はじめに
こんにちは。データエンジニアとして社内横断で使われるデータ基盤 Crois の開発を担当している青木です。
内製のジョブ実行基盤である Crois では、多数のコンテナジョブをスケーラブルに実行するために AWS Batch を利用しています (Crois に関しては こちらの記事 もあわせてご覧ください)。
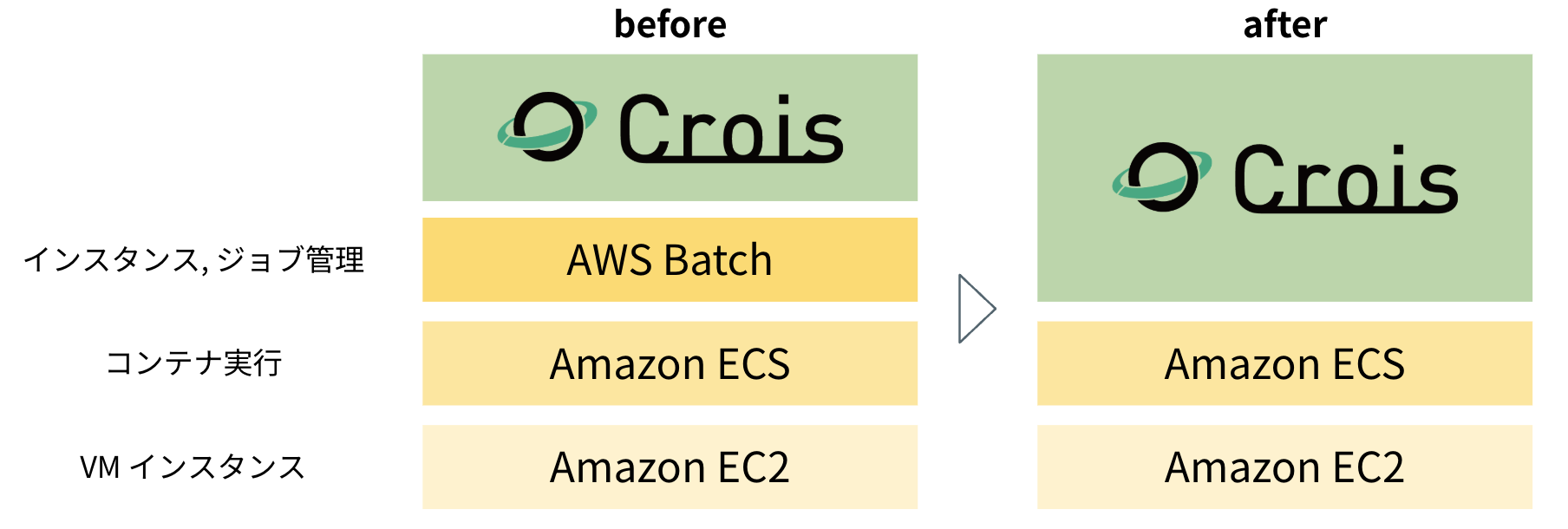
AWS Batch はスケーラブルなコンテナ実行を実現する強力なマネージドサービスですが、Crois のユースケースの多様化に伴い、より高い柔軟性が求められるようになりました。 そこで、AWS Batch の管理レイヤーを介さず、ECS on EC2 を直接制御するアーキテクチャへ移行しました。 その過程で直面した課題と、解決策として開発したインスタンス管理機構について解説します。
この記事が、次のような方々のお役に立てれば幸いです。
- コンテナジョブ実行基盤の設計や運用に携わっている方
- AWS のマネージドサービスを使いこなしつつ、特定の要件に合わせて拡張する方法を模索している方
- サーバーレスやイベント駆動アーキテクチャによるスケーラブルなシステム構築に興味がある方
コンテナジョブ実行基盤見直しの背景
内製データ基盤「Crois」とは
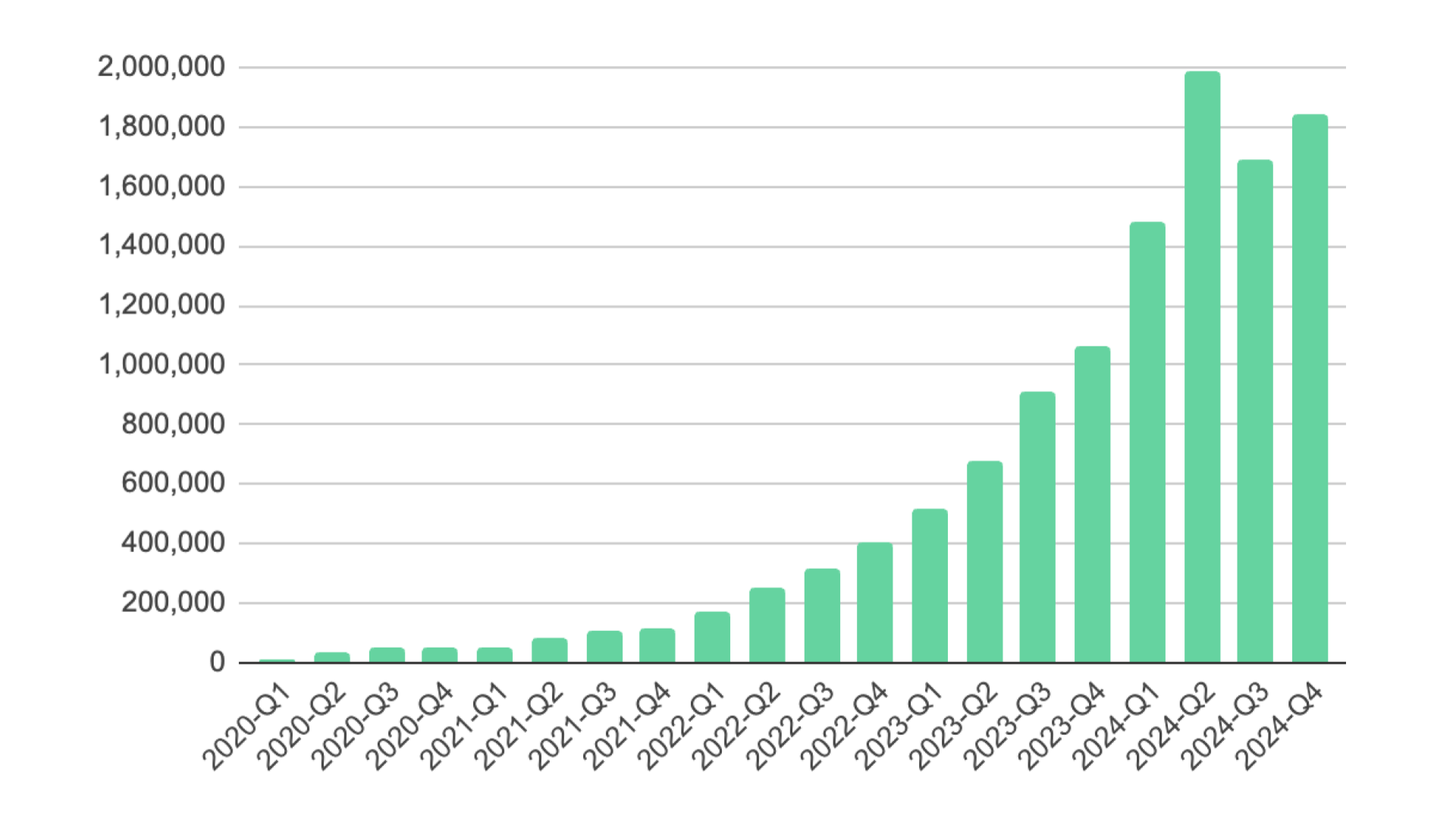
Crois は、リクルートの多様なデータ利活用を支える、バッチ処理に特化したワークフローエンジン・ジョブスケジューラです。機械学習の学習・推論パイプラインや ETL をはじめ、様々な事業領域の施策で利用されており、現在では 1 日あたり数万のコンテナタスクを実行する大規模なプラットフォームとなっています。
AWS Batch と Crois のユースケースのギャップ
Crois では、これまで大規模なコンテナ実行に AWS Batch を利用してきました。 AWS Batch は、内部で動作する ECS on EC2 1 の複雑さを隠蔽し、スケーラブルなバッチ処理を実現する強力なマネージドサービスです。
しかし、Crois の利用が拡大し、ユーザーの要求が多様化するにつれ、AWS Batch が提供する抽象化・管理の仕組みと、我々がプラットフォームとして提供したい機能との間にギャップが見えてきました。
【ユーザーのスペック選択の柔軟性】
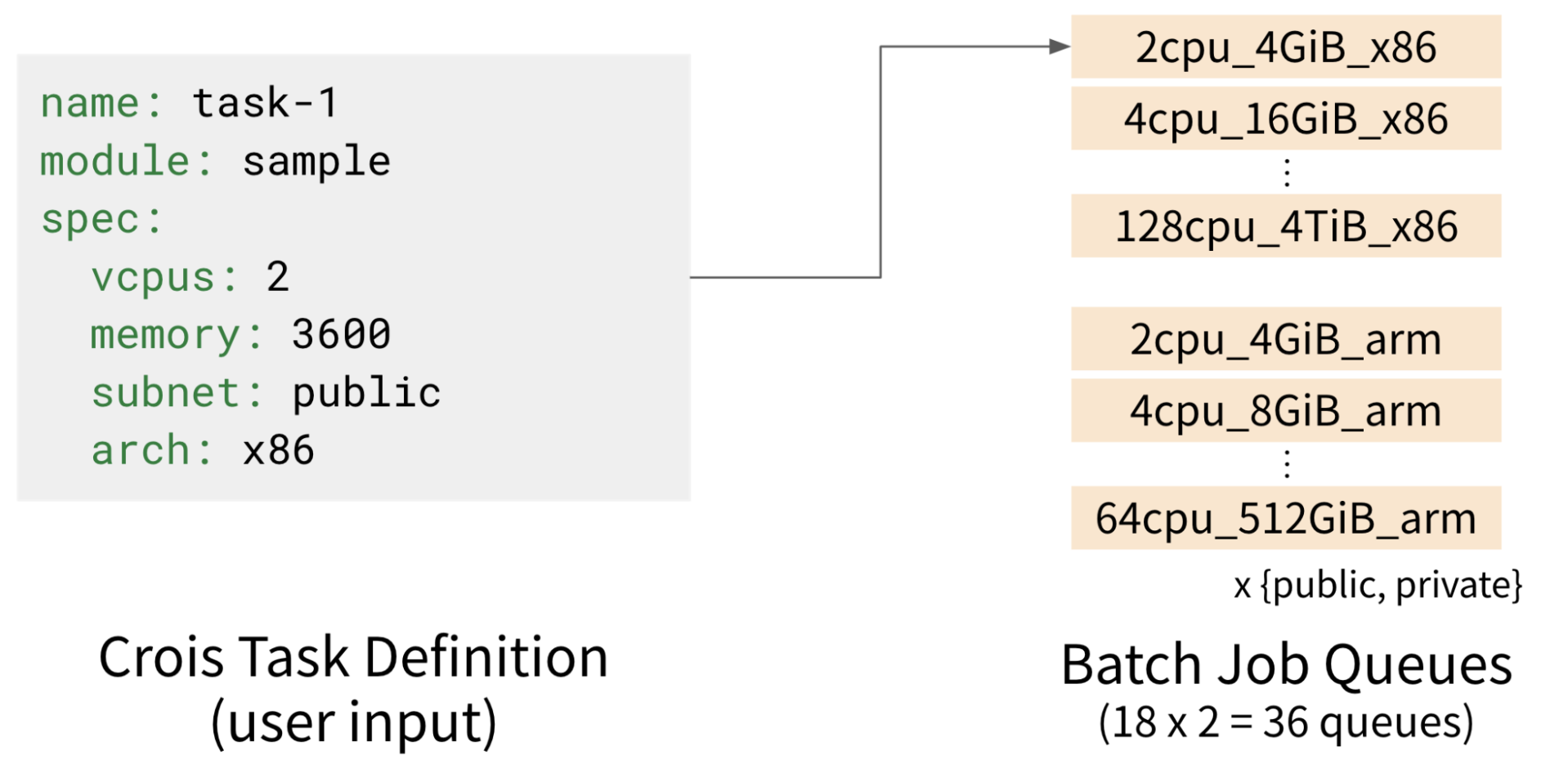
AWS Batch では、コンピューティング環境とジョブキューを事前に定義しておく必要があります。
Crois では、様々なスペックの実行環境をコスト最適に提供するため、スペックごとに細分化されたジョブキューを使用しています2。 しかし、ジョブキューの数にはアカウント・リージョンあたり 50 個というハードクォータが存在するため、ユーザーに提供できるインスタンススペックの選択肢はどうしても限定的になります。 これにより、ユーザー自身がコストやパフォーマンスを細かく最適化することが難しい状況でした。
【プラットフォーム側の運用負荷】
ジョブキュー・コンピューティング環境の更新時にはダウンタイムを発生させないために Blue-Green デプロイを行う必要があります。 Crois では 36 / 50 個のキューを使用していたため、Blue-Green デプロイを 3 回に分けて行う必要がありました。 この運用は非常に手間がかかり、新しい機能を迅速に提供することが難しくなっていました。
技術選定
こうした課題を解決するため、いくつかの選択肢を検討しました。
- 案A: AWS Batch マルチアカウント構成
- AWS アカウントを複数に分割することで、ジョブキューの制約を緩和する案。
- 不採用: 根本的な柔軟性の課題は残り、将来的なアカウント数の増加に伴う運用負荷の増大が懸念されました。
- 案B: EKS with Karpenter
- Kubernetes をベースとし、Karpenter による効率的なスケーリングが期待できる構成。
- 不採用: 非常に柔軟な実行環境を提供可能ですが、学習コストの高さや、既存の ECS ベースの実行環境との差分が大きいことによる移行コストの高さが懸念されました。
- 案C: ECS on EC2 の直接制御
- Batch の管理レイヤーを介さず、ECS と EC2 を直接制御する方式。
- 高い柔軟性を確保しつつ、既存の実行環境との差分も小さく済み、移行コストが小さくなると考えました。
- 懸念点: 次項で説明しますが、マネージドオートスケーリングはスケーリング性能が要件を満たさないため、インスタンスのプロビジョニングとタスク割り当てを独自に実装する必要がある点に懸念がありました。
柔軟性を確保しつつ移行コストも抑えられるため、案C: ECS on EC2 の直接制御 を選択し、スケーリング性能の課題解決を目指すことにしました。
独自の EC2 インスタンス管理機構
独自実装が必要になった理由: マネージドスケーリングの性能限界
案 C の実現可能性を検証するため、まずは ECS で提供されているマネージドスケーリングの性能評価を行いました。
目標性能は、インスタンスが立ち上がっていない状態から 1000 コンテナタスクを 5 分以内で起動し、タスク終了後直ちにインスタンスを終了できることでした。
インスタンスが全く立ち上がっていない状態から、まず 40 個のコンテナタスクを実行する形で試験を行った結果が以下です。
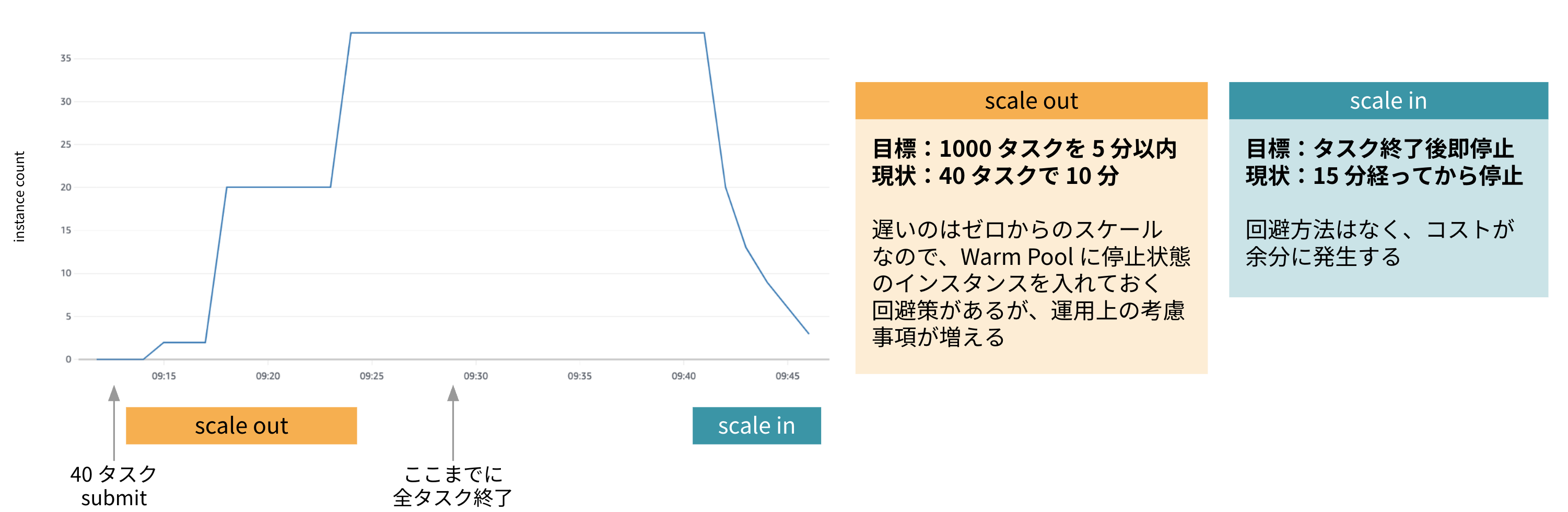
ECS のマネージドスケーリングでは 40 タスクが全て開始するまでに 10 分、またタスク終了からスケールイン完了までに 15 分余りを要すことが分かりました。 特にスケールインの開始が遅いことについては回避方法がなく、コストが余分にかかることになります。
この結果を受け、性能要件を達成するためには、インスタンスのライフサイクル (起動・終了) を自前で精密に制御する機構を開発する必要があると判断しました。
実装の詳細: イベント駆動アーキテクチャによる高速スケーリング
設計指針
設計指針として、1 インスタンス = 1 コンテナタスク という制約を設け、各コンテナタスクに対して 1 対 1 でインスタンスを管理するという設計を採用しました。 実行の流れは以下のようになります。

1 インスタンスに 1 コンテナタスクを割り当てるか、複数タスクを集約できるようにするか、という選択肢がありますが、下図のように Crois の需要特性はスパイク性が強いため、インスタンスの空きリソースにタスクをうまく割り当てられる機会は少ないです。 また、もし小さいタスクがスケジュールできても、そのタスクだけのために大きいインスタンスが残り続けて余剰リソースが無駄になる可能性が高いです。
システムとしてシンプルになり、ユーザーごとに細かくインスタンスをカスタマイズしやすくなるこの方式の方が良いと判断しました。

ナイーブな実装
ナイーブな実装としてまず考えられるのは、以下のようなものです。 Crois のワークフローは元々 Step Functions で実装されているため、AWS Batch Job を起動していた部分の前後でインスタンスの起動・終了を取り扱うようにするというものです。
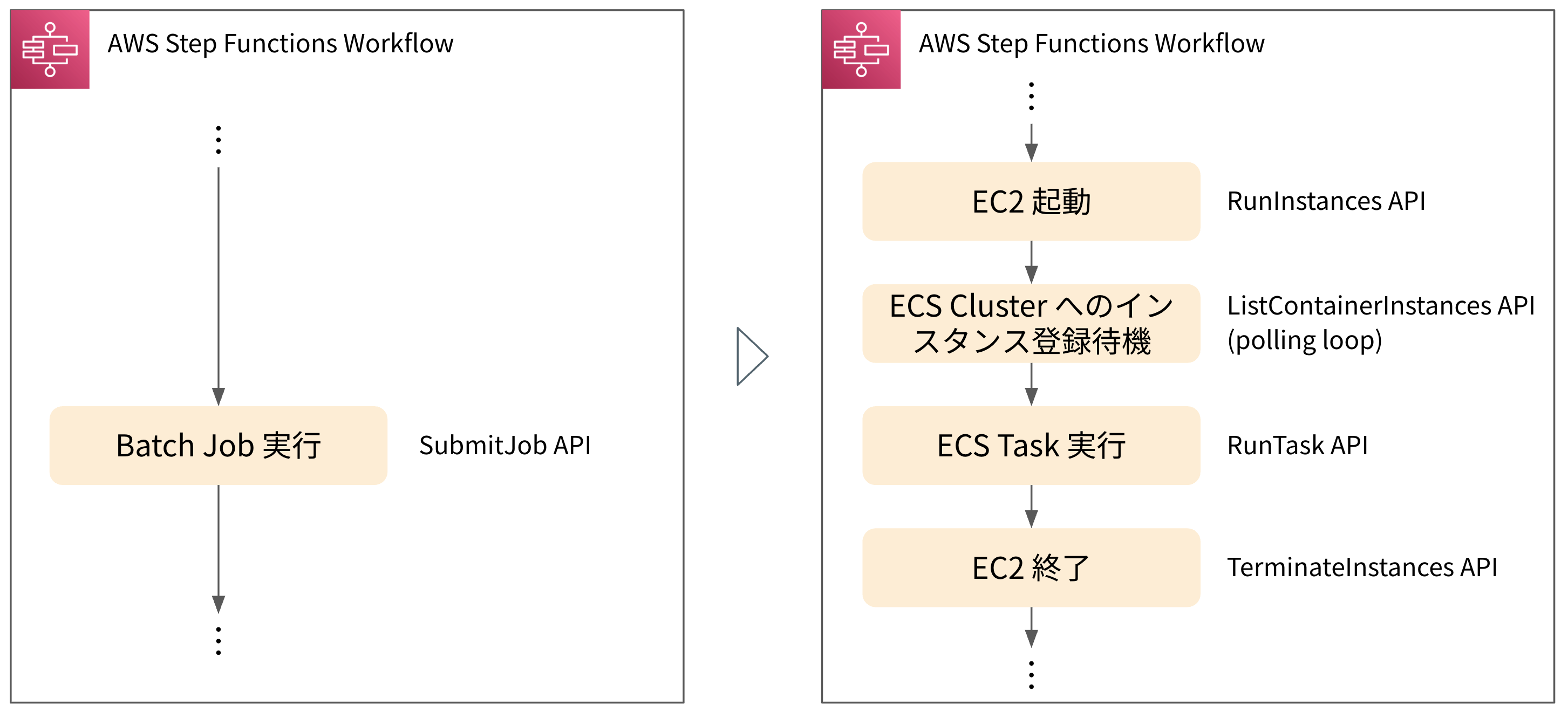
しかしながら、この方法にはいくつか問題があります。
- EC2 起動
- RunInstances API をタスクごとに呼び出すと、API のスロットリングを受けやすく、大量実行時にボトルネックになる
- ECS Cluster へのインスタンス登録待機
- Step Functions からポーリングで待機することにより、ステートの遷移回数が大幅に増え、コストが高くなる
- EC2 終了
- 途中で Step Functions が失敗した場合など、異常時に EC2 を確実に終了できず、不要なコストが発生する
そこで、以下のような起動・終了処理を実装しました。
【起動処理】API スロットリングを回避し、高速化する工夫

- EC2 起動
- Crois のワークフロー (Step Functions) は、EC2 を直接起動する代わりに、SQS に起動リクエストメッセージを送信します。
- Lambda が SQS キューからメッセージをバッチで取得します。
- Lambdaは、複数の起動リクエストを一つにまとめ、EC2 CreateFleet API をコールして、一度に多数のインスタンスを起動します。
- ECS Cluster へのインスタンス登録待機
- EC2 が起動しコンテナインスタンスとして ECS に登録されると、
Amazon ECS container instance state change eventが発行されます。 - Lambda が ECS のイベントを受け取り、Step Functions にコールバックを送信します。(Step Functions 側は WaitForTaskToken 方式で待機しています)
- EC2 が起動しコンテナインスタンスとして ECS に登録されると、
このアーキテクチャにより、スロットリングやコストの問題を回避しながら、高速でスケーラブルなインスタンス起動を実現しました。 サーバーレスのマネージドサービスを活用することで運用負荷も低く保っていることもメリットです。
Tips: CreateFleet API の活用
CreateFleet API は、複数のインスタンスタイプや購入オプション (On-Demand/Spot) を組み合わせ、優先順位を付けて柔軟にインスタンス群を起動できる API です。例えば、「c7i.large を優先し、在庫がなければ c6i.large を起動する」といったリクエストが可能です。Karpenter も内部的にこの API を利用しているようです3。
【終了処理】確実かつ速やかにインスタンスを終了するための工夫
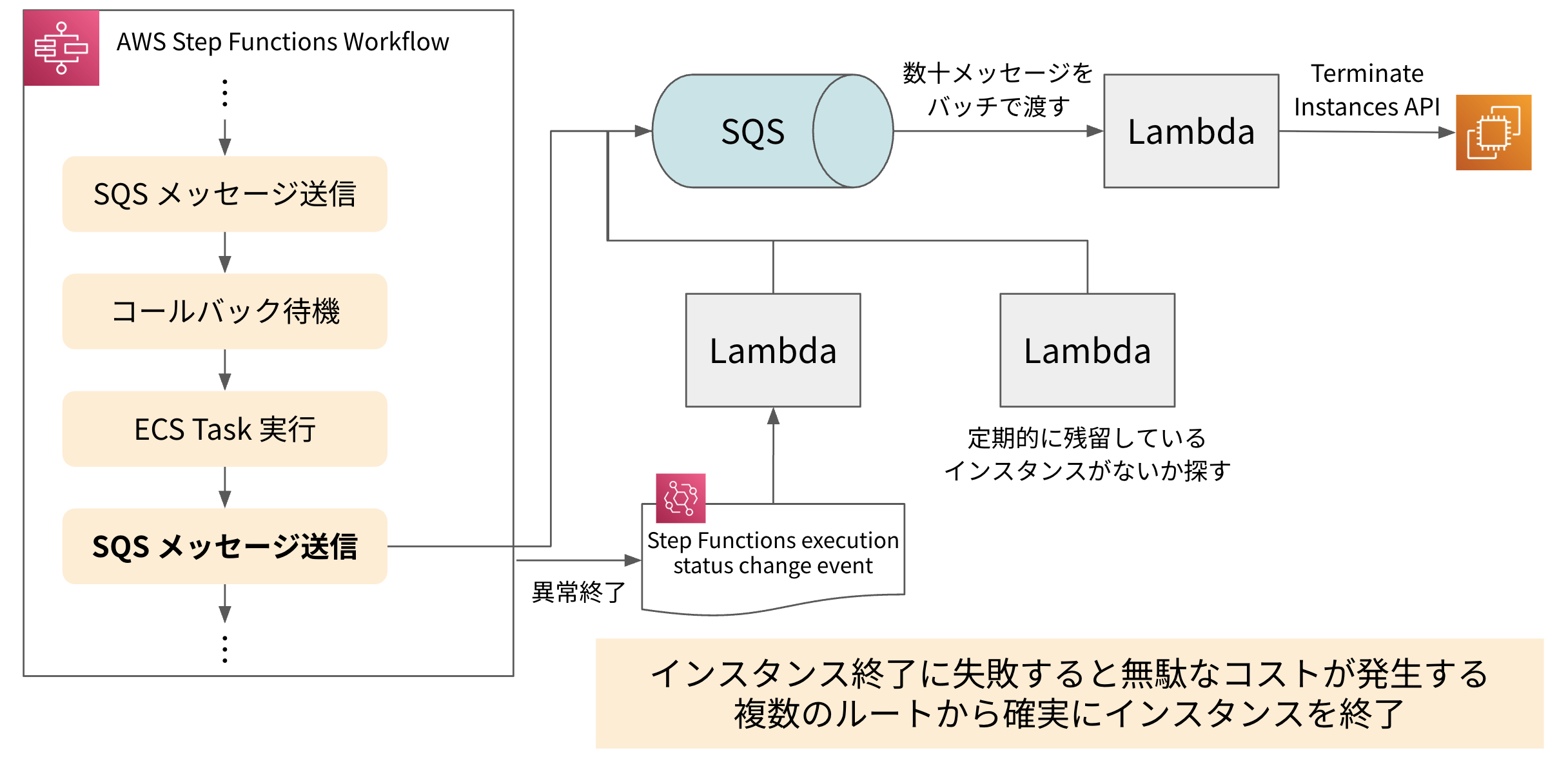
タスクが完了したインスタンスを終了させないと無駄なコストが発生してしまうため、確実かつなるべく速やかに終了させる必要があります。
インスタンス終了リクエストを受け付ける SQS を用意し、そこにインスタンス ID を含むメッセージを投入することで Lambda がインスタンスを終了するようにしています。 正常系では Step Functions の中から直接 SQS にメッセージを投入していますが、 Step Functions の失敗時にはその失敗イベントをトリガーに SQS にメッセージが投入されるようになっています。 また、予期せぬエラーに備え、どのタスクにも紐付いていない残留インスタンスを定期的に探索してクリーンアップする処理も実装し、確実なインスタンス終了を実現しています。
成果
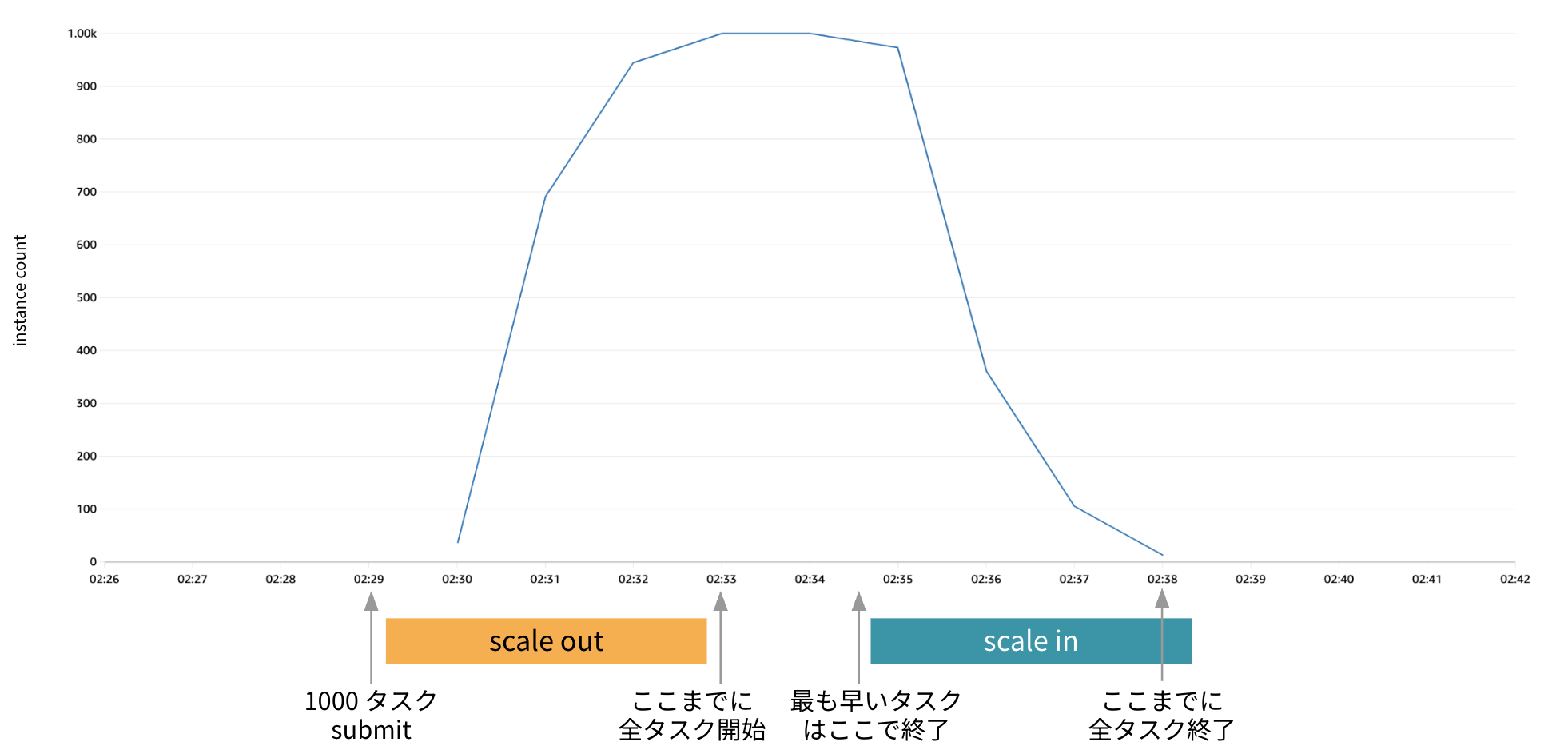
ベンチマーク結果
開発したジョブスケジューリング機構で、 1000 個のコンテナタスク (= 1000 インスタンス) を同時に起動するベンチマークテストを実施しました 4。 その結果、すべてのタスクが 5 分以内に開始され、タスク終了後にはインスタンスが直ちに停止されることを確認し、目標としていた性能要件を達成することができました。
得られた効果
この取り組みにより、ユーザーとプラットフォーム開発者の双方に大きなメリットがもたらされました。
- ユーザーは、Batch のジョブキューに縛られずに幅広いインスタンス・ストレージの選択肢から自由に実行環境を選択できるようになり、コストやパフォーマンスが改善した。
- AWS のコストは約 15 % 削減された。
- 開発チームの運用負荷が削減され、より価値の高い機能開発に注力できるようになった。
- コストのアロケーションが明確になり、ユーザーに正確かつ予測可能なコストをチャージバックできるようになった。

おわりに
本記事では、Crois の成長に伴うユーザーのニーズ多様化に対応するため、AWS Batch を介さずに ECS on EC2 を直接制御するアーキテクチャを構築した事例を紹介しました。 性能要件を満たすために、イベント駆動アーキテクチャ + サーバーレスのマネージドサービスでインスタンス管理を実装し、高速なスケーリングを実現した技術的な詳細について解説しました。
最後までお読みいただき、ありがとうございました。
-
AWS Batch は実行バックエンドとして ECS on EC2 のほか、EKS や Fargate を選択できます。Crois では ECS on EC2 を選択しています。 ↩︎
-
AWS Batch をバッチ処理に使用する場合、同じインスタンスファミリーでサイズの違うインスタンスを 1 つのジョブキューにまとめる構成の方がより一般的かと思いますが、任意のタイミングでさまざまなサイズのコンテナジョブが実行される Crois では、大きいインスタンスに小さいコンテナジョブが載るなど、無駄が発生しやすいためこのような構成にしています。 ↩︎
-
Groupless Autoscaling with Karpenter - Ellis Tarn & Prateek Gogia, Amazon ↩︎
-
コンテナタスクの内容は 5 分間 sleep するのみの処理。インスタンスは全て c6g.medium。 ↩︎

データエンジニア。社内横断で使われるデータ基盤 Crois の開発を担当
青木 悠
休日はバイクに乗ってお出かけ派
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら