
はじめに
こんにちは!若月と申します。
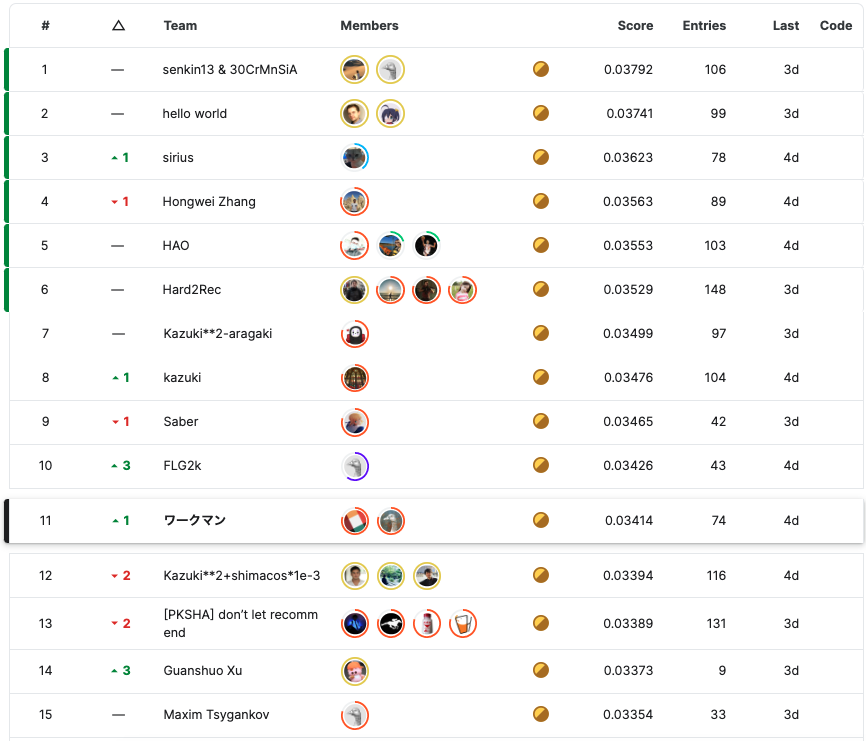
Kaggleで2022/02/07~2022/05/09の間に開かれた H&M Personalized Fashion Recommendations というコンペに 若月 と 翁 のチームで参加して2952チーム中11位となり、金メダルを獲得しました。
今回は我々がコンペで取り組んだ内容について書きます。
全体の流れ
コンペ概要
タスクは簡単には、顧客(customer)の情報、商品(article)の情報、購入履歴(顧客と商品のペア)が与えられるので、各顧客に対して近い未来に買いそうな商品を12件推薦するというものです。
- customers: 年齢やハッシュ化された郵便番号などの顧客情報。100万件程度。
- articles: ジャンルや色などの商品情報。10万件程度。
- transactions: 購入を表す(customer, article)のペアと、購入日、購入価格、購入チャネル(通販or店頭)。3000万件程度。
約2年間分のトランザクションデータが与えられており、評価に使われるのは学習データの最終日から1週間後までのデータです。
提出物は全customerに対して12個のarticleを割り当てた推薦リストで、評価指標はmAP@12です。mAPはmean Average Precisionの略で、各customerが実際に購入したものが推薦リストの上位に入っていればいるほど良くなる指標です。評価期間に購入がないcustomerはスコアに影響しません。
以後推薦の文脈に沿って、今後はcustomerをユーザー、articleをアイテムと呼ぶことにします。
手法
手順は大きく2ステップに分けられます。
- 各ユーザーに対して候補アイテムリストを生成
- 1で生成した候補に対して特徴量を生成し、機械学習モデルで各ユーザーごとのアイテムのランク付けをする
2の結果から各ユーザーごとにアイテム上位12件を取ったものを推薦リストとします。
モデル学習時は生成した候補の中で実際に購入があったユーザーとアイテムのペアを正例、そうでないものを負例として教師あり学習を行います。
これは推薦システムで使われる典型的手法のようです。( 参考 )
自分の場合は Microsoft Recommenders の中からベンチマークの結果が良さそうなLightGCNや、以前業務で使用して役に立ったLightFMなどを試したが、うまく精度を向上させることができなかった後に、この流れに行き着きました。
候補生成
各ユーザーに対して大雑把に購入しそうなアイテムのリストを生成します。 我々は以下のルールにより候補を生成しました。
- 直近人気アイテム
- ユーザーの年齢層での直近人気アイテム
- ユーザーが過去に買ったアイテム
- ユーザーが過去に買ったアイテムの最頻カテゴリ内での直近人気アイテム
- ユーザーが過去に買ったアイテムと類似したアイテム
- ユーザーが過去に買ったアイテムと同じ商品コードを持ったアイテム
- ユーザーが過去に買ったアイテムのOneHot表現の平均とカテゴリのOneHot表現が近いアイテム
ユーザーの情報としては年齢くらいしか役立てなさそうだったので、過去の購入履歴に基づいた情報を作成する必要がありました。
候補の良し悪しはRecall(実際に買ったものを候補でどれだけカバーしているか)やPrecision(候補のうち実際に買ったものの割合)で評価できます。 異なるルールでユーザーとアイテムのペアが重複していても、判別をモデルに任せれば大して問題はなさそうでしたが、なるべく多様性は持たせるようにしていました。例えばIDのみを取り込んでいる共起ベースのルールと特徴ベースのルールなどです。 最終的にRecallは15%~20%くらいになりました。
候補生成時に計算した順位などの情報もモデルに与える特徴量として残しておくと精度が上がりました。
特徴量生成
候補生成によって、ユーザーとアイテムのペアのリストが得られました。 これにユーザー自身の特徴、アイテム自身の特徴、ユーザーとアイテムのペアに対する特徴を横付けします。
- ユーザーの静的特徴(年齢のみ)
- アイテムの静的特徴(ラベルエンコーディングしたもの)
- ユーザーのトランザクションの統計量(購入価格と購入チャネルの平均と標準偏差)
- アイテムのトランザクションの統計量(購入価格と購入チャネルの平均と標準偏差)
- ユーザーの直近購入量、直近購入日までの日数
- アイテムの直近購入量、直近購入日までの日数
- (ユーザー, アイテム)の直近購入量、直近購入日までの日数
- ユーザーが過去に買ったアイテムのカテゴリ最頻値
- ユーザーが過去に買ったアイテムのOneHot表現の平均とアイテムのカテゴリのOneHot表現の内積
- LightFM で計算したユーザーの16次元埋め込み表現
OneHot表現の内積は、候補生成時には全カテゴリの内積の重みなし和を使いましたが、特徴としては各カテゴリの内積それぞれを入れました。
LightFMを使った他のバリエーションとして、ユーザーやアイテムの特徴をLightFMに入れる、アイテムの埋め込みも入れる、LightFMのスコアを特徴量とする、埋め込み表現の近傍を候補とするなども試しましたが、単純にユーザーIDとアイテムIDのみから得られたユーザーの埋め込み表現を入れた場合がスコアが一番良かったです。
学習 or 推論
特徴量生成後、(ユーザー, アイテム, 特徴, ラベル)を持ったテーブルが得られているので教師あり学習が行なえます。
モデルとしては、試した中では最も良かったCatBoostで損失関数をYetiRankとしたものを使いました。モデルのパラメーターはほぼデフォルトです。 他の多くのチームではLightGBMのlambdarankやloglossが良かったらしいですが、その違いの原因はよくわかっていません。 我々のチームはLightGBMでもlambdarankよりxendcgが良かったですが、それでもCatBoostのほうが良かったです。
提出作成時の推論は全ユーザーに対して候補生成と特徴量生成を行うとメモリに乗り切らないので、10個のチャンクに分けて行いました。
データ分割方法

与えられたトランザクションデータの最終週を第0週として連番を付与しました。
Validationには第0週のみを使うようにしました。複数週に対してValidationを行ったほうが良いという意見もありましたが、後述の通り、1週だけでもValidationスコアとPublicスコアの相関が非常に高かったため、最後まで1週のみをValidationに使用しました。
TrainとしてはValidation以外の直近何週かを使うようにしました。 例えば図の例では第1週に含まれるユーザーに対して第2週以前の情報で候補生成と特徴量生成を行ったものと、同様にして第2週, 第3週に含まれるユーザーについて作ったものを結合したものを学習データとしています。 最終的には6, 8, 12週のデータを使用しました。
提出作成時は1週未来方向にシフトしたものを学習データとしました。
アンサンブル
最終提出用に計算コストの高いパラメーターのものを何通りかGCEインスタンス上で計算し、コンペ締め切り最終日に結果が得られました。 しかし、Validationスコア、Publicスコア共に当時の最良ではなかったため、最終提出のうちの1つはそれらの結果を混ぜ合わせたもの(いわゆるアンサンブルやブレンディング)とすることにしました。
アンサンブルのロジックとしてはローカルでの指標が一番良かった 公開コード の方法を採用しました。幸いValidationに対する結果も保存していたため重みを客観的に最適化でき、Publicスコア(&Privateスコア)が最良のものを作れました。
アンサンブルはコンペ中盤に少しだけ試したがあまり効果がなさそうだったので1つのノートブックを育てていく方針にしていました。有効性を確認しておけば他のバリエーションも試せて良かったと思いました。
その他
他の上位解法との比較
KaggleのDiscussion上に投稿された他の上位解法との比較です。
全て同じように候補生成からのランク付けという流れに基づいていました。
我々より上位のチームでは、生成している特徴の種類がより充実してそうなのと、word2vec、tf-idf、 ProNE などの手法を使って候補生成や特徴量生成を行っているようでした。
他の大きな違いとしては我々がランク学習しか試してなかったのに対し、他のチームは二値分類も使ってランク付けをしていたことでした。一位のチームのベストモデルは二値分類として扱ったもののようでした。
BPRで最適化したユーザーアイテム類似度スコアを入れるとスコアが向上したという投稿もありました。我々が使っていたLightFMも同じアルゴリズムのはずですが、スコアの向上には寄与しませんでした。LightFMのスコアは重要特徴量にはなっていたので、もう少し時間をかけて検証すると良かったです。
Validationスコアとリーダーボードスコアの相関
Validationスコアをどの程度信頼できるかを確認するために、基本的に提出ごとにValidationスコアとPublicスコアをスプレッドシートに記録するようにしていました。下の図はPublicスコアとValidationスコアの散布図と、コンペ終了後に公開されたPrivateスコアとValidationスコアの散布図です。

|

|
図の通り、今回のコンペはValidationスコアとPublicスコアの相関は強かったです。 よって、Validationスコアが信頼できること、Privateスコアでの順位はPublicスコアでの順位から大きく変動しないことが期待されました。 実際に我々のチームでは最終提出の2枠として1, 2番目にPrivateスコアが良いものを選ぶことができ、順位表の変動も小さかったです。
Tips
直接精度向上には関係ないが行っていたTipsです。
- ユーザー、アイテムのIDやカテゴリなどの文字列を最初から連番の整数に変換しておくことで、省メモリになるうえ、コードが簡潔になった
- 毎回全てのデータで計算すると時間がかかりすぎて実験サイクルが遅いので、ユーザーを1%, 10%サンプリングしたデータセットを作成し、パラメーターで切り替えられるようにした( 参考コード )
- LightFMの学習やユーザーの購入履歴に基づく特徴量の計算は時間がかかるので、各データサイズ、各週に対して予め計算して保存しておいた
- なるべく依存関係を発生させないためにコードの共通化は最小限に留め、基本的に1実験につき1ノートブックとしてノートブックの出力で結果がわかるようにした
- 結果をチーム内で共有する場合はmainブランチのnotebooksディレクトリに直接pushし、良い影響があることを確認したあとにメインのノートブックにマージしていった
まとめ
H&Mコンペで我々が取り組んだ内容を解説しました。 KaggleのDiscussionに投稿したSolution もあるので良かったら合わせてお読みください。
やれることが沢山あり、チーム内で議論しながらとても楽しく参加できました。ほぼコンペの全期間を通して取り組んでいたのもあり、金メダルを獲得できてよかったです。
また、ちょうど業務でも似たことをやっているプロジェクトに取り組んでおり、このコンペから得た着想でCVRを20~30%くらい向上させることもできました。(月刊Kaggleは役に立つ)
最後に
ここまで読んでいただいてありがとうございます。 弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。

最近は人材領域でのデータ周りの分析などを担当
若月良平
リクルートグループ新卒入社5年目。プログラミングのコンテストが好き。スプラトゥーン2のプレイ時間は3500時間超え。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


