AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
I was almost hit by a car maybe because the long travel made me tired. My name is Takayanagi, working as an engineer.
I am attending the Association for the Advancement of Artificial Intelligence (AAAI) and this is the report for day 3.
AAAI-17/IAAI-17 Joint Invited Talk
This talk was given by Dmitri Dolgov at Waymo the spin-out company from google autonomous driving project. He was at R&D section of autonomous driving at Toyota.
The talk started with the history of self-driving and the importance of object recognition in self-driving and the problem that has to be solved in this field.
I was impressed that he argued several times that his company is not a automobile manufacture but the software company. I think the spirit of bay area makes him do so.
One interesting story I found was that the ML model did not recognize the pedestrian who jumped like a frog. Making a perfect system is still difficult.
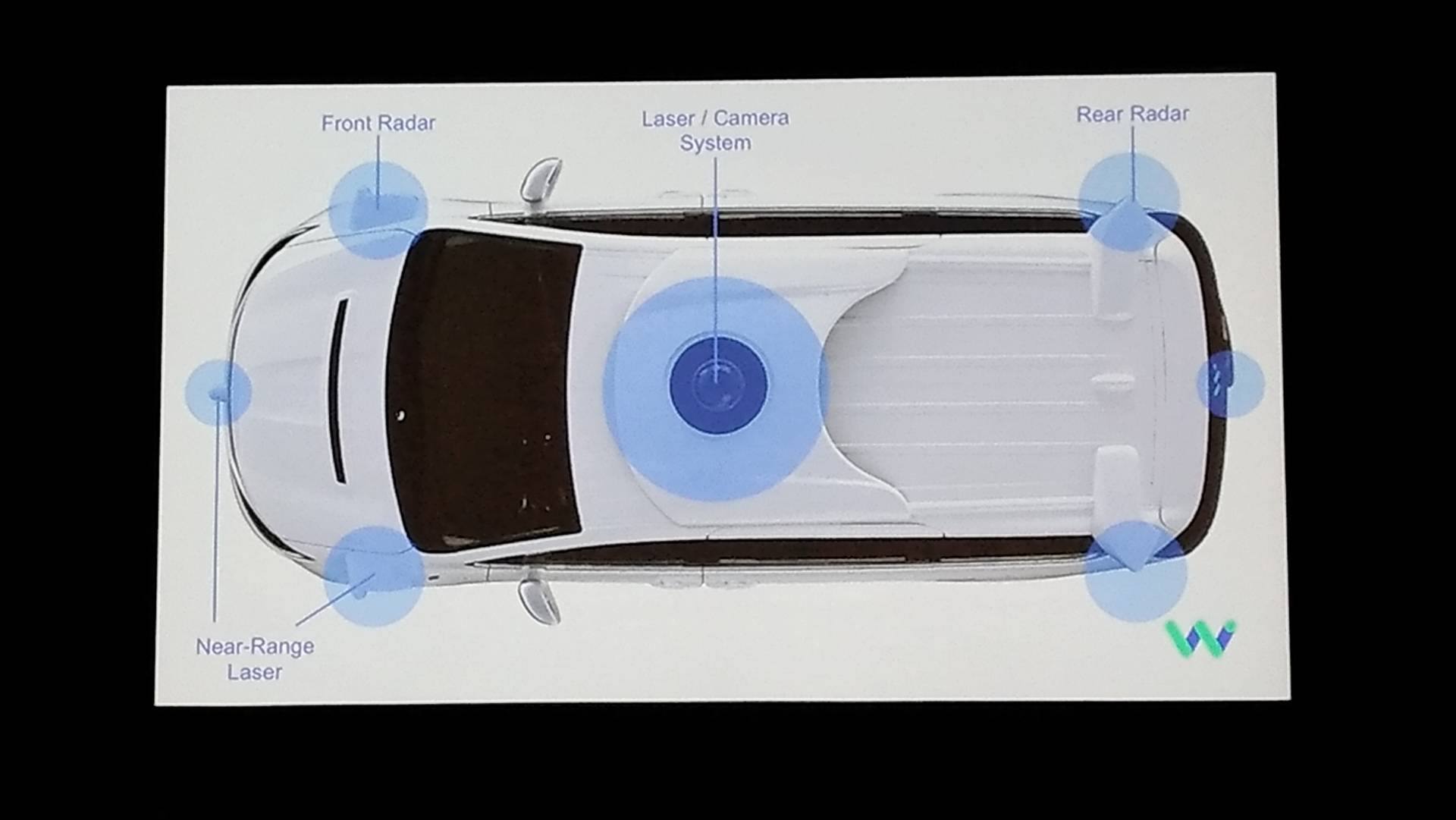
Figure 1: the explanation of radar equipped with car.

Figure 2: the picture illustrating how to recognize pedestrians, cars, and bikes.
HSO4: Optimization (plus one Senior Member presentation)
He introduced some of the interesting topics.
- ASVRG(Asynchronous Variance Reduced for Gradient Descent) which is Stochastic Gradient Descent(SGD) method using asynchronous variance reduction method.
- DML(Distance Metric Learning) with lower dimension which is extension of SGD
- a review of problems in recognition architecture (inference, emotion, meta-congnition)
ML21: Data Mining and Knowledge Discovery
I was intrigued by the title “Streaming Classification with Emerging New Class by Class Matrix Sketching” and saw this session.
The talk seemed to be based on the article.
He proposed a new method: SENC-MaS which enables us to do the classical classification and find a new data to classify and update the model using streaming data. This method introduces Global Sketching: a matrix approximating the input and Local Sketching: a matrix approximating the data belonging to a specific class. After creating these matrix, if the maximum inner-product of the Global Sketching and the data points exceed the threshold, the date is classified as a new class. The classification to the existing classes, can be done by doing the same procedure for the Local Sketching.
Since this is very beautiful framework, I will look further into it.
IAAI-17: Sense-Making: Using Automated Systems to Pull Out Patterns and Structure from Data
“Automated Data Cleansing through Meta-Learning”, it sounds like a dream for data scientist. The talk is based on this article
The method ambitiously aims to automate all pre-processing procedures (such as estimation of missing data, standardization, feature selection, imbalance adjustment). Many participants came to see this talk. The key idea is very simple: representing data as a vector and apply the same pre-processing as the other data whose representation is closer to this.
I recommend looking at the figure 1 in the original paper. In the paper, he compares several types of distance (Lp norm) and states the summary that he needs better mapping of data to the manifold. But it is still interesting challenge.
ML22: Dimensionality Reduction / Feature Selection
In the talk, “Robust Partially-Compressed Least-Squares” was proposed to reduce the computational cost and make the estimation robust for least squares method. The talk was maybe based on this article.
- Reduce the computation cost by introducing the weight as calculated in SVD.
- Instead of Lasso or Ridge, he used robust estimation method explained in this book.
- A proposal of rotation invariant method based on PCA for image processing.
- Introduction of Fβ (extension of F-value) instead of accuracy for feature selection with class imbalance.
- A proposal for estimation of medical spending using Tensor Decomposition named “Task Guided Tensor Decomposition(TaGiTeD)”.
I was interested in ”Robust Partially-Compressed Least-Squares”.
AAAI-17 Invited Talk
This talk was spoken by Kristen Grauman at Texas University.
He tries to solve the problem in learning the model from the realistic video without any labels. His presentation explains from the origin of the research to the mathematical model. The model assumes the equivalence of features, and this beautiful mathematical structure impressed me. In essence, the model learn the environment from the moving camera.


Figure: The difference between Invariant and Equivarant.

Figure: Invariant and Equivarant in relevance of video frames.

Figure: identify the position from the panorama camera.
The code is available here
I reported from AAAI on day 3.
ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)