
はじめに
この記事は Recruit Advent Calender 2021 の5日目の記事です。
株式会社リクルートでデータエンジニアとして働いている宮井と申します。Githubでは @mia-0032 として活動しており、 fluent-plugin-gcloud-pubsub-custom といったOSSを開発しています。仕事では社内のデータ基盤のうちの1つのプロダクトを初期から担当しています。
「Crois」と名付けられたそのプロダクトは、機械学習を用いたバッチ処理を主なターゲットにしたジョブスケジューラー/ワークフローエンジンです。社内を横断して使われることを想定しており、高いスケーラビリティ、安定性、セキュリティを実現することが求められています。
これらの要件を満たしつつ省力で運用できるようにAWSのマネージドサービスを活用した構成となっており、2021年8月19日に開催された AWS Innovate - Data Edition というイベントで、CroisでのAWSの活用方法について発表させていただく機会がありました。

自身が登壇した時の動画は公開期限が過ぎてしまっているため、この記事では発表のときに使用したスライドを用いながら、その概要をお伝えさせていただこうと思います。
発表の要点
この発表で聴講者の方に伝えたい内容が以下です。特に Step Functions を使ったワークフローエンジンのようなものを実現する際に参考になるかと思います。
- 高いスケーラビリティと安定性を実現する技術
- ジョブ実行の制御をすべてStep Functionsへ移譲することにより、Crois本体がスケールする必要のない構成をとることが可能。
- 社内横断で使われることを想定したチーム間でのデータの隔離を実現する技術
- ユーザーが作成するコンテナを変更することなく、Croisの処理を介在させる仕組み
- Step Functionsを使っていく上で遭遇した問題の解決方法
- 最大入力サイズの制限はS3にイベントをロード・ストアすることで対応。
- コンテナ起動エラーはコンテナ内部からDynamoDBにフラグを書き込んで無ければリトライする。
- Map状態で並列数の最大値はStateMachineと入力配列を分割して対応。
発表スライド
発表に使用したスライドを公開しています。ご興味あればご覧ください。
スライドには兄弟のような社内プロダクトの機械学習プラットフォーム「Crafto」も含まれているのですが、ここからは自分が担当したCrois部分を抜粋しながらコンパクトにまとめていきます。
Croisの概要
Croisはコンテナベースのジョブスケジューラー・ワークフローエンジンです。Croisが社内で生まれた背景には、機械学習を用いたバッチ処理が日々増えていく中で、多くの課題が出てきたことがあります。
データ活用における三者それぞれが課題に感じていた例が以下です。

こうした課題に対して、Croisは以下の方法で解決を試みています。

この解決策を実現するために以下の5つのシステムを提供しています。

特にコンテナイメージのカタログ機能が他のジョブスケジューラーと大きな違いになります。
CroisのWebUI
Croisでは処理に用いるコンテナイメージのことをモジュールと呼んでいます。先ほど紹介したモジュールのカタログページが以下です。
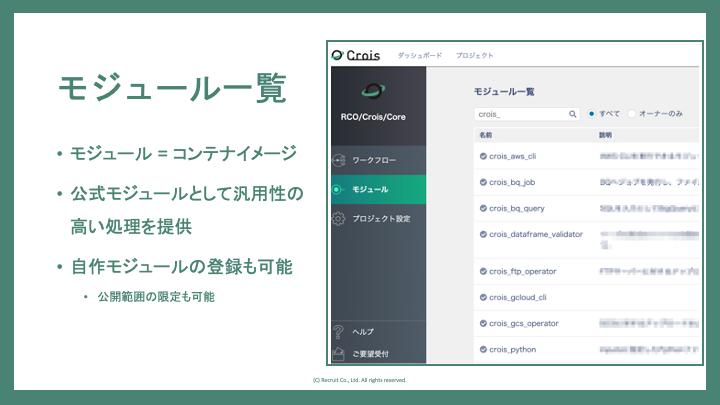
Croisではよく使われる処理を公式モジュールとして、Crois開発チームから提供しています。これにより簡単な処理であれば、ユーザーがコンテナイメージを作成する必要なく、ワークフローの記述だけで完結させることができます。

ワークフローのフローはYAMLで記述します。パラメータや入力出力ファイルなどには変数が使えます。
Croisの運用規模
社内横断で使われているため、大小さまざまなジョブが実行されています。登壇当時の稼働状況は以下です。

ワークロードとして特徴的なのは、巨大なインスタンスを1つだけ必要とするジョブもあれば、比較的小さなインスタンスを大量に使うジョブもあることです。Croisのアーキテクチャは、それらを問題なく実行できるようになっています。
当時と比較すると実行されるジョブは増えていますが、稼働率は維持しており、スケーラビリティの面では大きな問題が発生していません。
Croisの技術概要
Croisは社内横断で使われることを想定して設計されています。そのために必要とされるシステム要件は2つあります。

高いスケーラビリティが必要とされることは言うまでもないのですが、高いセキュリティについては補足が必要かもしれません。
ジョブスケジューラーというシステムの特性上、CroisにはパスワードやAPIキー等の機密情報が保存される可能性があります。 それらの情報をCrois開発メンバーや他のチームのメンバーが閲覧可能な状態になっていた場合、流出の危険性もあり、また離任時の影響範囲が大きくなります。
そういったことを考慮して、高いセキュリティという要件が入っています。
高いスケーラビリティ
高いスケーラビリティは、ジョブの実行処理をStep Functionsへ完全に移譲することで実現しています。
Crois本体がジョブの実行に関与しないため、本体の処理性能や障害がジョブの実行に影響しません。本体がジョブ実行に関与するとジョブ実行数の増加に伴い本体をスケーリングさせる必要がありますが、この構成をとることで不要になります。
Crois本体とジョブの状態の連携は、CloudWatch EventsやDynamoDBを介して行っており、これらも自動的にスケールします。
ジョブ実行をStep Functionsで行うためにはワークフローをState Machineへ変換する必要があります。
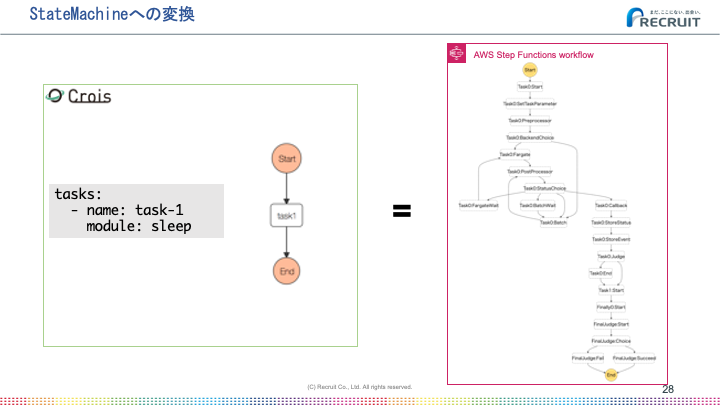
1タスクしかないシンプルなワークフローでもこの図のように何段階にも分割されたState Machineが生成されます。この中にはパラメータ変数の変換処理やエラー時のリトライ処理などが含まれています。
なお余談ですがCroisの初期の頃はもっとシンプルなState Machineでした。 過去に書いたテックブログの記事 を見ていただけるとご理解いただけると思います。
Stateが細かくなった理由はいくつかありますが、初期と大きく変わったのはコンテナ実行ステータスの扱いです。
初期の頃はコンテナが失敗したらそこで例外を投げてState Machineの実行を異常終了させていました。当時はそれで特に問題はなかったのですが、エラー時でも必ず実行される機能(finallyのようなもの)を実装するにあたり、コンテナが異常終了だったとしてもState Machineの実行自体は継続させる必要がでてきました。
そういった拡張をしていく中で、Step Functions側でハンドリングできるものは基本的にStep Functions側で行った方がメンテナンス性が高いことがわかり、結果として細かいStateのState Machineを生成する形になりました。
高いセキュリティ
高いセキュリティは、Crois上の大きな利用者グループ組織の単位であるルートプロジェクト単位で発行されるIAMロールとペアになるKMSキーによって実現されています。
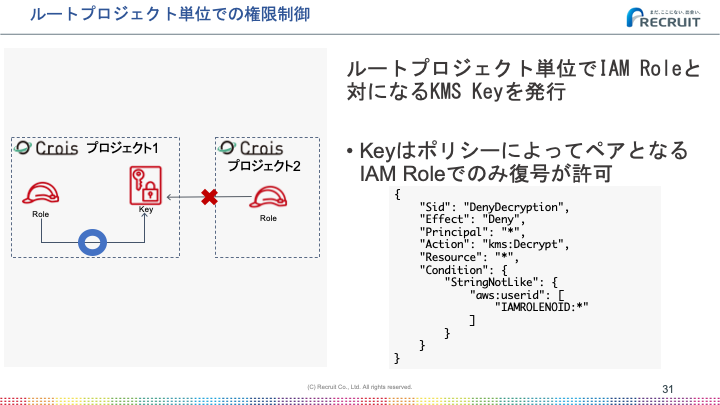
このキーを使ってタスクが出力したファイルや機密情報の暗号化を行っています。
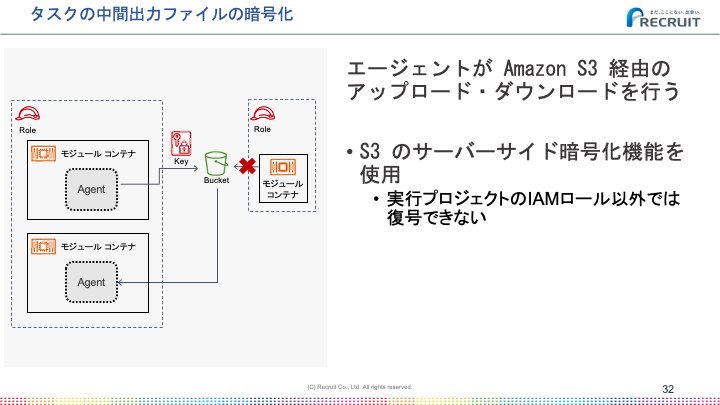
またファイル以外にも単なるパラメータなどを後続のタスクに引き渡したいことがあります。例えば、出力結果の配列で後続のタスクをループしたいことがありました。
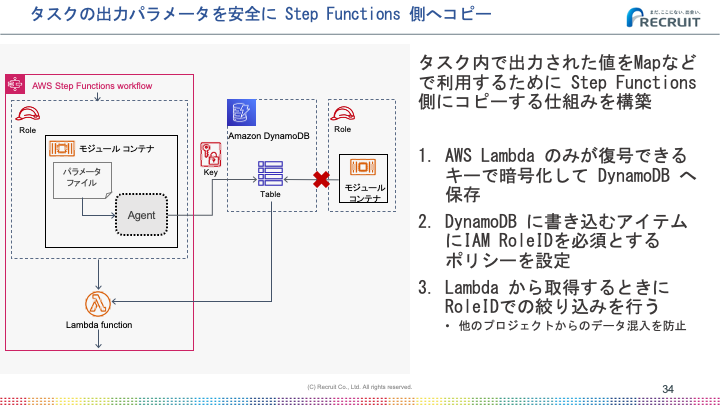
コンテナから単にDynamoDBへの書き込みを許可してしまうと、他のプロジェクトのタスクのレコードまで書き換えることができてしまいます。悪意がなくても誤った操作をしてしまうことはありえます。
DynamoDBのポリシー設定を工夫してそういった事態を防いでいます。
コンテナ内でCroisの処理を介在させる仕組み
ユーザーが作成するコンテナの処理が実行される前後で、前のタスクの出力ファイルを取得したり、逆に出力したファイルを後のタスクに引き継ぐためにアップロードしたりと、Croisが処理を介在しなければいけません。
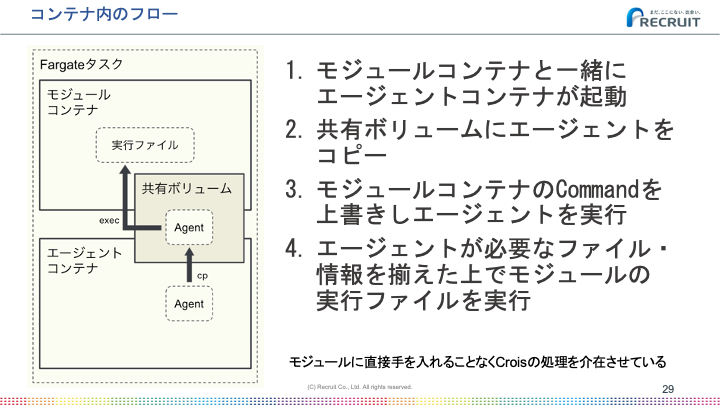
ユーザーの作成するコンテナに直接手を加えなくても、このように後からエージェントを注入する仕組みで処理を介在させることができています。
このエージェントがいるおかげで、リトライの処理やログ転送などが行いやすくなっており、このアーキテクチャは正解だったと感じています。
Step FunctionsのLimitsを乗り越える
Step Functionsへ処理を移譲することでスケーラビリティと安定性を実現していることは先ほど述べましたが、実際に運用を始めるとStep Functionsの制限に引っかかってしまうことが何度かありました。
ここからはその制限をどのように乗り越えたか紹介します。
最大入力サイズの超過
State Machineの実行時にInputを指定することができ、実行中も各Stateに引き継がれていきます。このInputには最大サイズが規定されており、それを超えるとエラーで終了します。
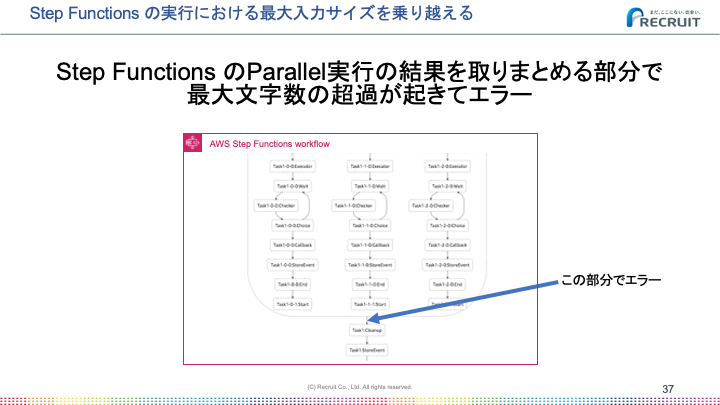
その最大サイズは十分に大きくてシンプルなフローでは問題にならないです。しかしループや並列実行を行うと各Stateの結果が配列で渡ってくるため、InputがそのStateの数だけ複製されるような状態になり、最大サイズを超過しました。
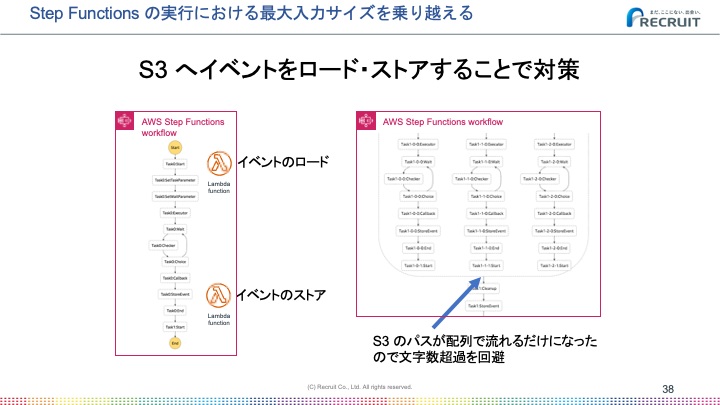
対策として、Inputとなる値をS3へ格納してループや並列実行の取りまとめ部分ではS3のパスのみが渡る形にしたところ、それ以降はエラーがなくなりました。
コンテナの起動エラー
State Machineからコンテナを実行する場合に限らず、ECS上でコンテナを実行する際にはネットワークインターフェースの初期化失敗などのエラーが発生する可能性があります。
すべてのエラーが事前にわかっているわけではなく、コンテナのメインの処理自体のエラーと区別がつかないようなパターンも存在しました。
Crois特有の問題としてはユーザーの作成したコンテナの処理の冪等性がユーザー側に委ねられていることです。このためエラーが出たら単純にリトライするわけにはいきません。誤って複数回実行されてしまうとまずい処理があることが予想されるためです。
そこで先ほどコンテナ内のフローで出てきたエージェントが活躍します。
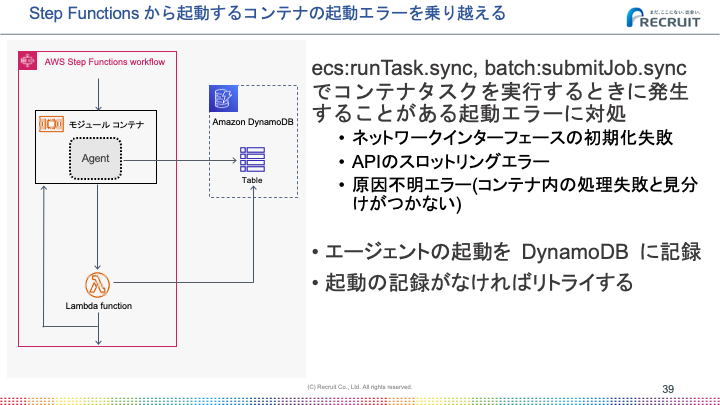
コンテナの起動エラーの場合、エージェントも起動しません。エージェントが起動したことを記録しておいて、起動したフラグがなければECSタスクを再実行するというフローを組むことで、自動的にリトライする仕組みができました。
Map Stateの同時実行数制限
Map Stateを使うことでInputに含まれる配列を使ったループ実行を実現できます。Map Stateの並列度はMaxConcurrencyというパラメータで設定できるのですが、無制限(0)を指定しても実際には40並列で頭打ちになることがわかりました。
Step FunctionsドキュメントのMapの項目 にも記載がある通り、Inputに指定した配列の要素数が40を超えると、この現象が起きます。処理中の要素が40個を超えるとどれかが終わるまで次の要素へ進みません。
この並列度の制限は例えば100並列で処理を回したいといった要件が出てきたときに問題になります。
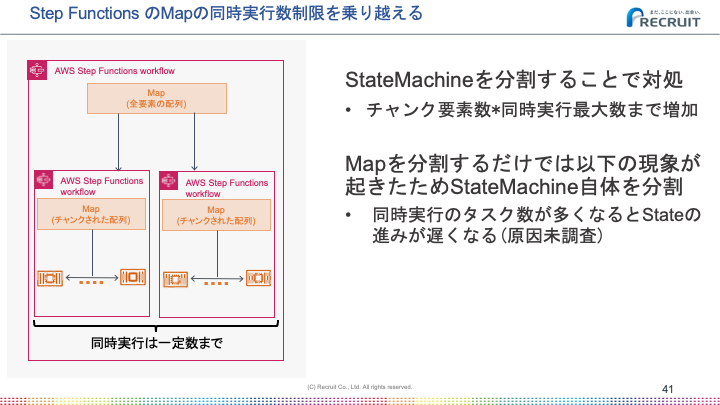
この仕組みは内部的には複雑なため、詳細については別途記事にしたいと思っています。
アイディアを簡単に説明すると、Mapに与えられる配列を分割してループ内処理を切り出したState Machineに与えるというものです。要はループ処理を2重ループに変更して、ループ内部処理を別State Machineに置換したような形になります。
こうすることで最大同時実行数を1000程度まで上げることができ、実用上は問題のない制限になりました。
おわりに
こうして発表させていただく機会があったので、CroisのStep Functions周りの仕組みをまとめることができました。Step Functionsを使ってワークフローを組んでいる/組みたい方の参考になれば幸いです。
あらためてまとめてみると過去に発表したところから大きなアーキテクチャの変更はないものの、ユーザビリティを上げるための改善が積み重ねできていることを実感した次第です。
明日の Recruit Advent Calender 2021 はQuramyさんです。
本記事を読んでいただき、ありがとうございました。弊社では、このような省力で運用できるシステム作りを楽しみたい方を募集しています。
===========================
===========================
興味のある方はぜひエントリーお願いします。
関連記事
- データ分析を軸に、組織や職種の壁を越えて協力し合う環境を作る ~リクルートグループ向けデータ分析プラットフォームCrois~
- Machine Learning Casual Talks #10で内製のデータ分析基盤について発表しました | Ad-Tech Lab Blog

社内横断で使われるデータ基盤プロダクトの開発リーダー
Yoshihiro MIYAI
動画サービス提供会社などを経て、データエンジニアとしてリクルートコミュニケーションズに入社。以来、データ基盤を担当しています。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


