
はじめに
この記事では、2021年10月に社内で開催したMLコンテストの利用データ準備に関する話をします。
本コンテストは検索並び順の改善を目的としたもので、サイト内の行動履歴データを元に、どのアイテムがユーザーにとって興味のあるアイテムなのか予測するタスクを解きオフライン評価指標のスコアを競う、というものでした。
サイト内の行動履歴データは社内のDWH(データウェアハウス)に日々蓄積されているのですが、私たちは行動履歴データを加工し、コンテストで利用する学習データ、テストデータ用のテーブルを作成する裏方業務を行いました。
本記事では、「どのようなコンテスト用データを作成したのか」「コンテスト用データを作成する上で注意した点」の2つについて紹介させていただきます。 要点は以下になります。
-
「どのようなコンテスト用データを作成したのか」
- コンテストで得られた知見を施策に生かすため、サービスの行動履歴データを元に社内利用可能なコンテスト用データを作成
- 行動履歴データを元にランキングシステム用の学習データを作成すると、Position biasの影響を受ける
- Position biasの影響を緩和するために、データのサンプリング方法を工夫
-
「コンテスト用データを作成する上で注意した点」
- コードレビューしやすいSQLクエリを開発するために、Jinja Templateを利用
どのようなコンテスト用データを作成したのか
コンテストの背景
今回のコンテストでは、ユーザーが検索した条件や、その条件で検索した結果表示されたアイテムの情報からそのアイテムがユーザーにとって興味のあるアイテムなのか、興味のないアイテムなのかを予測する2値分類のタスクを設計しました。
このタスクを選定した理由の1つとして、私たちの所属している部署では機械学習を用いて検索並び順の改善施策を行っており、今回のコンテストで得た知見を施策に活かしたいという思いがありました。
そのため、コンテストで使用する学習データ/テストデータの作成には、サービスサイト内の行動履歴データを利用しました。
行動履歴データには、ユーザーがどういう検索条件で検索を行ったのか、その結果どういうアイテムがどういう順番で表示されたのか、またそのアイテムに対して行ったアクション(閲覧や資料請求)などがアクセス時間と共に記録されています。
| ログID | ユーザーID | リクエスト時間 | アクション | パラメータ |
|---|---|---|---|---|
| 1 | ユーザーA | 2022-01-01 09:00:00 | 検索 | 検索条件1&検索条件2&アイテム1&アイテム2&アイテム3 |
| 2 | ユーザーA | 2022-01-01 09:01:00 | 閲覧 | アイテム1 |
| 3 | ユーザーA | 2022-01-01 09:02:00 | 資料請求 | アイテム1 |
| … | … | … | … | … |
ランキングシステムのモデル学習の課題
ユーザーのアイテムに対する興味度合いを推定するモデルを作成する上で、ユーザー自身がアイテムごとに興味のありなしを明示的に評価したデータ(以降ではこのようなデータのことをExplicit feedback dataと呼びます)があり、それを目的変数に使用できれば一番良いのですが、行動履歴データにはあくまでユーザーのサイト内での行動が記録されているだけで、趣味嗜好まで記録されているわけではありません。
そこで今回は、行動履歴データ上に記録されている、ユーザーが何らかのアクション(閲覧や資料請求)を行ったアイテムを、ユーザーが興味を持ったアイテムだと仮定し、正例とする。反対にユーザーのアクションがなかったアイテムをユーザーが興味を持たなかったアイテムと仮定し、負例とすることで学習データ/テストデータの作成を行いました(以降ではこのような仮定を置いて作成したデータのことをImplicit feedback dataと呼びます)。
Implicit feedback dataを学習データ/テストデータとして用いる場合は、Position biasを考慮する必要があります。 Position biasとは「アイテムの表示位置によって、ユーザーの嗜好とアクションの間に発生する乖離」のことを指します。 具体的には下記の図のようなケースで発生します。
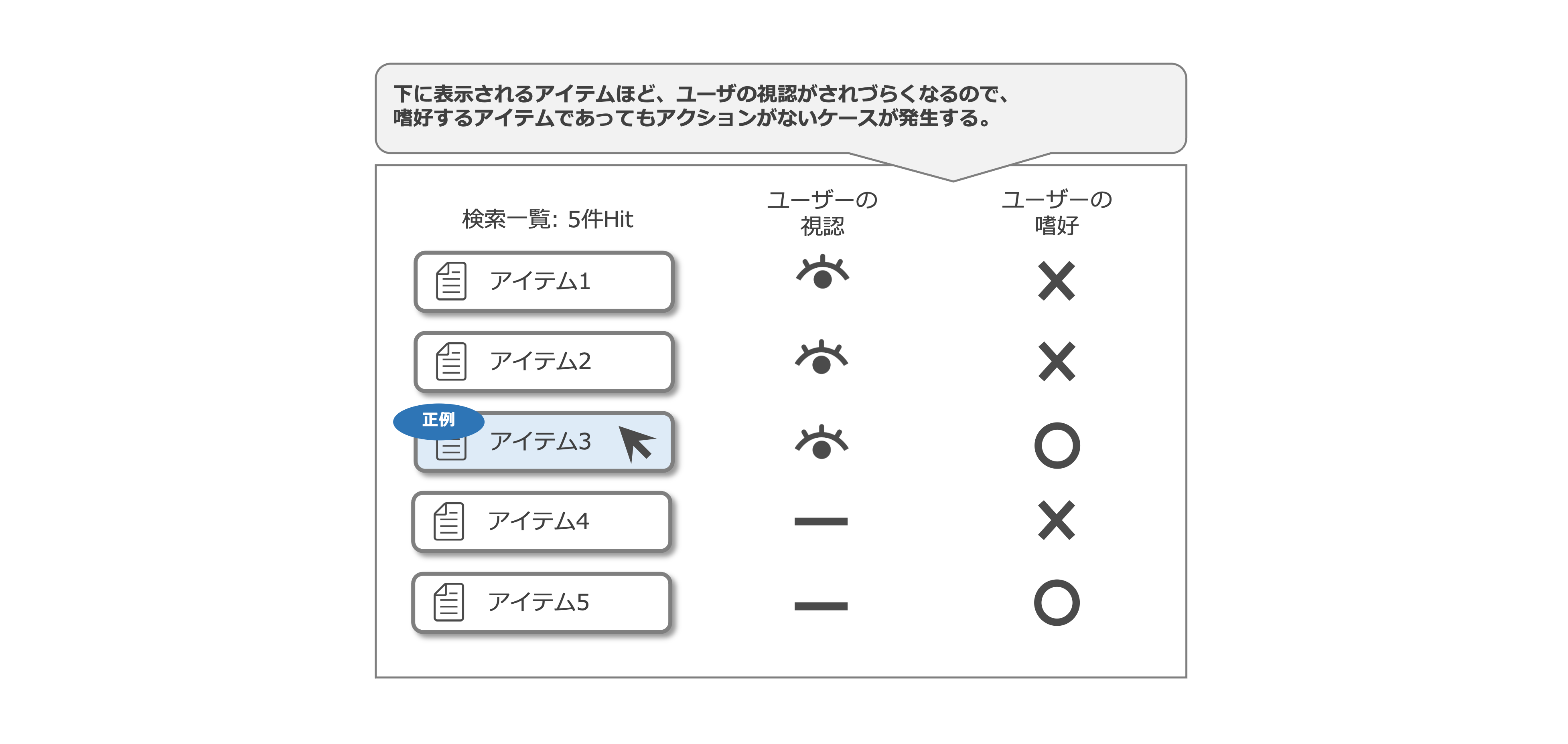
例えば、5つのアイテムをユーザーに提示した際に、上から3つ目のアイテムにユーザーがアクションしたとします。 この時、ユーザーは3つ目のアイテムに対してアクションを行なったので、それよりも上位に表示したアイテム1、アイテム2はユーザーに視認されていると仮定を置くことは容易ですが、アイテム3よりも下に表示したアイテムに関しては、ユーザーが実際に視認したのかはわからず、アイテム4、アイテム5には「本当に興味がなかったためアクションをしなかったもの」と「興味はあったが、視認できなかったためアクションできなかったもの」の2つが混じることになります。
このPosition biasを考慮せずに、ユーザーのアクションのみで正例/負例の割り振りを行うと、学習データ/テストデータにユーザーの嗜好がうまく反映されず、真に予測したい事象から外れた予測を行うモデルができてしまいます。
バイアスを考慮した機械学習用データの設計
Position biasを考慮したモデルの精度評価に関する先行研究は多々存在しますが、今回は様々な人が参加するコンテストということで、シンプルなタスクに落とし込みたいという思いがありました。
そこで今回は精度評価指標の部分でPosition biasを考慮するのではなく、データセットの作成方法を工夫することにより、Position biasの影響を緩和するアプローチを取りました(注意していただきたいのは、今回とったアプローチはあくまでPosition biasの影響を緩和するというだけで、影響を取り除けているわけではありません)。
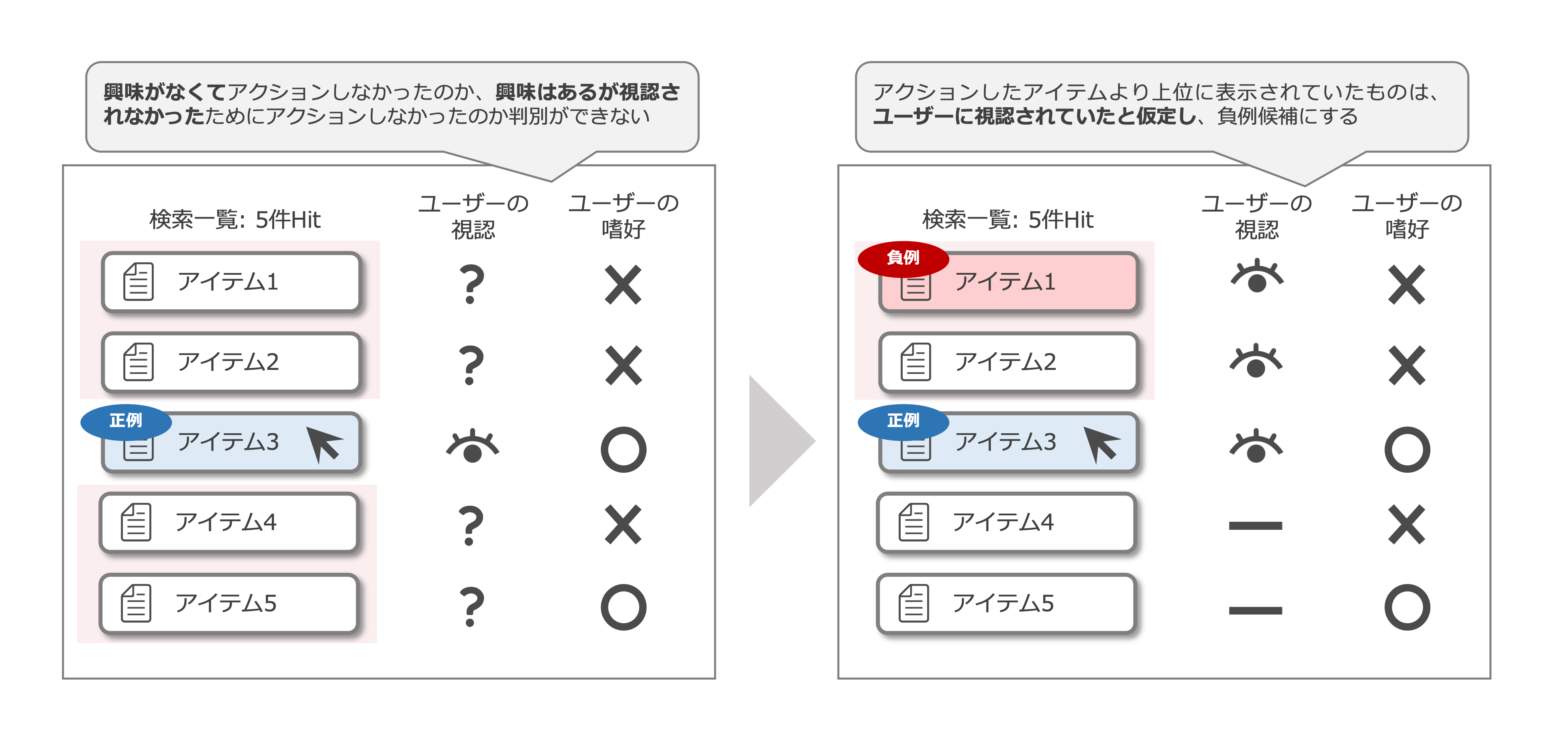
具体的には、ユーザーがアクションしたアイテムより上位に表示されていたものは、ユーザーの目に留まっているという仮定をおき、「アクションしたアイテムより上位に表示され、かつアクションが発生しなかったアイテム」を負例のデータ(=ユーザーが興味を示さなかったであろうアイテム)として選定、アクションされたアイテムより下に表示されていたものは学習データ/テストデータに含めないというアプローチを取りました。
アクションされなかったアイテムを全て負例せず、一部を抽出することで、「本当は興味があるが、視認できなかったためにアクションできなかった」アイテムを負例として採用するリスクを減らすことができます。
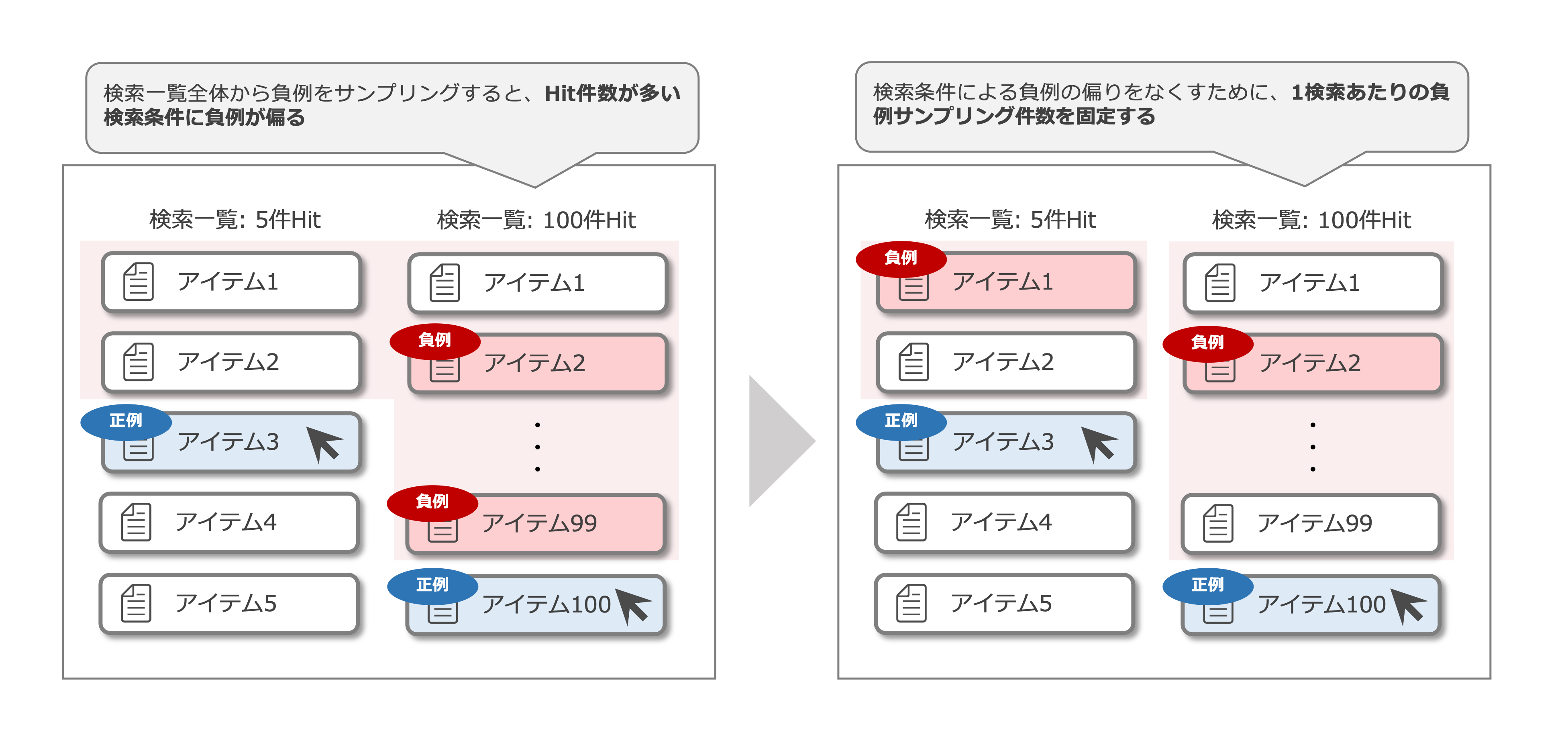
また、事前集計した際に、正例(=ユーザーがアクションを行ったアイテム)は、検索条件にヒットするアイテム数にかかわらず高々1,2アイテムであるが、負例候補はその数百倍のデータがあることがわかっていました。
そこで、負例に関してはサンプリングを行ったのですが、ここでもサンプリング方法に制約を加えました。 なぜなら、「アクションを起こしたアイテムより上位に表示され、かつアクションが発生しなかったアイテム」という条件のみで負例をサンプリングすると、検索条件にヒットするアイテム数が多い検索結果の方がより多くの負例がサンプリングされることになるからです。このように負例を作成し、ユーザーが設定した検索条件を特徴量として正例/負例を分類するモデルを作成すると、設定された検索条件が少ない(=より多くのアイテムがヒットする検索)方が負例に、設定された検索条件が多い(=ヒットするアイテムが少ない検索)方を正例に予測するモデルができます。
実際に作成したモデルを用いて、検索並び順の改善を行う際は、同一の検索条件にマッチしたアイテム集合の中でスコアリングを実施し、ユーザーが興味を持っていると予測されたアイテムをより上位に表示することになるので、設定された検索条件数を元にユーザーが興味を持っているか否かを判断するモデルだと、オンラインとオフラインでの評価スコアの差が大きいモデルができてしまうリスクが存在しました。
この課題に対応するために、今回は負例のサンプリング方法に制約を設けました。
具体的には、負例の数が検索条件にヒットするアイテム数に依存しないように、検索条件にヒットするアイテム数の多寡に関わらず、1つの検索条件から同数の負例をサンプリングするようにしました。
これにより、設定された検索条件数に依存しないモデルを作成することができるデータセットの作成を行いました。
以上のように作成した正例/負例のラベリングを行ったアイテムのデータに対して、アイテムを検索したときの条件やそのアイテム自体の情報を付与して、コンテスト用の学習データ/テストデータの作成を行いました。
データを作成する上で注意した点
今回データの作成を行う上で、コンテストの公平性を保つために、作成するデータの「正確性」を重視しました。
正確な(=バグのない)データを作成するために、開発中の動作チェックや、データ作成後のテストはもちろん、作成したSQLクエリのコードレビューも複数人で行いました。
SQLクエリを作成する上で、コード量が多くなると、開発自体しにくくなるのはもちろん、レビュワーにとっても可読しづらく、バグを見過ごしてしまうリスクが存在しました。
そこでコード量を少なくするために、Pythonの Jinja Template を利用して、動的にSQLクエリを作成するようにしました。
JinjaはPython用のテンプレートエンジンであり、pypi経由でのインストールで利用が可能です。
本記事では具体的な使い方については触れませんが、以下ではどのように利用したか紹介します。
日付の変数化
今回のコンテストでは、異なる期間のログデータを用いて、学習データとテストデータを作成する設計としました(オンラインで利用する場合と同様の状態に近づけるため)。
この場合、学習用データとテストデータは基本的には同じカラム構成になるため、対象日付以外の処理が共通の2つのSQLクエリを作成する必要が発生します。
Jinja Templateでは変数を設定でき、生成時に引数として渡すことで、動的に値を変更することができます。
今回は、日付指定の部分を変数化することで1つのテンプレートで学習用データ/テスト用データを作成するためのクエリを生成するようにしました。

出力カラムの操作
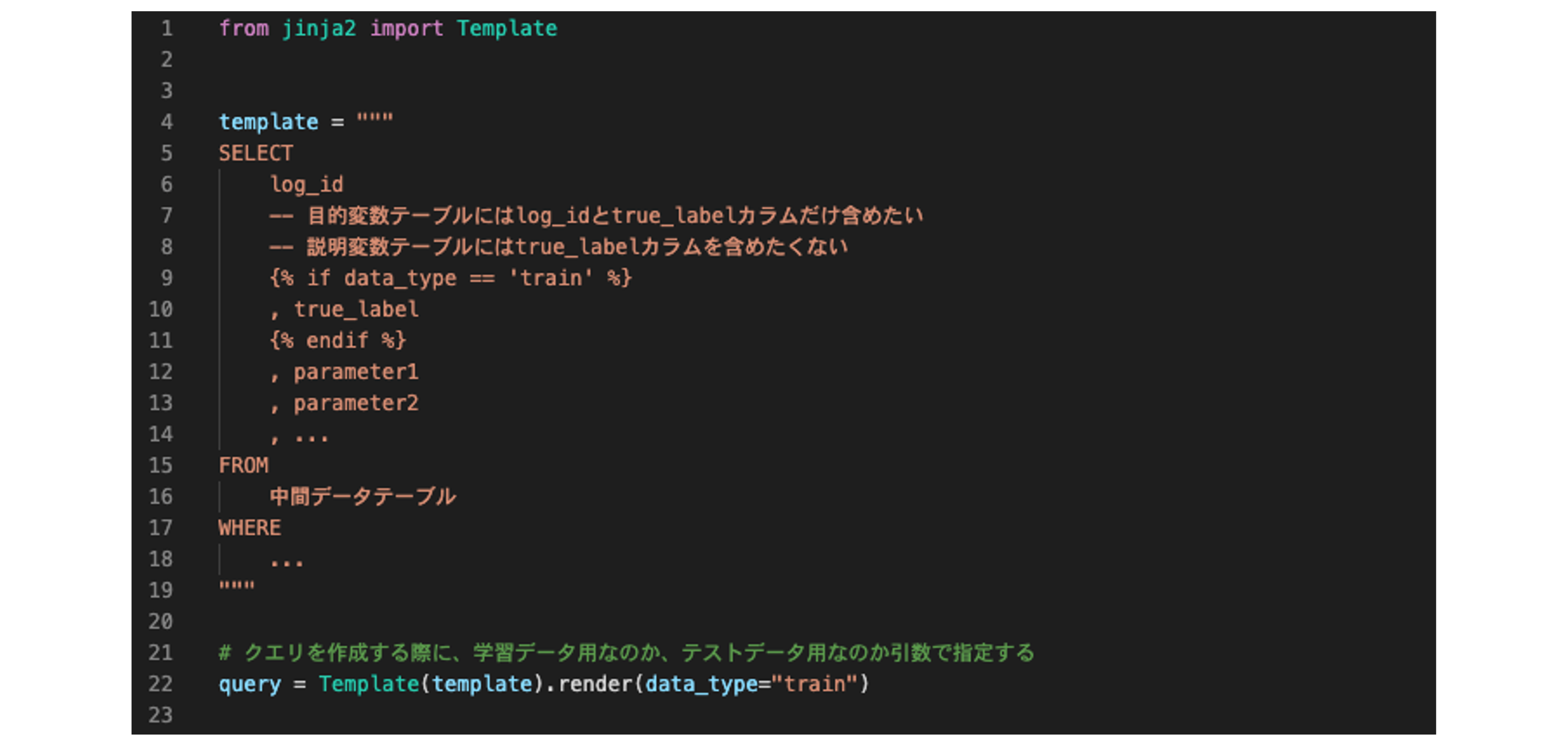
今回のコンテストでは、テストデータの説明変数を参加者が参照可能なテーブルに保持し、参加者はそのテストデータに対してスコアリングを実施し、事務局に提出、事務局側で正解のラベルと突き合わせて採点を行うという形式を取りました。
このため、参加者に公開するテストデータに関しては、説明変数だけを保持している必要がありました。
一方で、学習データに関しては参加者側でモデルを構築するために説明変数と目的変数両方とも保持している必要があります。
ここでも、学習データとテストデータで中の処理はほとんど同じなのに、最終出力カラムが異なるために、複数のSQLクエリを作成しなければならないという課題が発生しました。
これも上述の変数化の話と同様に、Template内でIF文を定義し、SQLを生成する際に引数として目的変数を加えるか否かを制御することで、1つのテンプレートで学習用データ、テスト用のデータの両方を生成できるようにしました。
繰り返し表現の削減
3つ目はクエリ内での処理の書き方に関する課題です。 例えば、複数のカラムに対して同様の前処理をする場合、同じ処理を複数回記述する必要があります。
カラム数が少ないテーブルならそれで問題ありませんが、テーブルに含める説明変数が多いと、同じ処理を何十行にもわたって記述する必要が発生します。
このようなケースの場合、FOR文を定義することで、コード量を減らすことができます。

終わりに
本記事では、MLコンテストで利用するデータを作成する際に、「どのようなコンテスト用データを作成したのか」「コンテスト用データを作成する上で注意した点」の2つについて紹介しました。
前者の「どのようなコンテスト用データを作成したのか」では、データの作成方法を工夫することでバイアスを緩和する方法について紹介しました。今回は主にPosition biasについて記載いたしましたが、これ以外にも様々なバイアスが存在し、そのようなバイアスを考慮した機械学習モデルについて複数の先行研究が存在します。バイアスを考慮した機械学習モデルに関する日本語の書籍だと 「施策デザインのための機械学習入門」 が個人的にはおすすめです。
後者の「コンテスト用データを作成する上で注意した点」では、PythonのJinja Templateを利用して動的にSQLクエリを生成する話をしましたが、データソースがGoogle BigQueryならば、 Scripting statements でも同様のことができます。
さらに、ELTツールである dataformのSQLX を利用すれば、動的にSQLXを作成するだけでなく、データ処理のパイプラインを構築することも可能になります。
本記事を記載する際に、コードだけでなく、SQLクエリもDRY原則に則って開発することが重要だなと、改めて実感しました。

SUUMOサイト内でのレコメンド・一覧おすすめ順の分析/ロジック開発を担当
Kenshin IKEGAMI, Takuya YOSHIKAWA, Kengo HOTATE, Mikio SHIGA
データを利用して、SUUMO内でのユーザー体験の改善を行う部署に所属
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


