データ推進室のsaka1です。
しばらく前に異動し、データ分析用の社内Webアプリケーションの開発・保守に携わっています。このシステムはリクルート社内でたくさん(数百人規模)の利用者がいるアプリケーションに成長していたのですが、データ量の増大や利用の拡大に伴い、安定性の問題などが発生し始めていました。
問題の対応過程で、Cloud SQL for MySQLの奇妙なクセやインポート処理の問題点など、運用上課題になる部分が見つかりました。この記事では、問題の調査から解決に至るまでの過程を紹介します。
自分ならどう調査し解決するか? という観点でも読んでいただけると嬉しいです。
背景
今回問題になったWebアプリケーションは、データ分析用のDjangoアプリケーションです。データ分析用といっても、技術スタックとして特別なものはあまり使っていません。記事に関連する箇所のみ簡単に構成を示します。
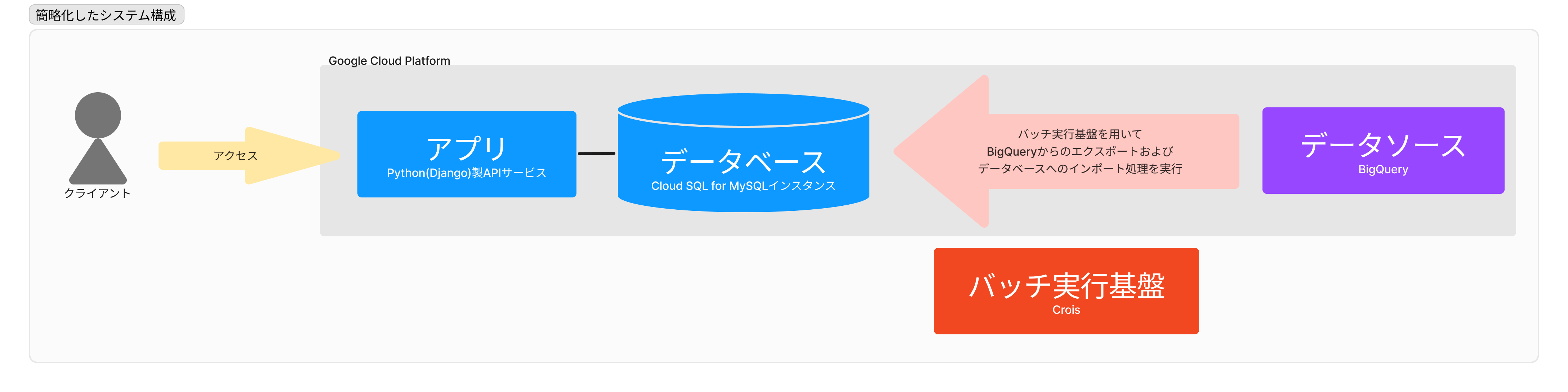
システムは次の要素から構成されています。バッチ部分を除くインフラ全体はGCP上に構築しています。
- アプリ: 普通のDjangoアプリケーションです
- データベース(DB): Cloud SQL for MySQLのインスタンスです
- バッチ: 内製のバッチ実行基盤(Croisといいます)を使い日次実行しています
- データソース: BigQueryです
Croisについては紹介記事があります。興味がある方には読んでいただきたいです: AWS Innovate - Data EditionにてStep Functionsを活用した内製ジョブスケジューラーの技術を発表しました
システムのデータソースとしてBigQuery(BQ)があり、毎日早朝にBQ上でデータ加工を行ってデータマートを作成します。データマートは数十のテーブルから構成されています。作成したデータマートのテーブルはバッチ処理にてCloud SQLインスタンスにインポートされます。
全てのテーブルは日次の洗い替えです。バッチでは大まかに、こんな手順で処理を行っていました。
- データマートの作成を行う一連のSQLを実行し、データをBQ上に作成する
- DB上のテーブルを全て空にする
- DBへのインポート処理を行う
- BQ上のデータを圧縮済みCSV形式でCloud Storage(GCS)にエクスポートする
- Cloud SQLのCSVインポート機能 を実行し、GCS上のデータをDBインスタンスに取り込む
要するに「MySQLの中身を全部消して入れ直す」操作を毎日行っているわけです。素朴で、わかりやすく、単純な戦略です。
どんな問題が起きたか?
この仕組みで運用を開始してしばらくすると、2種類の問題が発生するようになりました。
- 問題A: かなり稀(1ヶ月に数回以下)に、インポート処理が途中で失敗する
- 問題B: バッチ実行時間が延びてきていて、利用者影響が出そうになっている
どちらも問題ですが、特に問題Aのインポート失敗はシステムとして致命的でした。バッチの処理の流れからわかるように、インポートが失敗するとDBにはデータが無いままです。実質的にシステムは利用不能になってしまいます。
不幸中の幸いですが、全てのデータは洗い替えなので、バッチを再実行すればデータは復活するはずですが、瞬時に復旧とはいきません。そもそも、原因不明の失敗を起こしたインポートが再実行で成功するかは不明と言わざるを得ず、安定稼働にとって課題になっていました。
問題Bも軽微とは言えない問題で、深夜のバッチ実行にもかかわらず翌営業時間帯に突き抜けを起こしかかっていました。こちらについては、直接的にはデータマートの機能拡張に伴ってデータ量が増大していたため発生していた現象ですが、何らかの対応が必要な時期に来ていました。
ここからはまず問題Aについて論じ、次に問題Bを合わせた最終的な解決策について説明していきます。
なぜインポートは失敗したのか
まれにインポート失敗が起きるとはどういうことか? バッチのインポート処理の実装を見てみると、gcloud CLIを用いてgcloud sql import csvを叩くものでした。そしてインポート失敗時のログでは409という見慣れないステータスコードが出力されていました。another operation was already in progressとありますが、バッチでは同時に他のAPI呼び出しは行っておらず、かなり奇妙なエラーメッセージに見えました。
ERROR: (gcloud.sql.import.csv) HTTPError 409: Operation failed because another operation was already in progress. Try your request after the current operation is complete.
そこで、GCPのサポートに問い合わせてみました。サポートからの返答は要約すると以下の内容で、予想外のものでした。
- 当該時刻のDBインスタンスでは内部オペレーションが発生していた。HTTP 409はこれが原因である
- 内部オペレーションは不定期に実行される
- 全ての内部オペレーションを確実に検知する手段はない(これについて feature request はある)
- 対策はAPI呼び出しのリトライである
つまりCloud SQL for MySQLには、明記されていない動作があったのでした。インスタンスでは不定期に内部オペレーションが行われるので、API操作はそれが理由で失敗しうるということです。
サポートからは解決策も提示されました。リトライです。
そもそも、API操作であるからには、ネットワーク障害などで失敗する可能性を考慮しないわけにはいきません。APIからのレスポンスが409だった場合はもちろん、タイムアウト等の期待外れの状態に陥った時に回復する戦略が、私たちの実装には欠けていました。
見かけ上ネットワークエラーだったとしても、実はGCP側にはレスポンスが届いている可能性も(コーナーケースとはいえ)ありえるはずです。そういった場合を考慮するためには、リトライのたびにまずStatus APIを叩きインポートの成否を確認し……といった具合に、単にリトライするのではなく状態を考慮する必要がありそうでした。
実装はやや複雑になりそうですが、とりあえず問題Aの対応方針を立てることができました。
さらに踏み込んだ検討
直接的な解決策はインポート処理のリトライでした。これだけでも一定水準の解決にはなるかもしれませんが、前提を揺らしてみたり考察を深めたりすることで、さらに良い解決策が見つかることもあります。また、実行が遅いという問題Bは解決されていないため、解法をもう一捻りする余地がないか検討を進めていきます。
構造的な安定性を得るには?
前節で述べた対応方針は、リトライでインポート処理を安定させる事を狙っていました。しかし、より根本的な仮定を疑うことで、システムの安定性を高めることはできないでしょうか?
インポート処理が失敗すると困るのは、洗い替え前のデータを全削除してからインポートしているからです。もし、既存データを削除していなかったならば、その既存データを使ってアプリケーションは稼働を続けられます。 もちろん、古いデータで稼働を続けるとデータ鮮度に影響がありますが、データの内容およびシステム要件として、数日程度の鮮度低下は許容範囲だとわかっていました。
つまり、そもそも新しいデータが利用可能になる前に古いデータを消しているのが本質的な不安定さを生み出しているわけです。 こういった問題はRDBMSを普通に使う分には発生しません。なぜなら、トランザクションでデータの削除と挿入が同時に起こったかのように処理できるからです。
以上の考察から、データの洗い替え処理をMySQL上での操作に置き換えるアイディアが有望だと考えて検討していきます。そうなると、Cloud SQLのインポート機能では対応できなくなります。
Cloud SQLのインポート機能から脱却する
Cloud SQLのインポート機能は、簡単に使えて実行結果も容易に確認できる点は便利です。しかし、性能面でも問題があることがわかっていました。
- 実行時間の問題: インポートはあまり高速ではない。GCP側でバッチ処理のようなものを挟むので、一定程度のオーバーヘッドがあるように見える
- 並列性の問題: 1インスタンスにつきインポートは同時に1実行しかできない。これも性能上のボトルネックになりえる
つまりインポート機能が問題Bの原因の一部のように見えました。
原理的に考えると、今回のデータマートのインポート対象のテーブル群は互いに独立したデータであり、取り込み対象のCSVが分割されているので、並列処理が可能なはずです。具体的な実装例として、 MySQL ShellのParallel Table Import Utility はオブジェクトストレージからの並列取り込みができるそうです。しかし、Parallel Table Import UtilityはGCSに対応していないようだったので、自前で実装することにしました。
自前で実装というと大変そうに聞こえますが、MySQLにはバルクロード用の専用構文 LOAD DATA LOCAL INFILE が備わっています。バッチから適当な並列度でこれを流すだけです(詳細は後述)。
最終的な解決策
ここまでの議論を踏まえ改善したバッチ処理は、全体としてこのような事をします。
- DB上にて、洗い替える対象のデータベースとは別のデータベース(インポート用データベース)を作成しておく
- インポート用データベースに対してインポート処理を行う
- GCSのバケットから並列にダウンロードを行う
- ダウンロードしたcsv.gzファイルを解凍し並列でLOAD DATAする
- 洗い替える対象のデータベースの全てのテーブルを、インポート用データベースのテーブルにアトミックに差し替える
いくつかポイントがあるので順番に紹介していきます。
並列インポート
インポート処理はバッチ処理基盤のコンテナ上で行います。先述のようにLOAD DATA文をCloud SQLインスタンスに直接発行する形でバルクロードを行うこと、その処理を並列化してあること、が特徴となります。全ての実装はPythonで行いました。
まずGCSからのファイルダウンロードですが、BQからエクスポートされたcsv.gzファイルは分割されているので、もともと並列処理しやすくなっています。標準のGCSクライアントSDKに Transfer Manager という並列ダウンロード実装が含まれているので、これを使うだけです。
ダウンロードしたcsv.gzは解凍後にLOAD DATAします。処理を並列化するために、実装ではExecutorを使いました。並列度が高すぎるとDBサーバの負荷が上がりすぎたりスループットが落ちたりと弊害があります。そこでExecutorによって適度な並列度を与えるようにしています。
さらに、対象のデータマートではテーブルごとのサイズに不均衡がありました。テーブル単位での並列化だけだと、結局は数個ある巨大テーブルのロード時間は短縮せず、全体のバッチ実行時間の削減幅は限定的でした。そこで、同一のテーブルに対してもLOAD DATAを並列に投げるようにしてあります。この部分の実装には ProcessPoolExecutor を用い並列性を引き出すようにしてあります。
まとめると「テーブル単位での並列性」「個々のテーブルにおけるLOAD DATAの並列性」の2つを抽出するために、Executorを二重に使っていることになります。
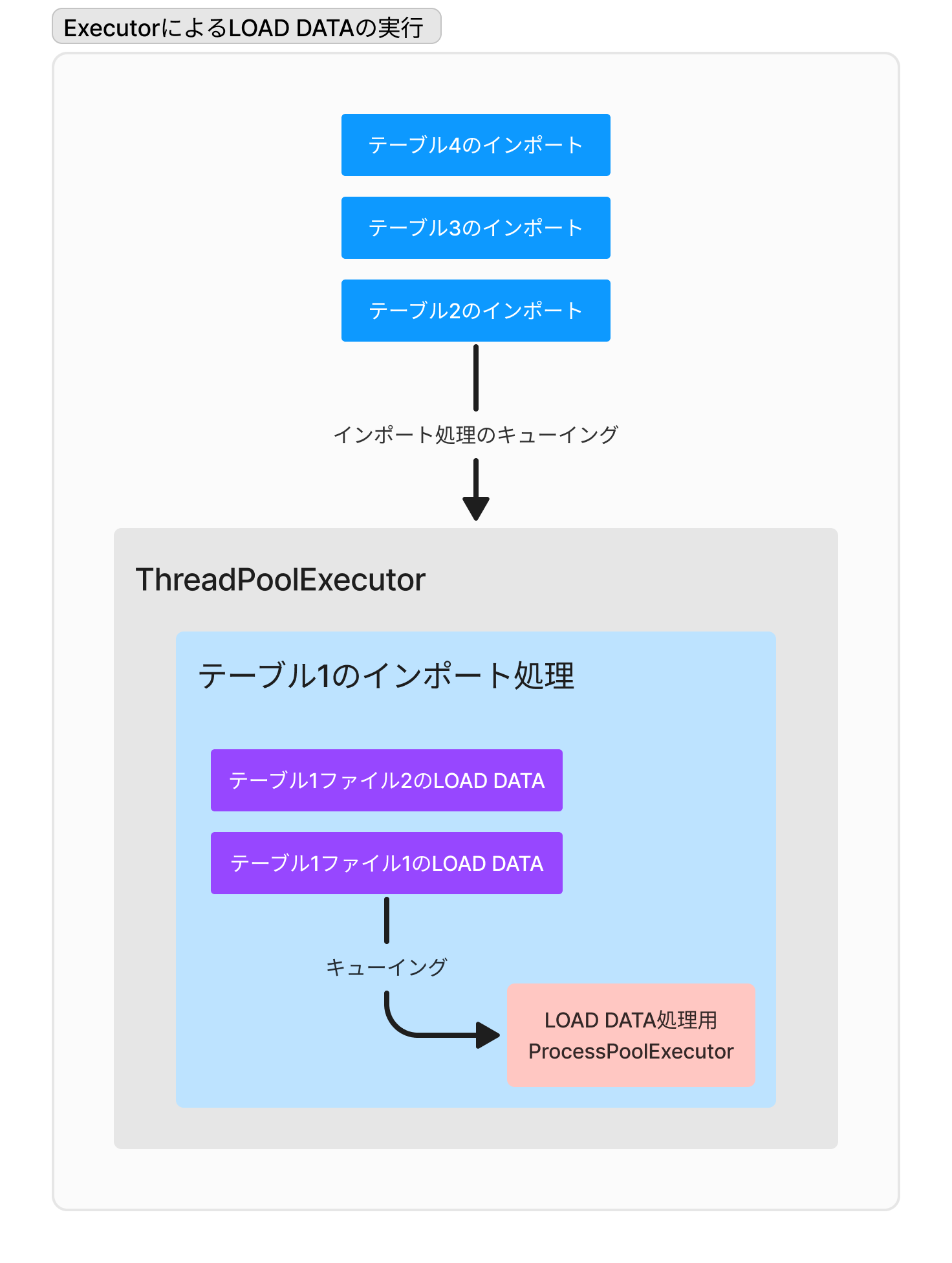
並列化実装における工夫
並列化はコードの可読性を下げやすく、バグが発生した際にも何が起きたか分からなくなりがちです。実装で利用したProcessPoolExecutorは低水準な並列処理部分を抽象化してくれますが、それでもかなり癖があり、普通のPythonコードに見えるものが裏側でプロセスのフォークをしてプロセス間通信では引数をシリアライズして……など複雑な仕組みを使っているため、奇妙な挙動と制限が多いです。
今回の実装では、いくつかの点には特に注意を払いました。1つ目はfork-joinの並列化パターンを守って例外を作らないことです。
# 実際に稼働しているコードの一部を簡略化して示した
with ProcessPoolExecutor(max_workers=parallel_table_count) as executor:
tables = conf.params.target_db_import_tables
futures = [
executor.submit(
_process_table,
conf,
tables,
)
for t in tables
]
for f in concurrent.futures.as_completed(futures):
try:
f.result()
except Exception as e:
logger.error(f"Failed to process table: {e}")
raise
Executorを初期化し、全てのテーブル分の処理をsubmitして、結果をconcurrent.futures.as_completedで待ち受ける、このパターンを崩さないように注意しました。それぞれのsubmit間で共有されるオブジェクトは最小限(イミュータブルなconf系の値など)になっています。
もう1つは、トレース用のロギングを丁寧に、あちこちに挿すことです。ログフォーマットにもひと工夫があります。
# ロガーに渡すログフォーマットの設定例
log_format = "%(asctime)s [%(process)d] %(name)s:%(lineno)s %(funcName)s [%(levelname)s]: %(message)s"
logging.basicConfig(
level=loglevel, format=log_format, datefmt="%Y-%m-%dT%H:%M:%S%z"
)
%(process)d はプロセスIDをログに含めるようにする指定で、マルチプロセスのPythonコードでは入れておくと流れが追いやすく、有効に感じました。
他にもあれこれ工夫したポイントはあるのですが、記事の分量の関係で省略します。いずれにせよ根幹になるアイディアは、ここで述べた以上のものはありません。
テーブルのアトミックな差し替え
インポート完了後には、インポート用データベース上に洗い替え後の最新のテーブルが準備できています。これを使って洗い替え対象のデータベースを最新化することを考えます。
素朴な実装は素直にDELETEしてからINSERTすることです。ここでは洗い替え対象のデータベースをdb、インポート用データベースをdb_importとしています。
-- テーブルtを最新化する処理の実装例
START TRANSACTION;
DELETE FROM db.t;
INSERT INTO db.t SELECT * FROM db_import.t;
COMMIT;
この実装はおそらく動作しますが、データベース上の全データを削除・コピーすることになるので実行コストが高い点は問題で、できることなら避けたいものです。
今回採用したのは、RENAME TABLEを使う方法です。
RENAME TABLE db.t TO db_old.t, db_import.t TO db.t;
db_oldは洗い替え前のデータを退避させるためのデータベースです。やっていることは要するにテーブルを db_import → db → db_old の順で玉突き移動させることです。図にすると分かりやすいです。
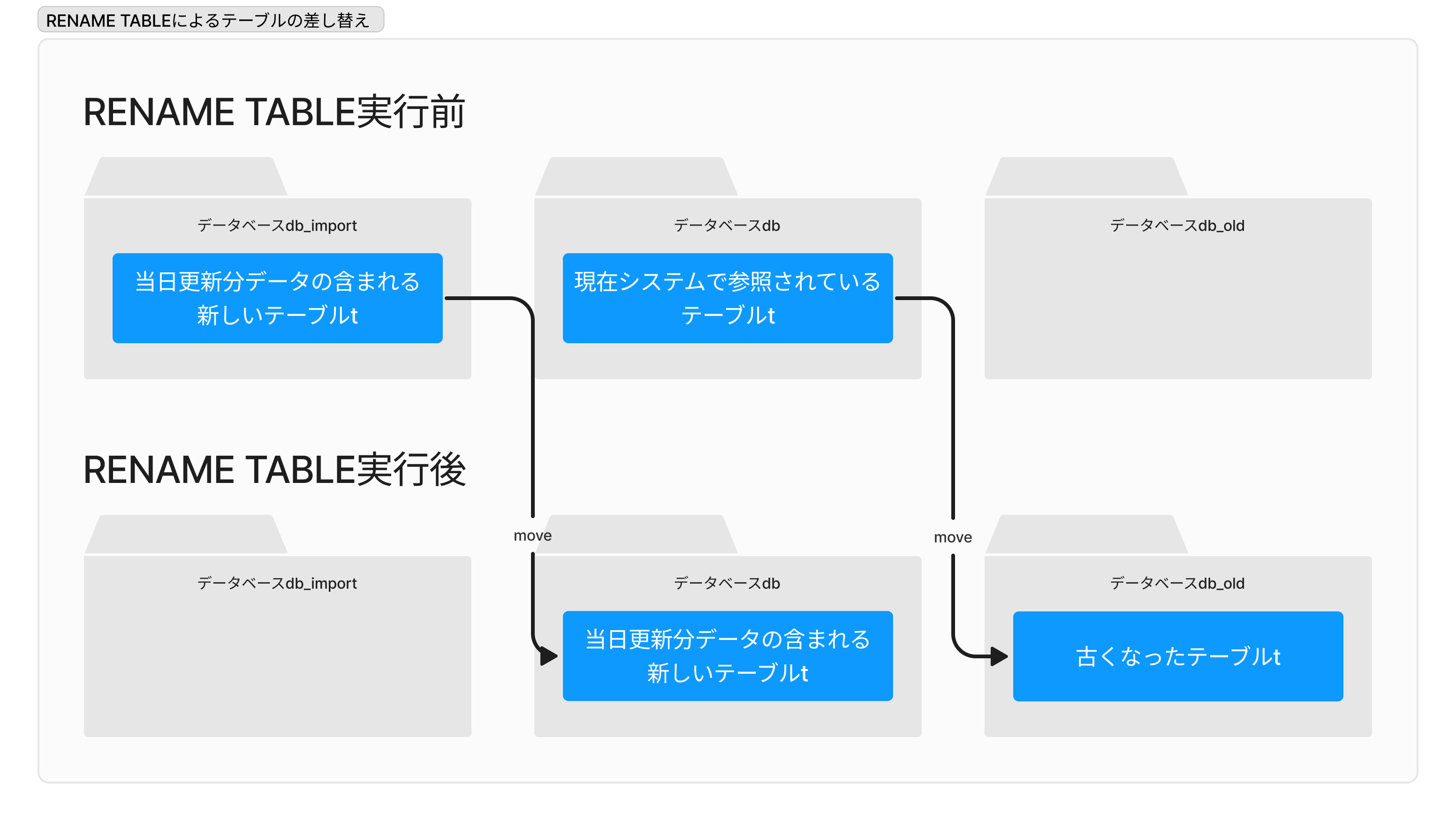
都合がいいことに、RENAME TABLE文は一文で任意の数のテーブルを移動させることができ、しかもその処理はアトミックに実行されます。仮に何らかの理由でバッチ処理が失敗しても中途半端な状態にはならず、常に古いテーブルか新しいテーブルのどちらかが利用可能であるとMySQLが保証してくれます。
さらに、RENAME TABLEは通常メタデータの書き換えでテーブルを移動させるため、物理的なデータコピーが発生せず、効率よく動作するのも利点です。
データの整合性を確実に保つのはしばしば容易でない問題ですが、問題をMySQLに解いてもらうことで、バッチ側のコードは単純かつ堅牢、しかも効率的な実装になりました。
結果
本記事で説明した方式をしばらく前にリリースし、今のところ安定稼働しているようです。インポート処理の実行時間については10倍程度の高速化ができました。
さらに、副次的なメリットですが、アプリケーションの無停止稼働に近づきました。これまでの方式ではMySQLのデータが空っぽなタイミングがあるため、その時間帯についてはアプリケーションをメンテナンスモードに切り替え、利用者からのアクセスを遮断していました。
システムは深夜稼働していなくともよいので、これで通常は困らないのですが、何らかの理由で営業時間帯にバッチを再実行したい時などでも、利用者影響を最小化することができるかもしれません。
未来に向けた宿題は?
この記事ではバッチの問題点の検討を行い、最終的にバッチ実行を堅牢にし実行時間を大幅に短縮する所までを行いました。それでは、これが満点の解答なのでしょうか。
筆者が思うに、次に疑う箇所があるとすると「本当にデータのインポートが必要なのか」かもしれないと感じています。
データをCloud SQLにコピーすることで、ある種のOLTP的なクエリは高速に実行できたり、Djangoから扱いやすくなったりする等のメリットはあります。しかし、例えばBigQueryに直接クエリを発行する設計にすれば、そもそもデータのコピーを工夫して行うという課題自体を消滅させられます。単一のCloud SQLインスタンスに処理させるには荷が重いOLAP系クエリも、BigQueryならば高速実行できるかもしれません。
このように、システムの改善はある意味で終わりがないものです。引き続き利用者にとってより価値あるシステムにしていくべく、問題を探し続けることになるでしょう。
まとめ
この記事では、Cloud SQLのインポート処理が不安定だという問題の調査から始め、解決に至るまでの過程を紹介しました。
もし私たちが場当たり的な対応に終始していたならば、もしかするとリトライ実装までで改善は止まっていたかもしれません。そうではなく、より根本にある真の課題を探し続けることの大切さを実感できる案件だったように感じます。

ソフトウェアエンジニア
saka1
2023年リクルート入社後、Webバックエンドやデータエンジニアの領域のお仕事をしています。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら