
はじめに
今年の10月初旬にアメリカのラスベガスで行われたdbt coalesce 2024にデータアナリティクスエンジニアの電電、木内、山家のメンバーで参加してきました。 dbt coalesceは毎年この時期に行われるdbtに関するカンファレンスですが、今年は現地での参加者2000人、オンラインでは8000人以上の参加者がおり、合計で144セッションが実施されました。今年は昨年に比べ、LLMの導入事例やsemantic layer, dbt meshの利用などの事例が多く紹介されていた印象を受けました。 各々約20セッションに参加し、今回のアドベントカレンダーでは特に面白いと感じた3つのセッションについて紹介します。
本記事は、データ推進室 Advent Calendar 2024 14日目の記事です
セッション紹介
1. Breaking the mold: A smarter approach to data testing
発表者: Anton Heikinheimo & Emiel Verkade
内容: Analytics Engineer(以下AE)は業務の中でデータ遅延や同期停止などの対処、予測しないデータの混入や常に緊急で入るデータの分析依頼などの業務によって忙しくなりがちです。この結果データの品質を管理することに手をつけられなくなり、データの品質悪化を招くことになります。 通常データの品質担保にはバリデーションテストなどを設定することが勧められますが、テストの形骸化やライフサイクルを意識できておらず運用コストがかかってしまうことがあります。そのためErrorだけでなくWarningを適切に使おうということが述べられていました。 また、dbtを用いたトランスフォームでは以下の図1のような構成がよく用いられています。その場合データソースに対するテストを左側で、Logicに対するテストを右側に示されているAssertionで実施することになります。
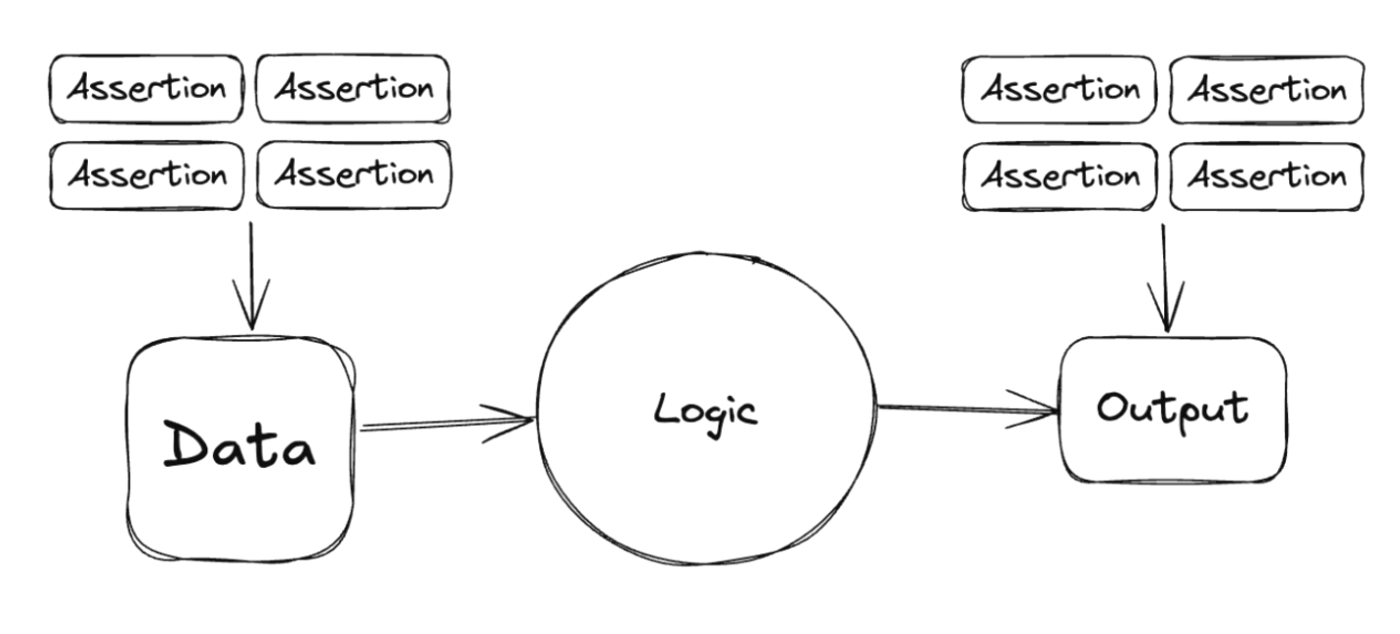
発表者はデータパイプラインのレジリエンスを向上させるためには、上記の構造に加えてsource_baseというレイヤー(図2)を既存のパイプラインに加え、そこにFiltersを設置することで、予期しないデータが入ってしまった場合でもデータパイプラインを止めることなく実行し続けることができると述べていました。
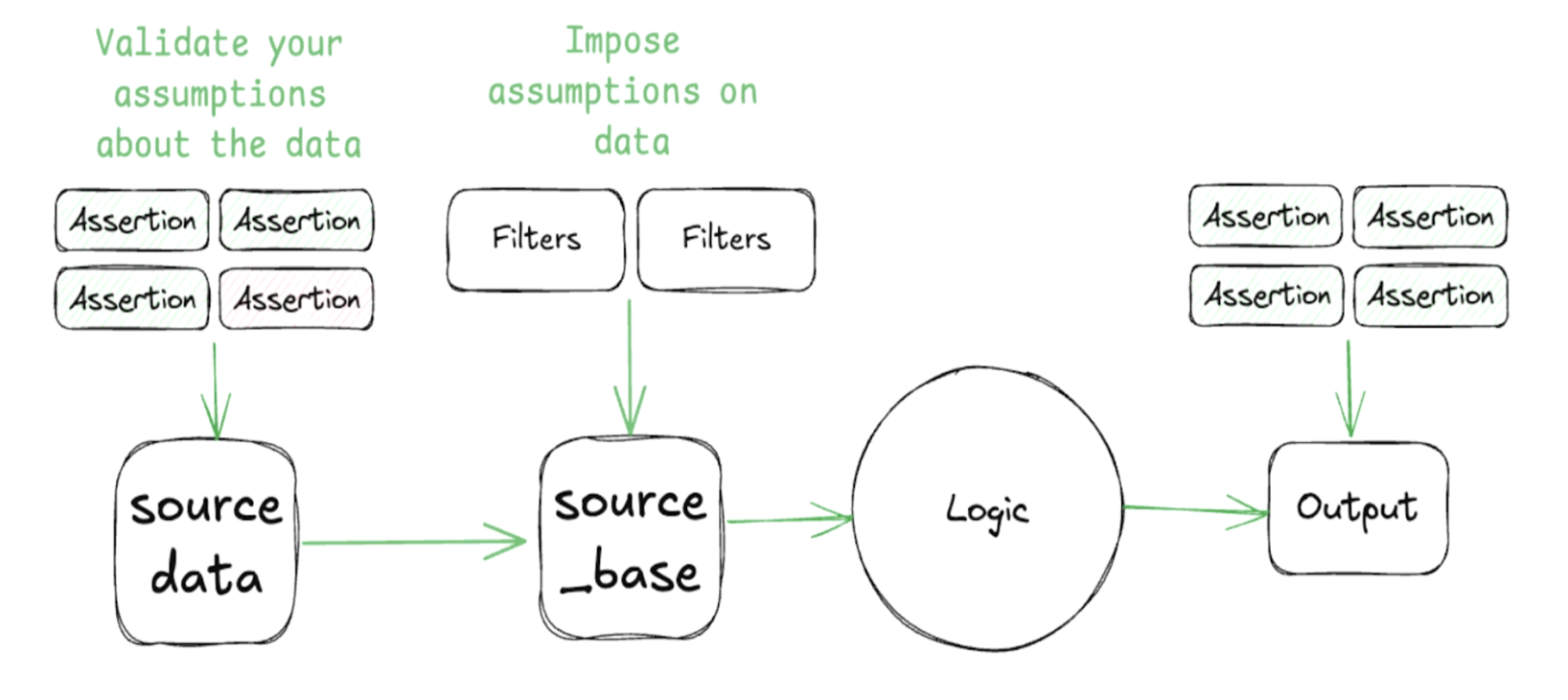
また、この際のFiltersではdbtに備わっているテストを使うのではなく、where句をSQLに設置し、dbtのマクロ機能を使うことで、スケールできるようにしていました。(具体事例は下記)
例1) nullを除外したり、特定の値のみを許容する場合
before
- name: service_type
description: ''
tests:
- not_null
- accepted_values:
values:
- pg
- mysql
after
WHERE service_type IN (
'pg'
, 'mysql'
)
AND service_type IS NOT NULL
例2) 複数のテーブルをJOINした際などに利用するrelationshipsテストの場合
before
- relationships:
to: ref('saleforce_accounts')
field: saleforce_id
after
WHERE salesforce_id IN (
SELECT DISTINCT salesforce_id
FROM {{ ref('salesforce_accounts') }}
)
データパイプラインの中で、dbtのテスト機能を使うのではなく、Filterを用いてvalidationを行うのはこれまで思いつかなかったので、目新しい発見でした。今後活かしていく場面があれば実践していきたいと思います。
まとめ:
- テスト全体のライフサイクルを考慮して重要度を定めて、テスト作成をするべき
- データに対してsource_baseというレイヤーを追加し、Filterをかけることでデータパイプライン全体のレジリエンスを高めつつ、データの品質担保を行うことができる
2. Generative AI, the ADLC and the coming era of analytics engineering
発表者: Jason Ganz
内容: アナリティクスエンジニアが注力する課題の変遷と今後について、Move up the stack(今の仕事を不要にして、より価値のあることに集中できるよう変化させるべき)という考え方と経験談を元に紹介されていました。 図3はデータ変換のフレームワークや分析時のプラクティス、またデータ自体の価値が、時代と共に進化してきたことを示しています。
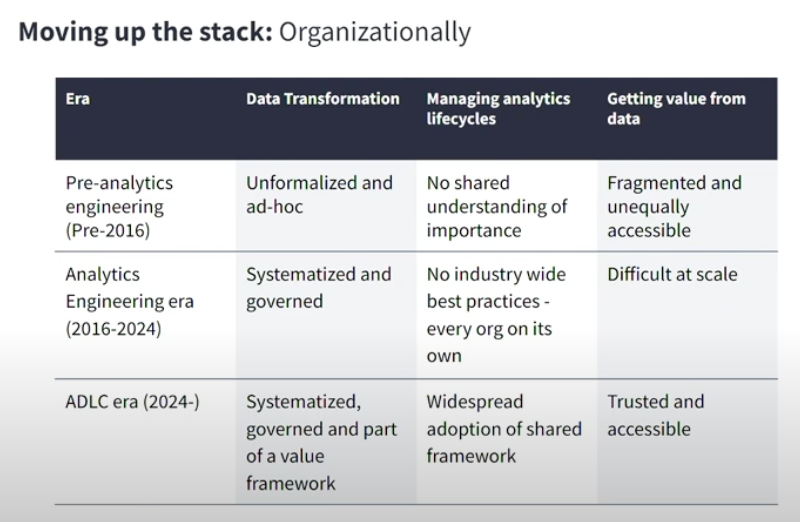
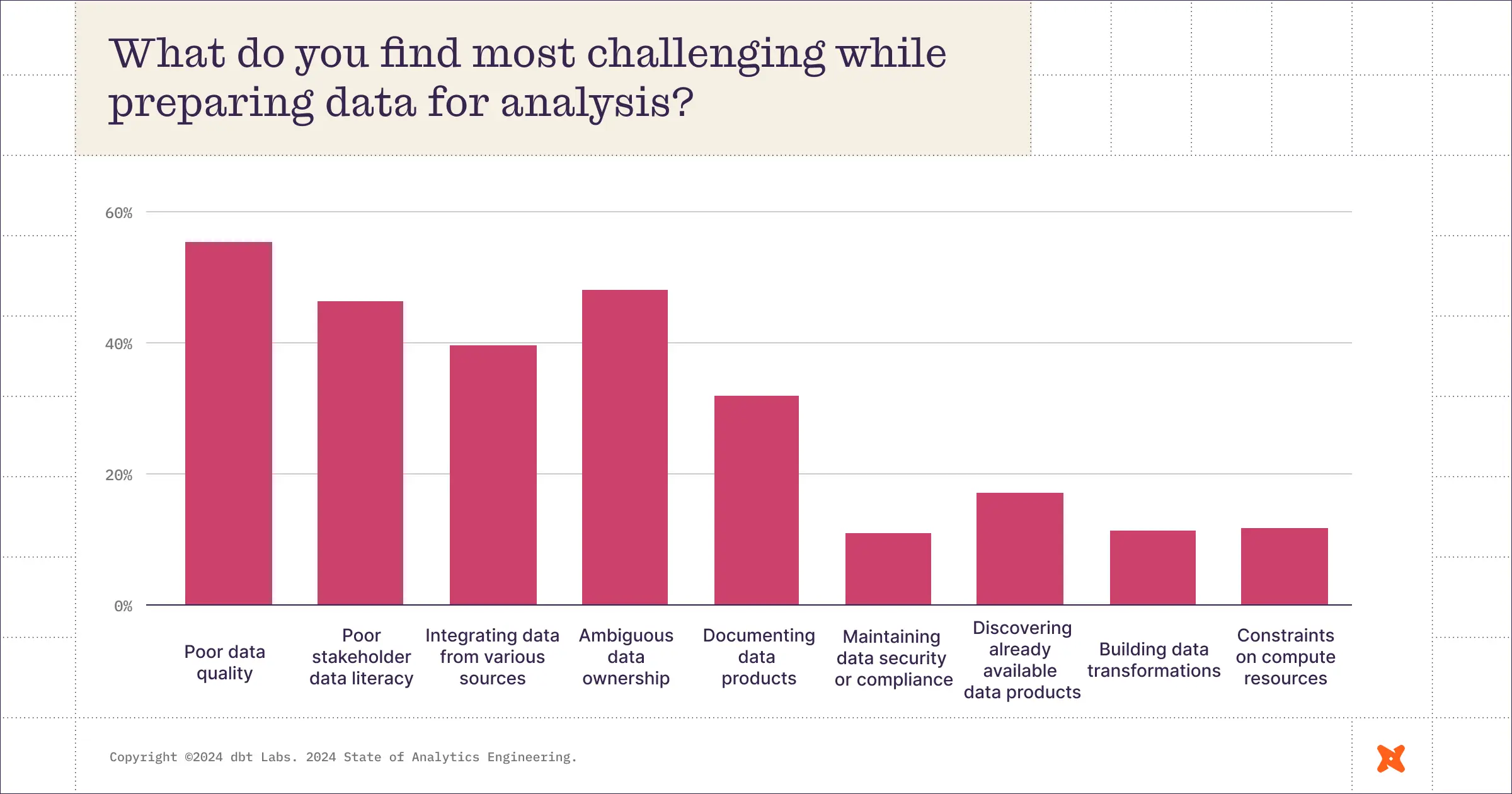
データウェアハウス(DWH)やdbtの登場により、クエリの作成・実行に注力していた時代からデータプロダクトの構築にリソースを集中できるようになった現在、多くの人が感じている課題はデータ品質とのことです。(図4の調査結果は他のセッションでも頻繁に登場していました)
データ品質改善の取り組みについても、Analytics Development Lifecycle (ADLC) や生成AIを利用しながら効率化し、より本質的な課題に集中できるよう変化させることが重要というお話でした。
- ADLCとは、分析システムもソフトウェアであるという考えのもと、その開発運用に適用するためSoftware Development Lifecycle (SDLC) をもとに作成されたフレームワークです。今回のKeynoteでも大々的に紹介されていました。
- 少し脱線しますが、ADLCの効果を最大化させるためのインターフェースとしてSemantic LayerとLLMの紹介もありました。(自然言語によるデータ問い合わせの信頼性が、Semantic Layerにより88%向上したとのこと)
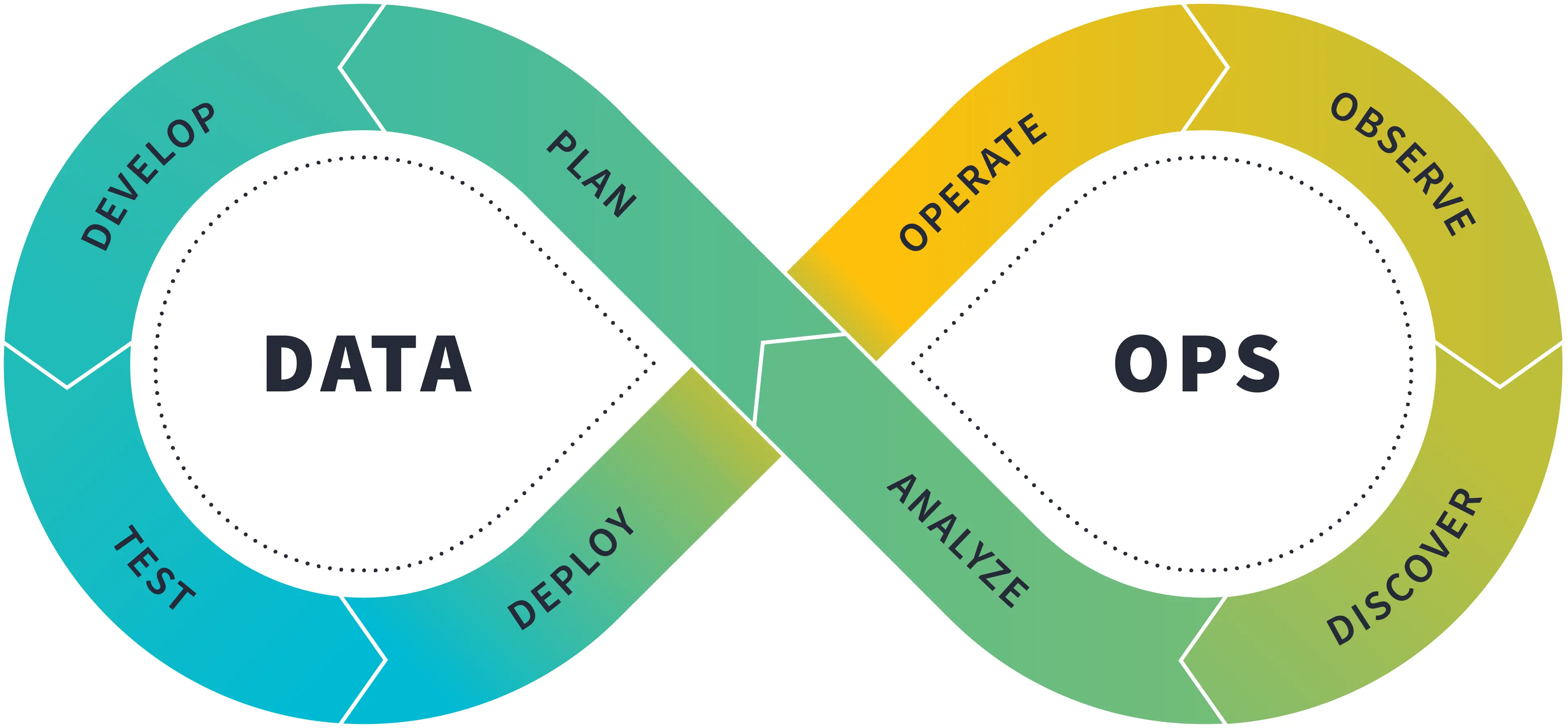
データモデルやダッシュボード等のデータ資産そのものに加え、開発運用や分析といった行為とステークホルダーを包含したプラクティスを整備・装着することで、データ信頼性向上のための組織的な文化醸成が期待できます。 また現状の開発運用・分析業務に対する健康診断としても活用できそうだなと感じました。
まとめ:
- Move up the stackの精神で、より価値のある仕事に集中できるようアナリティクスエンジニアの業務をアップデートしよう
- ADLCを回すことでシステムとデータの信頼性が向上し、組織のデータ活用が促進される
3. The convergence of data modeling across apps, analytics, and AI
発表者: Joe Reis
内容: データモデリングから逃げるなというお話。 リードタイムを重視してデータモデリングを疎かにした結果、多くのプロジェクトがデータを原因として失敗している。 限られたスコープで唯一のモデリング手法を取り入れて満足するのではなく、レイヤー毎に最適なモデリングを適用すべきという話を、総合格闘技(Mixed Martial Arts)を捩った形でMixed Model Artsと紹介されていました。 特に印象的だったのは以下3点です。
- ソースシステム側の品質にも目を向けるべき。
- データ分析基盤上だけでの品質担保には限界がある。連携元のソースシステムにおいても強度の高いモデリング方針やデータ品質施策を実行すべき。

- データ分析基盤だけでなくアプリケーションやML/AIを統合したデータモデリングが必要。
- アプリケーションが機械学習を取り入れ、分析データがアプリにフィードバックされるような構造も存在するため、分析利用のスコープに閉じたモデリングを実施した場合、後続での利用に制約が発生する可能性がある。
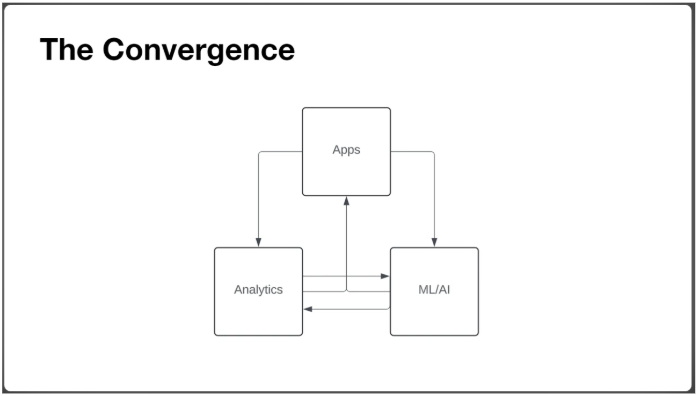
- 安易にOne Big Table (OBT) を作成しない。
- 利用者のSQLスキルにより、1つのテーブルで分析が完結できた方が良いと言う意見は必ずある。
- OBTを作成する際は柔軟性と保守性を考慮のうえ、明確な目的を持って意思決定すべき。
上記のスコープとあわせて、分析用途に限定せずシステム処理からも呼び出し可能なEnd to EndのSemantic Layerが今後必要となる点についても言及されていました。 日々スピーディーな開発が期待される一方で、データモデリングの整備をいかにやり切るか、アナリティクスエンジニアとしての腕の見せ所だと感じました!
まとめ:
- データモデリングは今後のAI活用において重要な役割を担う
- 特定の範囲と1つのモデリング手法に固執せず、適材適所を目指す
最後に
Keynoteをはじめとしたdbt Labsのアップデートは勿論のこと、様々な会社のdbt活用事例や考え方、dbtを中心としたエコシステムの最新情報を直に聞くことができ非常に刺激的な経験となりました! また、今回は有償のトレーニングセッションにも参加し、dbt MeshやSemantic Layer、dbt testのアプローチに関してハンズオン形式で学ぶことができました。 今回ご紹介した以外にも多くの興味深いセッションがあり、内容は YouTube に公開されているので気になる方はぜひご参照ください。

AirレジやクロスユースなどのAirプロダクトのデータマネジメント部分を担当
電電
新卒でリクルート入社。旅が好きで世界一周したりしていました。夢は南極に行くこと。

飲食・美容領域のアナリティクスエンジニア/マネージャー
木内 雄也
2022年に中途入社。KPOPにはまりました。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


