はじめに
機械学習エンジニアの本田志温です。2020年新卒入社で、機械学習を用いたデータ施策や社内のデータ活用プラットフォームの開発を担当しています。
本日はGPUによるモデルサービングに関するちょっとした注意点について話します。というのも最近、ある施策のためにGPUによるオンライン推論を行うAPIを開発したのですが、負荷テストをしたところ、処理性能が期待していたほど出ませんでした。いろいろと調査をした結果、原因は1つのリクエストの中でデータがGPUとCPUの間を行ったり来たりしていることだとわかりました。一度わかってしまえば当たり前のことですが、GPUによるモデルサービングをするときの注意点として書き残しておきたいと思います。
GPUによるサービング
ディープなモデルの推論を高速化するためのテクニックには、精度を落とさないものでは計算グラフのコンパイル、精度を犠牲にするものでは蒸留や量子化など、いろいろあります。しかし、最も効果が大きいのはやはりGPUの利用でしょう。私が担当しているある案件も推論速度をいかに上げられるかが重要であるため、推論にGPUを利用することにしました。
API開発は、Google Kubernetes Engine(GKE)上にGPUノードプールを作成するところから始めました。 公式ドキュメント に従って、クラスタにGPUノードプールを作成し、NVIDIAドライバを自動でインストールするためのDaemonSetを入れて、taintやオートスケールの設定を行いました。
基盤の準備が整ったところで、案件で使うアプリケーションコード(主に FastAPI と PyTorch で実装)をデプロイしました。GPUでFast APIの推論コードを動かすのは初めてだったのでうまく動くか不安でしたが、PyTorchの使用デバイスを指定する部分を変えるだけで済んで楽でした。
次に、処理性能を計測するために Locust というツールを使って負荷テストを行いました。
負荷分散しているのに処理性能が低い?
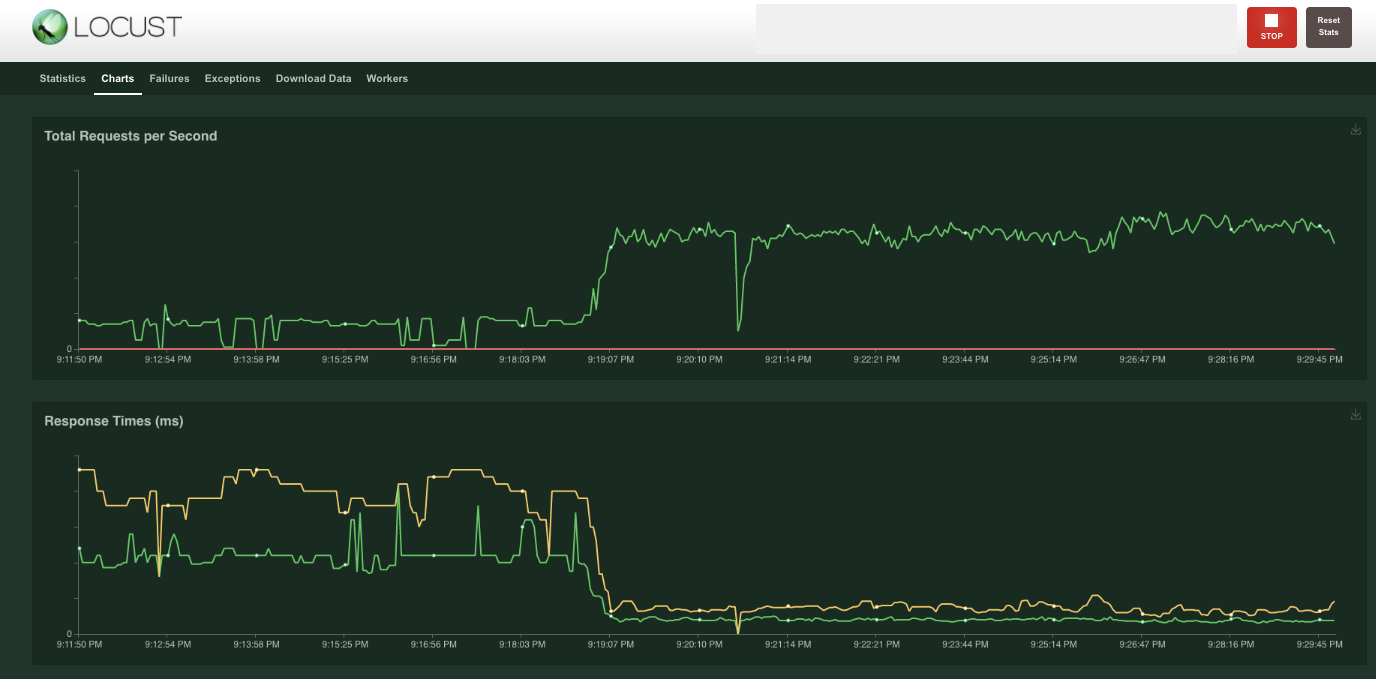
結果は奇妙なものでした。負荷を抑えてリクエストを1つずつ送ると、CPUで実行したときよりも劇的に速くなり、RPS (request per second) を増やすと、ノードが期待通りスケールアウトされました。しかし、ノードがスケールアウトしたときのレイテンシが理論値の数倍程度と、十分な性能を出せていませんでした。また、個々のリクエストのレイテンシが大きくばらついている点も気になりました(90パーセンタイル値が中央値の2.5倍)。
どこかで設定を間違えたのでしょうか?
犯人は…GPU・CPU間のデータの往復
最初は原因の見当がつかずロードバランサのアルゴリズムなど、当初あらぬ方向への疑いも持ちましたが、落ち着いてアプリケーション側のコードを見直してみると、データがGPUとCPUの間を往復している点が気になりました(そもそも、GPUとCPU間の移動ではデータのコピーが発生するため性能の低下を引き起こします)。PyTorchのTensorに対してダミーコードを示すと、次のような部分です。
x = x.cuda() # CPU -> GPU
h = MyNeuralNet1(x)
h = h.cpu() # GPU -> CPU
h = my_func(h)
h = h.cuda() # CPU -> GPU
y = MyNeuralNet2(h)
y = y.cpu() # GPU -> CPU
my_func()では、例えばMyNeuralNet1()の出力をMyNeuralNet2()の入力形式に合わせるための整形処理などを想定しています。この処理がGPUでも実行可能な場合、h = h.cpu()とh = h.cuda()の往復は冗長です。以降においても、この往復が冗長なものとして話を進めます。
このような余計な往復を削除して再度負荷テストを行うと、下図の通り、ノードのスケールアウトによってレイテンシ(Response Time)が改善しました。
余計な往復があるとなぜ遅くなるのでしょうか?先程のコードを図示してみました。
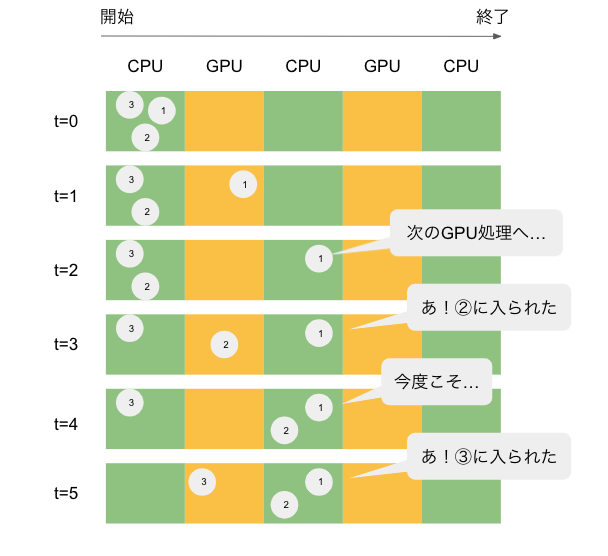
丸で表したリクエストはCPU→GPU→CPU…とパイプラインを流れていきます。CPUは1度に複数のリクエストを処理できますが、GPUは1つしかなく並列処理ができないので、オレンジの領域に入れるリクエストは1度に1つまでです。したがって、リクエスト①がGPUにあるとき、リクエスト②と③はGPUの空きを待たなければなりません(t=1)。
余計な往復があるケースでは、リクエスト①が1つ目のGPU処理から2つ目のCPU処理に移行した瞬間、GPUに空きができる(t=2,4)ので、リクエスト②や③がGPU処理に進んでしまいます(t=3,5)。こうなると、リクエスト①は2つ目のGPU処理に移りたくても、GPUの空きを待たなければなりません。
このように、N個のリクエストが互いに待ち合いをすると、1つあたりの処理時間は最大N倍になってしまいます。余計な往復がなければ、GPUを流れるリクエストは①、②、③…と順序通りになり、処理時間も1つ分で済みます。
ちなみに、このようなGPUとCPU間の余計な往復は、複数のレポジトリからモデル部分を取り出してパイプラインを作るようなときに発生しがちです。具体的には、物体検出と画像分類を順に行うパイプラインや複数の深層モデルのスタッキングなどが考えられます。
おわりに
最後までお読みいただきありがとうございました。
以上のように、GPUによるモデルサービングでは、GPU・CPU間のデータの行き来を最小限にするようにアプリケーションコードを修正する必要があります。これを怠ると、複数のリクエストを同時に処理するときにリクエスト間で待ちが発生してしまいます。また、今回と違ってどうしてもCPUを経由する処理を消すことができない場合は、処理全体をシングルスレッドにすることで解決できるかもしれません。
振り返ってみると「まずは最小限のアプリケーションコードでテストすべき」と突っ込みたくなりますが、どなたかのお役に立つことができれば幸いです。
一緒に働きませんか?
弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。

機械学習エンジニア
Shion Honda
好きな技術は深層学習、得意料理は麻婆豆腐です。
この記事をシェア

<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


