

はじめに
ファイナンスデータソリューショングループの高橋です。今回は、Snowflakeに存在するデータを定期的にGCSに連携する方法について紹介します。特にTerraformを用いた実装例は、web上で検索しても見つからなかったので皆さんの参考になれば幸いです。
背景
私が所属しているファイナンス領域では、社内のデータを活用して分析するだけでなく、社外にしか存在しないデータを収集することも重要なテーマとなっています。収集対象としたいデータはいくつかあるのですが、その中で重要なものの一つが Snowflake Marketplace で公開されている Prepper Open Data Bank でした。Prepper Open Data Bank(以下、PODB)では、国政調査などの商用・二次利用可能なオープンデータを加工した状態で提供してくれています。
所属しているグループでは、GCP環境をメインで使用しているため、他のデータと組み合わせて活用するためには、SnowflakeとGCP間でデータ連携を行う必要がありました。
SnowflakeからGCSへデータを連携する方法について
SnowflakeからGCPへのデータ連携方法を調べてみると、 SnowflakeからBigQueryへの移行 というGCPの公式ガイドを見つけました。そこで推奨されていた方法が、GCSにデータを直接エクスポートするというものであり、Snowflake側で提供されているストレージ統合オブジェクトを構成することで、比較的容易にデータ連携を行えるとのことでした。
必要な手順についてまとめると、以下のようになります。
- (GCP) データ連携先となるGCSバケットを作成する。
- (Snowflake) 1で作成したバケットを指定してストレージ統合オブジェクトを作成する。
- (GCP) 2で作成したストレージ統合オブジェクト用に作成されたGCPのサービスアカウントを取得し、必要な権限を付与する。
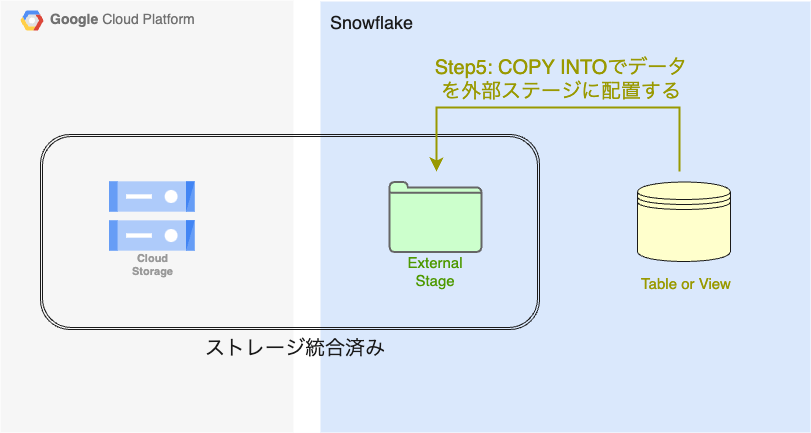
- (Snowflake) ストレージ統合オブジェクトを参照する外部ステージを作成する。(Snowflakeの外部ステージ = GCSバケットという状態になる)
- (Snowflake) 4で作成した外部ステージにデータを配置する。つまり、GCSバケットにデータが配置される。
- (Snowflake) 必要に応じて5の作業を定期的に実行するタスクを作成する。
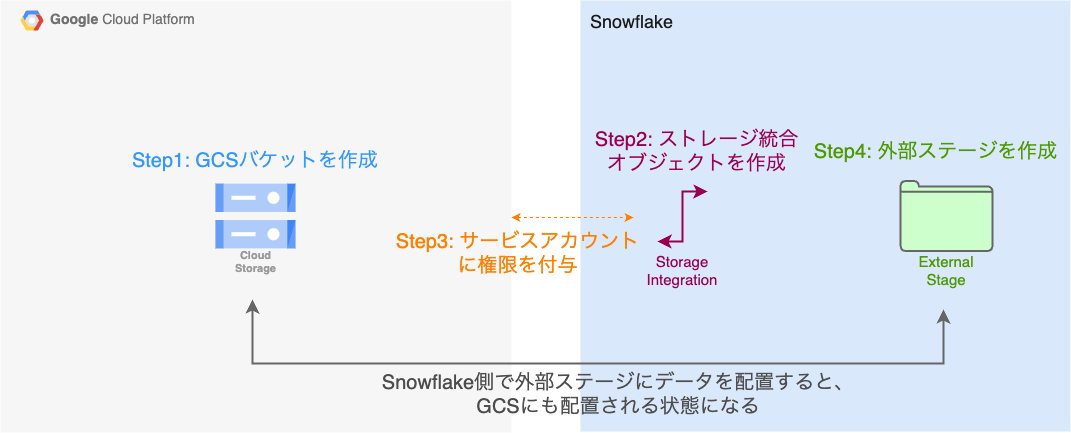
Snowflakeのドキュメントでわかりやすく説明されているため、詳細が気になる方はそちらも合わせてご確認ください。
- Google Cloud Storageの統合の構成 : 手順の2~4にあたる内容
- Google Cloud Storageへのアンロード : 手順の5にあたる内容
参考までに、PODBのJAPANESE CORPORATE DATA(全体で6GB程度)を全てSnowflakeからGCSに連携した場合にかかる費用について触れておくと、環境にもよりますがおよそ100円以内で実現できていると思います。
Terraformで実現するために
Terraformで実現することを選択した理由
公式ガイド のようにSnowflake上でクエリを実行することで、データ連携は実現できるのですが、以下のような問題があります。
- 誰がどのタイミングでどのような設定でリソースを作成したのか把握しづらい
- dev,stg,prdのように環境を分けている場合に、環境ごとに設定が必要で手間がかかる
そこで、インフラをコードで管理するIaCツールを使用することにしました。すでに他のGCPのリソースは、Terraformで管理していたため、新たにSnowflakeのリソースを追加する形で実装を進めることにしました。
Terraformによる実装
まず、Terraformで実装を進めるにあたり参考にしたブログ記事を紹介します。 https://medium.com/akava/snowflake-backups-to-amazon-s3-using-terraform-4519ddfc0c0c
この記事は少し古く、GCSではなくAWS S3を対象としているのですが、Terraformでの実装例が詳しく紹介されていて、とても参考になりました。もし、この記事がなければ実装にかなりの時間がかかったと思っており、とても感謝しています。
今回は、上記の記事の実装をベースにしつつ、大きく以下の2つの点を変更しました。
- AWSに関するリソースをGCPに関するリソースに変更
- Snowflakeの権限周りのリソースをsnowflake_grant_privileges_to_account_roleに統一(公式から推奨されているため)
使用するSnowflakeのリソースの紹介
具体的な実装に入る前に、使用するSnowflakeのリソースについて紹介しておきます。
- ユーザー:オブジェクトの操作などを行うエンティティのこと
- ロール:ユーザーに割り当てる権限のこと
- ウェアハウス:SQLの実行に使用されるコンピューティングリソースのこと
- データベース:データを保持する場所のこと
- スキーマ:テーブルやビューのようなデータベースオブジェクトのグループのこと
- ストレージ統合:外部のクラウドストレージとの統合を実現するオブジェクトのこと
- 外部ステージ:外部のクラウドストレージを参照できるようにするオブジェクトのこと
- ストアドプロシージャ:複数の処理をまとめて、繰り返し実行できるようにする機能のこと
- タスク:定期的に処理を実行できるようにする機能のこと
ファイル構成
実装は以下のような構成で行いました。
snowflake_to_gcs/
├── external_stage.tf
├── gcs.tf
├── iam.tf
├── procedure.js
├── procedure.tf
├── provider.tf
├── role.tf
├── storage_integration.tf
├── task.tf
└── warehouse.tf
各ファイルの中身について
先ほど説明したデータ連携に必要な手順と合わせる形で紹介していきます。 {PROJECT_ID}のように{}で囲んである部分に関しては、別途variableで定義するなどして置き換えてください。
Step 0: Providerを指定する。
provider.tf
terraform {
required_providers {
snowflake = {
source = "Snowflake-Labs/snowflake"
version = "0.93.0" # 実装時のバージョンのため、適宜変更してください
}
google = {
source = "hashicorp/google"
version = "5.37.0" # 実装時のバージョンのため、適宜変更してください
}
}
}
provider "snowflake" {
alias = "account_admin"
role = "ACCOUNTADMIN"
}
provider "snowflake" {
alias = "sys_admin"
role = "SYSADMIN"
}
provider "snowflake" {
alias = "security_admin"
role = "SECURITYADMIN"
}
provider "google" {
project = "{PROJECT_ID}"
region = "{REGION}"
}
Step 1: (GCP) データ連携先となるGCSバケットを作成する。
gcs.tf
resource "google_storage_bucket" "snowflake_integration" {
name = "{BUCKET_NAME}"
location = "US-CENTRAL1" # Snowflakeのリージョンと合わせている
uniform_bucket_level_access = true
storage_class = "STANDARD"
}
Step2: (Snowflake) 1で作成したバケットを指定してストレージ統合オブジェクトを作成する。
role.tf
# 実行時に指定されているロールを取得
data "snowflake_current_role" "this" {
}
storage_integration.tf
# GCSに対してストレージ統合を作成
resource "snowflake_storage_integration" "gcs_integration" {
provider = snowflake.account_admin
name = "{INTEGRATION_NAME}"
type = "EXTERNAL_STAGE"
enabled = true
storage_provider = "GCS"
storage_allowed_locations = ["gcs://{BUCKET_NAME}/"]
}
# 作成したストレージ統合を使用する権限を付与
resource "snowflake_grant_privileges_to_account_role" "integration_grant" {
privileges = ["USAGE"]
account_role_name = data.snowflake_current_role.this.name
on_account_object {
object_type = "INTEGRATION"
object_name = snowflake_storage_integration.gcs_integration.name
}
}
Step3: (GCP) 2で作成したストレージ統合オブジェクト用に作成されたGCPのサービスアカウントを取得し、必要な権限を付与する。
iam.tf
# ストレージ統合で作成されたサービスアカウントにカスタムロールを付与
resource "google_project_iam_custom_role" "snowflake_integration" {
project = "{PROJECT_ID}"
role_id = "snowflake_integration"
title = "Snowflake Storage Integration Custom Role"
stage = "GA"
# https://docs.snowflake.com/ja/user-guide/data-load-gcs-config#creating-a-custom-iam-role データのアンロードのみ
permissions = [
"storage.buckets.get",
"storage.objects.create",
"storage.objects.delete",
"storage.objects.list",
]
}
resource "google_project_iam_member" "snowflake_integration" {
provider = google
project = "{PROJECT_ID}"
role = google_project_iam_custom_role.snowflake_integration.name
# ここで先ほど作成したストレージ統合オブジェクト用に作成されたサービスアカウントを取得
member = "serviceAccount:${snowflake_storage_integration.gcs_integration.storage_gcp_service_account}"
}
Step4: (Snowflake) ストレージ統合オブジェクトを参照する外部ステージを作成する。
external_stage.tf
# 外部ステージを配置するデータベースを作成
resource "snowflake_database" "gcs_integration" {
provider = snowflake.sys_admin
name = "{DATABASE_NAME}"
}
# 作成したデータベースを使用する権限を付与
resource "snowflake_grant_privileges_to_account_role" "database_grant" {
privileges = ["USAGE"]
account_role_name = data.snowflake_current_role.this.name
on_account_object {
object_type = "DATABASE"
object_name = snowflake_database.gcs_integration.name
}
}
# 外部ステージを配置するスキーマを作成
resource "snowflake_schema" "gcs_integration" {
provider = snowflake.sys_admin
name = "{SCHEMA_NAME}"
database = snowflake_database.gcs_integration.name
}
# 作成したスキーマを使用する権限を付与
resource "snowflake_grant_privileges_to_account_role" "schema_grant" {
privileges = ["USAGE"]
account_role_name = data.snowflake_current_role.this.name
on_schema {
schema_name = "\"${snowflake_database.gcs_integration.name}\".\"${snowflake_schema.gcs_integration.name}\""
}
}
# 外部ステージを作成
resource "snowflake_stage" "gcs_integration" {
provider = snowflake.account_admin
name = "{EXTERNAL_STAGE_NAME}"
url = "gcs://{BUCKET_NAME}/" # 接続するGCSバケットを指定
database = snowflake_database.gcs_integration.name
schema = snowflake_schema.gcs_integration.name
# 扱いたいファイルの形式に合わせて変更してください (https://docs.snowflake.com/ja/sql-reference/sql/create-file-format)
file_format = "TYPE=CSV COMPRESSION=NONE FIELD_OPTIONALLY_ENCLOSED_BY='\"' EMPTY_FIELD_AS_NULL=FALSE NULL_IF=''"
storage_integration = snowflake_storage_integration.gcs_integration.name
}
# 作成した外部ステージを使用する権限を付与
resource "snowflake_grant_privileges_to_account_role" "stage_grant" {
privileges = ["USAGE"]
account_role_name = data.snowflake_current_role.this.name
on_schema_object {
object_type = "STAGE"
object_name = "\"${snowflake_database.gcs_integration.name}\".\"${snowflake_schema.gcs_integration.name}\".\"${snowflake_stage.gcs_integration.name}\""
}
}
Step5: (Snowflake) 4で作成した外部ステージにデータを配置する。つまり、GCSバケットにデータが配置される。
対象データが少ない場合は、一つずつCOPY INTOを実行して外部ステージにデータを配置するだけで良いと思います。(https://docs.snowflake.com/ja/sql-reference/sql/copy-into-location)
対象データが多かったり、定期的に実行したりしたい場合は、これ以降のステップの実装(ストアドプロシージャとタスクを使用)を参考にしてみてください。
procedure.js
// TARGET_DATABASE.TARGET_SCHEMAに存在するすべてのテーブル、ビューを対象にする
let view_names = getViewNames(TARGET_DATABASE, TARGET_SCHEMA);
let table_names = getTableNames(TARGET_DATABASE, TARGET_SCHEMA);
while (view_names.next()) {
let view = view_names.getColumnValue(1);
copyToGCS(TARGET_DATABASE, TARGET_SCHEMA, view, STAGE_DATABASE);
}
while (table_names.next()) {
let table = table_names.getColumnValue(1);
copyToGCS(TARGET_DATABASE, TARGET_SCHEMA, table, STAGE_DATABASE);
}
return `Unloading '${TARGET_DATABASE}'.'${TARGET_SCHEMA}' to GCS successfully finished.`;
// 現在の日付を取得し、データ保存時のパスに使用
function getCurrentDate() {
let sqlResult = snowflake.execute({
sqlText: `SELECT TO_VARCHAR(CURRENT_DATE());`,
});
sqlResult.next();
return sqlResult.getColumnValue(1);
}
// target_database.target_schemaに存在するviewの名前を取得
function getViewNames(target_database, target_schema) {
return snowflake.execute({
sqlText: `
SELECT table_name
FROM ${target_database}.information_schema.views
WHERE table_schema = '${target_schema}'
`,
});
}
// target_database.target_schemaに存在するtableの名前を取得
function getTableNames(target_database, target_schema) {
return snowflake.execute({
sqlText: `
SELECT table_name
FROM ${target_database}.information_schema.tables
WHERE table_schema = '${target_schema}'
`,
});
}
// tableに存在するカラム一覧を取得する
function getColumnNames(target_database, target_schema, table) {
return snowflake.execute({
sqlText: `
SELECT column_name
FROM ${target_database}.information_schema.columns
WHERE table_schema = '${target_schema}' AND table_name = '${table}'
ORDER BY ordinal_position
`,
});
}
// COPY INTOコマンドで外部ステージにデータを配置
function copyToGCS(target_database, target_schema, table, stage_database) {
let column_names = getColumnNames(target_database, target_schema, table);
let select_statement = "";
while (column_names.next()) {
let column_name = column_names.getColumnValue(1);
// 改行記号を削除したいため
select_statement += `REPLACE(${column_name}, '\\n', '') AS ${column_name}, `;
}
snowflake.execute({
sqlText: `
COPY INTO @${stage_database}.EXTERNAL_STAGE.GCS-INTEGRATION-STAGE/${target_database}/${target_schema}/${getCurrentDate()}/${table}.csv
FROM (SELECT ${select_statement} FROM ${target_database}.${target_schema}.${table})
single = true
HEADER = true
OVERWRITE = true
MAX_FILE_SIZE = 4900000000
`,
});
}
procedure.tf
# 特定のdatabase.schemaに存在するデータをGCSにコピーするプロシージャを作成
resource "snowflake_procedure" "unload_to_gcs" {
provider = snowflake.sys_admin
name = "{PROCEDURE_NAME}"
database = snowflake_database.gcs_integration.name
schema = snowflake_schema.gcs_integration.name
language = "JAVASCRIPT"
arguments {
name = "TARGET_DATABASE"
type = "VARCHAR"
}
arguments {
name = "TARGET_SCHEMA"
type = "VARCHAR"
}
arguments {
name = "STAGE_DATABASE"
type = "VARCHAR"
}
comment = "Unload data to GCS"
return_type = "VARCHAR"
execute_as = "CALLER"
null_input_behavior = "RETURNS NULL ON NULL INPUT"
statement = file("${path.module}/procedure.js")
}
# 作成したプロシージャを使用する権限を付与
resource "snowflake_grant_privileges_to_account_role" "procedure_grant" {
privileges = ["USAGE"]
account_role_name = data.snowflake_current_role.this.name
on_schema_object {
object_type = "PROCEDURE"
object_name = "\"${snowflake_database.gcs_integration.name}\".\"${snowflake_schema.gcs_integration.name}\".${snowflake_procedure.unload_to_gcs.name}(VARCHAR, VARCHAR, VARCHAR)"
}
}
Step6: (Snowflake) 必要に応じて5の作業を定期的に実行するタスクを作成する。
warehouse.tf
# GCSへのデータアンロード用のウェアハウスを作成
resource "snowflake_warehouse" "unload_to_gcs" {
# dev,stg,prdで同じものを使用し、再作成を行うとエラーが出るためdevの場合のみ作成とする
# IS_DEVは、dev環境で動かすときのみ1となるように設定する
count = {IS_DEV} == 1 ? 1 : 0
provider = snowflake.sys_admin
name = "{WAREHOUSE_NAME}"
warehouse_size = "X-SMALL"
comment = "Warehouse for unloading data to GCS"
# 参考: https://zenn.dev/mnagaa/books/3d668d2dfc657e/viewer/4c7e1f
auto_resume = true
auto_suspend = 60
statement_timeout_in_seconds = 3600
initially_suspended = true
}
# 作成したウェアハウスを使用する権限を付与
resource "snowflake_grant_privileges_to_account_role" "warehouse_grant" {
privileges = ["USAGE"]
account_role_name = data.snowflake_current_role.this.name
on_account_object {
object_type = "WAREHOUSE"
object_name = "{WAREHOUSE_NAME}"
}
}
task.tf
# stored_procedureを定期実行するtaskを作成
# unloadするデータを増やす際は、ここにdatabase, schemaを追加する
locals {
unload_database_schema_list = [
# https://podb.truestar.co.jp/archives/corp-data を対象としている
{
"name" = "PODB_JAPANESE_CORPORATE_DATA",
"database" = "PREPPER_OPEN_DATA_BANK__JAPANESE_CORPORATE_DATA",
"schema" = "E_PODB"
}
]
}
# タスク実行用にTASKADMINロールを作成
resource "snowflake_role" "task_admin" {
# dev,stg,prdで同じものを使用し、再作成を行うとエラーが出るためdevの場合のみ作成とする
# IS_DEVは、dev環境で動かすときのみ1となるように設定する
count = {IS_DEV} == 1 ? 1 : 0
provider = snowflake.security_admin
name = "{TASK_ADMIN_NAME}"
}
# TASKADMINにtask実行に必要な権限を付与
resource "snowflake_grant_account_role" "task_admin_grant" {
provider = snowflake.security_admin
role_name = "{TASK_ADMIN_NAME}"
user_name = "{USER_NAME}"
}
resource "snowflake_grant_privileges_to_account_role" "task_privileges_grant" {
privileges = ["EXECUTE TASK", "EXECUTE MANAGED TASK"]
account_role_name = "{TASK_ADMIN_NAME}"
on_account = true
}
resource "snowflake_grant_privileges_to_account_role" "task_admin_database_grant" {
privileges = ["USAGE"]
account_role_name = "{TASK_ADMIN_NAME}"
on_account_object {
object_type = "DATABASE"
object_name = snowflake_database.gcs_integration.name
}
}
resource "snowflake_grant_privileges_to_account_role" "task_admin_schema_grant" {
privileges = ["USAGE"]
account_role_name = "{TASK_ADMIN_NAME}"
on_schema {
schema_name = "\"${snowflake_database.gcs_integration.name}\".\"${snowflake_schema.gcs_integration.name}\""
}
}
resource "snowflake_grant_privileges_to_account_role" "task_admin_warehouse_grant" {
privileges = ["USAGE"]
account_role_name = "{TASK_ADMIN_NAME}"
on_account_object {
object_type = "WAREHOUSE"
object_name = "{WAREHOUSE_NAME}"
}
}
# TASKADMINにアンロード対象のデータへの権限を付与
resource "snowflake_grant_privileges_to_account_role" "task_admin_unload_database_grant" {
for_each = { for i in local.unload_database_schema_list : i.name => i }
privileges = ["IMPORTED PRIVILEGES"] # Snowflake marketplaceのデータにアクセスできるようにするため
account_role_name = "{TASK_ADMIN_NAME}"
on_account_object {
object_type = "DATABASE"
object_name = each.value.database
}
}
# タスクを作成
resource "snowflake_task" "unload_to_gcs" {
for_each = { for i in local.unload_database_schema_list : i.name => i }
provider = snowflake.account_admin
database = snowflake_database.gcs_integration.name
schema = snowflake_schema.gcs_integration.name
warehouse = "{WAREHOUSE_NAME}"
name = "TASK_CALL_${snowflake_procedure.unload_to_gcs.name}_${each.value.name}"
enabled = true
schedule = "USING CRON 0 3 15 * * UTC" # 要件に合わせてスケジュールを変更してください
sql_statement = "CALL ${snowflake_procedure.unload_to_gcs.name}('${each.value.database}', '${each.value.schema}', '${snowflake_database.gcs_integration.name}')"
}
resource "snowflake_grant_privileges_to_account_role" "task_grant" {
for_each = { for i in local.unload_database_schema_list : i.name => i }
privileges = ["OPERATE"]
account_role_name = "{TASK_ADMIN_NAME}"
on_schema_object {
object_type = "TASK"
object_name = "\"${snowflake_database.gcs_integration.name}\".\"${snowflake_schema.gcs_integration.name}\".\"TASK_CALL_${snowflake_procedure.unload_to_gcs.name}_${each.value.name}\""
}
}
実現する際に困ったポイント①:Snowflakeでのdev,stg,prd環境分離への対応
Snowflake上での環境分離は以下のスライドを参考にアカウント単位ではなく、データベース単位で実施することにしました。理由としては、最低限の切り分けを実現しつつ、管理が面倒にならないようにしたかったからです。
https://speakerdeck.com/kevinrobot34/snowflake-dbt-terraform?slide=9
データベース単位で環境分離を行う場合、各環境でSnowflakeのアカウントは同じであるため、terraform applyを行った際に、devで作成済みのリソースに対してstg,prdで再度作成しようとしてしまいます。その結果、Object xxx already exists.というエラーが出ることがあります。対策として、1度だけ作成されればいいリソースはdev環境でdeployした場合にのみ作成されるように、countを使用して対応しました。
実現する際に困ったポイント②:snowflake_grant_privileges_to_account_roleのドキュメント不足
執筆時点(2024/08)、TerraformのSnowflake providerには大きな変更が加えられ、機能の移行が進められている状態でした。その中でも、権限付与に関するリソースであり、今回の実装でも多用しているsnowflake_grant_privileges_to_account_roleは、もともとそれぞれのリソースごとに定義されていたsnowflake_xxx_grantを統合したものです。 移行直後のリソースでドキュメントも少ないため、GitHubでissueを立て、実装元とやり取りをしながら使い方について理解を深めました。つまずいたポイントは、大きく以下の2つでした。
- オブジェクトの種類に応じて、書き方が大きく2つ存在すること
- procedureでargumentを使用したい場合に、指定する引数が存在しないこと
1つ目に関しては、実装の中でon_account_objectとon_schema_objectのどちらかを引数で指定しているように、対象とするオブジェクトの種類に応じて、適切なものを選択する必要があります。
2つ目に関しては、ストアドプロシージャを定義する際に引数を指定しているのですが、引数を指定する方法が
ドキュメント
には記載されていないというつまずきポイントがありました。issueを立てて質問してみたところ、on_chema_objectのobject_nameの後ろに(arg_type1, arg_type2, ...)をつける必要があるという答えを得ることができました。
おわりに
私は、入社以来データ分析やモデリングを主に担当していて、SnowflakeもTerraformも触るのは今回の案件が初めてでした。スキル的に不安はあったものの、上司に取り組んでみたいと伝えたところチャレンジさせてもらえることになり、取り組んだ結果としてスキルの幅が広がったと感じています。
最後に、当社では、様々な職種のエンジニアを新卒・中途ともに募集しております。ご興味のある方は、以下の採用ページをご覧ください。

データサイエンティスト
高橋寛武
2021年新卒入社。ファイナンス領域でデータ分析やモデル開発を担当。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


