
はじめに
データ推進室の前田陽平です。 現在は主にバックエンドのWebアプリケーション開発に携わっています。 2024年6月21日, 6月22日に幕張メッセで開催されたAWS Summit 2024 のうち、1日目に参加しました。 (イベントの存在に気づいたのが開催の10日ほど前で、個人 times で行きたかったなあとぼやいていたら、それを見ていたマネージャーが背中を押してくれました。)
このブログでは、会場の雰囲気や面白かったセッションについて書いていきます。
会場の雰囲気



並列でいろいろなセッションが進むためリアルタイムで全てのセッションを聴くことはできませんでした。しかし、開催終了後に 7月5日までオンデマンドでの配信がされていて、聞きたいセッションは一部を除いて後からでも書くことができました。 現地で参加する場合はセッション枠の事前予約ができます。ただ、予約していなくても後ろの方であればまず入れると思ってよいと思います。

今年は生成AIに関する発表やブースがとても多く、特にAWSが出展している多くのブースで生成AIに関連した内容が含まれていました。
AWS は生成AIのテクノロジースタックとして次の3つのレイヤを強調しています。
- 大規模言語モデル・基盤モデルを活用した構築済みアプリケーション
- 大規模言語モデル・基盤モデルを組み込んだアプリ開発のためのツール
- 基盤モデルのトレーニングと推論のためのアーキテクチャー
特に、Amazon Q や Amazon Bedrock, Amazon SageMaker など、生成AIを活用するサービスが頻繁に紹介されていました。
セッション: Deep Dive in S3
ここからは、面白かったセッションやブースを紹介します。
まず、Amazon S3 (以下、S3) についてのセッションです。S3 とは Simple Storage Service の略で、その名の通りストレージを提供するサービスです。各種プログラミング言語からAPIへアクセスすることでファイルのアップロードおよびダウンロードが行えます。 S3は、フロントエンド, インデックス, ストレージ の三層で成り立つサービスです。このセッションでは、それぞれの層をテーマに解説がありました。
フロントエンド
フロントエンド層はクライアントとS3のやり取りを担当します。 S3では、ピークトラフィックが 1PB/s を超えることもあります。クライアントとS3がスムーズにやり取りするためにはフロントエンドとのやり取りがスケールするように実装するのが大切です。 このセッションでは、マルチパートアップロード及びレンジを使う方法や、リクエストを複数のIPへ分散する方法が紹介されていました。
マルチパートアップロードとレンジ
マルチパートアップロードとは、クライアント側で送りたいデータを分割して、並列にデータ転送する方法です。 データをまとめて転送すると何か障害があった場合に全てやり直す必要がありますが、 データを分割して並列で送信することで、障害があってもそこからやり直すことができる上に、高速化が期待できます。
この方法はAPIとして提供されています。
(https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/mpu-upload-object.html)
詳細は利用する言語によって異なりますが、例えば AWS CLI では、最初に create-multipart-upload を呼び出し、パーティションの回数分 upload-part を呼び出し、最後にcomplete-multipart-upload を呼びだすことで、マルチパートアップロードが実現されます。
データを取得する際にも、同様の並列化をすることができます。AWS CLI では、get-object-attributes で範囲を取得した上で、get-object --range を必要な回数実行することで実現されます。
リクエストを複数の IP へ分散する
DNS の MVA(multi-value answer) という機能を利用して、一つのURLに対して複数のIPアドレスを返すようにすることで、負荷を分散することができます。この方法は新しい AWS SDK を使用していれば自動で適用されます。
インデックス
インデックス層では、ストレージ層への key/value マッピングを行います。 S3 には350兆のオブジェクトが保存されていて、1秒あたり1億個以上のリクエストを処理する必要があります。
S3では、プレフィックスあたり 3500 PUT/s, 5500 GET/s 以上を処理できます。 キーのプレフィックスとは、オブジェクトキー名の先頭にある文字列です。S3を普通に使っていると、bucket/hoge/fuga/piyo.jpg のように、ディレクトリ構造を表したような文字列が現れます。しかし、S3は内部的にはディレクトリ構造をしているわけではなく、key/value 型のストレージでしかありません。
あくまで S3 がボトルネックになる場合の話ですが、適切なキーの命名方法として、キー名のカーディナリティを左に寄せておくことや、日付を入れるならなるべく右側にすることが挙げられていました。
ストレージ
ストレージ層では、保存されたデータが失われることのないように、冗長性を確保しつつデータを保持します。 S3 では、数百万個のHDDを使用し、エクサバイトのデータを保持しています。 また、S3 は、99.999999999% の耐久性と、99.9%の可用性を保障しています。 そのための方法として、さまざまな場所でチェックサムを取ることで整合性チェックをすること、データは冗長性をもって保持すること、定期的に耐久性監査を行うことが挙げられていました。 また、AZ(avairability zone)の範囲で障害が起こっても大丈夫なように、S3では複数のAZにデータを保持することがデフォルトになっています。
Express One Zone
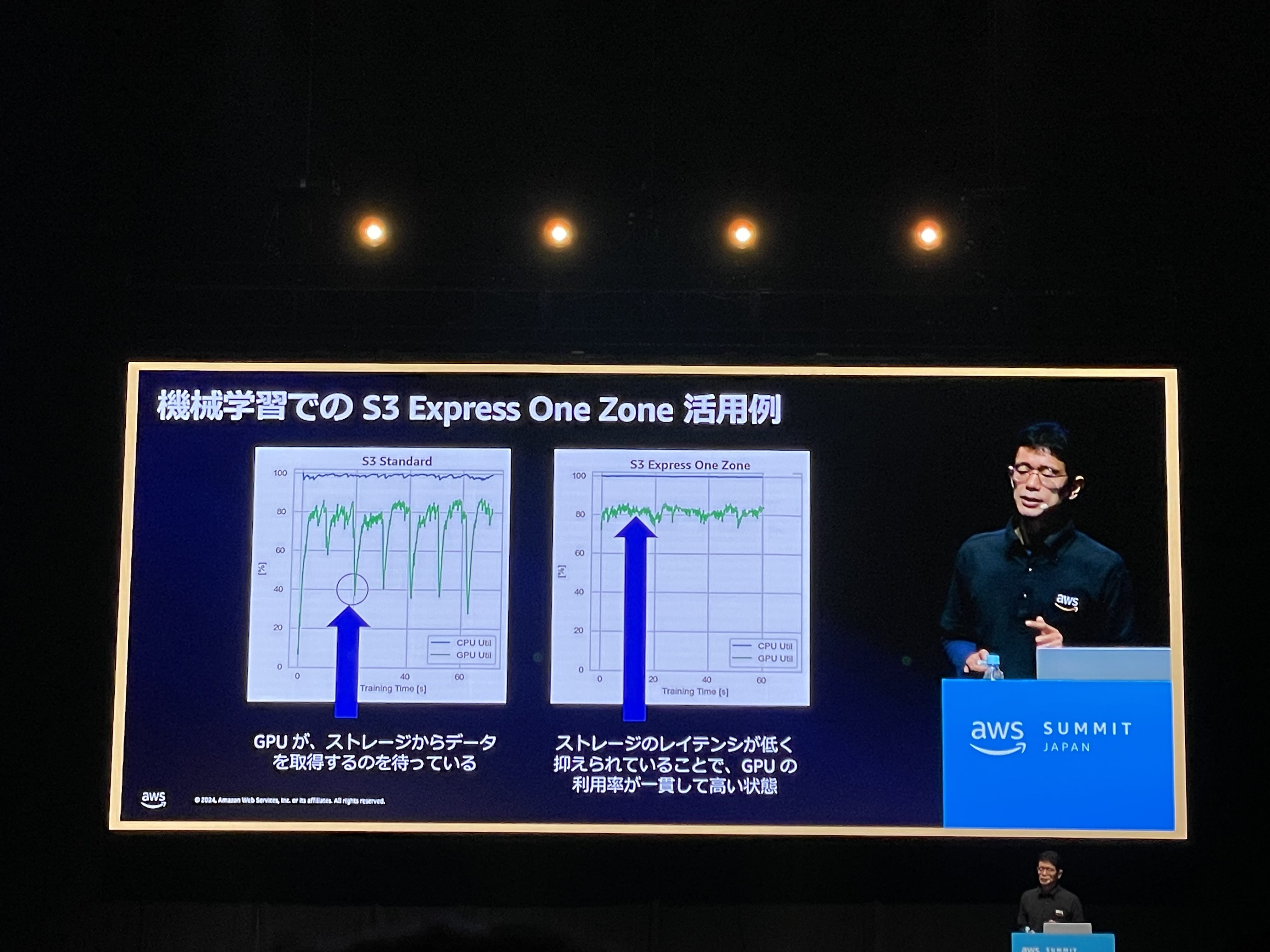
例外として、つい最近 Amazon S3 Express One Zone というストレージクラスができました。 マルチAZ による耐障害性の恩恵を受けることはできませんが、それ以外の部分では同じ耐久性を実現しています。 ストレージI/O のレイテンシがボトルネックとなる場合に利用すると効果的である場合があります。
セッション: IPv6 on AWS 〜Public IPv4 アドレス削減に向けてできることできないこと〜
IPv6 を使おう!というセッションです。
IPv4アドレスはすでに枯渇しており、AWS でもパブリックなIPv4アドレスの使用が全て有料になりました。 (https://aws.amazon.com/jp/blogs/news/new-aws-public-ipv4-address-charge-public-ip-insights/)
そのため、IPv6 を使うことが推奨されますが、通信相手も IPv6 を使用可能な環境を整える必要があるため、特にインターネット向けのサービスを提供するリソースでは、IPv4 を廃止して IPv6 へ移行することはまだ難しい状況です。
AWS はIPv6のサポート状況を公開しています。(https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/aws-ipv6-support.html)
表中のデュアルスタックとは、IPv4 と IPv6 の両方を使用する設定を指します。表を見ると、ほとんどのサービスがデュアルスタックの構成に対応していることがわかると思います。
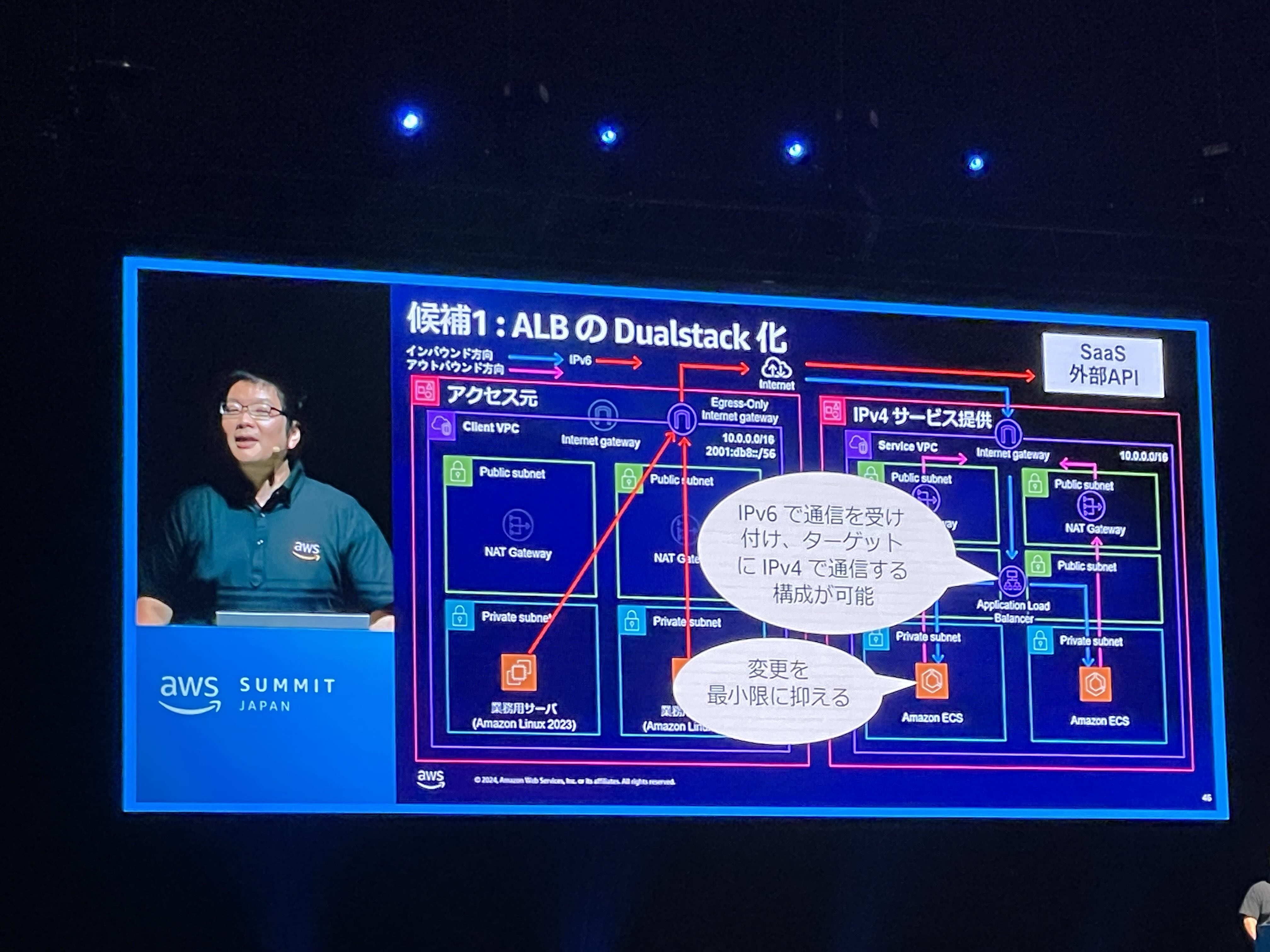
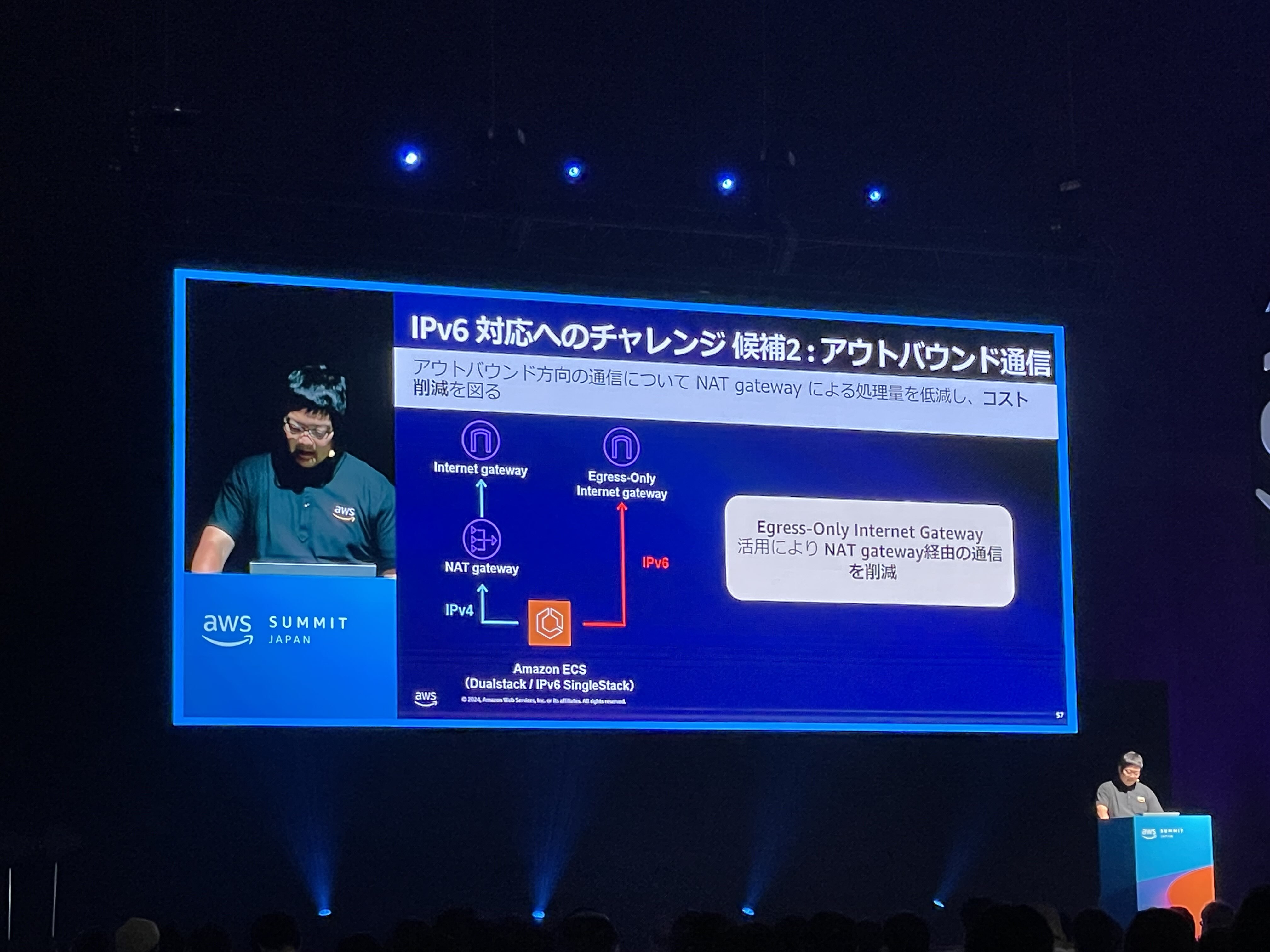
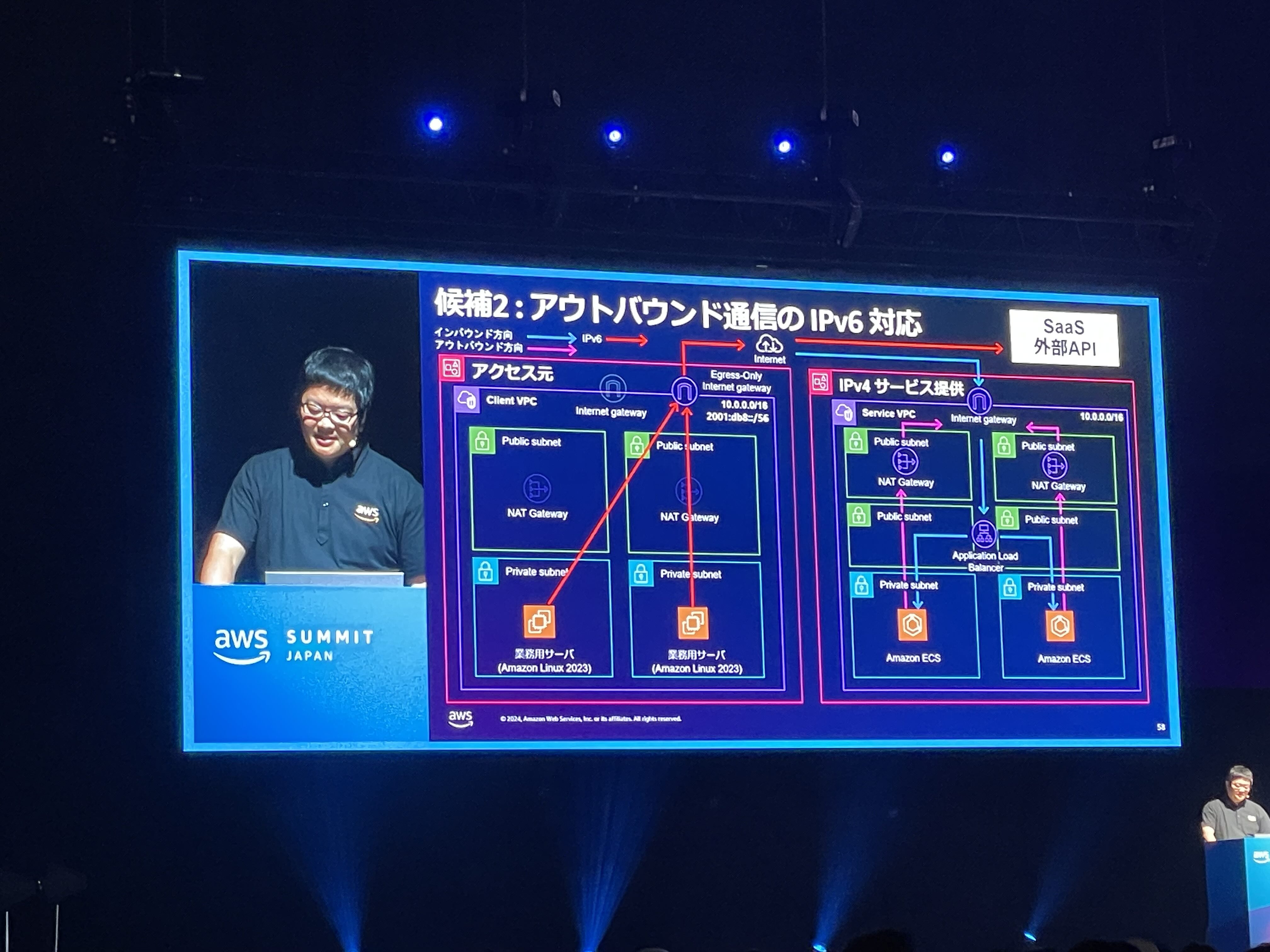
VPC 内からインターネットを通して外部サービスやユーザーと通信するときは、ゲートウェイを用います。 IPv6と関係があるものでは Internet Gateway, NAT Gateway, Egress-only Internet Gateway などがあります。 Internet Gateway は VPC(Virtual Private Cloud) から Internet と、Internet から VPC の双方向の通信に対応しており、EC2 インスタンスがもつ IPv6 アドレスが global IP アドレスとして機能します。 NAT gateway は、プライベートIPアドレスをグローバルIPアドレスに変換します。AWS では主に、VPCの内部から外部への接続は許しながらも、外部から内部の接続はできないようにするために用いられます。 Egress-only Internet Gateway は、NAT gateway のように内部から外部への片方向の通信を IPv6 環境においても実現するものです。IPv6ではルータを越える通信で用いるアドレスがグローバルに一意であり NAT 機能は必要ではありません。
IPv6 を導入することで、コスト削減が可能な場合があります。 この発表ではコスト削減の方法として
- ALB の Dualstack 化
- アウトバウンド通信の IPv6 対応
の二つが挙げられていました。
ALB の Dualstack 化

アウトバウンド通信の IPv6 対応
より詳しい内容が、以下のドキュメントに記載されています。
IPv6 on AWS ホワイトペーパー
https://docs.aws.amazon.com/ja_jp/whitepapers/latest/ipv6-on-aws/IPv6-on-AWS.html
IPv6 on AWS リファレンスアーキテクチャ
https://d1.awsstatic.com/architecture-diagrams/ArchitectureDiagrams/IPv6-reference-architectures-for-AWS-and-hybrid-networks-ra.pdf
ブース: AWS Snowball Edge

AWS Snowball Edge というサービスの紹介です。このサービスは、数十〜数百TB規模のデータを物理的に配送することで S3 で取り扱えるようにするものです。
このサービスを利用すると、物理デバイスが実際に送られてきて、手元でデータを取り込んだ後、AWSへ返送することになります。数十TBのデータを送信するならインターネットを通して送信するよりもHDDを新幹線で運んだ方が早いという話を聞いたことがある方もいるかもしれませんが、要はそれと同じことをやっています。
物理デバイスを実際に持たせてもらったのですが、それなりに重かったです。
ブース: AWS Outposts サーバー

AWS Outposts というサービスの紹介です。 ローカルでのデータ処理や、低レイテンシな処理を行うために、オンプレミス環境でAWSのサービスを利用できるようにするサービスです。
このサービスを利用すると、AWSが用意する専用のラックを自社のデータセンターなどに設置し、運用することができます。一家に一台 AWS サーバーの時代もすぐそこです。
ブース: AWS で妄想してみた

QuizKnock と AWS の方々が「こんなことできたらいいな」を考え、それをAWSで実現しよう!という企画です。QuizKnock の鶴崎さんが考えた、自動でクイズを出題してくれる「問題出し出しマシン」が印象的でした。
動画にもなっています: https://youtu.be/A48J4i8VMsY?si=vm7l4LOcq_tg4Uds
ミニセッション: 生成AIを支えるインフラ技術 〜AWS自社設計アクセラレーター AWS Tranium、Inferentia 搭載インスタンス〜
会場ではメインのセッションとは別にミニセッションという形で、ブースがあるところにディスプレイを置いてLTのような形式で発表が行われていました。ここではそのうちの一つとして、AWS が開発したハードウェアアクセラレータに関する発表を紹介します。

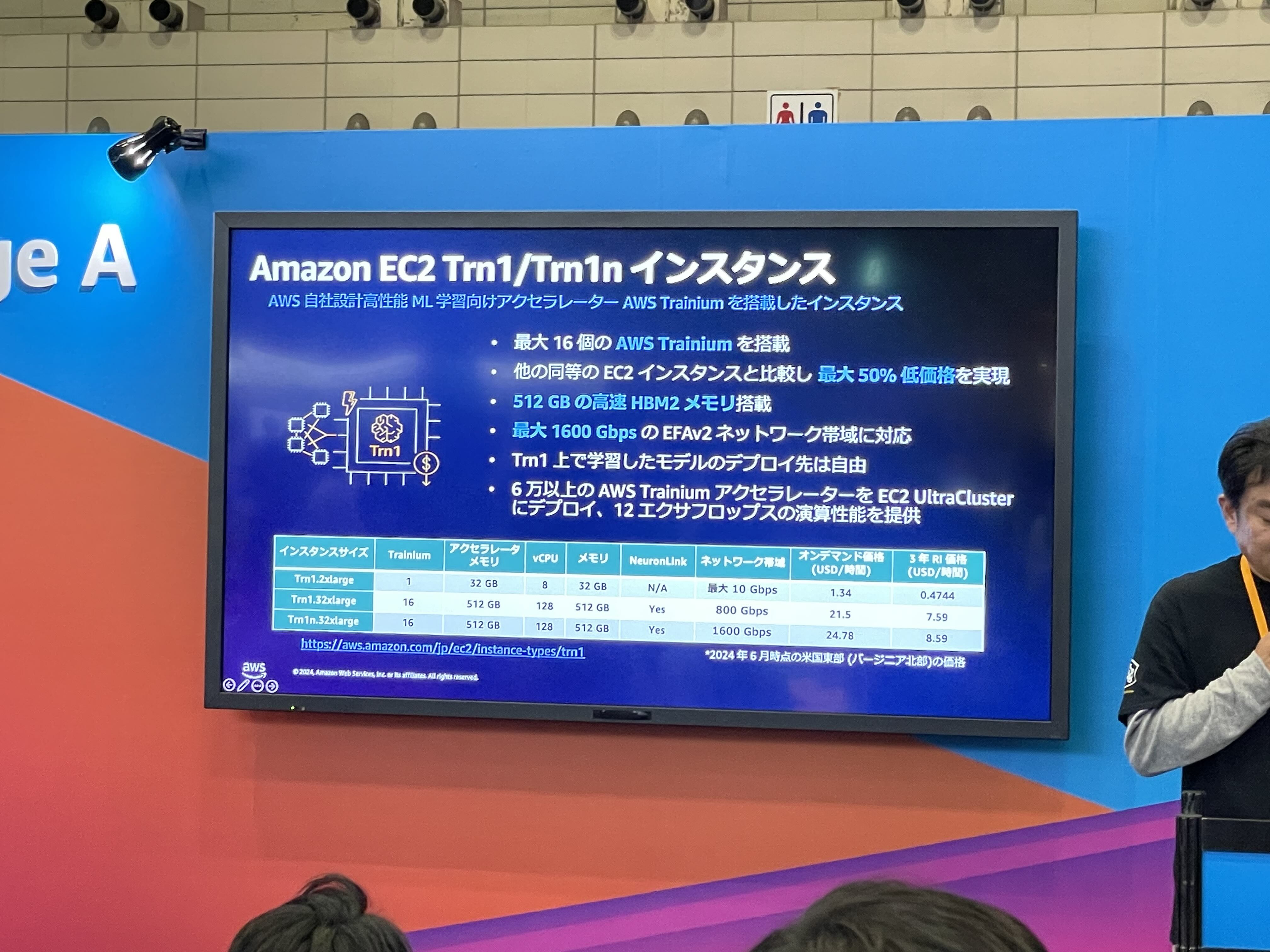
AWS は独自のハードウェアアクセラレータとして、AWS Inferentia, AWS Tranium, AWS Tranium2 を開発してきました。これらを搭載したインスタンスもあります。
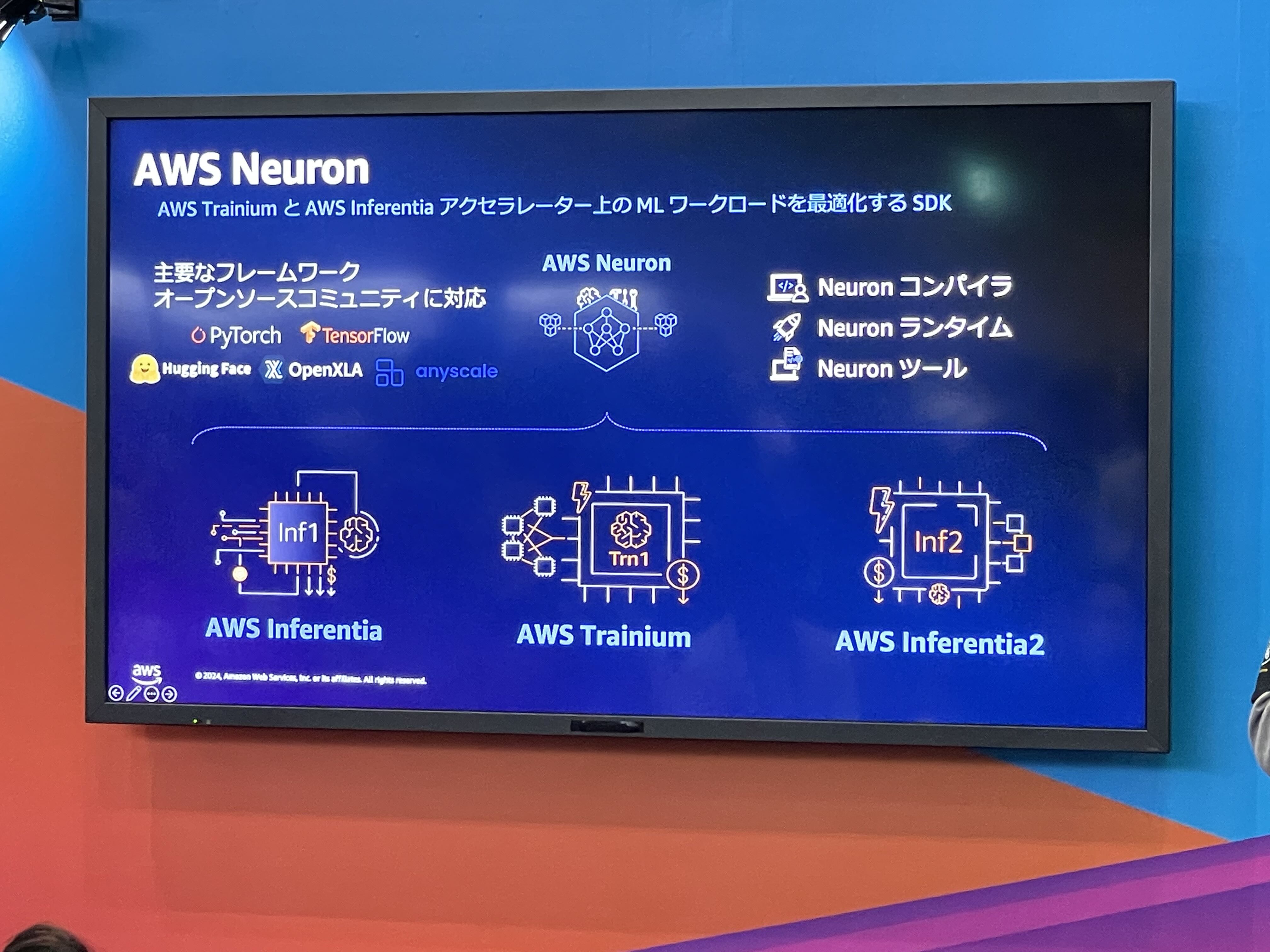

(現在も購入することができるようです: https://techbookfest.org/product/gF7Ev0CZzxk1xQcjNB1mYU?productVariantID=rJE2RiJcfYrzG6hNrVtDNf)
おわりに
このブログでは、AWS Summit 2024 について紹介しました。 ここに書いた他にも、事前に作成した学習モデルを指定の車体に搭載してコースを走る、DeepRacer というレースが開催されていたり、AWS を利用している企業の方々が発表する事例紹介セッションがあったりしました。 まさしく AWS 漬けの一日で、とても楽しむことができました! イベントへの参加は無料ですので、読んで頂いたみなさんも来年参加されてはいかがでしょうか?

ソフトウェアエンジニア
前田 陽平
2023年新卒でリクルートに入社。データプロダクトマネジメント2部所属。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


