1. はじめに
みなさん、はじめまして。 2023 年 4 月に新卒でデータスペシャリスト1として入社した新田洸平( @KoheiShinden )・中林雄一・藤原吏生です。 入社同期で複数本投稿予定の Recruit Data Blog の第 2 回目になります。
リクルートデータ組織では、新人研修として約 2 ヶ月にわたって専門人材の育成・立ち上がりにフォーカスした研修を行なっています。 この研修を通じてデータスペシャリストとして必要なスキルとスタンスがどのようなものかを学ぶことができます。 また、研修の 8 割以上は内製されており、研修のメンターは全てデータスペシャリストの社員によって構成されています。 このデータ分析ハッカソンで使用したデータ・提出機構・採点機構・サンプルノートブックなども全て内製されています。
この記事では、新人研修の一環として行われたデータ分析ハッカソンおよびこのハッカソンを通じて得た学びについて書いていきます。 このハッカソンは 1 チーム 3〜4 人で構成され、今年は全 9 チームで臨みました。 私たちは「チーム6」として参加しました。
2. データ分析ハッカソンについて
データ分析ハッカソンで扱われたタスクとデータについて紹介します。 今回取り組んだタスクは、ユーザが検索した条件や、検索した結果表示されたアイテムの情報から、ユーザがアイテムをクリックするかどうかを予測する 2 値分類のタスクとなっています。
使用したデータは、サービスサイト内のユーザの行動履歴データ2となっており、検索が行われた時間・検索したユーザ ID・検索条件・検索の結果表示されたあるアイテムの特徴・そのアイテムをユーザがクリックしたかどうかなどの情報が含まれるテーブルデータとなっています。
| ログID | リクエスト時間 | ユーザID | 検索条件 | アイテムの特徴1 | アイテムの特徴2 | … | クリック |
|---|---|---|---|---|---|---|---|
| 1 | 2023-04-13 09:00:00 | ユーザA | 検索条件1&検索条件2 | aaa | bbb | … | 無 |
| 2 | 2023-04-13 09:00:00 | ユーザA | 検索条件1&検索条件2 | aaa | ccc | … | 有 |
| 3 | 2023-04-13 09:10:00 | ユーザB | 検索条件1&検索条件3 | ddd | bbb | … | 有 |
| … | … | … | … | … | … | … | … |
したがって、今回のハッカソンでは、ユーザの検索条件や、検索した結果表示されたアイテムの情報を特徴量として、目的変数であるクリックの有無を予測するモデルの構築を行い、その精度を競います。
今回使用するデータは、ユーザがある検索条件で検索を行なった結果表示されたアイテムのうち、ユーザが実際にクリックしたものを正例、クリックしなかったものを負例としてデータを作っています。
また、このデータの特徴として、リクエスト時間・ユーザID・検索条件が一致するログが必ず偶数個含まれており、半分が正例、半分が負例となっています。
この特徴により、ある検索条件で表示されたアイテムのうち、正例と負例になるアイテムがペアとして得られ、このペアのうち、ユーザはどちらのアイテムをクリックするかという二値分類をペアごとに予測するというモデリング方法も可能になります。
データ設計の背景についてはこちらの記事で詳しく説明されています:
【連載:Recruit 機械学習コンテスト】②コンテストデータ作成について
ハッカソンに取り組むに際し、分析環境・サンプルノートブック・リーダーボードが提供されました。
分析環境としては、Vertex AI 上で動く Jupyter Notebook3 が与えられました。 この Notebook 上でデータの分析やモデルの構築を行います。
サンプルノートブックとしては、データの分析方法や特徴量エンジニアリングのためのヒント が記された EDA(Exploratory Data Analysis、探索的データ分析)のノートブックと、特徴量作成・モデルの学習・モデルの評価・スコアの提出が行えるベースラインのノートブックが配布されました。EDA とは、データセットを分析し可視化することでデータの傾向や異常値などを観測して特性を理解することです。
サンプルノートブック作成についてはこちらの記事で詳しく説明されています:
【連載:Recruit 機械学習コンテスト】⑤サンプルノートブックについて
リーダーボードは、パブリックリーダーボードとプライベートリーダボードが用意されており、学習データとは別の評価用データ、テストデータによってそのスコアが計算されます。 パブリックリーダーボードは公開されており、各チームが提出したスコアをリアルタイムで確認することができます。 コンペティション終了時にプライベートリーダーボードが公開され、最終的なテストデータでの精度を競います。
3. 取り組みの概要・時系列
1 日目
初日にまず、研修全体の動きとして、講師の方々からタスクやデータ、評価方法や提出方法などについての説明がありました。その後、各チームに分かれて開発を進めていきました。
私たちのチームでは、全員がタスクやデータを理解して提出作業に慣れるために、配布されたテーブル定義やベースラインモデルに目を通し、ベースラインモデルを使った予測を行い予測結果をリーダーボードに提出するところまでを一通り実行しました。(担当者:自チーム全員)
この時点ではどのように開発を進めるかをしっかりと決めきれておらず、とりあえずテーブル定義や実際にユーザが見る画面を眺めながら追加できそうな特徴量をみんなで考えていました。
「アイテム選びにおいて重要な情報がベースラインモデルでは使われていない」ということがわかったため、該当する情報を特徴量として追加することにしました(担当者:藤原・中林)。 また、自然言語カラムの活用方法を検討したり、ベースモデルを LightGBM から CatBoost、XGBoost に変更するなどといった変更を並行して進めました。(担当者:新田) 我々のチームでは最終的に LightGBM が最良の結果を示しました。(CatBoost をうまく使うことで点数を伸ばせたチームもあったことが最終発表でわかりました。)
2 日目
1 日目に行き当たりばったりの分析をしてしまった反省を活かして、今日取り組むタスクについてアイデアを出したり、優先度をつけたりする話し合いから始めました。(担当者:自チーム全員)
話し合いの結果、まず EDA をした上で特徴量を新しく作ることになりました。 具体的には、順位尺度のある変数の扱いを変更する、アイテム詳細情報の処理方法を検討する、その他 3 つ程度の特徴量を新たに追加するなどのアイデアが出ました。 このうち、アイテム詳細情報の扱いは複雑なように見えたため、それ以外のアイデアに対する実装を 3 人で分担して、並列的に進めました。 順序尺度についてはスコアに寄与しませんでしたが、その他のアイデアによってスコアが少しだけ改善しました。(担当者:自チーム全員)
3 日目
3 日目開始時点で、1 位と大きく差があるものの 2 位についていたため、比較的リラックスしながら目の前の作業を淡々と進めていました。 アイテム詳細情報の特徴量追加(新田)、時系列に基づき train/validation 分割をする(藤原)、ハイパーパラメーター探索・特徴量の追加(中林)のように分業しつつ進めました。 この中では特にアイテム詳細情報の追加はかなり効果が高く、大きくスコアが向上しました。
アイテム詳細情報には、ユニークな属性が多量に存在することが分かりました。 単純に One-hot Encoding を行なってしまうと非常に次元数の多いベクトルとなり、提供された計算環境ではメモリ容量が不足してしまうことがわかったため、一旦出現頻度が高い特徴量から順に 20 個だけをピックアップしました。 徐々に増やしていく中で、100 個の特徴量を使ってもメモリが落ちないということがわかったため、目的変数との相関係数の絶対値が大きい順に特徴量を 100 個選択し、One-hot Encoding を行うことでさらにスコアが伸びました。 (最終的には、ノートブックでファイルを複数実行していたためにメモリを消費していて、1つのノートブックでは全部の特徴量を使っても落ちないということがわかりました…)
4 日目
いよいよ最終日です。研修全体の動きとして、最終日には全チームが最終発表を行うため、発表スライドを作成する必要があり、作業時間があまりない状態でした。
この時点では手持ちのアイデアもそろそろ少なくなってきていたため、全員でアイデアを捻り出し、ユーザ視点に立ち返るなどして使用する特徴量を検討したり、現状の特徴量を再度分析したりとできる限りのことをしました。 しかし、最終日の施策はどれもスコア向上には寄与せず悔しい最終日となってしまいました。
4. 結果
さて、それではいよいよ気になる最終結果です。 以下の図 1 が最終的な各チームのパブリックスコア、2 がプライベートスコアです:
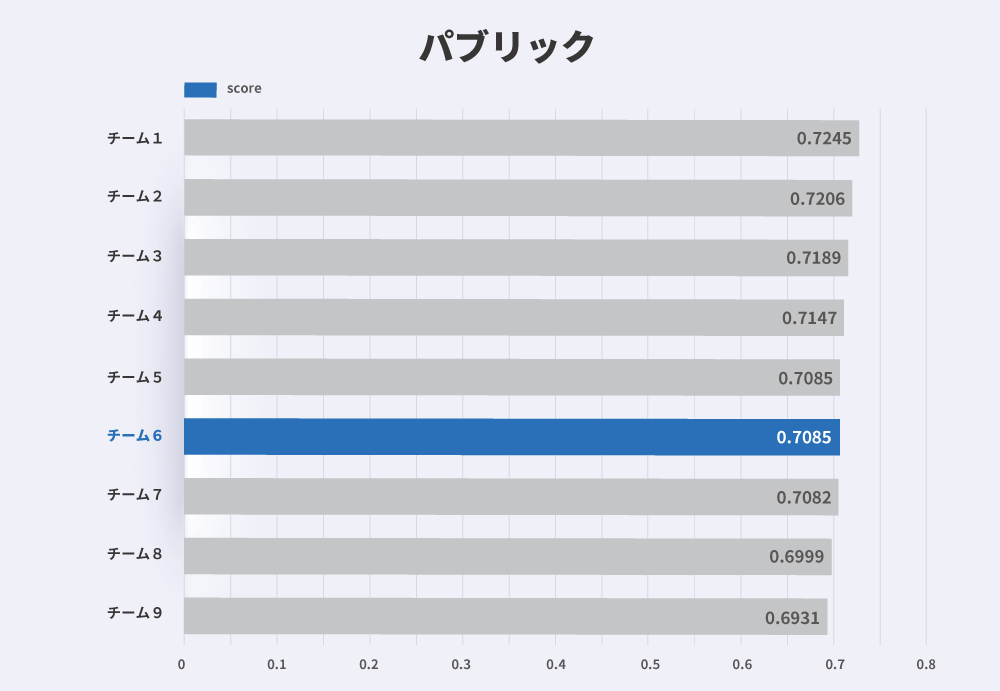
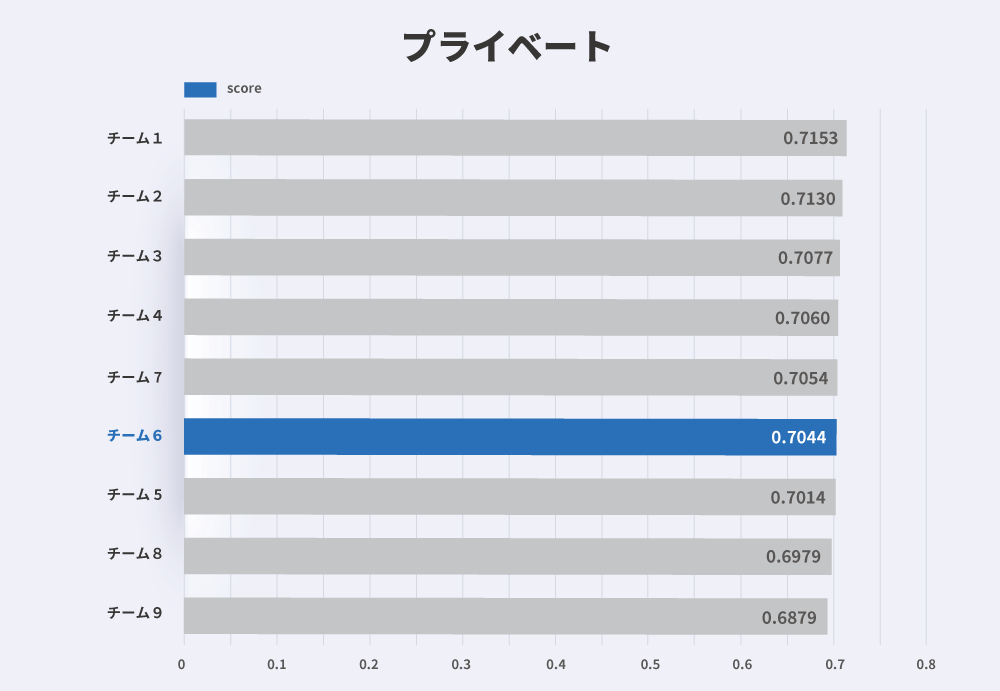
我々のチームである「チーム6」は 6 位という結果になり、最終的なスコアはパブリックで 0.7085、プライベートで 0.7044 です。 1 位のチームである「チーム1」は、パブリックは 0.7245、プライベートで 0.7153 となっています。
次に、以下の図 3 はチームごとのパブリックスコアの推移です:
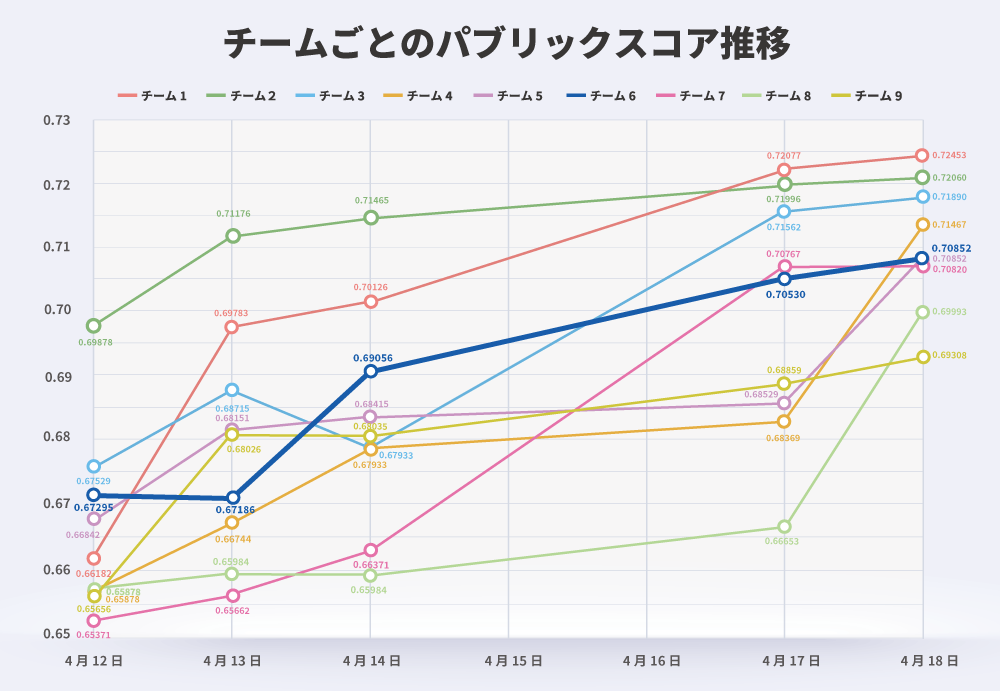
我々のチームは 3 日目に大きな伸びを見せましたが、それ以降は伸び悩み停滞する形となりました。 1 位となったチーム1は徐々に着実にスコアを伸ばしており、後述しますが綿密なタスクとスケジュール管理が功を奏したようです。
5. 学び
それでは最後に、データ分析ハッカソン研修を通じて得た学びについて「データ分析」と「協働」の 2 つの観点からの学びについて共有します。
データ分析の学び
まず、データ分析の学びについて、ここでは特に重要だと感じた「EDA」「特徴量エンジニアリング」「仮説検証サイクル」の 3 つの要素について共有します。
EDA の重要性
データ分析の観点から得た 1 つ目の学びとして、EDA の重要性が挙げられます。
EDA により、特徴量やモデルの改善につなげられる洞察を得られ、精度改善のための仮説を立てられるようになります。 また逆に、ビジネス的な観点からの仮説をEDAによって検証することもできます。 実際に我々のチームでも序盤は直感で特徴量を追加していましたが、EDA により目的変数と特徴量の相関などを確認でき効果的な精度改善を行えました。
特徴量エンジニアリングの重要性
2 つ目の学びとして、特徴量エンジニアリングの重要性が挙げられます。
ユーザ行動予測の精度改善において機械学習による予測モデルはもちろんですが、それ以前にユーザの特徴量をうまく作成することが非常に重要です。 特徴量をうまく作成するためには、ビジネスを理解しユーザ視点に立ってEDAを行うことも重要となってきます。 実際、ユーザ視点に立って考えることで、特定の項目がアイテムを探す際に重要であると気づき追加したところ、大きな精度改善につながりました。
仮説検証サイクルの重要性
3 つ目の学びとして、仮説検証サイクルの重要性が挙げられます。
モデルの精度改善では仮説検証サイクルを回すことが重要です。 EDAや特徴量モデリングを行う際に、思いついたアイデアに対して闇雲に取り組むよりも仮説を持って取り組むことでより効果的な改善につながります。 例えば、サービスサイトの利用者視点に立つと「アイテムを比較する際に詳細情報は必ず確認する」という行動が仮説として考えられ、特徴量として追加することで実際に大きく予測精度が向上する結果を得られるといった取り組みが挙げられます。
研修中は、このサイクルを多く回せていなかったため、自身の課題の一つと感じ、配属後の業務で伸ばしたいと思いました。
協働の学び
次に、協働の学びについて、ここでは特に重要だと感じた「チームワークとタスク管理」「メンターやチームメンバーとのコミュニケーション」の 2 つの要素について共有します。
チームワークとタスク管理
協働の観点から得た学びの 1 つとして、チームワークとタスク管理の重要性が挙げられます。
今回は全てのチームが 3〜4 人で構成されていました。 4日間という時間の中で、チームメンバーの動きと取り組むタスクの優先順位が効率的に改善に取り組んでいく上でのキーポイントでした。 実際に 1 位のチームは、スプレッドシートでタスクの進捗状況を管理してメンバー全員が効率的に改善に取り組んでおり、その徹底ぶりには圧巻されました。 また、機械学習コンペに関する記事を複数参考にすることで多くのアイデアを取り込み、それらのほぼ全てを実行していました。 出たアイデアを全てやり切る重要性を感じました。 特に、我々のチームとの違いとして、モデルは CatBoost を使用する、特徴量としてデータセットに含まれない外部データを追加する、数値データの四則演算などにより特徴量を増やす(合計で 300 個程度の特徴量)、疑似ラベル(Pseudo-Label)をつけたデータで学習を工夫するなどがありました。(本当に同じ時間で取り組んでいたとは思えない程のタスク量です)
チームメンバーやメンターとのコミュニケーション
2 つ目の学びとして、チームメンバーやメンターとのコミュニケーションの重要性が挙げられます。
前述の通り今回のハッカソンでは複数名のチーム制となっており、うまく連携を図ることでより大きな相乗効果を発揮することもできます。 連携を図るためにはメンバー間でよくコミュニケーションを行うことが重要です。 会話をすることで同じ課題を持っていることに気付いたり、1 人の視点では考えつかなかった課題に気付いたりできます。 オンラインとオフラインを自由に選べる中で、各チームで工夫して積極的なコミュニケーションに取り組んでいました。
また、メンターを頼ることも非常に重要です。仮説検証の方向性について意見をもらうことで良し悪しを確認したり、開発で詰まったポイントについて相談することで自分ではできないことが解決したりと良い事づくめです。 これは今後の業務においても言えることで、報連相の重要性について学ぶことができました。
6. まとめ
今回の記事では、新人研修の一環として行われたデータ分析ハッカソンの取り組みの様子とハッカソンを通じて得た学びについて書きました。 研修を通して、業務に近い実践的な技術的スキルや協働などの社会人としてのスキルを体験し、そこから今後の業務において重要な学びを得ることができました。 うまくいった工夫や反省点を今後の業務につなげて活かしていきたいです。
また、今回取り組んだハッカソンは、タスク設計やデータセット作成、提出・採点システムまでが完全に内製されていることに驚きました。 メンターである先輩社員の皆さんの技術力の高さに圧倒されると同時に、やりごたえがあり非常に学びの多い面白い研修を用意していただいたことはありがたい限りです。 圧倒的感謝!!
次回は Recruit Data Blog の第 3 回目 GCP ハッカソンについてです。お楽しみに!
7. 最後に
ここまで読んでいただきありがとうございます。 このような技術研修を行っている当社では新卒採用を行っています。 ご興味のある方は、以下の採用ページをご覧ください。
====================
====================
-
データスペシャリストとは:リクルートが保有する膨大なデータを扱い、プロダクトを改善するための施策立案〜推進、新たな機能の拡充・開発、中長期を見据えた事業戦略の提案など、幅広い領域において新たな価値の創造に貢献します。(参考: データスペシャリストコース(データサイエンティスト・機械学習・アルゴリズム)|新卒採用2024年卒|株式会社リクルート ) ↩︎
-
行動履歴データは、ユーザを特定の個人に識別不可能な状態に処理されています。 ↩︎
-
計算リソースは 8vCPUs 30GBMemory T4GPU となっています。 ↩︎

検索エンジニア
新田 洸平(しんでん こうへい)
23 年新卒でリクルート入社。検索エンジニアリング 2 グループ所属。情報検索大好き人間です。

HR領域プロダクトのリコメンド改善を担当
中林 雄一(なかばやし ゆういち)
23 年新卒でリクルートに入社。旅行が好きで、今年 3 月はインドに行きました。

データスペシャリスト
藤原 吏生(ふじはら りき)
23 年新卒でリクルートに入社。住まい賃貸 DSG 所属。趣味はボードゲーム。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら