
はじめに
LLM 20 Questions というKaggleのコンペにmajimekunチーム(メンバーは 若月 、 翁 、 桑原 の3人)として参加し、832チーム中11位となり金メダルを獲得することができました。 この記事では、コンペの概要や我々の取り組みについて紹介します。

コンペ説明
このコンペでは20回以内の質問で秘密のキーワードを当てるゲーム (20 Questions) を解くことを考えます。
ゲームは2対2の対戦形式で行われ、各ペアはGuesserとAnswererの2種類のエージェントから構成されます。 Guesserは各ラウンドでAnswererに対して質問(Ask)を行い、その回答をヒントに推定(Guess)した秘密のキーワードを1つ出力します。一方、AnswererはGuesserから受け取った質問に対して “yes” か “no” のどちらかを回答します。
一度の対戦につきレートがなるべく近い4つのチームが選ばれ、各チームはそれぞれGuesserとAnswererどちらかのエージェントを担当します。一つのキーワードがランダムに割り当てられ、一方のペアのGuesserが先に正解のキーワードを当てるとその時点でそのペアの勝利となります。どちらのペアも正解を当てられなかった場合は次のラウンドに進みます。同じラウンドで両ペアが正解を当てた場合や、どちらのペアも20ラウンド以内に正解を当てられなかった場合は引き分けとなります。勝ったペアのレートが上がり、負けたペアのレートが下がるようになっています。
ゲームの一例として、「majimekun(Guesser) & Goya Shuto(Answerer) VS Fayez Siddiqui(Guesser) & ISAKA Tsuyoshi(Answerer) 」の対戦中のあるラウンドを以下に示します。
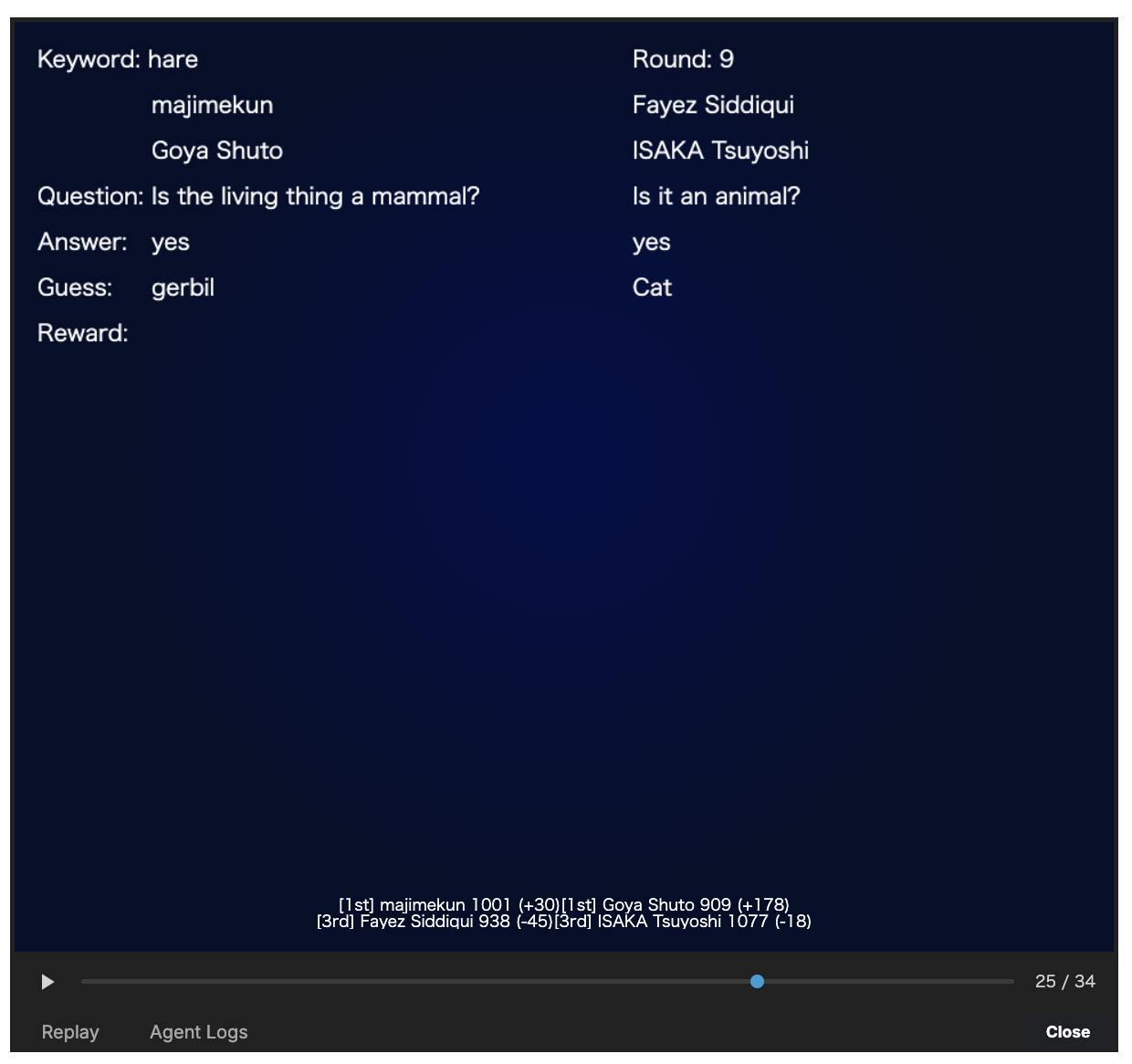
キーワードリスト
正解となり得るキーワードのリストはPublic評価時とPrivate評価時とで異なるものが使用されました。 Public評価時は予め公開された「物」に関するキーワード(例:Bird cage, Donuts, Hand Sanitizer, Mouse, Protein bar)からランダムに選択されます。 Private評価時はPublic評価時に出現しないことが保証されている「物」に関するキーワードがランダムに選択されます。
その他の仕様
- 文字数制限
- Guesserが行う質問は750文字以内
- 推定する単語は100文字以内
- 実行時間の制限
- 各ラウンドで各エージェントが使用出来る時間が60秒与えられる
- 上記に加えてゲームを通じて使用できる時間が300秒与えられる
majimekun解法
majimekunの解法は、辞書順による二分探索に基づいた手法と、意味的な質問を使う手法の2通りからなります。ここでは主に注力していた意味的な質問を使う手法について説明します。
KaggleのDiscussionにも 解法 を投稿しています。
Answerer
Answererの構成はシンプルで、ルールベースで答えられる質問はそれで対応し、そうでないものはLLMに答えさせるというものです。変なことはせず、質問に対して可能な限り正確に回答することを目指しました。
ルールベース
質問が以下の正規表現に一致する場合に回答します:
- 開始/終了文字:
(starts|start|begins|begin|end|ends) with the letter ['"]?([a-zA-Z])['"]?\?$ - 含有文字:
(includes|include|contains|contain) the letter ['"]?([a-zA-Z])['"]?\?$ - 辞書順:
keyword.*(?:come before|precede) "([^"]+)" .+ order\?$
これらのルールベースの選定としては、Public評価期間中の対戦ログに多く見られた形式の質問であり、文字単位でなくトークン単位で処理するLLMには難しく、ルールベースでは簡単に答えられるものを選びました。また、辞書順の質問は二分探索を用いるGuesserで使われていました。
LLMによる回答
ルールベースで答えられなかった質問はLLMに回答させました。以下のような制約があるKaggleの環境内で動作するコードを書く必要がありました。
- 提出ファイルの容量が20GB以下
- 1回あたりの計算時間が60秒以下
- GPUメモリは16GB
この環境で動かせそうなのはパラメーター数が7B~9B程度のLLMであり、16ビットだとGPUメモリの容量を超えてしまうため、8ビットや4ビットに量子化して扱う必要がありました。また、1つのモデルだけで推論するより、多数決を取ったほうが回答が堅牢になると考え、複数のモデルを使うようにしました。 最終的にGemma-2-9B, Llama-3.1-8B, Mistral-7Bを4ビットに量子化したものの多数決で回答させるようにしました。 また、一度に2モデル以上をメモリにロードするとメモリの上限を超えてしまう可能性があったので、推論のたびにモデルをロードし直すようにしました。この場合、1ラウンドに3モデルをロードし直すと持ち時間に間に合わないことがわかったので、モデルのロード順を回転させ、1ラウンドに2モデルをロードし直せば済むように工夫しました(あるラウンドで最後にロードしたモデルはメモリに残しておき、次のラウンドでロードし直さずに推論する)。
Guesser
GuesserにもLLMを使っていますが、その場でLLMに推論させるのではなく、あらかじめキーワードリスト、質問リスト、各キーワード・質問ペアに対して"yes"となる確率、各キーワードの事前確率を用意しておき、Ask時には相互情報量が最大(条件付きエントロピーが最小)になるような質問をし、Guess時には最尤なキーワードを答えるようにしました。 この手法のモチベーションとしては、パラメーター数が7B~9B程度のLLMに20個程度の質問と答えのペアを与えてそれらしいキーワードを答えさせるのは厳しそうだが、1つのキーワードと質問のペアに対しては十分良い答えを返してくれると期待したからです。
最適な質問と最適なキーワードを導き出すロジックは単純です。そのターンまでに集めた質問と回答のペアをもとに、条件付きエントロピーを最小化することで最適な質問を決定します:
$$\begin{array}{c} q_{opt} = \text{argmin}_q \sum_{z\in\lbrace\text{yes, no}\rbrace}P(q=z|q_1,…,q_t)[-\sum_k P(k|q_1,…,q_t,q=z) \log P(k|q_1,…,q_t,q=z)] \end{array}$$
ここで、$k$はキーワード、$q$は質問、$q_1,…,q_t$はすでに集めた質問(と回答)を表します。これはベイズの定理を使うと数値計算できる形になり、$K$をキーワード数、$Q$を質問数とすると、計算量は$O(KQ)$となります。majimekunが用意したキーワード約32,000個と質問約1,000個に対しては十分間に合います。
最適なキーワードは次のように導き出されます:
$$\begin{array}{c} k_{opt} = \text{argmax}_k P(k|q_1,…,q_t) \end{array}$$
また、これらの計算の中にはキーワードの事前確率$P(k)$(後述)も組み込みました。これにより、質問とキーワードの選定時、Private評価に使われるキーワードリストに入っていそうなキーワードを重視するようになりました。
キーワードリスト生成
この手法ではリストにないキーワードを推測することはできません。しかし、キーワードが多すぎると正しい答えを見つけるのが難しくなります。質の低いキーワードはAskとGuessの両方に悪影響を及ぼす可能性があります。よって、キーワードの選定は重要と考えられました。 キーワードリストの品質を評価するために、公開されているキーワードをランダムにtrain用とvalidation用に分け、validationキーワードに対してRecallとPrecision(または語彙数)を評価しました。
WordNetなどの辞書からキーワードリストを作る方法を色々試行錯誤した結果、最終的にはLLMに生成させるのが良いと判断しました。
ホスト側でPrivate用のキーワードは公開されているキーワードリストと同一のソースから抽出されることが明言されていたため、LLMを用いて公開されているキーワードに似たキーワードを生成させ、それをPrivate用のキーワードリストとして用意しました。 具体的にはPublic評価用キーワードリストからキーワードを$N$個サンプリングし、LLMにサンプリングされたキーワードに似た単語を$M$個出力させる操作を繰り返し行うことでキーワードリストを生成しました。
このような操作を行うと同一の単語が複数回出力されることになりますが、面白い発見として、単語の出現回数とPrecisionの間に強い正の相関があることが認められました。 このことから、出力回数が多い単語ほどPrivate用のキーワードリストに含まれる確率が高いことが推察されました。この事実を踏まえ、出現回数による足切りをすることで正解となる確率が低いキーワードを除外することにしました。 また、各単語$k$に対して、同じ出現回数ごとのPrecisionをその単語の事前分布$P(k)$として割り当てました。このように出現回数ごとの傾向も確率分布で考慮することで、Privateキーワードとして出現しやすそうなキーワードを重視できるようになりました。
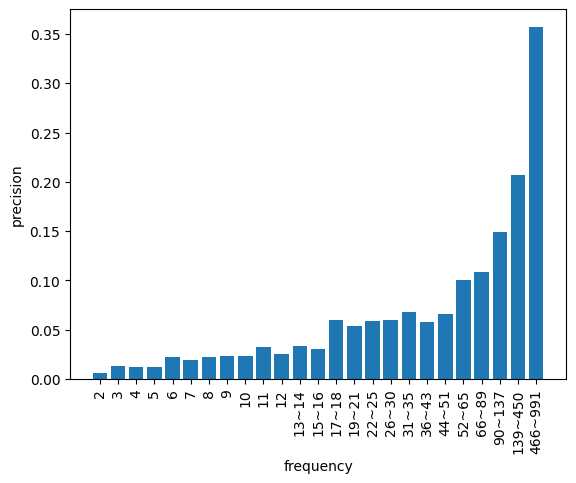
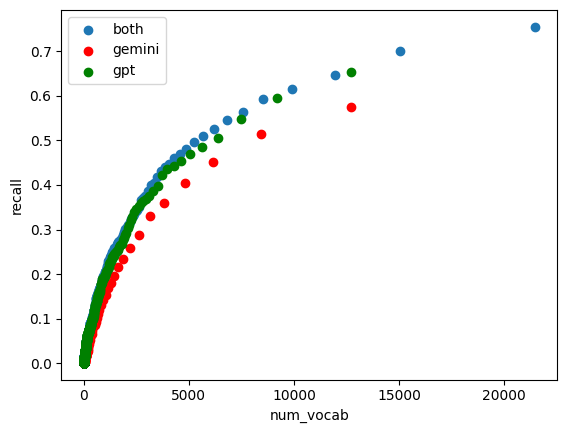
生成に用いたLLMはgpt-4o-miniとgemini-1.5-proの2種類です。足切りに使用する出現回数を変化させながらRecallの値を評価すると以下の図のようになりました。 単体のモデルではgpt-4o-miniがgemini-1.5-proよりRecallの性能がよく、また両者の結果をマージすることで更にRecallが上がることが確かめられました。
質問リスト生成
最適な質問は自動的に導き出されるため、質問が多いほどGuesserのパフォーマンスが向上すると考えられます。
次の方法で質問を用意しました。
- 「Does the word start with “a”?」のような質問
- Public評価時の対戦ログから収集した質問
- LLMが生成した質問
LLMによる質問生成は、Publicのキーワードリストから$N$個($N$は適当な値)サンプリングして、$N$個のキーワードをなるべく半分に分けるような質問を繰り返し生成させることで行いました。
最終的な質問リストに似たような質問が多く含まれていたとしても、 Guesser の章で説明したアルゴリズムでは、質問の選択時に相互情報量を最大化するため、過去にした質問に似た質問が選ばれる可能性は少ないと考えられます。 しかし、似たような質問がリストに多く含まれていると、キーワードと質問のペアに対するラベリングに時間がかかってしまうため、 SentenceTransformers を用いて質問同士のCosine類似度を計算し、すでに質問リストに含まれている質問と類似度が高い質問は除外するようにしました。
キーワードと質問ペアに対するラベリング
キーワードと質問の各ペアに対して"yes"となる確率の表を用意しておく必要があります。表はペアのAnswererの挙動と一致していることが望ましく、環境にいる典型的なAnswererと同じような確率値を求めることを目指しました。ここでも堅牢にするため、Gemma-2-9B, Llama-3.1-8B, Mistral-7B, Phi-3-smallの4つのLLMが出力するトークン確率の平均値を使用しました。推論には高速化のために vLLM を使いました。キーワード約32,000個と質問約1,000個の全ペアに対して計算する必要があり、そこそこの計算リソースを必要としました。
二分探索
二分探索を使った手法は、キーワードリストを用意しておいて、「Does the keyword precede “melon” in alphabetical order?」などといった質問を繰り返して毎回半分ずつキーワード候補を絞っていく方法です。この方法が最も効率的で、$2^{20}$個のキーワードリストを用意しても20回の質問で正解を導くことができますが、正解を得るためには基本的には100%の精度でペアのAnswererが答えてくれる必要があります。そのため、Answererが100%の精度で答えることができるかどうかを確認するためのプロトコルが ある公開ノートブック で提案されていました。このプロトコルでは、Guesserが1ラウンド目に「“Is it Agent Alpha?"」という特殊な質問をし、Answererが二分探索の質問に対応できるか判定します(Answererが「“yes”」を答えた場合、Guesserは2ラウンド目以降二分探索の質問をします)。majimekunチームもこのプロトコルを使って二分探索を行うかどうかを決めるようにしました。Public評価時には、このプロトコルを採用しているチームはそれ程多くない印象でしたが、 こちら によると、Private評価で上位になったチームの多くがこのプロトコルを採用していたようです。
キーワードリストとしてはWordNetの単語とLLMで生成したキーワードリストを合わせたものを使い、173,000個程度になりました。
実際にはPrivate評価時には二分探索を使ったエージェントが上位の殆どを占めており、それらの間の対戦は、Guesserがどれだけ速く正解キーワードを答えられるか、キーワードリストに正解キーワードがあるのかの勝負になっていました。 majimekunでも質問回数を減らすために、確度の高いキーワードとそうでないキーワードに分けて二段階に二分探索を行う、事前確率に基づいて二分探索を行うなどの案がありましたが、Public評価時にはそこまで多くの二分探索エージェントがなさそうだったので優先度を下げ、適当に作ったキーワードリストと単純な二分探索を行うにとどめてしまっていました。この辺をもう少し工夫するとより上位が狙えたと思います。
Private評価時のパフォーマンスについて
二分探索が行われた場合と行われなかった場合のmajimekunのエージェントのパフォーマンスについて詳細を見てみます。
二分探索
Guesserとしての性能は、キーワードリストの質と探索の効率に依存します。 以下の図がチームごとの二分探索エージェントの性能を大まかに表しています。 横軸は、キーワードを見つけられた割合、縦軸は報酬(21 - 質問回数)の平均を表しています。 つまり、右上に位置するほど性能が高いと言えます。
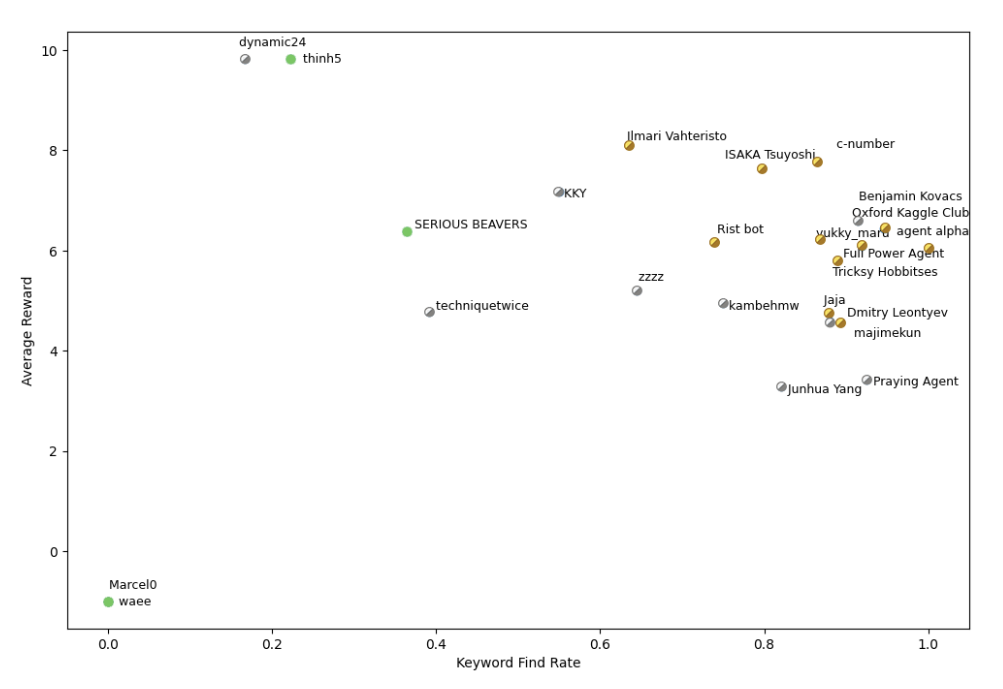
majimekunのエージェントはキーワードのRecallは高かったものの、キーワードを厳選していないことに加え、単純な二分探索しか行っていなかったので、他の金メダルを取っていたチームと比べて質問回数が多くなってしまっていたようでした。
Answererはルールベースに基づいて回答を行うため、正解率は100パーセントです。 なので、Answererとしての性能については他チームのエージェントと差がありません。
意味的な質問を使う手法
Guesserの場合、majimekunのエージェントは こちら の章で説明したように相互情報量最大化のアルゴリズムを使って質問を選択し、最尤なキーワードを推定していきます。
(例)キーワードがHare(野うさぎ)であった時に、majimekunのエージェントが出力した質問と推定キーワード
| Round | Question | Answer | Guess | Top 3 guesses with probabilities |
|---|---|---|---|---|
| 1 | Is it Agent Alpha? | no | blender | 1ターン目は事前確率 が大きいキーワード からランダムに選択 |
| 2 | Is it a type of tool or equipment? | no | flower pot | flower pot(0.002) cushion(0.002) cactus(0.002) |
| 3 | Is the keyword related to food or animals? |
yes | seaweed | seaweed(0.004) granola bar(0.003) fruit(0.003) |
| 4 | Is it a type of food or beverage? | no | lizard | lizard(0.006) birdhouse(0.006) coral(0.005) |
| 5 | Is it a living organism? | yes | coral | coral(0.012) chipmunk(0.011) bison(0.011) |
| 6 | Is it typically found in water? | no | chipmunk | chipmunk(0.015) bison(0.015) gerbil(0.015) |
| 7 | Is the keyword a type of animal? | yes | bison | bison(0.021) gerbil(0.020) tortoise(0.019) |
| 8 | Is the living thing a mammal? | yes | gerbil | gerbil(0.047) hedgehog(0.040) moose(0.035) |
| 9 | Is it typically associated with pets? |
no | moose | moose(0.050) grizzly bear(0.042) zebra(0.041) |
| 10 | Is it smaller than a human? | yes | opossum | opossum(0.062) Hare(0.050) coyote(0.031) |
| 11 | Does the keyword start with the letter ‘c’? |
no | Hare | Hare(0.063) koala(0.035) marmot(0.032) |
最初の方は、「動物もしくは食べ物?」というように候補をざっくり絞り込む質問をし、徐々に、「哺乳類?」、「ペット?」というようにより候補を絞る質問をしていっているのが見て取れます。
結果の集計 によると、我々の提出したエージェントは二つ合わせて、15%(8/54)程度の正解率だったようです。 二分探索なしのエージェント全体の正解率が 2.5%程度 だったようなので、比較的高い正解率だったと言えるでしょう。
また、非公式ですが、二分探索を除いた場合のエージェントの性能について、 こちら で分析されています。 この分析では、phrase-BERTを用いて、
- Guesserだった場合は、GuessしたキーワードのCosine類似度の最大値
- Answererだった場合は、ペアがGuessしたキーワードのCosine類似度の最大値
をゲームごとに求めて、その平均値をそれぞれGuesserとしての性能、Answererとしての性能としています。 Guesserとしての性能とAnswererとしての性能を足し合わせた指標で、majimekunのエージェントは1位と4位でしたので、この指標において、majimekunのエージェントはかなり高い性能を持っていたと言えるでしょう。ただし、分析対象のゲーム数が少なく、またペアの組み方はランダムではなく、上位にいけばより強いエージェント同士でマッチするようになるというバイアスもあるので、あくまで参考程度の指標です。
おわりに
終了数時間前に賞金圏内のチームが入れ替わるような不確実性の高いコンペでしたが、最終的に金メダルを取ることができて良かったです。 LLM、情報理論、プログラムの高速化や省メモリ化など、様々な技術を駆使して取り組むことができ、とても楽しいコンペでした。
一緒に働きませんか?
ここまで読んでいただいてありがとうございます。 弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。

人材領域でのレコメンドシステムの機械学習周りを担当
若月良平
スプラトゥーンが好きです。

人材領域でのレコメンドシステムの機械学習周りを担当
翁啓翔
最近はテニスとランニングが好きです。

人材領域でのデータ周りの基盤構築などを担当
桑原旦幸
最近はトライアスロンにはまっています。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


