
はじめに
こんにちは。新卒2年目になりました、中間です。業務では主にレコメンドシステムの改善に取り組んでいます。
今回は、5月初旬に終了したKaggleのNBME - Score Clinical Patient Notesという文書データを扱うコンペにチームで参加して1471チーム中4位となり金メダルを獲得することができたので、取り組みなどを紹介しようと思います。
順位の右に表示されている数値が、参加中に確認できる順位と最終順位がどれくらい異なるかを表しています。ご覧の通り、若干の順位の変動があったコンペで、金メダルを獲得することができました。
- コンペURL: https://www.kaggle.com/competitions/nbme-score-clinical-patient-notes
- 解法URL: https://www.kaggle.com/competitions/nbme-score-clinical-patient-notes/discussion/322799
コンペについて
参加しようと思ったきっかけ
私は、過去に文書データを扱うコンペに何度か参加したことがあり、このコンペにも興味を持ちました。 ベースライン を組んで、他の参加者にその内容を共有するというところからスタートしました。
過去にチームを組んだことのある方々とチームを組むことにし、最終的には4人チームでこのコンペに参加することになりました。
タスク
今回のコンペのタスクは、患者に関するメモの中から特定の症例に関連する文言があるかどうかを検出するというものでした。 具体例を挙げると、以下のようになります。
- 患者に関するメモ
- I’m 17 yo. I feel chest pressure these days.
- 特定の症例があるかどうか
- 検索文: Chest-pressure
- 患者に関するメモから「chest pressure」を検出する
- 検索文: thyroid-disorder
- 患者に関するメモから何も検出しない
- 検索文: Chest-pressure
提供されたデータ
今回のコンペで提供されたデータは、アメリカの医師免許試験の一つである USMLE Step 2 Clinical Skills から提供されています。
以下が実際に提供されたデータの一例です。

患者に関するメモの内容がpn_history、特定の症例の検索文がfeature_textです。case_numはどのような症例に属するかを表します。予測対象はlocationで、pn_historyの何文字目から何文字目までが、特定の症例に関連する文言となっているかを示します。annotationは、その特定の症例に関連する文言です。
このようにラベルが付与されたものとは別に、ラベルが付与されていないデータも提供されていました。
評価指標
評価指標には、 micro-averaged F1 score が用いられました。
解法の紹介
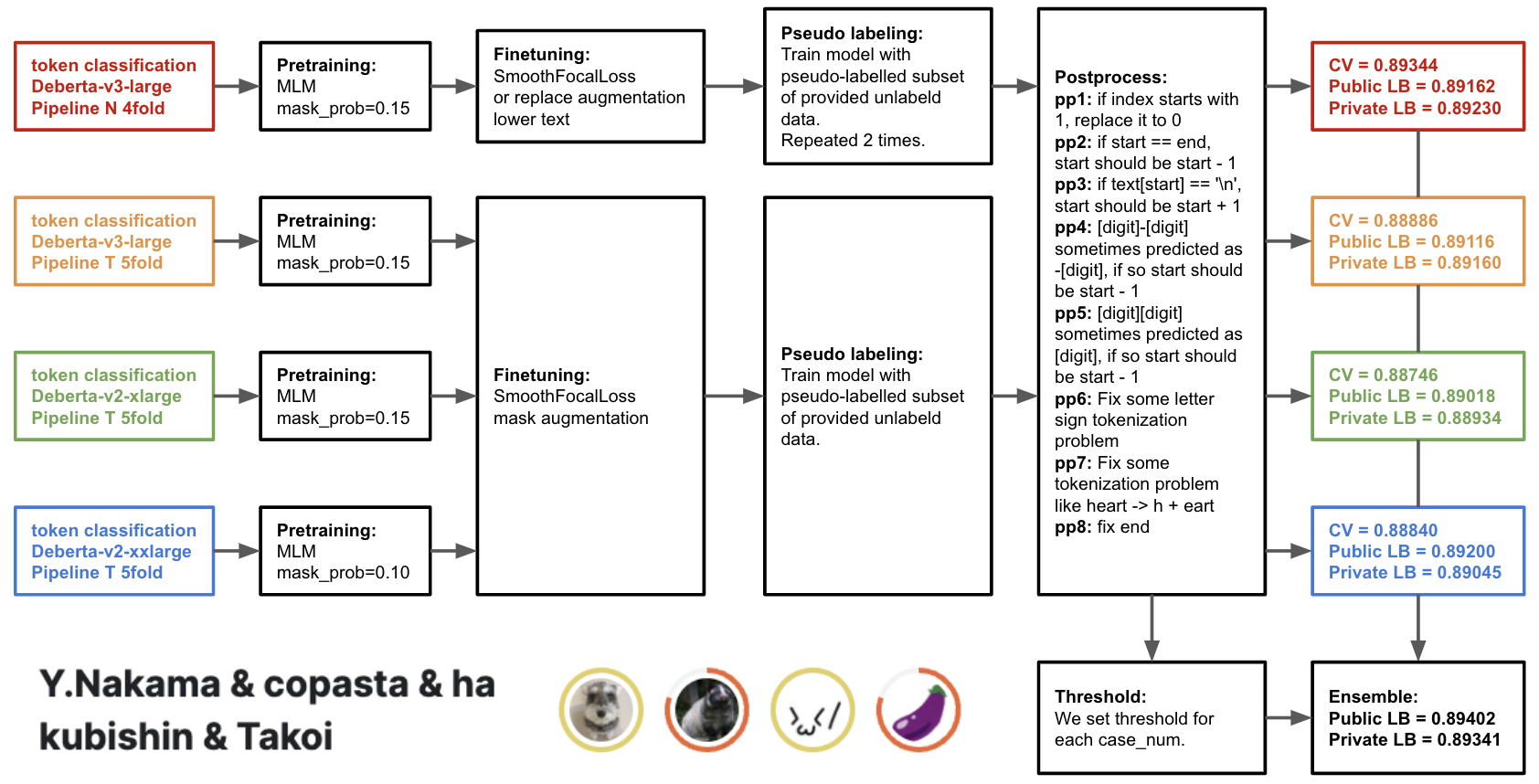
こちらが私のチームの解法の概要になります。 精度向上に大きく寄与した以下の要素について紹介します。
- DeBERTa models
- Pretraining
- SmoothFocalLoss
- Augmentation
- Pseudo labeling
- Threshold optimization
- Postprocess
DeBERTa models
BERT
や
RoBERTa
と比較して、
SQuAD(Stanford Question Answering Dataset)
などのデータセットに対してより良い精度が出ているモデルに、
DeBERTa
があります。DeBERTaは、①disentangled attention mechanismと②enhanced mask decoderにより、BERTやRoBERTaと比較してより良い精度を実現しています(詳しくは
こちら
をご覧ください)。また
DeBERTaV3
は、DeBERTaに対して改良版の
ELECTRA
-Style Pretrainingを取り入れることで精度を向上させたものになっています。
今回のコンペに関しては、DeBERTaが一番精度が出やすいモデルとなっていて、最終的には、DeBERTaの中でも以下の3種類のモデルを使いました。
- DeBERTa-v3-large
- DeBERTa-v2-xlarge
- DeBERTa-v2-xxlarge
DeBERTaがRoBERTaなどと比較して一番精度が出ることに気づき、いち早く ベースライン を出しましたが、今後の文書データを扱うコンペでは初手DeBERTaが当たり前になるかもしれませんね。
Pretraining
「 Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks 」という論文があるように、今回のコンペで扱うデータはドメインが医療であり、提供された医療に関する文書に対して、MLM(Masked Language Model)のPretrainingを行うことで、精度の向上につながりました。MLMのPretrainingを行うことによる精度向上は、過去の文書データを扱うコンペでも報告されており、もはや試すのが当たり前となっているように感じます。実際に、上位の参加者の多くがMLMのPretrainingに取り組んでいました。
SmoothFocalLoss
SmoothFocalLossは、 FocalLoss と Label smoothing を組み合わせたものになります。FocalLossは、クラスが不均衡であるときに精度向上に寄与するもので、今回のコンペでは正例が負例に対して圧倒的に少なく、FocalLossを使用することで精度が向上しました。Label smoothingは、ラベルがノイジーなときなどに精度向上に寄与するもので、今回のコンペでは複数のアノテータがラベリングを行っていることもありラベルがノイジーであったため、Label smoothingを使用することで精度が向上しました。
Augmentation
Data Augmentationには、以下の2つを使用しました。
-
or replace augmentation
特定の症例の検索文であるfeature_textに対して、”-or-”が含まれる場合にランダムでその前後を入れ替えるというData Augmentationをすることで、精度が向上しました。
例)“feels-hot-or-feels-clammy” → “feels-clammy-or-feels-hot” -
mask augmentation
患者に関するメモの内容であるpn_historyに対して、一部のtokenをmask tokenに置き換えるというData Augmentationをすることで、精度が向上しました。
例)“I’m very sleepy” → “I’m [mask] sleepy”
Pseudo labeling
Pseudo labelingとは、学習時に用いてないデータに対する予測値を疑似的に目的変数として扱い、学習に利用する手法です。今回のコンペでは、ラベルが付与されたデータとは別に、ラベルが付与されていないデータも提供されていたので、それを用いてPseudo labelingを行うことができました。ラベルが付与されていないデータを全量使用してしまうと、ラベルが付与されたデータの割合が小さくなり過ぎてしまうので、ある程度サンプリングを行う必要がありました。またPseudo labelingは、1回だけやるのではなく、複数回繰り返した方がより精度が向上しました。
Threshold optimization
今回のコンペでは、
ベースライン
がそうであったように、多くのチームがtoken classificationで解いていました。最終的な予測であるlocationを求めるにあたって、そのtokenを正例として扱うかを決めるために、モデルの出力に対して閾値(デフォルトは0.5)を適用する必要がありました。多くのチームは特に場合分けをせずに閾値を適用するようにしていた印象ですが、私のチームでは、どのような症例に属するかを表すcase_numごとに最適な閾値を適用するようにしました。閾値の最適化の範囲が広すぎると逆効果で、0.47~0.53となるべく狭い範囲で最適化を行うことで、精度が向上しました。
Postprocess
Postprocessでは、以下の4つが大きく精度向上に寄与しました。
-
startが1の予測値はstartを0にする
例えば、予測値が1~10であったときに、0~10に修正することで精度が向上しました。 -
startとendが同じ予測値はstartを前に1ずらす
例えば、予測値が2~2であったときに、1~2に修正することで精度が向上しました。 -
startの文字が改行の場合startを後ろに1ずらす
例えば、予測値が10~20で10文字目が改行\nであったときに、11~20に修正することで精度が向上しました。 -
heart -> h + eart となっているようなものに対してstartを前に1ずらす
例えば、
・heart -> h + eart
のようにtokenizeされてしまい、予測された文字列が中途半端な文字から始まるケースがありました。 そのようなケースをnltkのword_tokenizeを用いて検出し、startを前に1ずらすことで精度が向上しました。
今回のコンペはラベルがノイジーであったことから、Public LBとPrivate LBとでは多少の順位変動が予想されたため、ノイズに左右されにくいPostprocessで確実に精度を改善していくことを意識していました。
さらに上位に行くために何が足りなかったのか
Increase k-fold
1位のチームは、k-foldの分割数を増やし、validationのデータ数を減らしてtrainのデータ数を増やすことで、大きな精度向上が確認できたとのことでした。過去コンペである Google Brain - Ventilator Pressure Prediction においても、k-foldの分割数を増やすことによる精度向上は大きく、今回のコンペでも当然試すべきでした。
Adversarial training
Adversarial trainingにはいくつか手法がありますが、中でも AWP という手法が 過去コンペの1位解法 で使用されていたこともあり、今回のコンペでも使用されていました。私のチームでも試してみて、Pseudo labelingをしていないときは精度が向上しましたが、Pseudo labelingをしているときは逆に精度が悪化してしまい、使用を断念しました。もう少しパラメータを調整してあげる必要があったのかもしれません。
おわりに
最後まで読んでいただきありがとうございました。
結果としては、4位という高順位で金メダルを獲得することができ、また多種多様な解法があり学びも多くて良かったです。チームでの参加も楽しむことができたので、また機会があれば色々な人と組んでみたいと思いました。
一緒に働きませんか?
リクルートというと、あまりKaggleのイメージはないかもしれませんが、多くのKagglerが在籍しています。2021年からKaggle部という部活も立ち上がり、月に一度LT会を開催し、知見を共有し合っています。自分が参加していないコンペの話など聞くことができ、非常に勉強になる場だと感じています。
当社では、様々な職種のエンジニアを新卒・中途ともに募集しております。ご興味のある方は、以下の採用ページをご覧ください。

レコメンドシステムの改善を担当
中間康文
Kaggle Competitions & Notebooks Grandmaster。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


