こんにちは、データエンジニアの多田です。 私は現在、データ利活用基盤「Knile(発音は “ナイル")」の開発をしています。
今回は、私が Knile チームでスクラムマスターからプロダクトマネージャーへと役割が推移していく中で取り組んできた、チーム開発の課題とその対策について紹介いたします。

Knile とは
Knile とは、以前 CET と呼ばれていたチームが開発するデータ利活用基盤です。
Knile のビジョンや設計思想については、最近行われた社外への登壇資料があるので、ご覧ください。
時間軸で取り組むチーム運営
この記事では以下の 4 つのサイクルに分けて取り組みを紹介します。
- 長期計画
- 半期
- 四半期
- スプリント(2 週間)
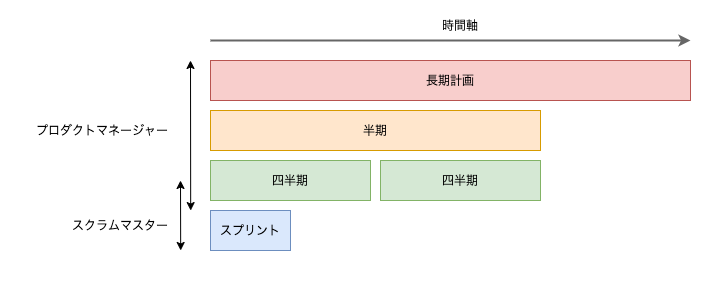
これは実際に業務の中で考える思考の順番でもあります。
より抽象度が大きく戦略性の求められる「長期計画」から始まり、最終的には日々の開発までスコープを刻むことで、メンバー間におけるコミュニケーションコストを小さくするという狙いもあります。
長期計画
リクルートでは新しい年度になると、会社から全体に対して長期方針の共有があり、各メンバーはこれに沿った形でミッションを策定し日々の業務をこなしていきます。
会社の方針のインプット
会社方針には、具体的なシステム要件やメンバーアサインの話は出てきませんが、少なくとも数年以内に会社が目指していく方向性というものは得られます。 特に、データ利活用基盤については「半歩先に」というポリシーで見据える事が必要で、各事業プロダクトが必要になったときにすぐに着手できるように動けないと会社全体のスピードが落ちてしまいます。
昨今のクラウドプロバイダは、ニーズが高いシステムをマネージド化しサービスとして利用可能にすることに力を入れており、限られたリソースで汎用的なデータ基盤をつくっても太刀打ちできません。
例えば、Knile では誰でも使えるアドホック分析基盤として JupyterHub を提供していましたが、Google Cloud が Vertex AI という統合型分析基盤の提供を始めたので、 Knile としてもバックエンドとして Vertex AI を使えるような機能追加を行いました。
このように、データ基盤チームに求められていることは、クラウドプロバイダーや OSS の状況を常に把握し、「会社が目指す方向」に合わせて事業との間で橋渡しをすることだと考えています。
横断データチーム
2021 年 4 月の会社統合により、それまで各リクルート子会社がもっていた多数のデータ基盤プロダクトが「横断プロダクト」としてまとめられ、適用範囲が広がることになりました。
例えば、Knile は「旧リクルートライフスタイル」のプロダクトでしたが、現在では自動車領域や業務・経営支援領域などでも採用事例が増えており、「なぜ社内外のシステムではなく Knile を利用するのか」という問いに明確に答えられることがより重要になってきています。
また、横断プロダクトチームが持つデータ基盤プロダクト同士で提供価値が重なるものがでてきているため、プロダクト間の連携や統廃合といった、単なる利活用だけではない開発の必要性も増えています。
例えば、横断プロダクトの中には Job 実行基盤として Knile 以外にも Crois というプロダクトがあります。 両者はもともとの会社が異なり活用してきた事業が異なるという経緯はありますが、それぞれ機能拡充していった結果両者の機能差分は埋まりつつあり、社内利用者からすると「どっちを使えばいいの」という疑問が生まれます。
基盤プロダクトとして難しいのは、単純に自プロダクトを高機能にすればいいというわけではなく、「組織として何が最適なのか」といった観点をもってプロダクトの方向性を決める点にあります。 この観点では、横断プロダクトの各プロダクトは、競合というよりは「エコシステムの協働者」となります。
半期
リクルートでは半期単位でメンバーが達成すべきミッションを設定します。
ミッションの方向性は、より上位の組織から整合性をもって降りてくるものですが、具体的な プロダクトバックログ に落とすには柔軟性があり、ここが基盤プロダクトのプロダクトマネージャーとして一番面白い部分だと思っています。
プロダクトバックログのスコープ
一方、期間が明確に決まっているミッション制度と、Knile チームが採用している スクラム という開発手法のすり合わせには毎回難儀します。
例えば、ミッションの 1 つに「システム信頼性の向上」というテーマがあるとすると、それに対応するタスクとして期限のないリファクタリングから、締め切りのある EOL 対応まで幅広い種類があり、 「この半期にどの順番でどこまでやるか」という調整を都度行っていく必要があります。
気づくと締め切りがあるタスクを優先的に行ってしまい、重要だが締め切りのないタスクを後回しにしてしまうのは、みなさん経験があることだと思います。
そこで、以下のようなマトリクスを使って、予め枠を抑える方法を採ることにしました。
- 攻め(計画的)と守り(対症療法的)
- SRE サイトリライアビリティエンジニアリング にある「SRE のうちエンジニアリングの割合を 50%以上にする」という記述を参考にしています
- これは、Knile チームの SRE が開発チームと分離していないから発生する問題でもあります
- 機能開発(Dev)と運用(Ops)
- リソースの半分以上は機能開発にあてたいという私の願望があります
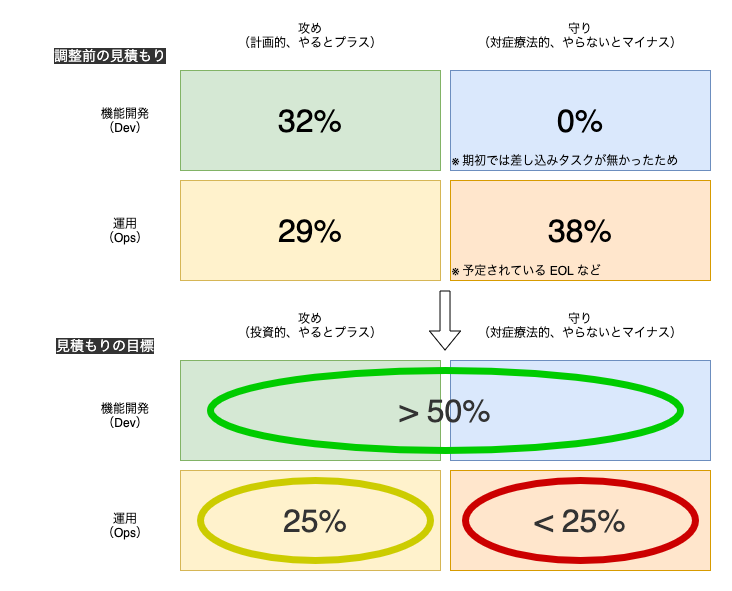
これをチームでは「50%ルール」と呼んでいます。
直感的に、枠を抑えた開発計画は全体最適にはならない気もしますが、「私達はこの半期に新規開発していない」のような心理的疲弊を防ぐためには有効かと思い、暫定的に活用しています。
チームの心理的圧力とリソース配分については過去に個人ブログでも投稿しているので参照してください。
プロダクトマネジメントツールとしての ZenHub
私のチームでは ZenHub を使いプロダクトバックログとスプリントを可視化しています。
ZenHub は多くのデータを GitHub のデータとして管理しているので、「Single Source of Truth としての GitHub」を破壊しづらいのが好みなポイントです。
社内でも ZenHub を使っているチーム (スタディサプリの例) は複数あって実績がありますが、Jira などの他のプロジェクト管理ツールでもいいと思います。
バックログアイテムは GitHub の Issue として管理され、複数の Issue を束ねるために Epic というデータ構造を利用しています。
ZenHub は最近開発が活発なので多機能なのですが、私のマネジメントポリシーではごく少数の機能のみ必須で使い、あとはメンバーの自由にやってもらっています。
- Release と Release Report (バーンアップチャート)
- Estimate (見積もり)
- Milestones もしくは Sprints (スクラムスプリント)
- Epic はネストせず、ミッションと同期させる
バーンアップチャートの有用性については、上述のスタディサプリの記事に言いたいことが全て書いてあったのでそちらを参照してください。
1 点、「Epic はネストせず、ミッションと同期させる」というのは、私がやっているおそらく独自の取り組みになります。
ZenHub の仕様上は Epic はネストさせることで、バックログアイテムの複雑な依存関係を表現できますが、これは利用していません。
プロダクトマネージャーとしては、「各メンバーのミッションとチームの開発計画に齟齬がないか」を考慮して同期し続けることに主眼があります。
しかし、見積もりに対する実績の増減や差し込みタスクにより、半期の途中でミッションを見直す必要がそこそこの頻度で発生します。
各メンバーのミッションは GitHub や ZenHub の管理外で行われるので、ここだけは Single Source of Truth から逸脱せざるを得ません。 そこで、Epic のリスト(半期で 10 個程度)をスプレッドシートで管理し、
- チーム外からみたロードマップレベルの開発計画のためのスプレッドシート
- チーム内のバックログ、スプリント管理のための ZenHub
というように使い分けています。
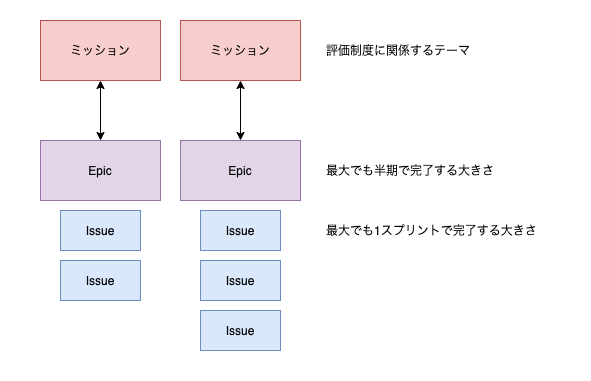
イメージとしては productboard というサービスのようなことを手作業でやっている感じです。
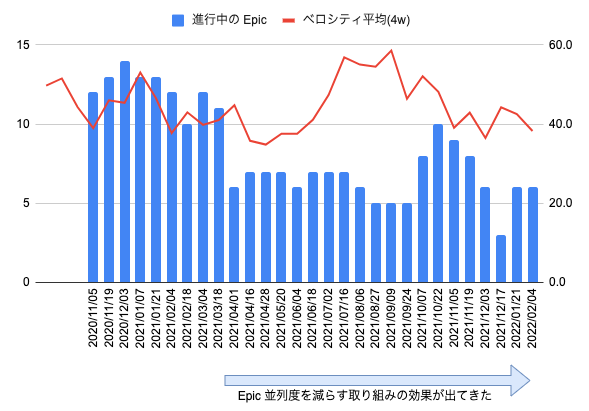
Epic 優先度とタスク並列度
私が Knile 開発チームでスクラムマスターになったときに最初に取り組んだのは、「チームメンバーが同時に携わっているタスク数を減らす」ということです。
これは、「 フロー効率 」という概念から来ています。
プロダクトバックログのスコープが調整済みであっても、それに取り組む順番を間違えると、チームとしてのスループットは減少します。
2 年前にスクラムマスターを始めたころは「1 人=Epic」になっており、チーム開発というよりは「個人開発 ✕ N」という状態でした。
そこで、まずは ZenHub を使い「今回のスプリントで動きがある Epic」を見える化しました。
スクラムのスプリントプランニングではスプレッドシートで管理された Epic の優先度の高いものから順番にスプリントバックログとし、原則的に採用の Epic 以外のタスクは次以降のスプリントに回すようにしています。 ただし、タスクに待ち時間が発生するものや、兼務・個人プロジェクトなどチームとして管理できないものについては例外としています。
この取り組みを 1 年以上続けることで、タスクの並列度を低い状態で安定させることができました。
四半期
タスク調整
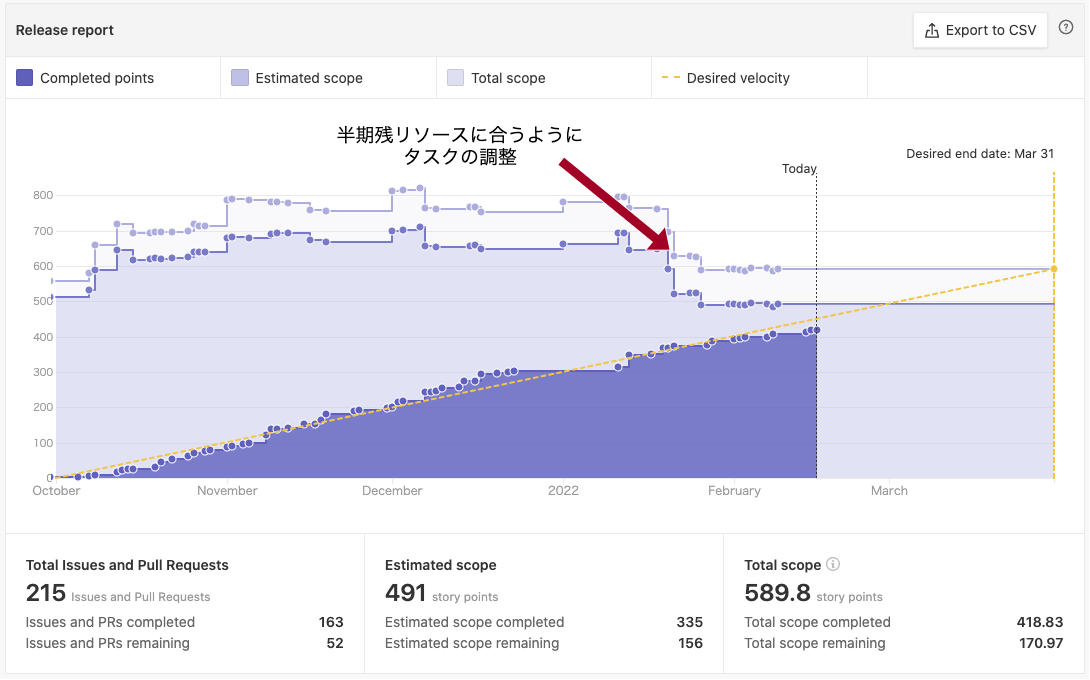
見積もりの誤差や「対症療法的」タスク、その他差し込みにより半期のスコープはだいたい上振れます。
これを修正し、現実的なタスク量に調整するために四半期ごとに Epic の見直しを行います。
これには、ZenHub のバーンアップチャートを使って管理しています。
「50%ルール」を守るようにタスク種類ごとにスコープを変動させ、半期終了時のタスク完了予定が妥当なものになるようにします。
これにより「スクラムの指標は正常なのにミッションが未達成」という状態を防ぎます。
アジャイルメトリクスの測定
Knile チームでは
class SRE implements interface DevOps
に倣って class Scrum implements Agile という方針を打ち出しています。
つまり、スクラムはシステムのアジャイル性を高める 1 つの具体的処方箋である、というポリシーです。
スクラムは「問題が発生したら計画を変更してでも柔軟に対応する」というフレームワークですが、そのためには「いまのチームがどういった状態か」を知る必要があります。
「 (スクラムは)その他の技法・⽅法論・プラクティスの⼊れ物として機能するものである (引用:スクラムガイド,2020 年 11 月) 」の通り、にスクラムに規定されていない独自の取り組みがいくつかあります。
Knile チームでは大きく
- Four Keys
- アジャイルメトリクス
という 2 つの指標を使っています。
Four Keys についてはメンバーのブログを参照してください。
ここでは「アジャイルメトリクス」について紹介します。
これは、 More Effective Agile という書籍を参考に、メンバーに 28 項目のアンケートを実施し、それの時系列変化を観測することでチームの定性的問題を把握し対処していく運用です。
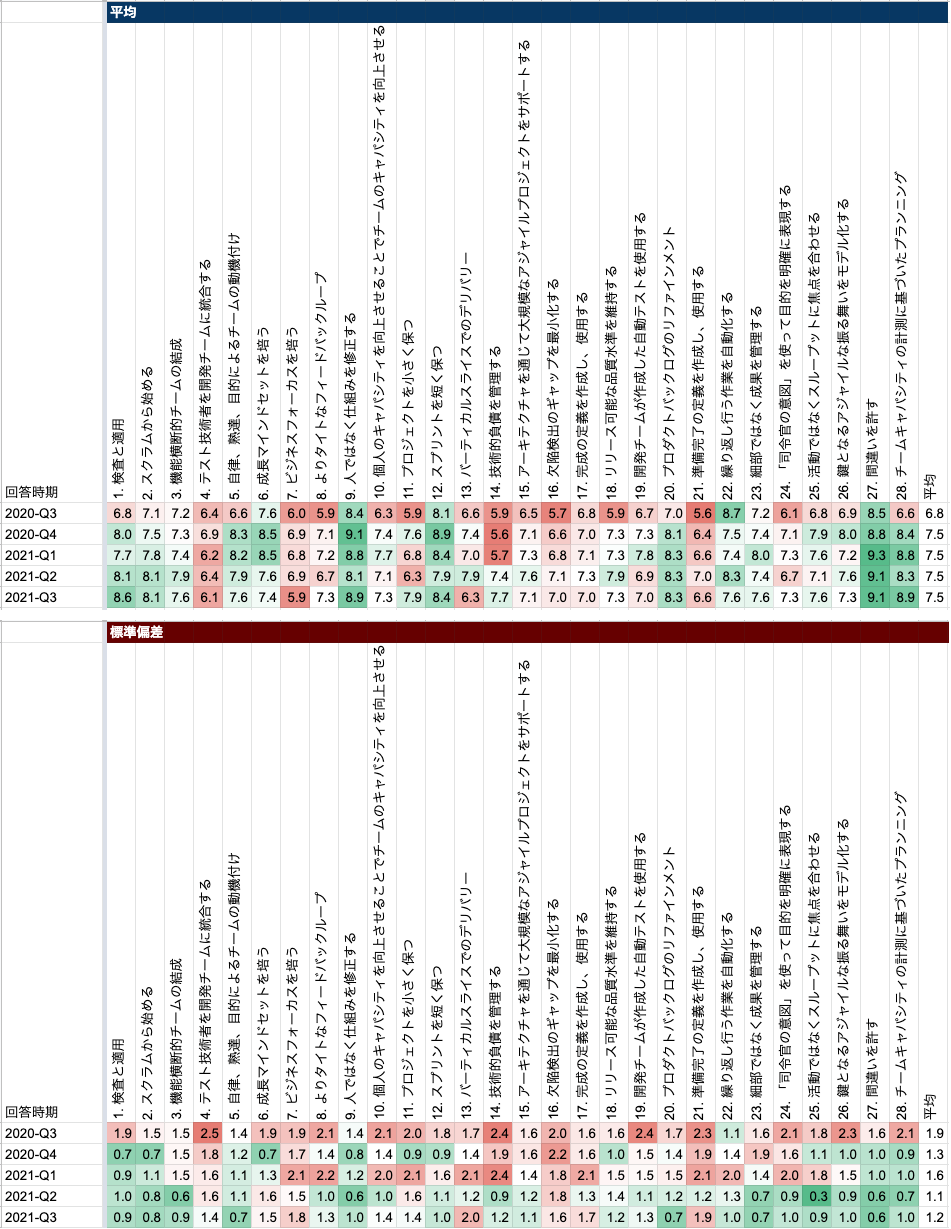
メンバーには、四半期に 1 回、28 項目に対し 0 から 10 までのポイントでアンケートに回答してもらっています。 これはざっくり、「チームがどれだけアジャイルできているか」を間接的・主観的に図る指標になります。
アンケート結果は匿名で、四半期ごとに集約され、以前の回答からの平均値と標準偏差の差分を調べます。
集計の結果、
- 平均が低いもの : チームとして改善の必要性がある
- 標準偏差が大きいもの : チームメンバー間で意識のズレがあるので、「項目自体に無自覚」or「チームの中で浸透に偏りがある」
としてアンケート実施の次の四半期に改善タスクを投入します。
例えば実際の取組みとしては、
- 「21. 準備完了を定義する」の平均値が低かった
- Issue テンプレートを整備したり、Production Readiness Checklist、リリースステージの定義を行った
- 「14. 技術的負債」の平均が低く、標準偏差が大きかった
- 一部のメンバーは負債に関して問題意識を持っていないが、その他大部分のメンバーが技術的負債に対して危機意識があるとみなした。アクションとして技術的負債を分類し、何が負債なのか、それは意図的なのかというディスカッションを設けた
- 「7. ビジネスフォーカスを培う」は平均値が低かった
- データ基盤と事業の距離が離れてしまっているため、 CRE (Customer Reliability Engineering) といった役割を作り、社内利用者とのコミュニケーションを密に行う取り組みを実施した
- 「9. 人ではなく仕組みを修正する」「27. 間違いを許す」は継続して平均が高く、標準偏差も小さかった
- これはチームとして誇れることなので採用でも積極的に活用していくことをチームで確認した
- 全体的に標準偏差が大きかった
- アジャイルやスクラム自体の知識が不足しているためスクラム勉強会を実施した。その結果、標準偏差は改善傾向にある
このように、悪い点は改善し良い点は伸ばしていくという取り組みを行っています。
スプリント
スクラムイベント
スクラムガイドにはスクラムの 5 つのイベントが記載されていますが、Knile チームでは以下のようなスケジュールで行っています。
- スプリント
- スプリントプランニング(スプリント開始前+隔週 3 回)
- デイリースクラム(毎日)
- スプリントレビュー(都度)
- スプリントレトロスペクティブ(隔週 1 回)
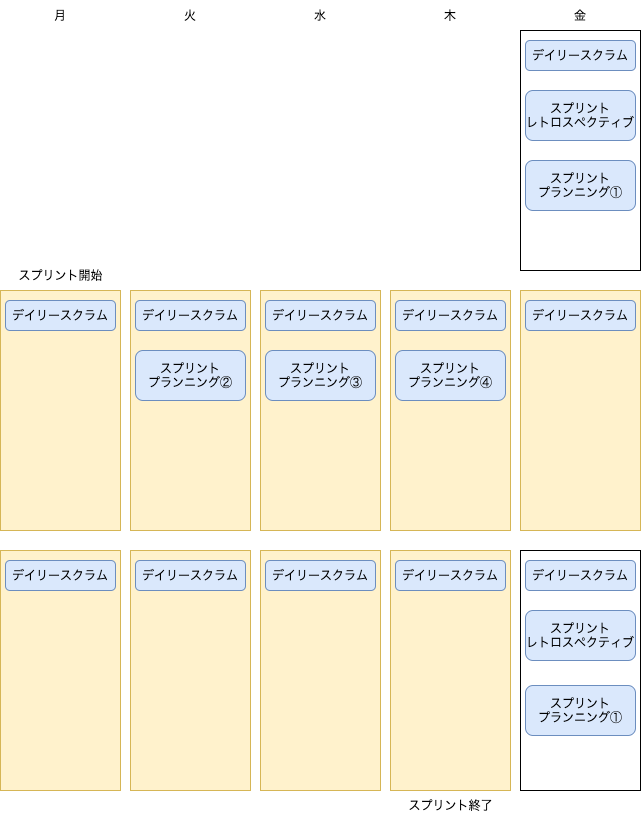
スプリントプランニングは、スプリント開始前とスプリント中 3 回の計 4 回行っています。
- スプリント開始前 : 次のスプリントをのタスクをバックログから抽出しアサイン
- スプリント中(バックログリファインメント) : バックログの見積もり、分割、着手開始条件の設定
のように目的が異なり、特にスプリント中のプランニングにより、次回スプリントの開始をスムーズに行うことができます。
スクラムにかかるコスト
スクラムの運営には予想以上のコストがかかります。
例えば Knile チームの実施コストを見積もると以下のようになります。
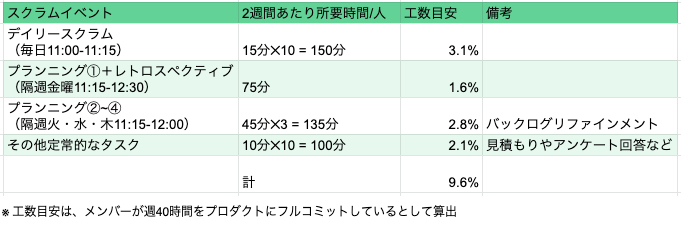
つまりチームの人的リソースのうち、約 10%のコストをスクラムの運営に費やしていることになります。
スクラムは手段であって目的はシステム開発を通じて会社の利益に貢献するかです。 なので常に「我々はスクラムを採用することで、それにかかるコストに見合うメリットを得られているか」を考えるのが重要です。
スプリントプランニングと見積もり
Knile チームではスプリントプランニングでバックログリファインメントを行うときに、メンバーのアサインはせず、実際にスプリントが開始されるときにメンバーが好きなタスクを持って行って作業を開始します。
この方法は、自分がスプリントで取り組むタスクをある程度自由に選べるということで便利なのですが、以下のような問題もあります。
- メンバーによって熟練度の差があり、「誰が担当するか」によって見積もりが変動する
- 例えば、「A さんは API の設計・実装は人より早く作業できるが、Job ワークフローシステムの知見は乏しい」など
- 同様に、得意な人が得意なタスクを連続して選択する傾向がある
- 熟練度の問題で、あるタスクを問題なく遂行できるメンバーが少数しかいない場合に、そのメンバーに選択肢がなくなる
この問題を解決するためには、スキルマップを使ってトラックナンバーを把握する、メンバーの熟練度に偏りが生じないようにタスクアサインを調整するなど、短期的には効果が出にくい対策を取る必要があります。Knile チームでは後述の Troubleshooting という取り組みで、ある程度担保しています。
ナレッジマネジメントの取り組み
ここからは、時間軸による営みではなく、日々蓄積されるナレッジの品質の向上というストックの取り組みを紹介します。
Knile チームでは以下の 4 つの GitHub レポジトリを作り、技術文書を管理をしています。
- ADR
- Spec
- Docs
- Troubleshooting
ADR (Architectural Decision Record)
これは、システムを新しく追加、または大幅にアップデートする際の意思決定の履歴を記録を記録するものです。
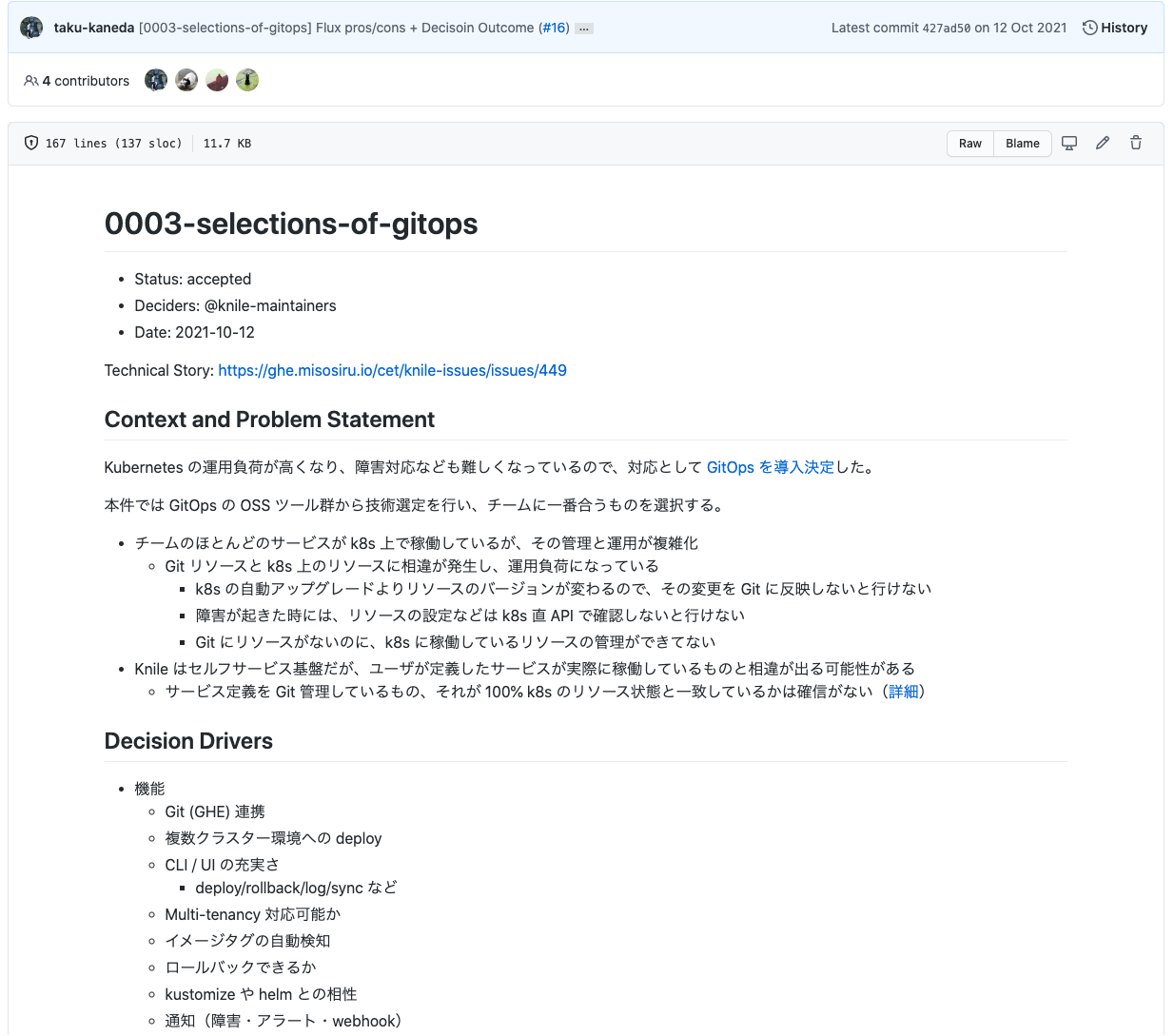
後述の「Spec」は「最新のシステムの設計図」を示しますが、そのような形になった経緯については記録されていません。
例えば、GitOps 環境として Argo CD と Flux という選択肢があったときに、「最終的に Argo CD を採用しこのようなアーキテクチャーになった」というのは「Spec」で管理できますが、 「なぜ Flux は採用されなかったのか」や「その際にどういった判断基準があったのか」などの情報は管理できないため、ADR でログを残します。
「Spec」は常に最新のもので更新していくのに対して「ADR」は過去のスナップショットになります。 昨今のデータプロダクト向けクラウドサービスや OSS は変遷が早いため、「いま採用するなら○○だと思うんだけど、なぜ✕✕が採用されたのだろうか」という疑問が尽きることはありません。 将来メンバーが増えたときに「強くてニューゲーム」をするために必要です。
ADR のフォーマットには様々な種類がありますが、Knile チームでは Markdown Architectural Decision Records というものを採用しています。
Spec
これは、複数のシステムをまたぐシステム全体の設計書になります。

Knile を支えるレポジトリはおよそ 70 あり、システムのライフサイクルやシステム間の結合度によってコードが分割されています。
例えば、 Knile Prediction API と呼ばれる推論 API 基盤だけでも、ベースイメージ作成コード、Jupyter Notebook CI/CD、ジョブ用 K8s マニフェスト変換コード、API 用 K8s マニフェスト変換コード、API ランタイム Python パッケージなど、10 以上のコードが影響しあっています。
それぞれのレポジトリに Readme はありますが、そのスコープはあくまでもレポジトリに閉じているため、システム連携のための仕様をどこに置くかは責任があいまいになりがちです。
そこで、システムを横断した仕様書置き場として Spec というレポジトリを用意して管理しています。
これは、メンバーのオンボーディング資料としても活用しています。
Docs
これは、社内の Knile 利用者向けのマニュアルです。
Sphinx と reStructuredText をつかってマークアップされています。 Knile は社内利用者が 150 名以上、データ施策数が 100 以上登録されており、データサイエンティストから Web エンジニアまで様々なスキルセットの利用者がいます。
そのため、できるだけ平易な言葉をつかって「データサイエンティストでもデータパイプラインが構築できる」ことを目指しています。
Troubleshooting
これは、社内向け障害報告書( ポストモーテム )をまとめるレポジトリです。
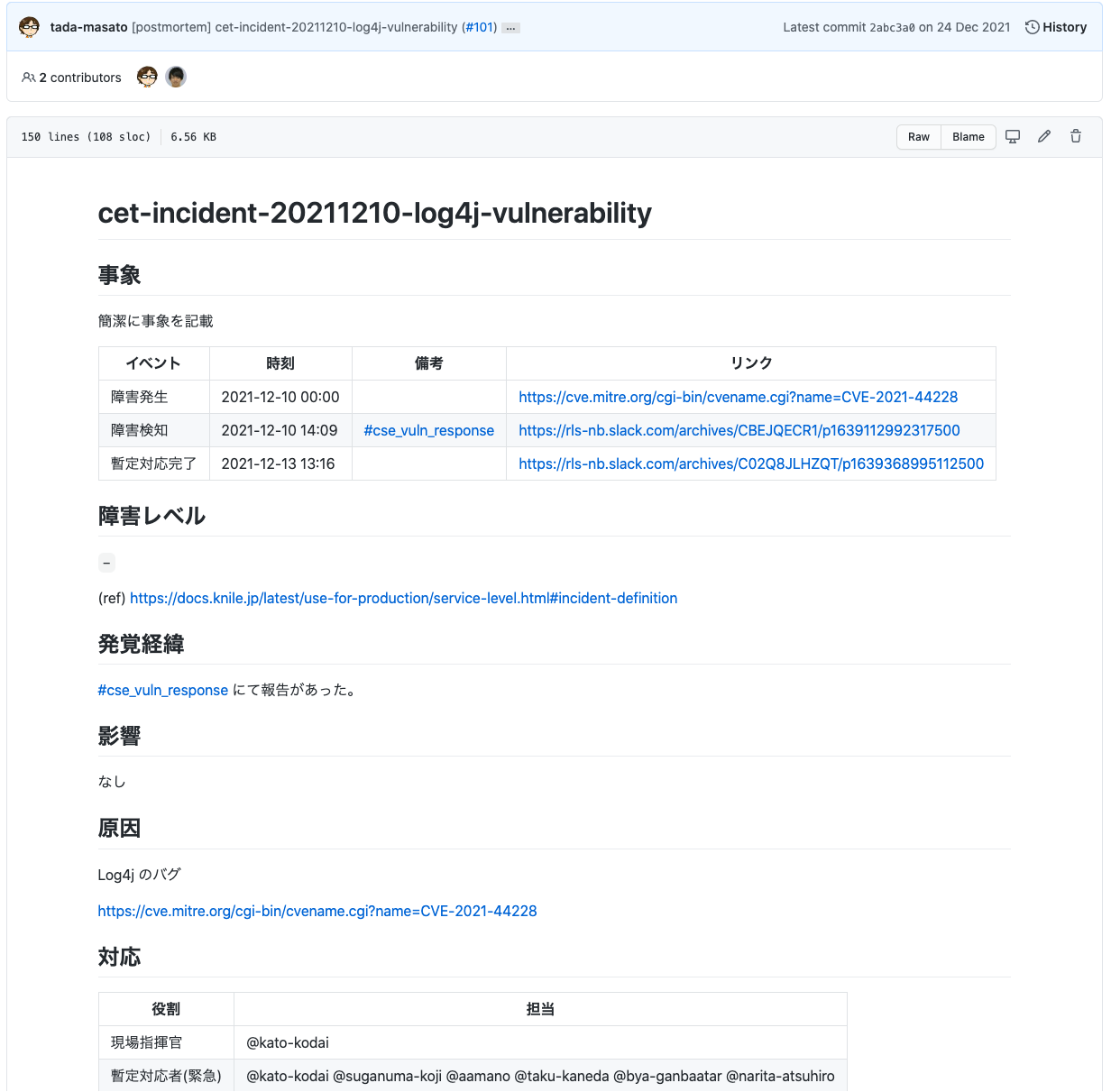
入門監視 を参考に、障害対応時の役割分担や対応手順を定めており、事業影響がない問題であってもポストモーテムを書くことにしています。
一番の目的は、「障害解決を通じてチームの熟練度を揃える」ことと、「将来同じことが起こったときに類似の解決方法をすぐ知れる状態にする」ことです。
チーム全体の熟練度を上げるには、全員がすべてのシステムに触れるのが一番ですが、限られた時間では限度があります。
そこで、障害解決に至った思考や取り組みを共有することで、熟練度のパワーレベリングを行います。
障害対応は多くの場合緊急性が高いので、熟練度の高いメンバーがアサインされる傾向にあります。ここをトレーニングの場としてランダムなアサインにするのはなかなかできることではありません。 ポストモーテムでは、試したことや考えたことを時系列で記載することを推奨していて、熟練度の低いメンバーはそれをレビューすることで経験値を積みます。 万が一同じシステムで問題が起こっても、過去の障害対応の経験が活きることで見通しが良くなり対応スピードの向上とメンバー間の熟練度の偏り解消が期待されます。
まとめ
Knile と呼ばれるリクルートのデータ利活用基盤のスクラムマスター・プロダクトマネージャーとして経験してきた課題とそれの対策を、時間軸・ナレッジマネジメントという 2 つの軸で紹介しました。
Knile チームはデータエンジニアリングを仕事にしているので、チーム開発においても様々な定量・定性な指標を使って、チーム自体もデータドリブンで改善しています。
今回紹介した取り組みは唯一の正解というわけではなく、「複雑な問題に対応する適応型のソリューションを通じて、⼈々、チーム、組織が価値を⽣み出すため (引用:スクラムガイド,2020 年 11 月)」の 1 つの方法に過ぎません。
みなさんの開発チームでも参考にしていただき、より良い世の中になっていければ幸いです。

データ利活用基盤 Knile のプロダクトマネージャー
多田雅斗
リクルートのデータエンジニアグループを経て社内プロダクトの API 基盤開発、スクラムマスター、プロダクトマネージャーになった人
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら