
はじめに
データパイプラインにおいて、「ETL」という言葉を耳にする機会は多いと思います。 Extract(データの抽出)、Transform(データの変換)、Load(データのロード)の3つを指し、分析環境やBIツールに事業データを連携する際には、この一連の流れが欠かせません。
この3つに分けられているのには理由があって、それぞれが担う責務が異なるからだとされています。 Extractは、事業DBから直接データを取ってくる役割。 Loadは、アプリやBIツールで使える形に仕上げる役割。 そしてTransformは、データを目的に合わせて変換する、という役割です。
近年はクラウドデータウェアハウスが非常に強力になり、様々なビジネス要件に合わせた処理を Transform 層で実現するようになりました。その結果、目的に応じて多数のテーブルを生成し、多数のクエリが実行され、多数の Job が動くようになりました。
この記事では、肥大化する Transform 層における Job 管理に焦点を当てたいと思います。依存関係をシンプルに管理する Asset Centric という考え方に触れつつ、その弱点を補う運用策を、具体例を添えて紹介します。
本記事は、データ推進室 Advent Calendar 2024 7日目の記事です
TL;DR
この記事では、データパイプラインのTransform層における複雑化する Job 管理の課題と、その解決策について解説します。
主なポイント:
-
Job 管理の課題
- データ変換処理の複雑化により、SQLの肥大化や依存関係管理が困難になる。
- Airflowなどのツールを用いて依存関係を管理するが、さらに複雑化する場合がある。
-
Asset Centric アプローチ
- Job 単位ではなくデータ(テーブル)単位で依存関係を管理する方法。
- Asset Centric な依存関係管理には、 dbt や Dagster といったツールがある。
-
Asset Centric の課題と改善策
- Asset Centric でもデータの多重更新やテーブルと Job の関係把握が難しいなどの運用課題が発生する。
- BigQuery の監査ログや dbt の query comment 機能を活用することで、 Job 実行履歴を可視化して運用負担を軽減した。
結論:
Asset Centric アプローチを導入することで Job 管理を効率化にしたいが、新たな課題への対応が必要になる。監査ログや query comment 機能を活用して可視化を行い、効率的な運用を目指した。
データパイプライン開発における Job 管理の背景
Transform の運用課題
Transform 層で実施する処理には、特定の粒度、たとえば「月ごとの集計」や「特定のコード値に基づく変換」といった処理が代表的です。 この程度であれば、SQLでGROUP BY句やCASE文を書けば簡単に済むと思われるかもしれません。 たとえば、「毎月の問い合わせ件数」を分析する場合、問い合わせデータを引っ張ってきて、問い合わせ月ごとにレコード数をCOUNTするだけです。
ところが、実際に分析し始めると、これが意外に厄介です。
ECサイトで具体例を考えてみましょう。
商品カテゴリ別の需要と在庫数を集計するという一見シンプルなタスクでも、想像以上に手間がかかります。 注文データを商品カテゴリごとに紐付けて集計したり、在庫データからカテゴリ別の在庫数を拾い上げたり、その両者を突き合わせたり――と、細々した処理がいくつも出てきます。
参考:商品カテゴリ別の需要と在庫を分析する場合の具体的な処理
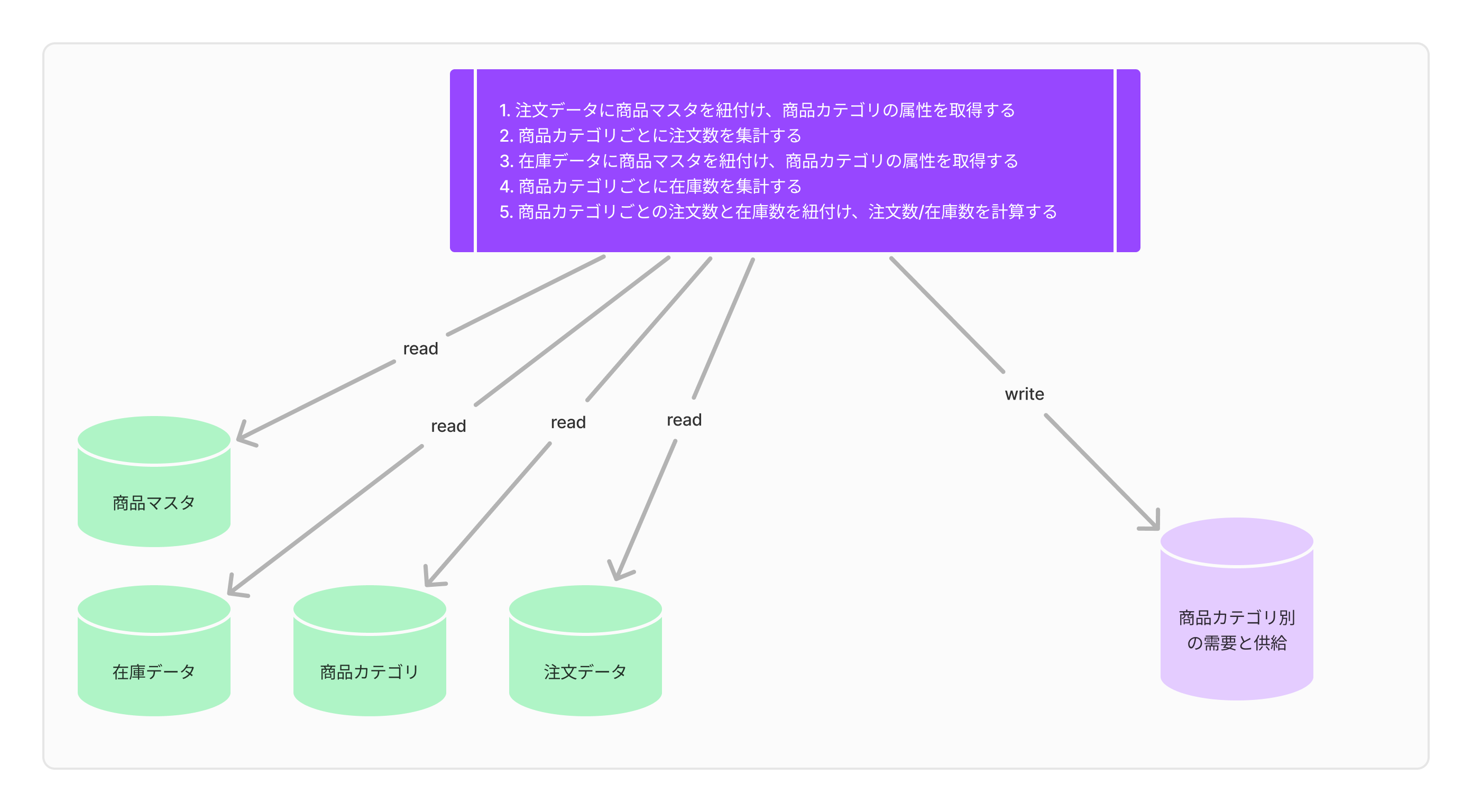
さらに「カテゴリ別の平均価格はどうなっているの?」とか「売れた商品の平均価格を計算してほしい」といった要求が重なると、どんどん処理が複雑化していきます。 気づけばSQLは数百行規模に膨れ上がり、ミスは増え、修正は大変になり、Transform層の運用に泣かされることになるわけです。
そこで、こうした問題を解決するためには、ひとつの大きな処理を小分けにして、別々のテーブルに分割する方法が効果的です。
Job の分割
最初からカテゴリのついた注文データと在庫データがあれば、処理はもっと簡単になります。 そこで、これらの中間テーブルを作る処理を別の Job で作成します。
- 中間データ生成処理
- カテゴリのついた注文データの作成
- カテゴリのついた在庫データの作成
- 需要供給マートの生成処理
- カテゴリごとに注文数と在庫数の集計
- カテゴリごとの注文数 / 在庫数を計算
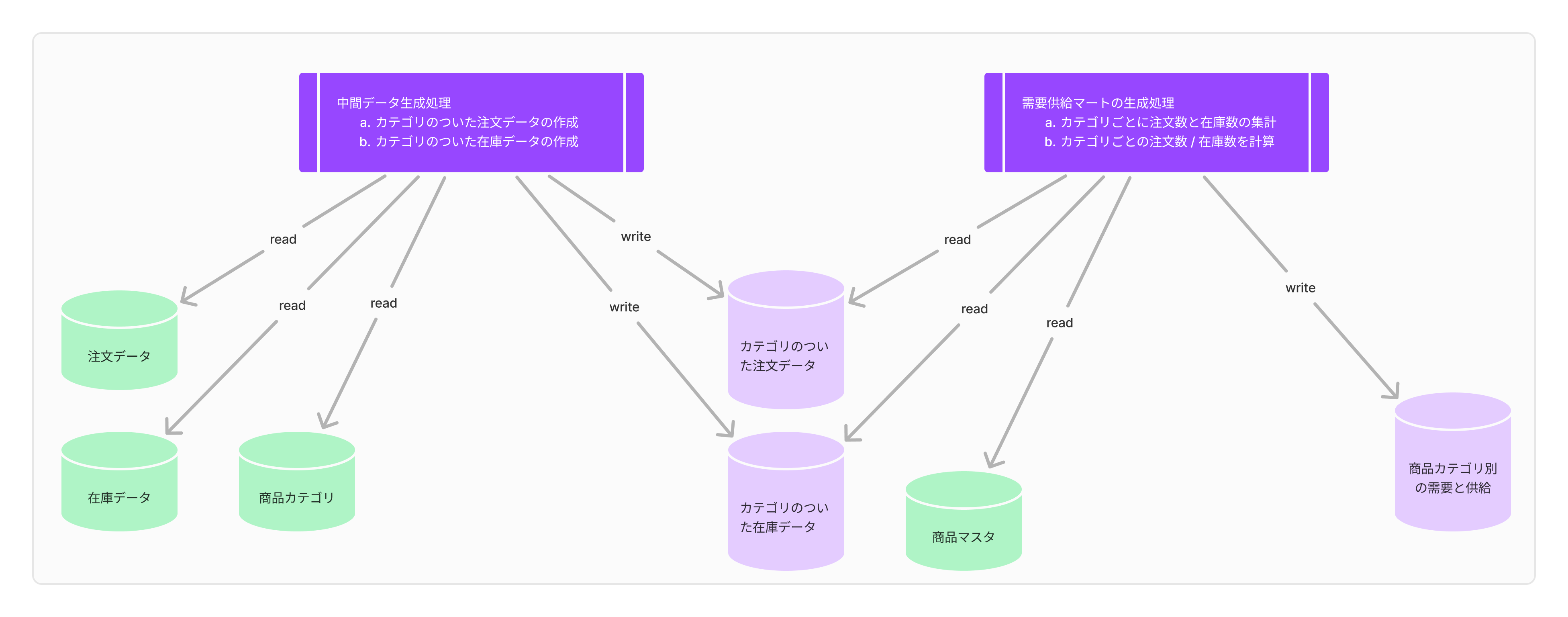
このように2つの Job に分ければ、[需要供給マートの生成処理]は軽くなり、SQLも見通しがよくなります。 さらに、[中間データ生成処理]で作成したマートは、製品ブランドごとの問い合わせユニークユーザー数を出すといった、その他の分析にも活用できて便利です。
しかし、ここにも課題が発生します。 それは Job 間の依存関係です。 [需要供給マートの生成処理] Job は、[中間データ生成処理] Job が終わってからでないと動かせません。 もし[中間データ生成処理]に失敗しているにもかかわらず、[需要供給マートの生成処理]を動かしてしまうと、不適切なデータがBIやアプリに現れ、混乱を招きかねません。
こうした依存関係をきちんと管理するためには、ワークフローエンジンと呼ばれるツールが役立ちます。 たとえば、Airflowというツールでは、DAG(有向非巡回グラフ)という概念を使って、[中間データ生成処理] -> [需要供給マートの生成処理]という実行順序を指定できます。 これにより、間違った順番で Job を実行しないようにできます。もし[中間データ生成処理]が失敗した場合は、[需要供給マートの生成処理]は実行せず、エラーでストップすることも可能です。
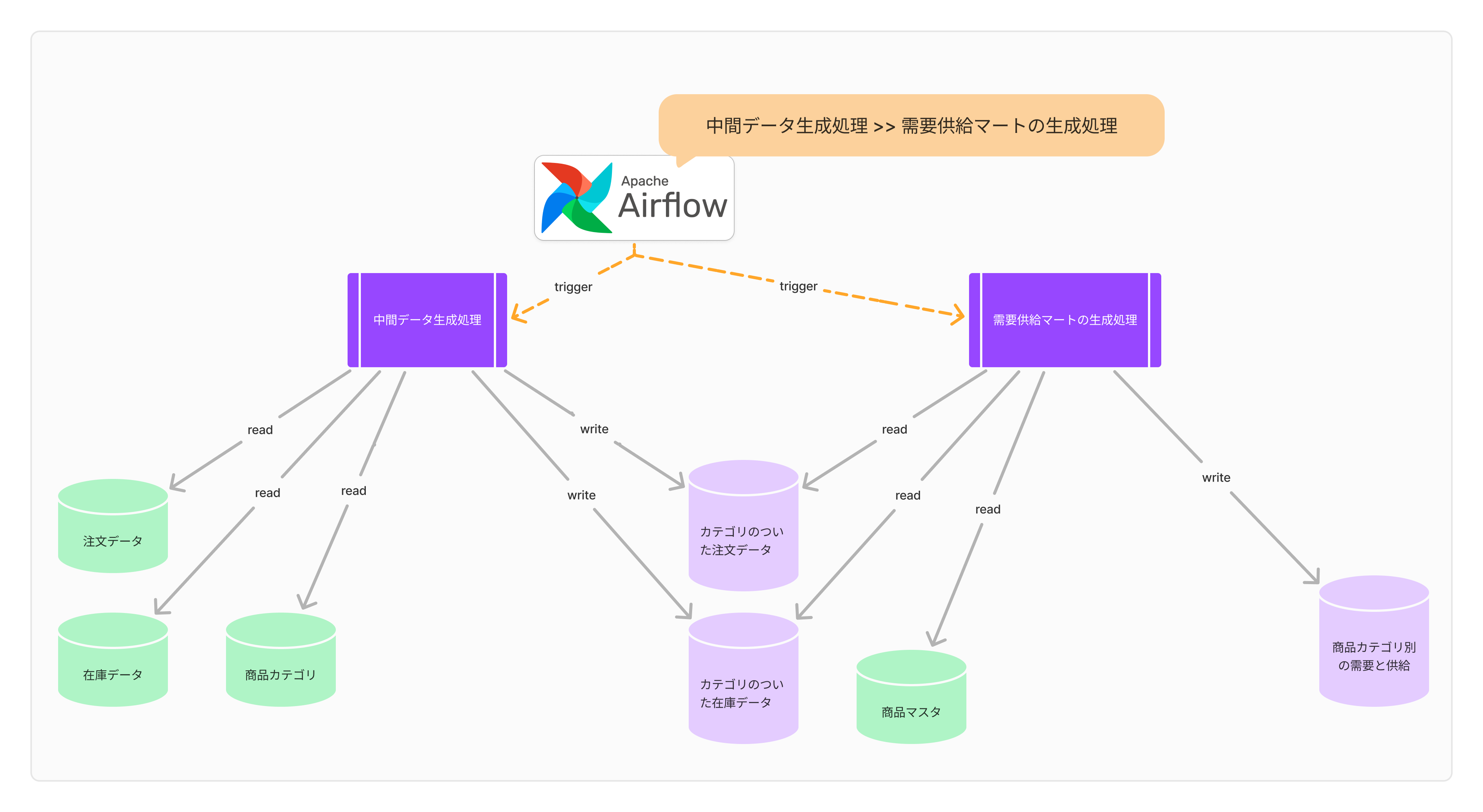
他にも、Argo(Kubernetesベースのツール)など、同様の機能を持つツールがいくつかあります。 こうしたツールを使うことで、Transform層のデータ変換処理を細かく分割し、それぞれの Job 間の依存関係を管理することが可能になります。
ただ、ここでまた別の問題が浮上します。 それは、 Job 間の依存関係が複雑になりすぎる、という状況です。
依存関係管理の課題
たとえば、まずtask_aという Job を実行した後に、task_bとtask_cを同時に実行します。 次に、task_cの後でtask_dを実行し、その上でtask_bとtask_dの両方が成功していれば、最後にtask_eを実行する――という複雑な依存関係を表現しなければならないとします。
Airflowで記載すると、以下のようになります。
task_a >> [task_b, task_c]
task_c >> task_d
[task_b, task_d] >> task_e
「おお、これで解決だ!」と思いますよね。 確かに、この記述の通りに依存関係を定義しておけば、問題なく動きます。 しかし、実際の運用では、「あれ?task_eってtask_fにも依存していたんじゃなかったっけ?」なんてことを、うっかり忘れてしまうことが多いです。
データ変換処理では、カラムを一つ追加するといった簡単な改修であっても、参照するテーブルを増やしたりで、依存関係が増えていきます。 たとえば、商品カテゴリではなく製品ブランド別の需要供給を見たいとなると、ブランドのマスタと紐づける必要が生じます。 この場合、ブランドのマスタデータが生成されているタイミングも依存関係に含めなければなりません。 大規模な改修を行う場合はなおさら、依存関係の調査が難航します。
こうした見落としがあると、せっかく精密に組み立てたはずの Job が動かなくなる、あるいは誤った順番で実行される、といったトラブルが発生します。 管理のためにツールを導入したのに、その管理がさらに厄介になる――というのは、何とも皮肉な話ですね。
Asset Centric な依存関係管理
データ変換処理の依存関係は、突き詰めればSQLのFROM句に書かれたテーブルと、それを参照している処理のことです。 そこで、データそのものに定義された情報だけで依存関係を管理するのもアリじゃないか――という話になるわけです。
このような方法が Asset Centricという考え方です。対して、従来の Job =Task に着目した依存関係管理を Task Centric と呼んだりします。
Asset Centric で管理すると、依存関係を直感的に把握できます。たとえば、Source から Table A, Table B を生成する Task X があり、その次に Table B からTable C を生成する Task Y があるようなケースを考えてみます。
Task Centric でTable C の依存関係を把握するには、Task Y の中身を把握しておく必要があります。これに対し、Asset Centric な方法で依存関係を表すと、Table A, B, C 間の依存関係が直感的に分かります。
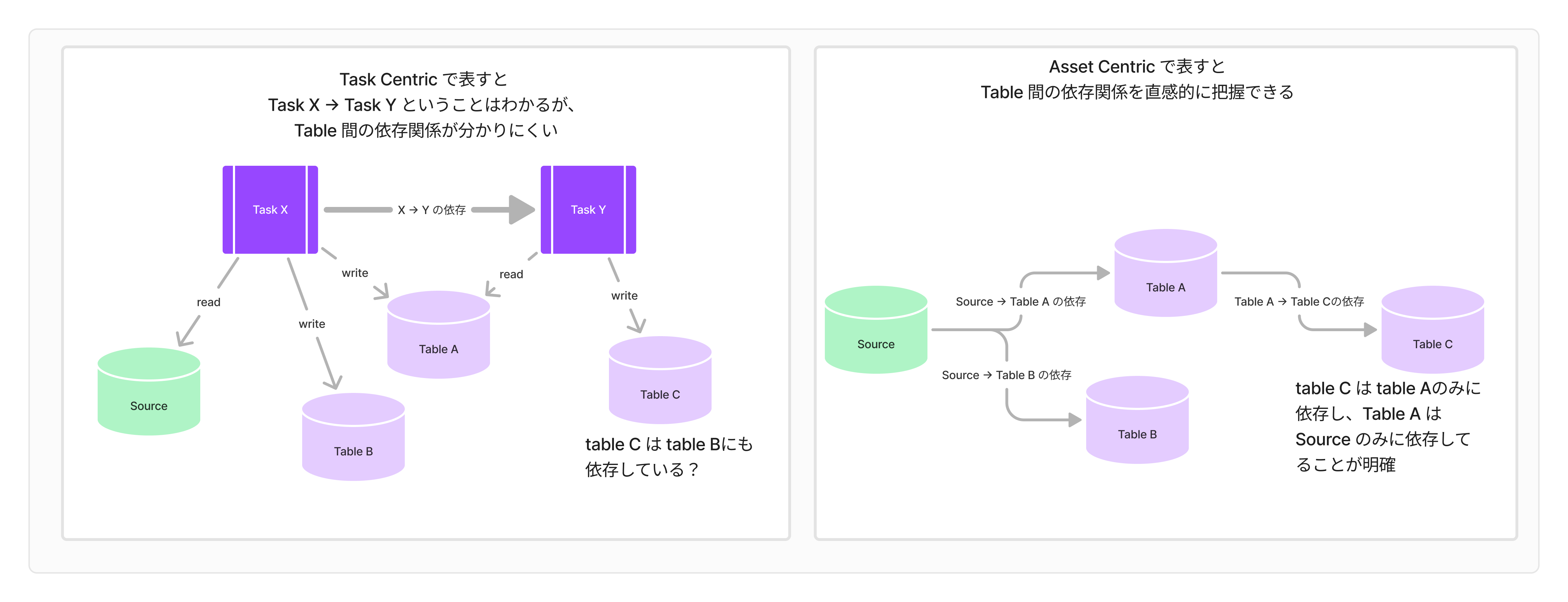
このように、Asset Centric なアプローチで依存関係を捉えると、 Job の中身を把握する必要がないため、シンプルに管理できそうです。
具体的なイメージを持っていただけるよう、Asset Centric な方法で管理できるツールを2つ紹介します。
dbt
dbt というデータ変換ツールは、Jinja形式で書かれたSQLファイル を使って、SQLの中で参照されているテーブルを再帰的にたどることで、データリネージ(データの流れの系譜)を構築してくれます。
テーブルを生成する際は、データリネージに基づいて、処理を上流から下流へと順番に実行してくれます。 たとえば、raw_data → processed_data という順序のデータリネージがある際、「processed_data を作りたい」と指定すれば、raw_data も自動的に生成してくれます。実際のコード例は以下のようになります。
-- models/processed_data.sql は models/raw_data.sql に依存しており、自動的にその依存関係が追跡されます。
-- models/raw_data.sql
select *
from my_database.my_schema.raw_table
;
-- models/processed_data.sql
with raw as (
select * from {{ ref('raw_data') }}
)
select
id,
value * 2 as processed_value
from raw
where value > 0
;
上記のように定義すれば、 dbt は dbt run --select +processed_data というコマンドで raw_data と processed_data を生成します。
Dagster
Dagsterというワークフローエンジンでは、asset という形式でデータとそのデータが依存する情報を表現できます。 この仕組みのおかげで、データの依存関係を自動的に追跡してくれます。 dbt とは異なりSQLに閉じないので、 APIリクエスト結果などでも依存関係を管理することができます。
https://docs.Dagster.io/getting-started/what-why-Dagster
前述と同様の例を Dagster で実現する場合のコード例は以下になります。
# processed_dataはraw_dataに依存しており、自動的にその依存関係が追跡されます。
from dagster import asset
# 最初のデータ資産を定義
@asset
def raw_data():
# データを生成するプロセス(例: データベースから取得)
return [1, 2, 3, 4, 5]
# 依存する資産を定義
@asset
def processed_data(raw_data):
# raw_data を使ってデータを加工する
return [x * 2 for x in raw_data]
上記のように定義すれば、 Dagstar は dagster job execute --selector *processed_data というコマンドで raw_data と processed_data の両方を生成することができます。
Asset Centric な依存管理の課題
データの多重更新
Asset Centric も銀の弾丸ではなく、データの多重更新がおきてしまうという課題を持っています。 たとえば、table_Xというテーブルがあり、それに依存するtable_Yとtable_Zがあるとします。 ここで、table_Yは毎朝10時に最新のデータで更新し、table_Zはお昼の14時に更新しなければならない、という状況を考えてみてください。
これを dbt の Asset Centric な方法で処理するとどうなるでしょう。まず、朝10時に dbt run -s +table_Y を実行し、table_X を更新します。 そして、14時には dbt run -s +table_Z を実行することで、またしてもtable_Xが更新されるわけです。
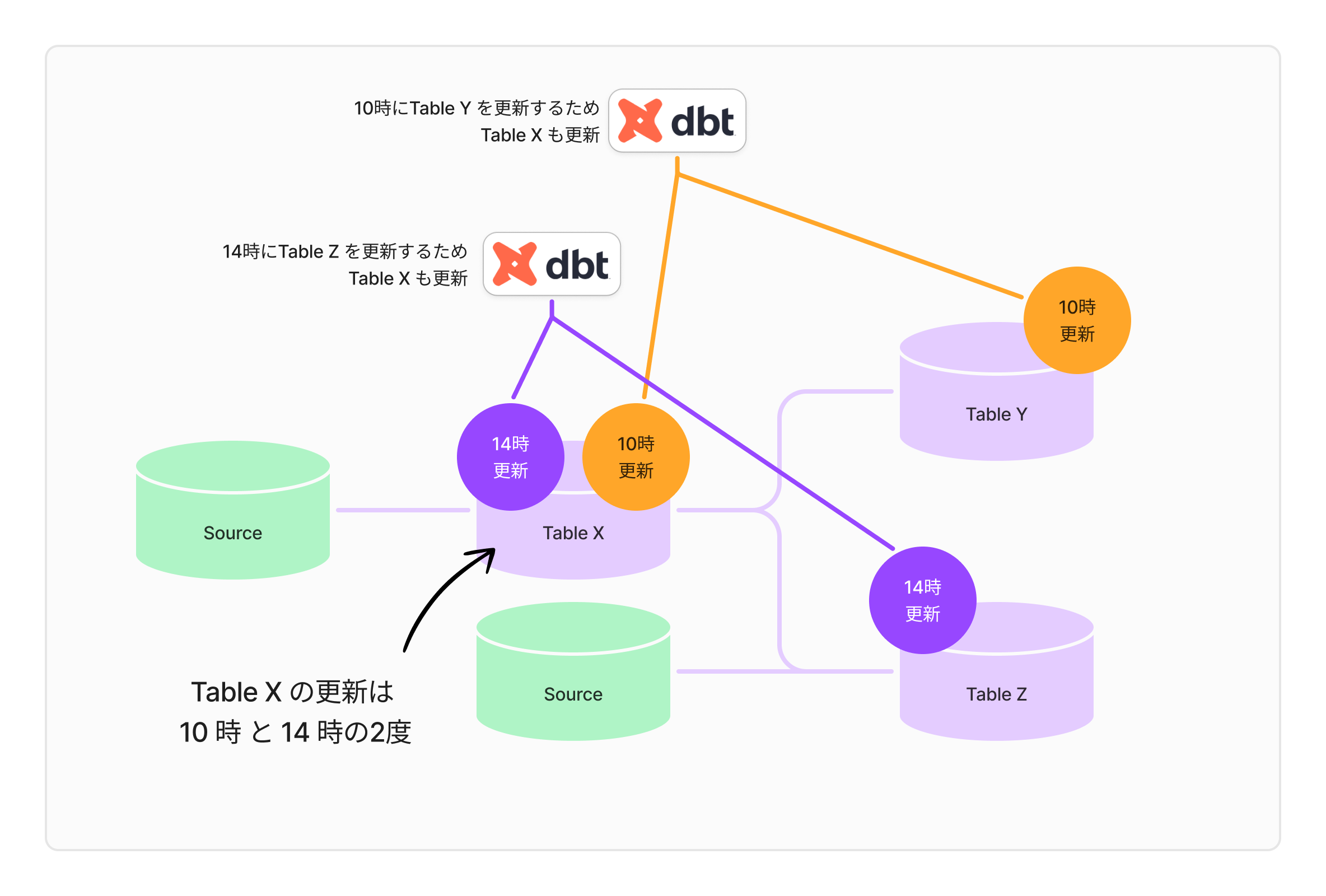
問題はここです。table_X の利用者にとっては、「あれ、さっきまでのデータと違う?」という状況が1日のうちに何度も発生します。 更新が頻繁に行われるのは、タイミングによっては混乱を招くことになります。
多重更新を避けるための Job 管理
そこで、14時の Job では、Table X を更新しないこととします。
このようなことを想定してか、dbtの exclude 機能は、特定のモデルを実行対象から除外する際に使用されます。この機能を使用することで、特定の条件に一致するモデルを簡単に除外できます。
dbt run --select +Table_Z --exclude Table_X
こうすることで、テーブルを多重更新しないようコントロールできます。
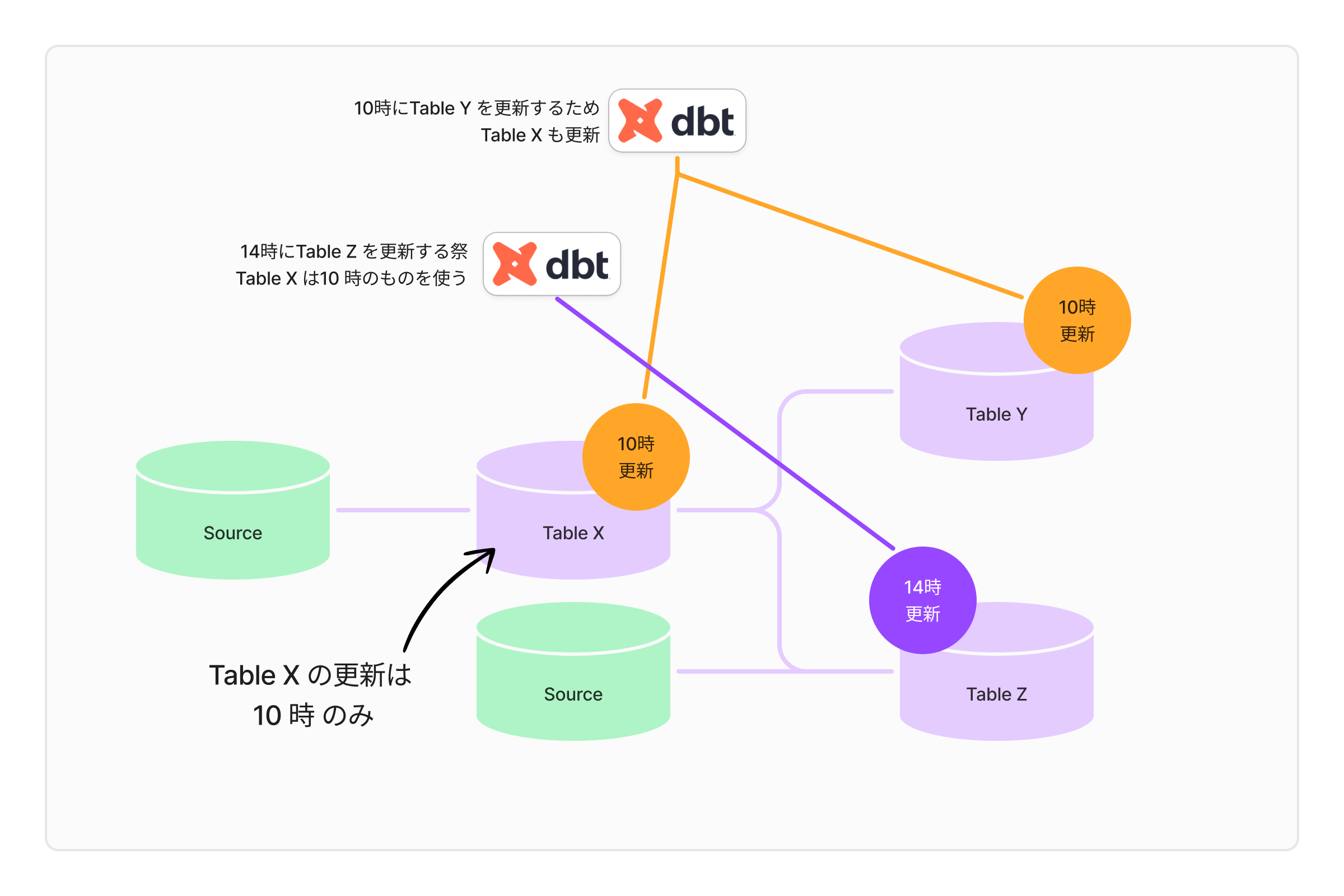
さて、この方法を使って、多重更新が起きているテーブルを洗いだし、逐一 exclude で除外していくのですが――ここで Asset Centric の弱点が顔を出します。
データそのものに定義された情報だけで依存関係を管理していたので、Job が更新する対象テーブルは、 Job を定義するソースに記載されていないのです。具体的には、dbt run --select +Table_Z という処理からは、 Table_Z が更新されることはわかりますが、その上流の Table_X が更新されるのかどうか、判断がつきません。そのため、どの Job がどのテーブルを更新するのか、 SQL を読み解く必要があるのです。
これが結構厄介で、依存関係が増えるほど混乱を招きやすくなるわけです。除外条件も複雑になると、手作業でJobを細かく管理するような状態に陥ります。
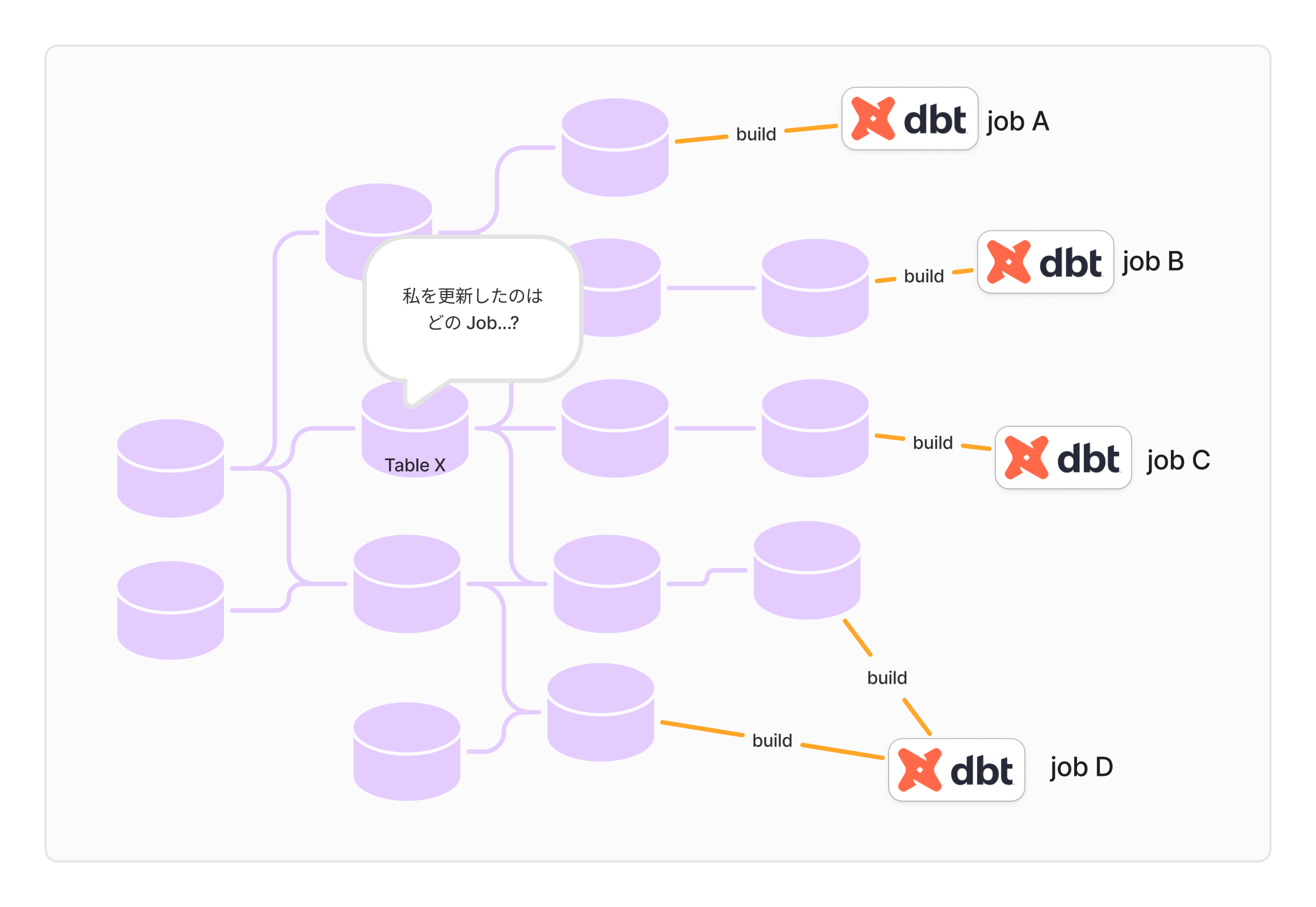
管理のために Asset Centric なアプローチを導入したのに、その管理がさらに厄介になる――というのは、何とも皮肉な話ですね(2回目)。
ログを活用した data observation によって足りない情報を補う。
どのテーブルが、いつ、どの Job によって更新されているのかがわかれば、解決できます。そこで、これらのメタ情報を自動で収集・可視化することで管理の負担を軽減できます。
データリネージの管理は、Asset Centric なツールが自動でやってくれています。 たとえば、 dbt なら、 Job を実行する前に dbt ls -s +table_Y といったコマンドを使って、その結果を時刻とともにログに記録しておけば良いです。 これで「どの Job がどのテーブルをいつ更新したか」を一瞥できるようになります。
実際、こうした機能は既に dbt のパッケージに含まれていたりします。 たとえば、 elementary-data というパッケージは、dbt run の後に on-run-end フックを使ってログを記録し、「どのテーブルがどの Job で更新されたのか」や「どの Job が失敗したのか」といった情報を記録してくれるものです。
https://docs.elementary-data.com/dbt/package-models#dbt-run-results
Job を実行するたびにpost hookで別の処理を走らせるのは、リソースが限られている環境だと少し重たいかもしれません。 こうした場合は、dbtのパッケージを使わずとも、DWH(データウェアハウス)に備わっているロギング機能を活用する方法があります。 たとえば、BigQueryには監査ログの仕組みがあります。 これを利用すれば、dbtが生成したテーブルと、それを実行した Job の情報を確認できます。
https://cloud.google.com/bigquery/docs/reference/auditlogs
次の章では、BigQuery 監査ログ、そして dbt の query comment 機能を組み合わせて、「どのdbt Job がどのテーブルをいつ更新したのか」を把握できる仕組みを作る方法をご紹介します。
監査ログをつかった data observation
query comment を使った Job 名の記録
BigQuery の監査ログを使います
https://cloud.google.com/blog/ja/products/data-analytics/bigquery-audit-logs-pipelines-analysis
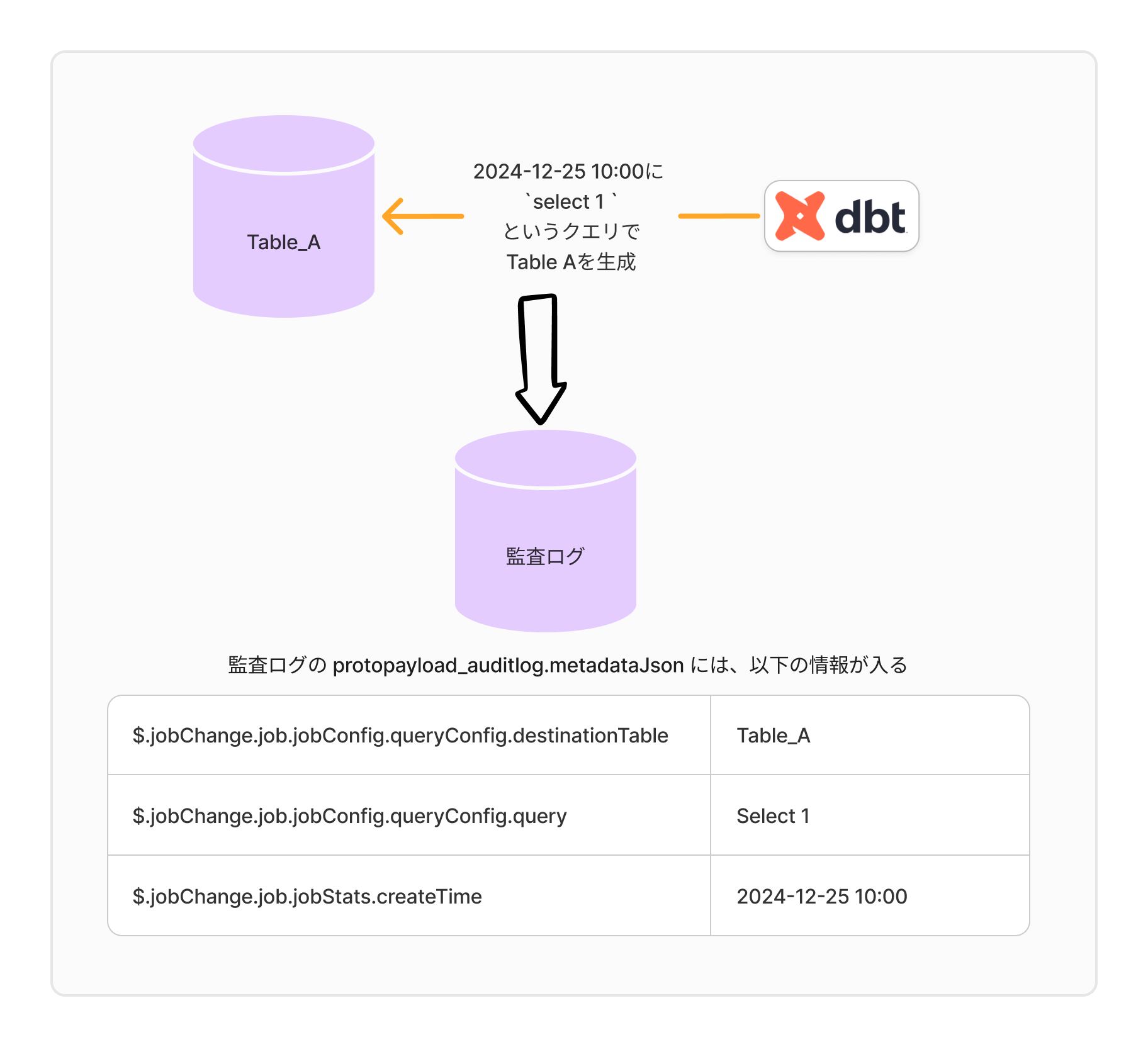
監査ログの protopayload_auditlog.metadataJson というフィールドに、JSON形式で BigQuery のテーブル生成 Job のログが格納されます。 そして、生成されたテーブル名は jobChange.job.jobConfig.queryConfig.destinationTable という key に格納されます。 さらに、BigQuery で実行される SQL 文は、この JSON スキーマの jobChange.job.jobConfig.queryConfig というkeyに格納されます。
さて、 dbt は model ファイルに記述された Jinja 形式の SQL を compile してから BigQuery 上で実行します。 この際、compile する際に動的な comment をつけることができます。
https://docs.getdbt.com/reference/project-configs/query-comment
これを使うと、vars のような 実行時に定義できる変数も渡すことができます。
query-comment:
append: false
Job-label: true
comment: "Job name is {{ env_var('JOB_NAME') }}"
dbt run --select table_X --vars={"JOB_NAME": "daily-Job-10am"}
上記の例で dbt run をすると、コンパイルされた SQL に動的なコメントを載せることができます。
/* Job name is daily-Job-10am */
create or replace view `gcp-project`.`my_dataset`.`table_X`
OPTIONS(
description="""""",
)
as ...
この一連の流れにより、実行元の Job 名をコメントでつけた SQL が、テーブル生成時に、監査ログの jobChange.job.jobConfig.queryConfig に記録されるという仕組みです。
テーブルを更新した Job を可視化する
さて、監査ログから Job 名・テーブル名・生成時刻の3つを取得できるようになりました。 実際にこれらを取得するクエリは以下のようになります。
SELECT
DATETIME(TIMESTAMP(JSON_EXTRACT_SCALAR(protopayload_auditlog.metadataJson, "$.jobChange.job.jobStats.endTime")), "Asia/Tokyo") AS endTime,
SPLIT(JSON_EXTRACT_SCALAR(protopayload_auditlog.metadataJson, "$.jobChange.job.jobConfig.queryConfig.destinationTable"), "/")[OFFSET(5)] AS tableId,
REGEXP_EXTRACT(JSON_VALUE(protopayload_auditlog.metadataJson, "$.jobChange.job.jobConfig.queryConfig.query"),r'/* Job name is (.*?) */') AS Job_name,
FROM
`auditlog_all.cloudaudit_googleapis_com_data_access_*`
WHERE
TRUE
AND PARSE_DATE("%Y%m%d",_TABLE_SUFFIX) >= DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 7 day)
AND JSON_VALUE(protopayload_auditlog.metadataJson, "$.jobChange.job.jobStatus.JobState") = "DONE"
AND JSON_VALUE(protopayload_auditlog.metadataJson, "$.jobChange.job.jobConfig.queryConfig.query") LIKE "%/* Job name is %" /* dbt の Job を指定 */
この結果を使い、可視化を行うと、テーブルごとにどの Job によっていつ作られたのかを確認することができます。 ※実際にこの可視化を行うには、すこしだけ情報をアレンジしています。
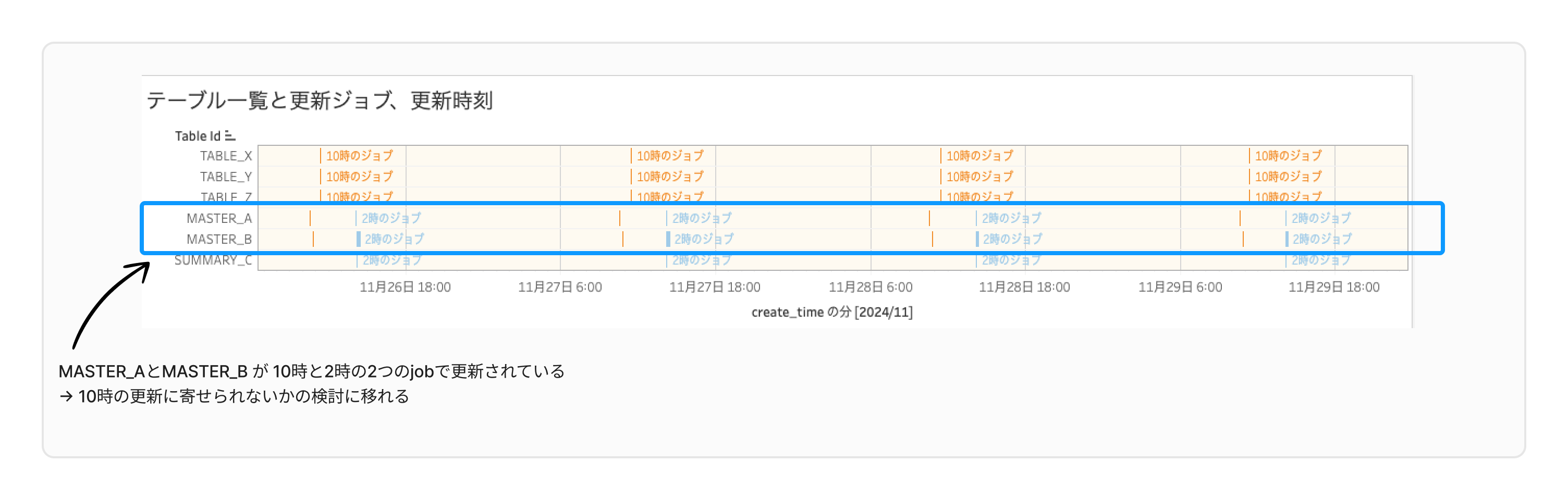
図では、以下のような情報を可視化しています。
- Table ID列:テーブル名
- ガントチャートの色分け:テーブルを生成した Job 名
- ガントチャートの幅:テーブル生成にかかった時間
これにより、以下のような改善が可能になります。
- 複数回更新されているテーブルを確認し、 Job を統合可能か検討する
- 更新のタイミングが近い Job の最適化
また、 BigQuery の監査ログには、 dbt の情報だけでなく、 Job で消費されたリソース量や更新行数といった統計情報も含まれています。 これを活用することで、重たい Job の発見やデータ不備の検知も行えます。 詳しい情報は、データアクセス監査ログの仕様も参照してください。
https://cloud.google.com/bigquery/docs/introduction-audit-workloads?hl=ja
まとめ
データ変換処理における Job 管理では、依存関係の管理や処理の最適化が重要です。 Asset Centric な方法を用いることで、依存関係が複雑になっても管理が容易になります。しかし、更新タイミングの把握や多重更新といった別の課題が発生します。
これらの課題に対しては、監査ログを活用して Job とテーブルの更新履歴を可視化することで対応できます。 その結果、更新タイミングの最適化や Job の統合といった改善点が明確になり、より効率的なデータパイプラインの構築が期待できます。
最後に
今回は Job とテーブルの更新履歴を可視化することで、改善点を探せる状態までをご紹介しました。
さて、監視・可視化が整った後は、実際に複数回テーブルを更新している Job を統合したり、不要な Job を削減したりと、 Job のメンテナンスを行う必要があります。
こちらについては、2025年2月19-20日(自分のセッションは20日17:45~予定です)のRECRUIT TECH CONFERENCE 2025にてご紹介予定です。
テーブルがどの Job で更新されてるか、という情報を元に、 Job の実行時間の調整やリソースの最適化を通してJobを減らした事例についてご紹介したいと思いますので、続きが気になる方は、ぜひ以下よりご参加お申し込みをよろしくお願いいたします!(参加費無料、オンライン開催です)
https://www.recruit.co.jp/special/techconference2025

アナリティクスエンジニア
森田順也
2019年からリクルートでアナリティクスエンジニアとしてデータ基盤の開発運用を担当。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら
