています。 論文では、複数の特徴量を組み合わせた"concept"を中間ステップとして学習し、“concept"の組み合わせで最終的な予測を行う、CAT(Concept-bAsed Taylor additive model)を提案しています。 こちらの論文については、のちのパートで詳細を紹介します。
Applied Data Science (ADS) Trackのベストペーパー
LiGNN: Graph Neural Networks at LinkedIn
続いて、Applied Data Science (ADS) Trackのベストペーパーです。LinkedinではLiGNNと呼ばれる千億のノード、数千億のエッジからなる大規模なグラフニューラルネットワークを開発、展開していますが、どのようにスケーラビリティやコールドスタート問題に対処しているかなどを紹介していました。 またA/Bテストからの知見も紹介しており、実際に求人応募返信率や広告CTR、アクティブ率などの指標が改善したことも紹介されていました。
Keynotes
AI for Nature: From Science to Impact
The Ohio State UniversityのTanya Berger-Wolfさんの発表です。 生物多様性が前例のない速度と規模で失われていることをデータで示し、GPSや高解像度カメラ等のデータ収集技術の進化と併せて、これらのデータからAI・機械学習によりデータから洞察を引き出すことの重要性を訴えられていました。 これを新しい科学の分野であるimagiomicsとして紹介し、生物多様性の保全に対して、どのようにAIが活用できるか議論をされています。
From Word Prediction to Complex Skills: Compositional Thinking and Metacognition in LLMs
Princeton UniversityのSanjeev Aroraさんの発表です。LLMがもっともらしい言語を生成できるが、処理する言語の意味を理解していないことを説明する比喩として “ Stochastic parrots ” という用語が使われます。LLMは本当に “Stochastic parrots” なのか? “Stochastic parrots” では難しいと考えられる「理解」を示すか検証するために、複数のスキルセットを組み合わせないと解決できないタスクを用意し、LLMが学習中に見たことがない組み合わせのスキルを獲得できることを実験的に示しています。 またスケーリング則をもとにするとLLMのモデルサイズを10倍にすることで、組み合わせることのできるスキル数が2倍になるなどの理論解析も併せて提示されていました。
Empower an End-to-End Scalable and Interpretable Data Science Ecosystem using Statistics, AI and Domain Science
最後の招待講演は、Harvard UniversityのXihong Linさんの発表です。 Linさんは統計学者ということで、統計学者の視点から、LLMなどが登場したAI時代における統計学について自身の遺伝子学の研究を紹介しながら、講演されていました。 個人的にも、意思決定にモデルを利用する際など、解釈可能な統計モデルが有用なケースは多いと感じています。このようにML畑の人だけでなく、統計畑の人でもKDDは非常に楽しめる学会であると感じました。
ここからは、参加者が関心を持ったり、自身の事業ドメインで活用できそうと感じたりした論文を紹介していきます。
Interpretable AIに関する論文紹介
まずは松岡からResearch Trackのベストペーパーでもある解釈可能なAIモデルに関する論文紹介です。
CAT: Interpretable Concept-based Taylor Additive Models
背景
ファイナンスやヘルスケア領域においてモデルの解釈性は重要となり、多くの研究があります。 既存の解釈手法としてLIMEなどのpost-hocな手法がありますが、元の予測モデルに忠実でないケースや計算量に課題があると指摘されています。
解釈可能なモデルとしては、一般化加法モデル(GAM)や交互作用項を考慮したGA2M、近年ニューラルネットを利用したNeural Additive Models (NAM) などが提案されています。NAMに関してはパラメータが多く過学習しやすいことを指摘しています。
以降で、本研究で提案されているモデルについて、concept encoderとTaylor Netをそれぞれ見ていきます。モデル全体のアーキテクチャは以下のようになっています。
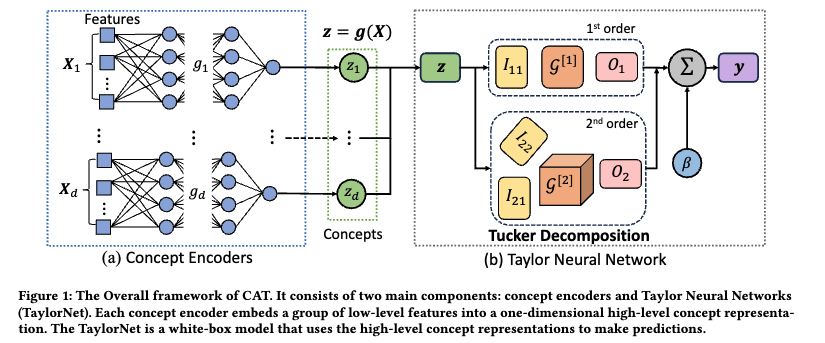
Concept Encodersについて
特徴量に対して、conceptを表すカテゴリが付与されていると仮定します。このカテゴリごとにスカラー値のコンセプトに集約することがconcept encoderの役割です。数値実験では3層のMulti-layer Perceptoron (MLP) が使われています。
TaylorNetについて
得られたconceptごとの交互作用項まで含めた、目的変数との非線形関係のモデル化を考えます。テイラー展開のテンソルを使った表現を用いて、テンソルに対するTucker分解を適用する手法が提案されています。
Tucker分解を含むテンソル分解については書籍 関係データ学習 や 鹿島先生の講義資料 関係データの機械学習 などを参考にしてください。
実験結果と解釈性について
実験結果として、MLP、XGBoost、解釈性の高いモデルとしてNAMとの比較結果が紹介されています。
論文中の実験では、RMSEやAccuracyなどの指標に関して、他の解釈可能モデルよりもCATの精度が高いこと、またより少ないパラメータで短時間で学習できることが確かめられています。
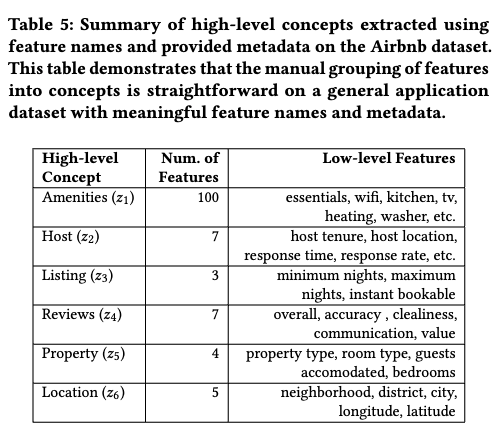
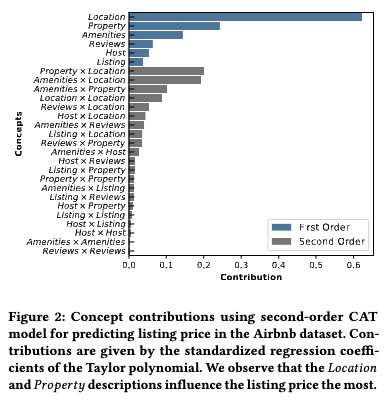
Airbnbの物件価格予測の問題において、Table 5で定義したconceptを用いた場合の貢献度がFigure 2で可視化されています。neighborhoodやdistrictを集約したLocationや、room typeなどを集約したPropertyの貢献が大きいことが分かります。
検索結果として適した画像に関する論文紹介
次に大橋から、検索システムにおける表出画像に関連する論文を1本紹介いたします。
検索において良い画像
様々なアプリケーションでは検索機能を備えており、検索結果は例えば商品画像とともにユーザに提示されます。検索結果を構成する要素の一つである画像はユーザ行動に変容を促すことができるため、できるだけ「良い画像」を提示したいです。 ユーザ行動に変容を促せれば、E-Commerce Market等においては売り手および買い手にとって良い効果をもたらします。
では検索結果として表示させる画像として「良い画像」とはどういったものでしょうか? それを定義・判別することは自明ではなく、困難な作業です。もし仮にできたとしても、その良さが事業的なKPIに貢献するかはまた別の問題として残ります。
論文: Image Score: Learning and Evaluating Human Preferences for Mercari Search
本論文では上記のような課題に対し、メルカリでの取り組みを紹介しています。
画像の質の判定方法
画像の良さを判別しようとした時、人が手作業でアノテーションをする方法・ルールベースでアノテーションする方法などがありますが、手作業にかかる金銭的・時間的コストであったり精度の面で問題が生じてしまいます。
そこで論文では、それらの問題の解決策として近年めざましく発展しているLarge Langage Model (LLM)を用いて画像の良さを評価する方法を提案しています。LLMで高品質なラベルを得られる一方で、手作業にかかる金銭的・時間的コストを削減できる方法になっています。 具体的には、Chain-Of-Thoughtと呼ばれるダイレクトに結果を問うのではなく思考過程を順次説明させて推論精度を向上させるプロンプティングを用いて、画像ごとに画像の良さを表すスコアをLLMに推論させます。プロンプトの具体例は以下をご覧ください(論文Figure 3より抜粋)

画像の質とユーザ行動
LLMで生成した画像の良さを表すスコアを推定できるようになりましたが、そのスコアがユーザ行動と関係があるのかはきちんと検証しなければなりません。論文では、画像のスコアとユーザのクリック率が有意に相関していることが報告されています。
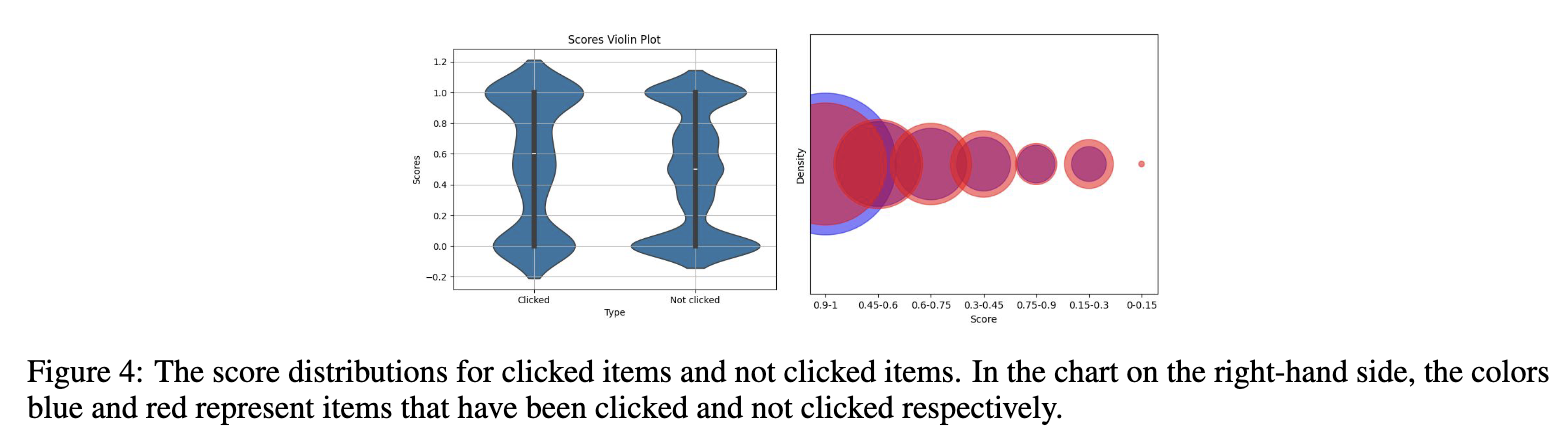
実運用に向けたモデル学習
次に、先述の画像スコアを実際にサービスで運用していくことを考えます。実際のアプリでの運用を目指す場合、日々大量の画像が更新されるため全てLLMでスコアを推論するのはコストの面で非現実的です。そこで論文では、LLMの出力を教師ラベルとして、その出力を代替するニューラルネットワーク(CLIP + Multi-layer Perceptoron (MLP))を学習させることにより、その問題を回避しています。学習する際は、CLIPの重みは凍結しMLP部分のみを学習させることにより高速化を図っています
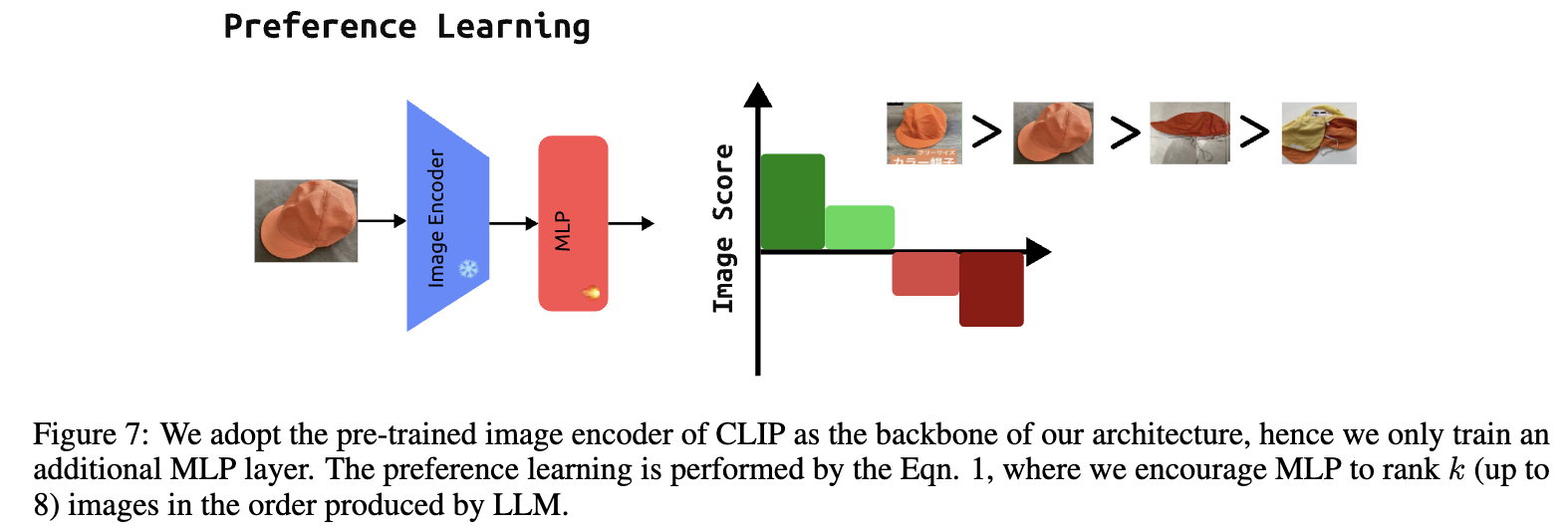
オンライン検証
最後に、今回のロジックを使って良いスコアを持つ商品が検索結果の上位に来るようにしたロジックと旧来のロジックでのオフライン検証・オンライン(A/B)検証を行っています。ここではオンライン検証の結果を紹介します。 実験は実際のアプリ上での旧来ロジックと提案スコアを用いた方法をユーザに提示し、評価は提案ロジックの運用コストを評価するための指標であるBenefit-Cost-Ratio (BCR)とユーザの行動変容を評価するための指標であるAverage Transaction per User (ATPU)の2つを用いています。
また、提案ロジックで推定した画像の質をどのように検索結果の並び順に反映させるかという点が議論になっており、論文では元々の検索スコア( $existing\_ relevance\_ score$ )と画像スコア( $image\_ score$ )に2つを用いて、以下のように積を取って最終スコア( $final\_ score$ )とするものと、和をとって最終スコアとするものの2種類を用意して実験しています。
- $final\_ score = existing\_ relevance\_ score * image\_ score$
- $final\_ score = existing\_ relevance\_ score + image\_ score$
結果は以下の通り、提案手法が既存のロジックに対し改善したことが報告されています。variant1が和を用いたスコアで、variant2が積を用いたスコアになっています。

相互推薦システムに関する論文紹介
最後に、長島からは、相互推薦システム (RRS) に関連する論文を2本紹介いたします。
- Revisiting Reciprocal Recommender Systems: Metrics, Formulation, and Method
- Beyond Binary Preference: Leveraging Bayesian Approaches for Joint Optimization of Ranking and Calibration
RRSとは
そもそも、RRSとは何でしょうか?
従来の推薦システムが「ユーザにアイテムを推薦する」システムであるのに対し、RRSは「ユーザにユーザを推薦し合あう」システムです。例として、従来の推薦システムにはECサイトが、RRSにはマッチングアプリが思い浮かびます。マッチングアプリでは、ユーザグループA (例: 女性) に対してはユーザグループB (例: 男性) を、BにはAを推薦することになります。
RRSの課題
RRSには、一般的な課題があります。それは、RRSに適した評価指標や学習手法が確立されていないことです。
本来、RRSでは二者間のマッチを促進したいので、双方の推薦における性能 (例: ランキング性能) が重要となります。一方で、既存手法では、片方の性能のみが評価される傾向にありました。つまり、昨今のRRSには、RRSの性能を包括的に評価する手法と、RRS全体の効果を最適化する手法とが求められていると言えます。
論文1: Revisiting Reciprocal Recommender Systems: Metrics, Formulation, and Method
上記の課題に対し、RRSに適した評価手法と最適化手法を Chen Yang らが提案しています。
評価手法
評価指標として、下記の3観点に基づき、Recall/Precision/NDCG の再定義を行なっています。
- 全体のカバレッジ (Overall Coverage)
- 双方向の安定性 (Bilateral Stability)
- バランスの取れたランキング (Balanced Ranking)
ここでは一例として、バランスの取れたランキング $\mathrm{RNDCG}$ の定義を示します。定義自体は簡潔で、従来の $\mathrm{NDCG}$ を双方のユーザグループ $\mathrm{A}$ / $\mathrm{B}$ に対して計算した上で、それらをユーザグループのサイズ ( $\mathrm{A}$ なら $n$ , $\mathrm{B}$ なら $m$ ) で重み付けし平均をとっており、これは、ユーザグループによらず1ユーザの重みを全て等しいものとして評価していると解釈できます。
$$ \mathrm{RNDCG@K} = \frac{n \cdot \mathrm{NDCG}_ {\mathrm{A}} + m \cdot \mathrm{NDCG}_ {\mathrm{B}}}{n + m}. $$
最適化手法
また、最適化手法には、複数の推薦戦略ごとの学習と戦略選択を掲げています。
戦略は下記のいずれかで、あるユーザペア $(a_ i, b_ j)$ について、各戦略を選択した場合の効果 (例: CTR) を対応するモデルによって予測し、その効果が最大となる戦略で推薦を行なっていきます。なお、予測値を $[0, 1]$ で返せるのであれば、モデル構造は任意です。
- ユーザグループAのみに推薦する ( $T_ A = 1, T_ B = 0$ )
- 効果: 対応するモデルの予測値 $\hat{y}_ {10}$ + B側の空きスロットに対する期待値 $\bar{y}(b_ j)$
- ユーザグループA/B双方に推薦し合う ( $T_ A = 1, T_ B = 1$ )
- 効果: 対応するモデルの予測値 $\hat{y}_ {11}$
- ユーザグループBのみに推薦する ( $T_ A = 0, T_ B = 1$ )
- 効果: 対応するモデルの予測値 $\hat{y}_ {01}$ + A側の空きスロットに対する期待値 $\bar{y}(a_ i)$
論文2: Beyond Binary Preference: Leveraging Bayesian Approaches for Joint Optimization of Ranking and Calibration
また、損失関数に焦点を当てた、RRSに適した最適化手法を Chang Liu らが提案しています。
Chang Liu らは、CTR予測におけるランキングとキャリブレーションを同時に改善する為、クリック行動を確率でモデル化しました。実は、本論文はRRSの研究ではないのですが、副次的な効果として、RRSの双方の推薦におけるランキング性能をも最適化することを可能にしています。
クリック行動のモデル化
本研究では、まず、CTRを $\beta$ 分布としてモデル化することで、ユーザ × アイテムのペア毎の事後確率を計算します。ことRRSでは、ユーザ/アイテムをユーザグループAのユーザ/ユーザグループBのユーザとして、また、クリック行動も適当な行動として読み替えてください。
ペア毎の事後確率の計算に当たり、ユーザ毎の事後確率 $P^{u}_ {\mathrm{click}}$ とアイテム毎の事後確率 $P^{v}_ {\mathrm{clicked}}$ を計算します。論文中では、この計算に不動点反復法を採用しており、後の学習と比較して短時間で済むことが言及されています。その後、得られたユーザ/アイテム毎の事後確率に基づき、ユーザ × アイテムのペア毎の事後確率 $P_ {\mathrm{agg}}$ を計算するのですが、これは単にユーザの事後確率とアイテムの事後確率の平均等で構いません。
$$ P_ {\mathrm{agg}} = \mathrm{agg}(P^{u}_ {\mathrm{click}}, P^{v}_ {\mathrm{clicked}}). $$
損失計算
上で求めた事後確率に基づき、損失を計算していきます。ここで、事後確率 $P_ {\mathrm{agg}}$ とラベル $y$ を足し合わせた新しいスコア $z$ を定義します。事後確率の存在により、ラベルが一致していても、新しいスコアでは同点が解消され得ることが分かります。
$$ z = P_ {\mathrm{agg}} + y. $$
あとは、このスコア $z$ の大小でランキングに関する損失 $\mathcal{L}_ {\mathrm{rank}}$ を計算した上で、キャリブレーション用の損失 $\mathcal{L}_ {\mathrm{cal}}$ (Binary Cross Entropy) と足し合わせるだけです。
$$ \mathcal{L}_ {\mathrm{total}} = \lambda \mathcal{L}_ {\mathrm{cal}} + (1 - \lambda) \mathcal{L}_ {\mathrm{rank}}. $$
なお、 $\mathcal{L}_ {\mathrm{rank}}$ の算出においては、従来のランキング単位 (Query) の明示は不要です。 $z$ 自体にユーザ及びアイテムの事後確率が含まれているので、ランキング単位は気にせず、全レコード間でのランキングを最適化することが可能です。つまり、RRSの文脈では、双方の推薦におけるランキング性能を同時に最適化することが可能になります。
おわりに
今回は KDD 2024 への参加を通じて、データサイエンスの最前線に触れ、多くの刺激を受けることができました。本記事ではいくつかの論文をピックアップして紹介しましたが、他にも多くの興味深い論文がありましたので、気になる方はぜひ こちら からご参照いただければと思います。
最後までお読みいただき、ありがとうございました。本記事が何かの参考になれば幸いです。

データサイエンティスト
松岡佑知
リクルート入社7年目。最近はSaaS領域でマネージャーおよびデータサイエンティストを担当。

データサイエンティスト
大橋勢樹
リクルート入社2年目。飲食領域での推薦アルゴリズム・検索アルゴリズム開発などを担当。
データサイエンティスト
長島弘昂
リクルート入社3年目。人材領域での推薦アルゴリズム開発などを担当。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


