自己紹介
みなさん、はじめまして株式会社リクルートにデータスペシャリストとして新卒入社しました電電(@yosyuaomenww)と申します。 GitHubでは seven320 として活動しています。 今回は新人研修の一環として行われたPIGICONというコンペが個人的に面白かったので、このコンペについて書いていきたいと思います。
全体の流れ
新人研修とPIGICONの立ち位置
データスペシャリストとしてリクルートに入ると入社後bootcampという1ヶ月ちょっとの新人研修があります。
研修は各種の技術的なものに関する講義やコンプライアンスなども含む社会人研修など多岐にわたりますが、今回はそれら全てに触れると膨大な量になってしまいますので割愛したいと思います。一部のスライドが一般に公開されていますので、気になる方は こちら を見ていただければいいと思います。(なお自分はデータスペシャリストコースでの採用なので、研修内容についてはエンジニアコースとは一部異なる部分があります)
今回はPIGICONと呼ばれている研修を紹介します。 なお本研修はリモートで行われており、自分は自宅からslackやteamsなどを通して質問などをしていました。
また、本研修ではコンペという形はとっていますが、新人研修の締めくくりという形もあり、新卒同士でめちゃくちゃ競争をするという感じではなく、途中での知見共有やslackを使った雑談などが行われており、ワイワイしながら進行していました。
PIGICONとは?
PIGICONは社内の研修コンペで、簡単にまとめると
- Programming and Intelligence: Greatest Improvement CONtestの略です(長いですね)
- ISUCON (Webサーバ最適化コンペ) に機械学習の要素を取り入れた新しいタイプのコンペ
というもので、機械学習コンペとサーバの高速化の二つの要素を取り入れたコンペとなります。
今回のPIGICONのテーマではピギネイターと呼ばれるあるサービスをより速く正確にすることが参加者に求められました。
ピギネイターについて
ピギネイターはユーザとのやりとりを通じて、ユーザの想像するものを当てるサービスです。ピギネイターというサービス名は「 アキネイター 」というサービスからインスピレーションを受けているようです。
PIGICONでは、参加者がこのピギネイターを改善してスコアを競い合います。スコアラーが仮想ユーザとなり、サービスに対してアクセスしてきます。 より具体的に言うと、このゲームでは、ユーザはある高分子を思い浮かべて、ピギネイターにゲームスタートを知らせます。次にピギネイターはこのユーザーに対して思い浮かべた高分子の特徴(重さや分子数、生成に必要な実験タイプなど)を聞いていくことができます。 この際にピギネイターはユーザが思い浮かべている高分子の種類を推測することもできます。 つまり、質問をするか推測をするかということもピギネイターが判断します。 最終的にユーザーが思い浮かべている高分子をピギネイターが当てることができれば正解、間違えればさらに質問を繰り返していき正解にたどり着くまで回答します。
全体の流れとしては下図のような流れになります。
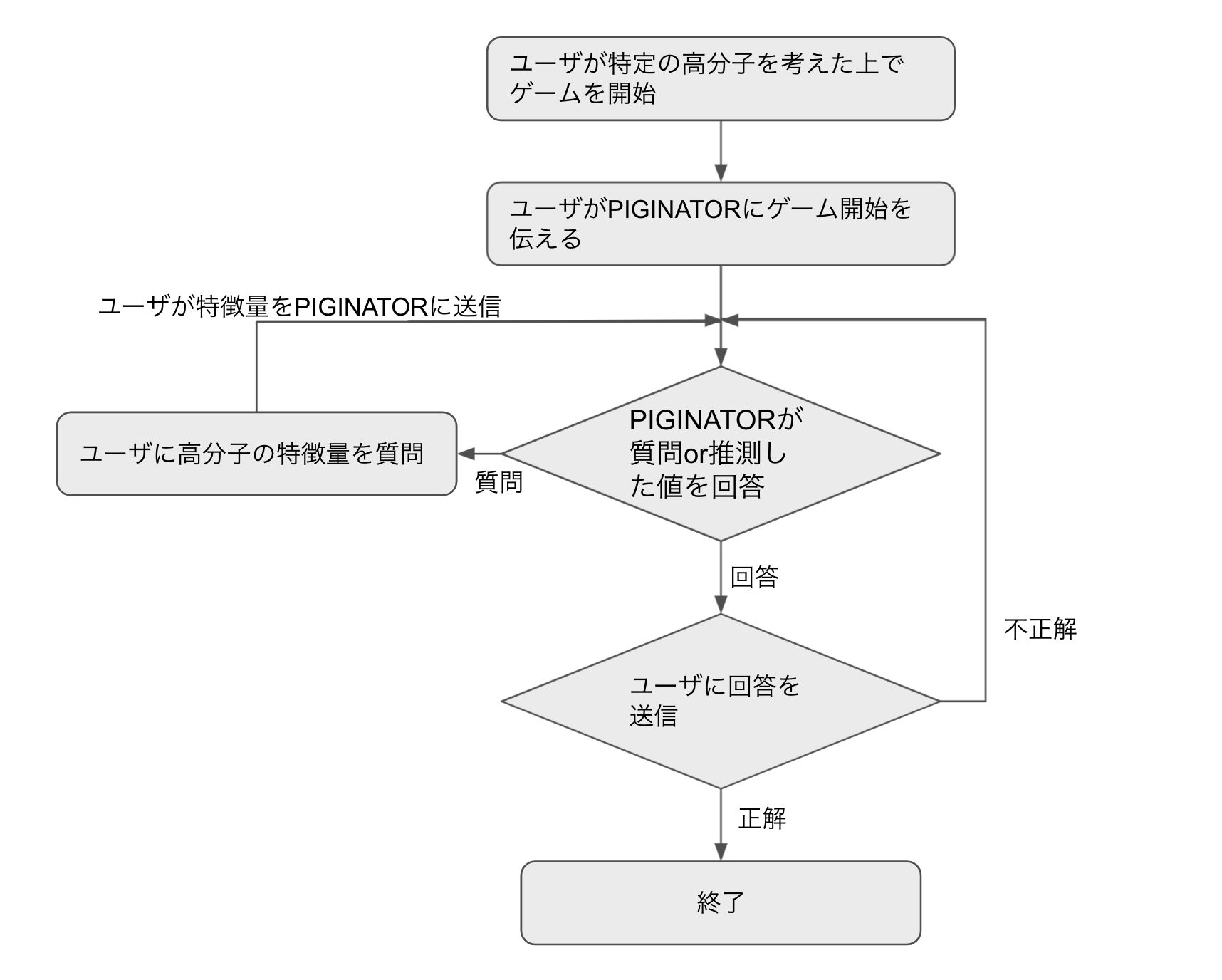
またユーザとピギネイターのやりとりは以下のように何度も行われます。

このような一連の流れが1ゲームとなります。ピギネイターはより少ない質問でより正確にユーザが予測している高分子を当てることが目的となります。
本コンテストでは、ピギネイターのサービスのAPIサーバの初期実装が与えられます。また、高分子を予測するロジック作成のための訓練データとして高分子の特徴量とラベルのペアが与えらています。参加者は、これらを元にしてピギネイター内のモデルやサーバのロジック改善を行って、モデルの精度向上や推論速度向上、APIサーバのスピードアップなどを行います。
スコアについて
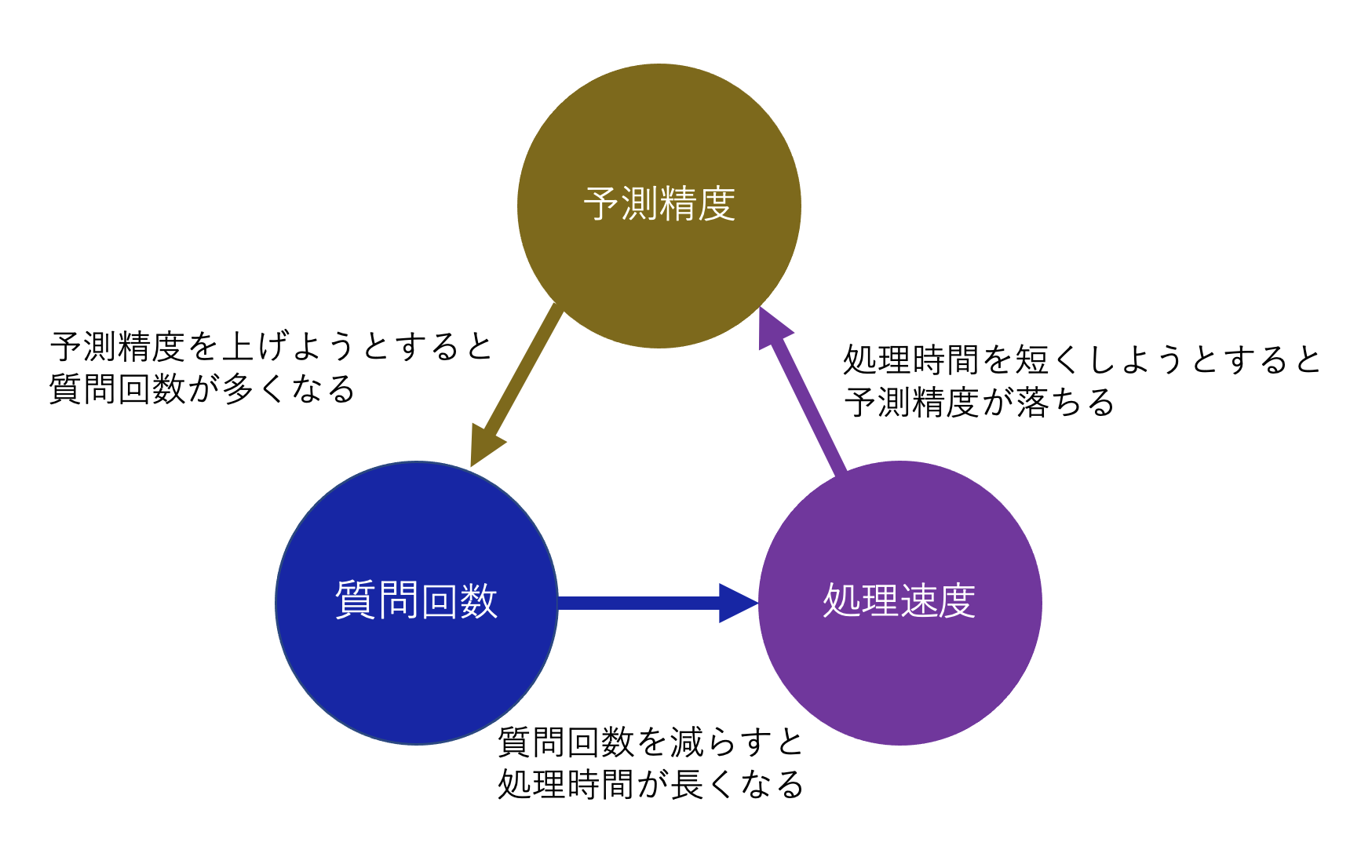
このコンペにおいて重要な指標であるAPIサーバーのスコアは
- ユーザーへの質問回数(少ないほど良い)
- 予測精度(高いほど良い)
- 予測を返すまでの処理時間(短い程よい)
の3つを考慮しており、そのスコアの大小を個人で競い合います。 (ピギネイターのスコアについてのより詳しい内容については、 こちら をご覧ください)
スコアを構成するこれら三つの要素は以下のようにさんすくみの関係となっており、
- 予測精度をあげようとすると必要な特徴量の数が増えてしまい質問回数が増加する。
- 質問回数を減らすと間違いが増えるので、結果的に推論のやりとりが多くなり処理時間が長くなる。
- 処理(推論)速度を短くしようとするとあまり複雑なモデルが使えず、予測精度が落ちる。
これらのバランスをとることが高いスコアを出すのに必要でした。
スコア計算は、各自に与えられたAWSのインスタンス環境において好きなタイミングで実行することができ、また、各自のパソコンのdocker環境でテストを行うこともできました。
リーダーボードについて
このコンペにはパブリックリーダーボード、プライベートリーダーボードが存在しており、訓練データとは別の評価用データ、テストデータによってそのスコアが計算されます。 開始時点からの各自が出したスコアが表示され、その途中経過や実行時間、精度ロスなどのスコア内訳がそれぞれわかるようになっています。
また、自分にしか見えないスコアボードもあり、その中では各種のスコア内訳が見えるようになっていました。

PIGICONの時系列、自分が取り組んだこと
1日目
まず、与えられたAPIサーバーがどのような構成になっていて、内部のモデルが何なのかを読み解いたり、スコア計算がどういう計算で行われているかを把握していました。その後、与えられたタスクに対して何ができるか、何ができそうかをgithubのkanbanで整理して、優先順位を付けました。
また、デプロイから採点を行うための流れを確認していました(初期実装スコア:40くらい)
調べたところ初期サーバーはbjoern + wsgrief + falcon で構成されていてAPI内部で使用されているモデルは決定木でした。決定木だと使えていない特徴量があったり、精度がいまいちだったこともあって、lightGBMのモデルを作成してベースラインを作っていました。(スコア: 40 -> 65) 1日目の終わり頃から、同期が結構高いスコア(80くらい)を出していてちょっとあせりました。
2日目
2日目はAPIサーバーの高速化ができないか検討していました。 まず取り組んだのはAPIサーバーの並列化です。与えられているインスタンスがcpu2個のものだったので、並列化できれば速くなるかなと思ってサーバ構成をbjoernからgunicornに変更、worker数を増やして速度改善を行いました。(スコア 65 -> 68くらい) さらにlightGBMよりもcatboostの方が推論速度がだいぶ速いという話を聞いてcatboostの実装を行いました。同期がかなり精度の高いモデルのnotebookを配布してくれたのでscoreが一気にのびました。(68 -> 90くらい)
3日目
この日実施したこととしては、質問の個数を減らしたりしてその影響を見たり、推論時にバッチ処理した方が速くなるんじゃないか、ということを検討していました。 また他にも、使用されていたjsonエンコーダーを orjson に変更することで高速化を行ったりしていました。 (スコア 90くらい -> 95くらい)
4日目
最終日です。いろいろやっていた施策についてもネタ切れ気味になりつつありました。しかしながら、与えられたデータをよく見ていた同期が「ある特定の特徴量が同一の値であるものは同一の高分子クラスを持っている可能性が高い」というのを発見し、知見として共有してくれたので、それをもとに質問の順序を変更し、特徴量と高分子クラスのペアをキャッシュに保存して利用する機能を作ることで、一部の物質については質問回数を減らしつつ、精度が上がるという結果が得られました。(スコア 96 -> 100)
また、このキャッシュを外部に保存することにより評価データの解を得ることができ、scoreの限界値を試したりしていました。 これは評価データを全てキャッシュに保存しているので、テストでは使えないですが…一瞬一位になったりしていました。
最後に細かい部分を調整したりして評価scoreは105くらいまで伸びました。 あとは最後に実施されるサーバを全て再起動してテストデータに対してスコア計算をする再起動試験でうまくいくことを願うばかりでした。
結果
そんなこんなで終了時間となり、各自最終スコアが出揃いました。
気になる最終結果は
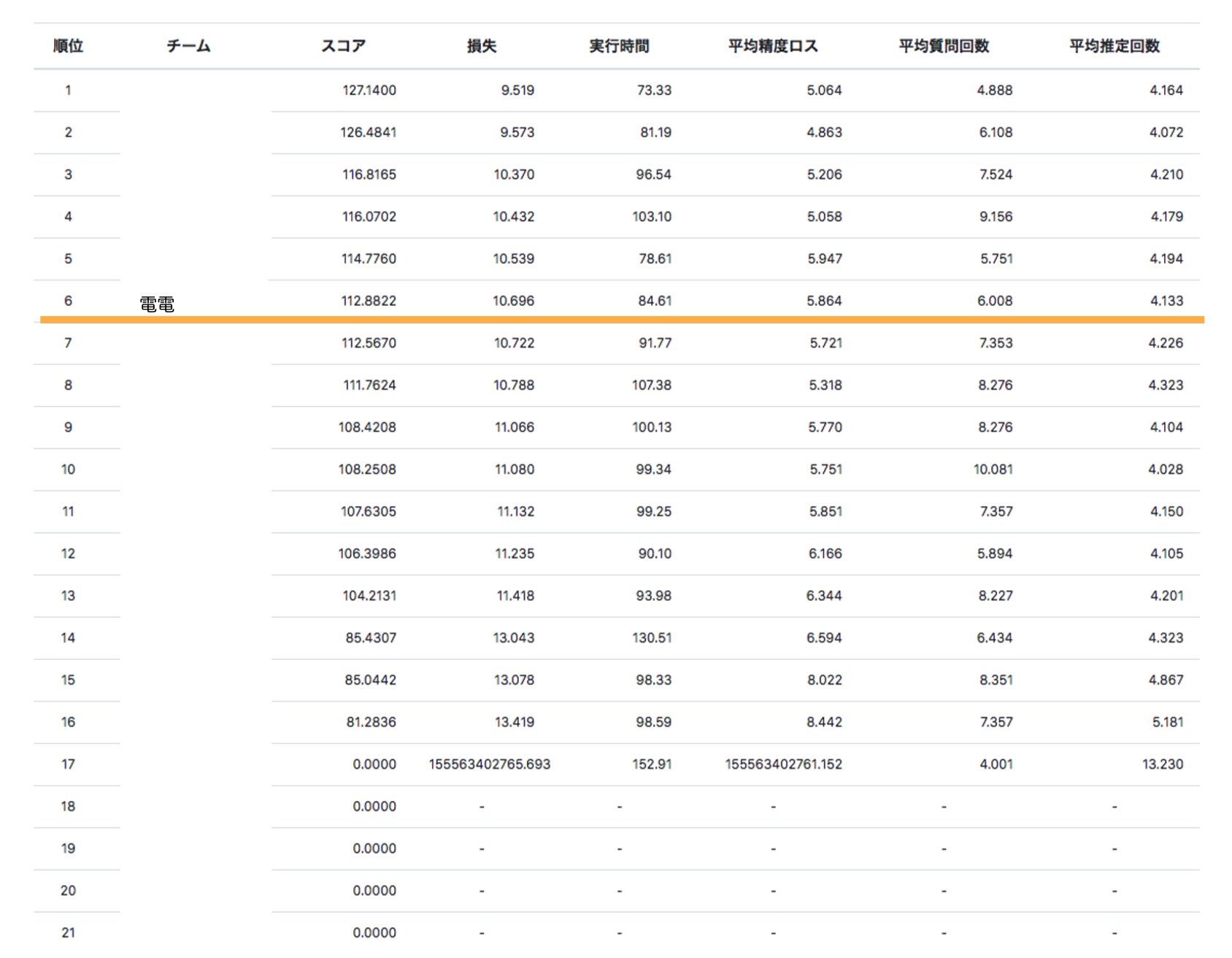
最終スコア112.9で6位でした。
一位は127.1を出していたのでもっと出せたんだな〜という印象でした。
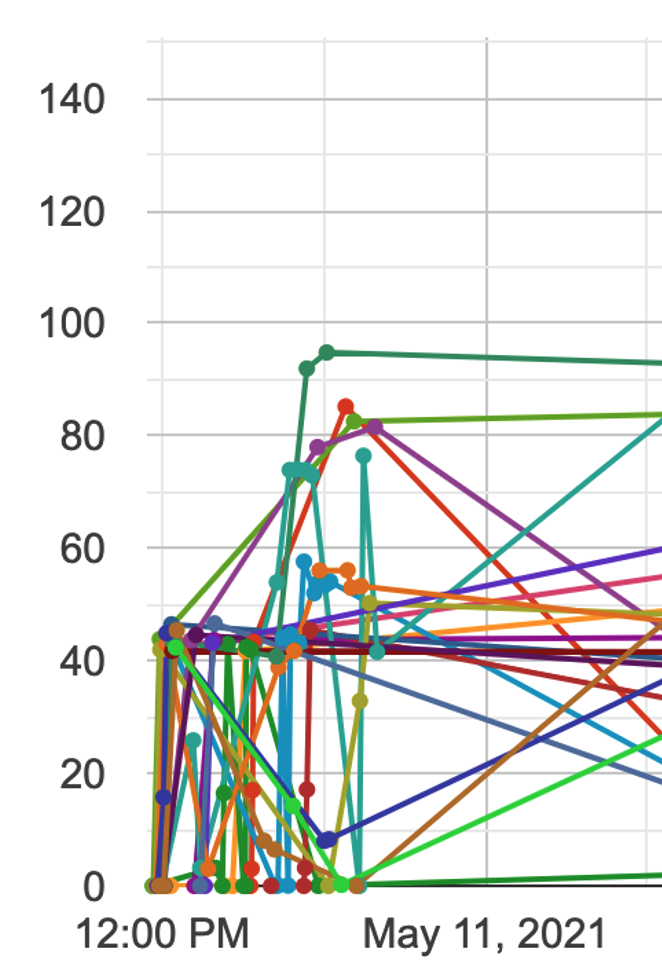
ちなみに全体のスコア推移は以下のようになっています。
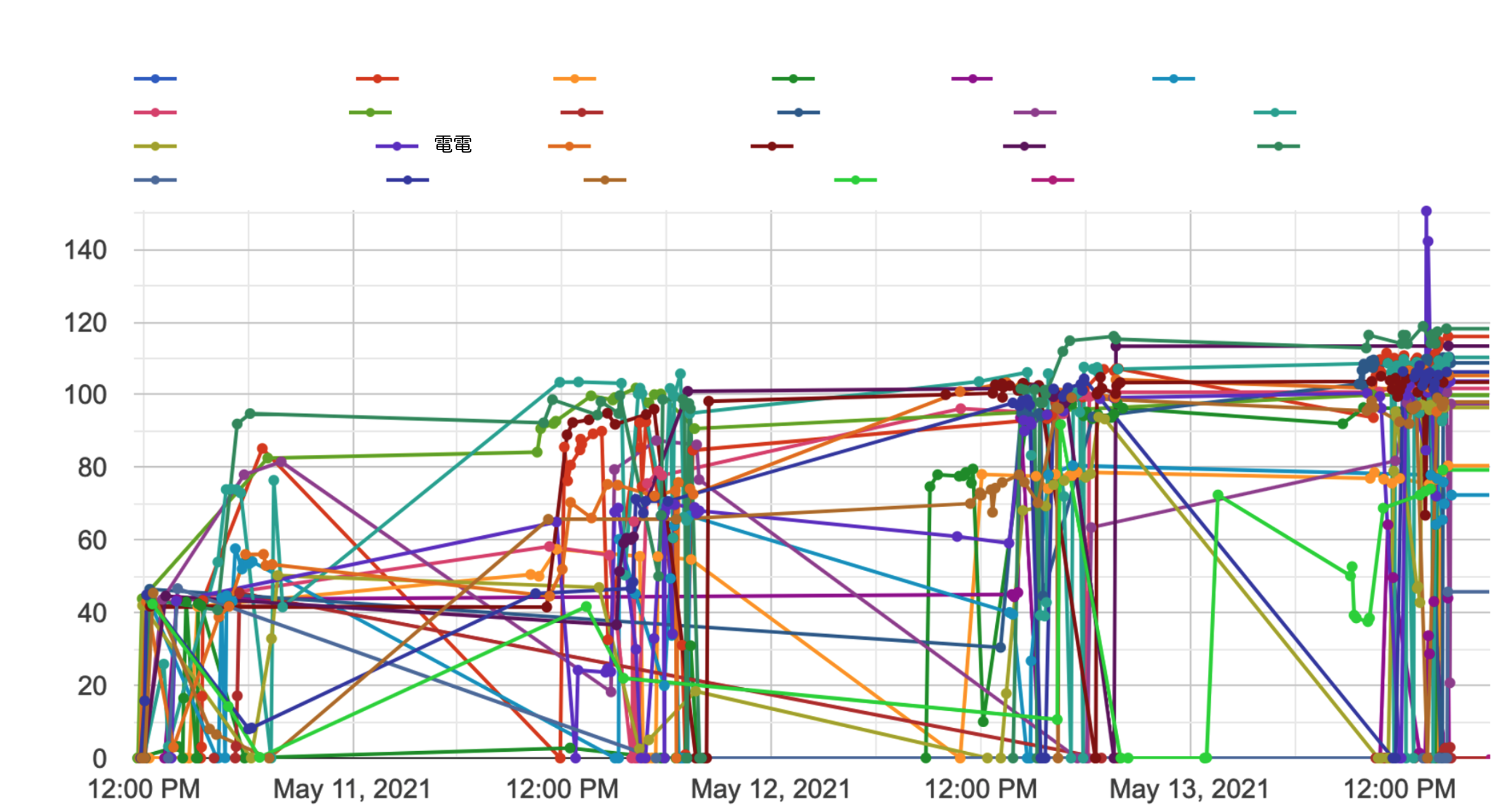
- 全体を通してみると1日目にみんなAPIの構造を抑えて改善を行っている。
- 2日目で多くの人が共有ノートブックを使って点数を伸ばしている。
- 3,4日目あたりでどんどん試行回数が増えてきて細かいチューニングを行っている
などの様子が伺えます。
振り返って
PIGICONが終わりました。振り返ってみると、反省点としては
- 全体としてプロセスの実実行時間の切り分け(どの処理にどれくらいの時間がかかっているか)などの計測部分を疎かにしてしまった
- 研修なのだからもっと技術的に尖ったことに挑戦するべきだった、具体的には後述している他の同期のように他の言語やフレームワークを使用してAPIを構築し直すなど序盤で取り掛かれる部分をやってもよかった。
などがありました。 逆によかった点としては、以前まであまり取り組めていなかった
- taskを切って取り組む
- 優先順位を持ってブレずに開発する
- 次行うタスクに必要な情報を集める
が研修を通して行え、成長が実感できました。
また、同期には
- Python3のAPI実装が与えられていたが他言語でのAPI実装を行ないスコアを出す人(Go, Rust, Cを試している人がそれぞれいました)
- 与えられた変数の値の特別性を見抜いてキャッシュをうまく使った人
- 各役割(推論、API、処理時間など)での時間をloggerで出力し、どこが遅くなっているか計測している人
- 推論を速くするために推論を高速で行えるライブラリ(ONNX)を導入する人
などをしている人がいて、特に他の言語を使って一からAPIを書いて実装を行っている同期を見てすごいところに入社したなと感じていました。 また、このように一つの指標でもいろんな面からの取り組みがあるのはPIGICONのいいところだなと思っています。
まとめ
個人的にはそこそこ良い結果が出せたのではないかなと思っています。 予測モデルを用いたAPIやそのモデルの切替に適した設計の諸々を学ぶことができましたし、何よりも自分があまり意識できていなかったタスクの切り分けや優先順位を意識できたのは大きな成長だなと感じました。 今後もエンジニアリング、データサイエンスのスキルだけではなくこのようなソフトスキルについても意識しながら、実業務に生かして行きたいと考えています。
最後に
さて、ここまで読んでいただいてありがとうございます。 このような技術研修を行っている弊社では絶賛新卒採用を行っております。
===========================
===========================
興味のある方はぜひ申し込んでみてください!!!
それではまた、電電でした。

Airペイ、AirレジなどAirプロダクトのデータ周りの整備や分析を担当
電電
新卒でリクルート入社。旅が好きで世界一周したりしていました。今の夢は南極に行くこと。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら