はじめに
リクルートで横断データ基盤の開発運用をしている澄川です。今回は beetle という内製 ETL 処理フレームワークへのデータ品質テスト機能導入について紹介いたします。
本記事は、データ推進室 Advent Calendar 2024 10日目の記事です
beetle とは?
beetle は当社の美容・飲食・SaaS 領域などのデータ基盤を支える ETL 処理のフレームワークです。
- S3 や GCSからのデータ取得
- SQL 実行によるデータ変換およびマートテーブルの作成
- 作成したデータの S3 や GCS への格納
などの処理を、簡単な YAML 形式の設定ファイルで記述できるのが特徴です。
処理の実行単位を ジョブ と定義しているのですが、現在 800 ジョブ以上が登録されておりそれぞれ定期的に実行されています。
ジョブの中には依存関係を持つものが存在します。「あるジョブでテーブルを作成し、次のジョブでそのテーブルを参照する」といったようなジョブ間の起動タイミングの制御もできるようになっています。
課題: beetle にデータ品質チェック機能がない
beetle の抱えていた問題点
beetle の抱えていた問題点として、beetle には基本的なETLの機能しか備わっておらず作成されたテーブルの品質を担保する仕組みがないという点がありました。
そのため実運用上では SQL の不備やそもそもの入力データの不備の影響で、生成されたデータが不適切になってしまっており、利用者からジョブの修正や再実行の依頼が来るケースがたびたびありました。
出力されたマートテーブルに対して利用者側でデータの品質をチェックすることは可能ですが、そこで問題が発覚したときにはそのテーブル作成に必要なジョブを全て再実行する必要があります。また、品質が低下しているテーブルを入力として扱うジョブが複数あるケースも存在し、品質低下が連鎖的に大量のテーブルに伝播してしまうこともあります。
運用者の視点でも、ジョブの再実行はスケジュール化された定期実行とは別の枠組みでの実行になるため、影響範囲の洗い出しからジョブの実行までを手動で行う必要があり、手間がかかってしまうというのは大きな課題です。
そこでジョブの実行中に品質が低下していることを早く検知したり、後続ジョブへの影響を少しでも抑えたりする仕組みの開発を行うことになりました。
そもそもデータ品質とは?
データ品質を簡単に説明すると、データの正しさや漏れのなさを評価する指標です。
国際的には ISO/IEC 25012 で規格化されており、この中で評価項目として15項目が定義されています。
例えば
- 正確性: データが正しいか
- 完全性: データに漏れがないか
- 一貫性: データ内に矛盾がないか
などの観点が挙げられています。
作成されたテーブルの品質が不十分だとそのデータを使った分析の質を下げてしまうリスクがあるため、このデータ品質は重要な指標となっています。
解決策としての dbt test 機能導入
dbt とは?
dbt はデータ変換に特化したツールで、YAML 形式の設定ファイルや SQL ファイルを書いてコマンドを実行することで自動的に正しい順序で処理をおこなうことができます。
ライブラリの豊富さ・リネージ機能・DAG の自動生成 などの観点から注目度が非常に上がっており、近年データマネジメント界隈でも存在感が大きくなっています。ちなみにリクルート社内でも一部チームではすでに dbt を利用しています。
この後も本アドベントカレンダーに dbt に関する記事が公開される予定となっておりますので、気になる方はぜひご覧ください。
dbt test 機能
今回導入することにしたのは dbt の数ある機能のうちの1つの test 機能です。
この機能はまさにデータ品質の担保のための機能で、デフォルトで以下の4つのテスト項目が備わっています。
- unique: 特定のカラムの値がユニークであること
- not_null: 特定のカラムの値が not null であること
- accepted_values: 特定のカラムの値が、指定されたいくつかの値のいずれかに合致すること
- relationships: 特定のカラムの値が、別のテーブルの特定のカラムの値として存在すること
これらに関しては利用者は自分で SQL を書くことすら不要で、YAML ファイルにテスト項目名を書くだけでテストが実行できます。
version: 2
sources:
- name: {project_name}.beetle_test
database: {project_name}
schema: beetle_test
tables:
- name: test_dbt_test # テーブル名
columns:
- name: id # カラム名
data_tests:
- unique # テスト項目
また、上記以外のテスト項目も以下のように SQL を記述することで実行できます。
{% test less_than_ten(model, column_name) %}
select
{{ column_name }}
from {{ model }}
where {{ column_name }} >= 10
{% endtest %}
beetle の設定 YAML ファイルに dbt テストを行うことを表す項目を追加し、指定されたディレクトリに dbt の YAML ファイルと(必要な場合に限り) SQL ファイルを配置するだけで dbt test 機能を利用できます。
テスト実行時の挙動
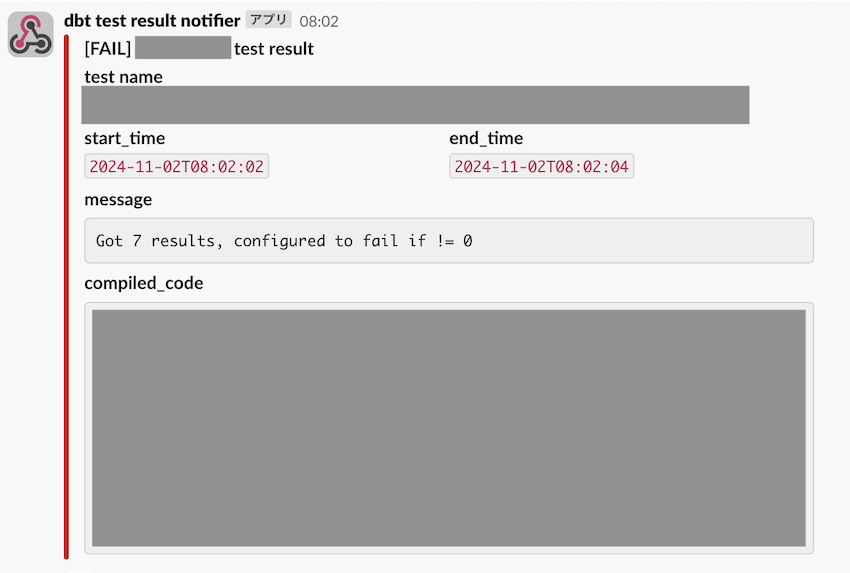
スケジュールされたジョブが起動し dbt test が実行されると、事前に登録しておいた Slack チャンネルにテスト結果が投稿されます。
特にエラー時には実行されたクエリや条件に引っかかった件数などが通知されるため、エラー内容の把握の助けになります。
また、もし後続ジョブがあれば、データ品質テストの基準を満たさなかった場面での挙動は2つのパターンから選べるようにしています。
- 後続ジョブは継続する
- 後続ジョブも停止する
後者を選べば、データ品質の低下したテーブルに依存したマートテーブルの作成が阻止できるため、影響を素早く堰き止めることができます。
さらに、エラー基準とは別に WARNING の基準も指定できるので、品質低下の予兆を検知し品質低下の影響が大きくなる前に対応に着手するということも可能になっています。
まとめ
ETL フレームワーク beetle へのデータ品質テスト機能導入について紹介いたしました。
この導入によって
- データ品質の向上
- 不適切なジョブ実行の防止によるコストの削減
- ジョブ再実行減少による運用コストの削減
などが期待できます。
なお、本来の dbt の機能はもっと幅広いものであり、今回使用した test 機能はあくまでもその一部に過ぎません。dbt の今後の展開を追いつつ、社内のETL処理フレームワークの発展を考えていく予定です。

データエンジニア
澄川 憲太郎
2023年リクルート入社後、横断データ基盤の開発と運用をしています。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら