
はじめに
本記事は『 NeurIPS 2021 参加報告 前編 』の続きです。引き続き、昨年12月に参加した機械学習の国際会議「Neural Information Processing Systems」の様子を紹介します。本記事ではスポットライト発表、ポスター発表、チュートリアルについて書きます。
再度のおことわりですが、個々の論文を詳しく解説するよりも研究動向を概観することを優先して紹介するので、詳細に興味を持たれた方は原典をあたっていただくようお願いします。また、論文紹介で用いる図は断りのない限り論文から引用したものです。本文については引用はありません。
スポットライト発表
スポットライト発表からは5本の論文を紹介します。
Diffusion Models Beat GANs on Image Synthesis
- 著者: Prafulla Dhariwal, Alex Nichol
- URL: https://proceedings.neurips.cc/paper/2021/hash/49ad23d1ec9fa4bd8d77d02681df5cfa-Abstract.html
拡散モデル(diffusion model)は最近注目されている生成モデルの一種で、ノイズを徐々に付加または除去することによってデータと潜在変数の間をつなぎます。尤度ベースで学習するため、GANと比べてモード崩壊1が起きにくく、学習が安定しやすいというメリットがあります。また、同じく尤度ベースの自己回帰モデルよりも高速に学習・推論できます。拡散モデルはCIFAR-10など小さい画像データに対しては既に最高性能を達成していましたが、ImageNetのような比較的大きい画像に対してはGANに劣後していました。著者らはこの原因を次の2点だと考えました。
- 拡散モデルのアーキテクチャが十分に最適化されていないこと
- GANが多様性を犠牲にして画像品質を高めていること
そして、アーキテクチャの探索と、多様性と画像品質のトレードオフによってそのギャップを埋めることに成功しました。下図において、左がBigGAN(FID2 6.95)、中央が提案手法(FID 4.59)、右が実際の画像です。BigGANよりも多様な画像を生成できていることがわかります。

Learning to See by Looking at Noise
- 著者: Manel Baradad, Jonas Wulff, Tongzhou Wang, Phillip Isola, Antonio Torralba
- URL: https://proceedings.neurips.cc/paper/2021/hash/14f2ebeab937ca128186e7ba876faef9-Abstract.html
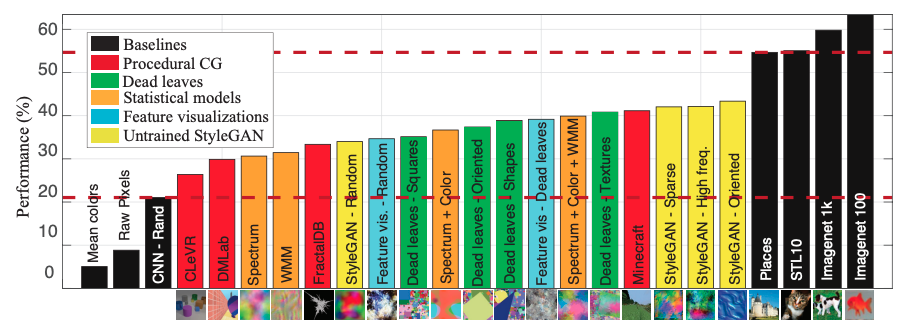
画像認識において標準的なパラダイムとなった大規模データでの事前学習には、著作権、プライバシー、(社会的な)バイアスといった問題がつきまといます。そこで近年、こういった問題から無縁な人工データによる事前学習の研究が行われています3。本論文では、いろいろな手法で発生させたノイズを使ってモデルを事前学習し、ImageNet-100の linear evaluation で「ノイズの性能」を比較しました。結果は下図の通りで、初期状態のStyleGANから生成された画像が画像認識モデルの事前学習に使えるということがわかりました。
Overcoming Catastrophic Forgetting in Incremental Few-Shot Learning by Finding Flat Minima
- 著者: Guangyuan SHI, JIAXIN CHEN, Wenlong Zhang, Li-Ming Zhan, Xiao-Ming Wu
- URL: https://proceedings.neurips.cc/paper/2021/hash/357cfba15668cc2e1e73111e09d54383-Abstract.html
Incremental few-shot learningは、継続的に新規クラスをfew-shotで学習するタスクです。古いクラスを忘れてしまう破壊的忘却(catastrophic forgetting)をどう防ぐかが重要で、従来の対策は主に、パラメータへの制約や古いクラスに関する制約をつけることでした。
しかし、著者らが注意深く実験を行ったところ、訓練データで作った分類器を使って特徴抽出し、k-meansで分類する(継続学習をしない)という簡単なベースラインで従来手法に勝ってしまいました。
そこから、いろいろな制約をつけて継続学習するよりも最初の訓練時に平坦解(flat minima)を探す方が有効なのではないかという仮説に至りました(下図(c))。
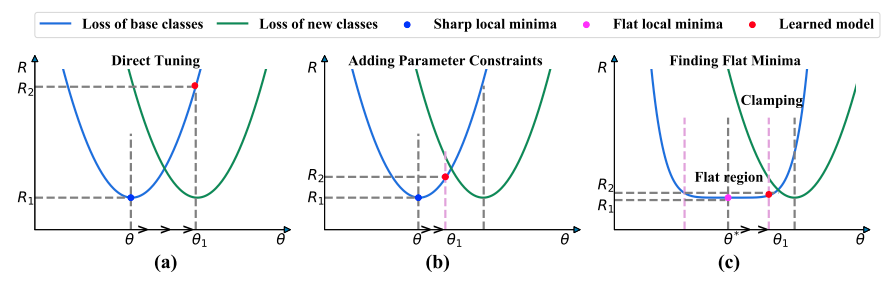
実験をしてみると狙い通り、そのように学習させたモデルは破壊的忘却の影響が小さいという結果が得られました。
FjORD: Fair and Accurate Federated Learning under heterogeneous targets with Ordered Dropout
- 著者: Samuel Horváth, Stefanos Laskaridis, Mario Almeida, Ilias Leontiadis, Stylianos Venieris, Nicholas Lane
- URL: https://proceedings.neurips.cc/paper/2021/hash/6aed000af86a084f9cb0264161e29dd3-Abstract.html
連合学習(federated learning)4 のほとんどの従来手法は、ローカルとグローバルのモデルが同じアーキテクチャをとります。このため、デバイスの種類が増えると、ローエンドなデバイスを対象外とするか、モデルサイズを一律に小さくするか、いずれかの妥協が必要となります。そこで、NNの幅をデバイスの性能によって変えられる仕組みを作りたいという動機が生まれます。NNの幅調節には、重要でない結合から順に落としていく順序付きドロップアウト(ordered dropout)という手法が使えます。
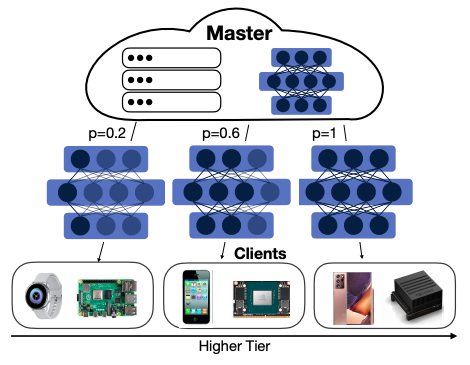
本論文で提案する連合学習手法であるFjORDは、次のようなものです:
- デバイスをクラスタリングし、各クラスタに許容できるNN幅を割当てる
- クライアント側で順序付きドロップアウトし、計算した勾配をサーバに送る
- 集めた勾配でモデルを学習させる
順序付きドロップアウトは推論時にも使えるので、バッテリー低下などのオンラインの性能劣化にも対応できます。
Counterfactual Invariance to Spurious Correlations in Text Classification
- 著者: Victor Veitch, Alexander D’Amour, Steve Yadlowsky, Jacob Eisenstein
- URL: https://proceedings.neurips.cc/paper/2021/hash/8710ef761bbb29a6f9d12e4ef8e4379c-Abstract.html
自然言語処理では、文中に「予測結果に影響してほしくない単語」がある場合があります。例えば、“X is a"という入力文に続けて文章を生成するとき、Xが"He"なら"doctor”、“She"なら"nurse"としてしまうような言語モデルがあったとしましょう。このようなモデルは「見かけの相関」を利用しているので分布外のデータ(OOD; out of distribution)に弱いですし、機械学習の公平性(FairML)の観点からも望ましくありません。
本論文は、テキスト分類モデルのテンプレート文に対してXを他の単語に置き換えたときにモデルの出力が変わらないことを反実仮想不変性(counterfactual invariance)と定義し、それを実現するための学習方法を提案しました。また、そのような性質を持つモデルはOODデータに対する予測性能が高いことも示しました。
ポスター発表
ポスター発表からは6本の論文を紹介します。
Projected GANs Converge Faster
- 著者: Axel Sauer, Kashyap Chitta, Jens Müller, Andreas Geiger
- URL: https://proceedings.neurips.cc/paper/2021/hash/9219adc5c42107c4911e249155320648-Abstract.html
画像認識ではImageNetなどで事前学習させたモデルを所望のタスクにファインチューニングさせるという手続きが主流となっている中、GANで識別器をスクラッチで学習させるのは非効率に思えます。しかしこれには理由があって、識別器として安易に学習済みモデルを使うと敵対的学習のバランスが崩れて生成器の勾配消失が起きやすいという問題があります。
そこで、著者らは学習済みEfficientNet5の各層の出力をチャネル・層方向にミックスしたものを識別器に渡すことを提案しました。このようにすることで、生成器は画像の様々なスケールについてフィードバックを受けられるので、より多くの情報から学習できます。実際、StyleGAN2-ADA6の識別器を提案手法に置き換えると、学習の収束が早まるだけでなく、収束後のFIDの値も改善しました。

従来のGANが苦戦してきたポケモンの画像生成(訓練データはたった831枚)でも比較的うまくできています。 動画 もあるのでぜひご覧ください。

ちなみに、ポケモン画像生成といえば、大量のテキスト・画像ペアで学習した DALL-E を使うとさらに高品質な生成ができるという 報告 もあります。
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
- 著者: Hassan Akbari, Liangzhe Yuan, Rui Qian Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, Boqing Gong
- URL: https://proceedings.neurips.cc/paper/2021/hash/cb3213ada48302953cb0f166464ab356-Abstract.html
本論文では、動画、音声、テキストという異なるモダリティのデータを同じ重みで扱えるモデルを自己教師学習によって実現するVATT(video-audio-text Transformer)を提案しています。
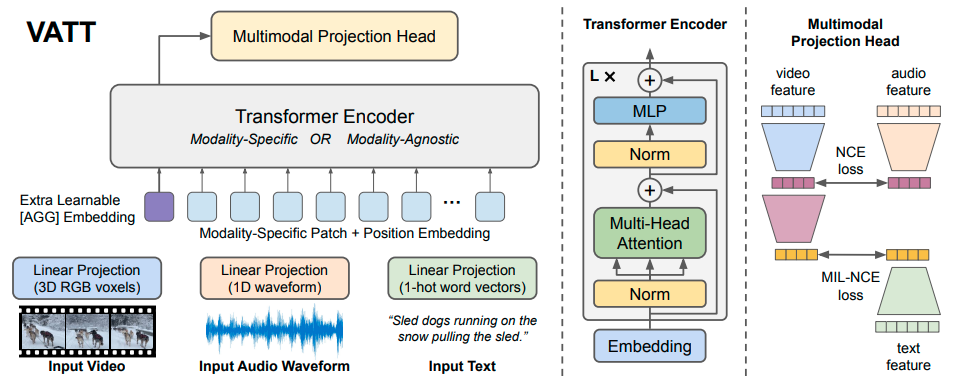
上図の通り、動画は各フレームをパッチに分割、音声は適当なサイズに分割、テキストは単語ごとにone-hotエンコーディングした上で線形変換した上で、Transformerに入力します。訓練データには、YouTubeからマイニングした動画とその音声及びスクリプトを利用します。VATTは「動画と音声」及び「動画とテキスト」という2つのペアでの対照学習 7を通して、モデリティをまたいだ表現を獲得します。ゼロショットの動画検索などの実験により性能が確認されています。
Low-Rank Subspaces in GANs
- 著者: Jiapeng Zhu, Ruili Feng, Yujun Shen, Deli Zhao, Zheng-Jun Zha, Jingren Zhou, Qifeng Chen
- URL: https://proceedings.neurips.cc/paper/2021/hash/8b4066554730ddfaa0266346bdc1b202-Abstract.html
GANの生成器は潜在空間からデータが分布する高次元多様体への写像だと考えることができます。すると、画像のうち関心のある領域Aについて、JacobianのGram行列を低ランク分解することで、潜在空間のうちAを操作する部分空間を導けます。また、Aに影響しない零空間も導けます。

こうして得られた部分空間の方向に潜在変数を移動させると、画像を編集できます。下の図は、FFHQデータセットで学習させたStyleGAN2についてこの操作を行ったものです。

A 3D Generative Model for Structure-Based Drug Design
- 著者: Shitong Luo, Jiaqi Guan, Jianzhu Ma, Jian Peng
- URL: https://proceedings.neurips.cc/paper/2021/hash/314450613369e0ee72d0da7f6fee773c-Abstract.html
創薬では、標的タンパク質の立体構造が与えられたときに、その特定の部位に結合するような分子を設計するというタスクがあります(structure-based drug design; SBDD)。本論文はSBDDのための分子生成モデルを提案しています。
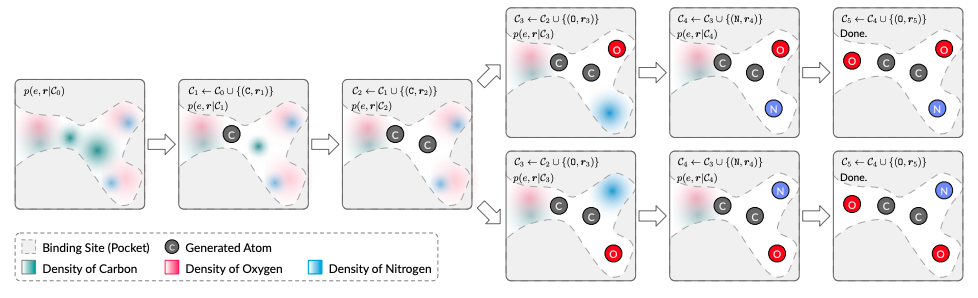
まず、タンパク質を電子密度で表現します(その座標がどの原子に占められているかの確率分布を考える)。 次に、GNNなどを組み合わせたモデルで結合部位内の各座標における原子の存在確率を予測します。これを自己回帰的に繰り返して原子を配置していくことで、最終的に結合部位にはまる分子が生成されます。
MLP-Mixer: An all-MLP Architecture for Vision
- 著者: Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Tom Unterthiner, Jessica Yung, ANDREAS Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy
- URL: https://proceedings.neurips.cc/paper/2021/hash/cba0a4ee5ccd02fda0fe3f9a3e7b89fe-Abstract.html
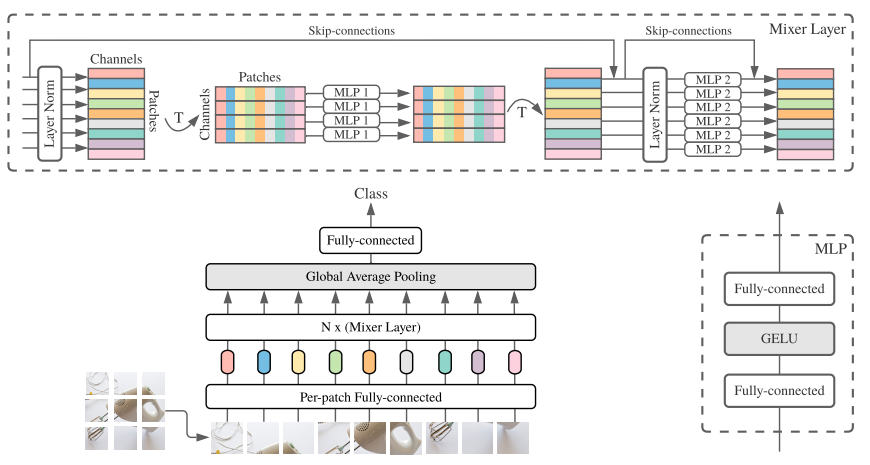
画像データに対する深層学習と言えば、畳込み演算を用いたCNNが長らく主流で、最近は自己注意(self-attention)を用いたTransformerが注目されているという状況でした。これに対して本論文は、多層パーセプトロン(multi-layer perceptron; MLP)をベースとした画像認識モデルとしてMLP-Mixerを提案し、これらの演算の必要性に疑問を投げかけています。
MLP-Mixerは、時間(トークン)方向とチャネル方向に交互にMLPを適用するMixer層を重ねたシンプルなモデルです。
MLP-MixerをJFT-300M(3億枚の画像からなるデータセット)で事前学習すると、畳み込みを利用するBiT(big transfer)や自己注意を利用するViT(vision Transformer)に匹敵する性能を出しました。
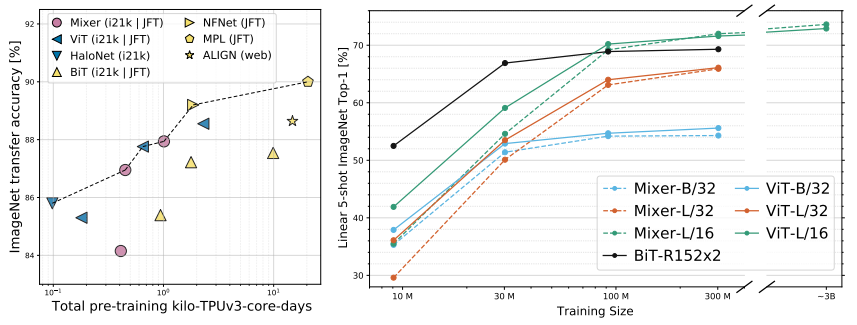
この結果から、画像認識において畳み込みや自己注意といった演算が効果的ではあるものの、必要とは言えないという結論が示唆されます。
Pay Attention to MLPs
- 著者: Hanxiao Liu, Zihang Dai, David So, Quoc V Le
- URL: https://proceedings.neurips.cc/paper/2021/hash/4cc05b35c2f937c5bd9e7d41d3686fff-Abstract.html
本論文もMLPベースのアーキテクチャを提案していますが、画像だけでなくテキストの学習も高い性能が出せると主張しています。
本論文で提案するgated MLP(gMLP)も、大まかに見るとチャネル方向と時間(トークン)方向のミックスを繰り返したもので、畳込みや自己注意を用いていません(下図)。
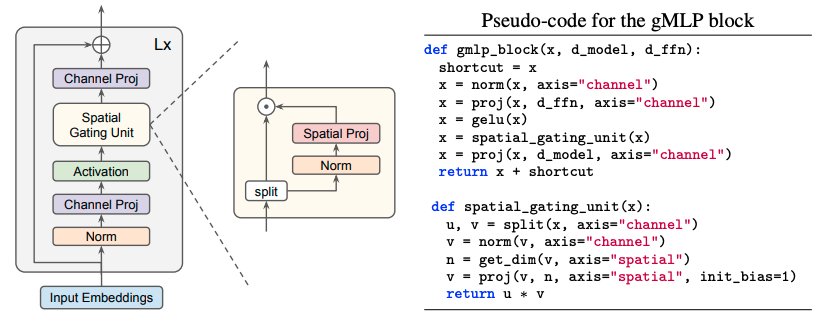
ところで、MLP-MixerもgMLPもGoogle発の研究で、発表時期も前者は2021年5月4日、後者は2021年5月17日と非常に近いです。昨年は他にもMLPベースの手法が提案されて一つのトレンドとなりましたが、この辺りの話題については こちらの資料 で詳しく論じられているので、興味のある方はぜひご覧ください。
Tutorial
チュートリアルは10本のプログラムがありました。このうち3本をごく簡単に紹介します。
Self-Supervised Learning: Self-Prediction and Contrastive Learning
- 発表者: Lilian Weng, Jong Wook Kim
- URL: https://nips.cc/virtual/2021/tutorial/21895
自己教師学習は汎用モデル実現のための有力なアプローチとして活発な研究が行われています。本チュートリアルでは、多数ある手法を自己回帰的な予測(例:言語モデル)と対照学習という2つのアプローチに分けて紹介します。また、将来の展望として動画データの活用などを挙げています。
Beyond Fairness in Machine Learning
- 発表者: Timnit Gebru, Emily Denton
- URL: https://nips.cc/virtual/2021/tutorial/21889
近年FairMLの研究が活発化していますが、本チュートリアルではそういったテクニカルな研究ではなく、現在の機械学習の研究成果が実際にどのような社会的影響をもたらしているかについて議論しています。既存の研究でもよく取り上げられる例で言うと、言語モデルが差別的表現を学習するというものや、特定の人種・性別・年齢の組に対して顔認識モデルの精度が低いといったものがあります。また、機械翻訳が未対応の低リソース言語を使う集団の声が他の言語での言論にかき消されるというような、社会システムとの相互作用で顕在化するより根深い問題についても紹介されています。
ML for Physics and Physics for ML
- 発表者: Shirley Ho, Miles Cranmer
- URL: https://nips.cc/virtual/2021/tutorial/21896
機械学習と物理という2つの領域の間で知識の交流が深まっています。機械学習には物理における「場」や幾何的な対称性のアイディア、そして微分方程式などの概念が輸入されてきました。逆に、物理のシミュレーションを機械学習で高速化するといった試みも増えています。本チュートリアルではこれらの動向を紹介した後、「複雑な問題に機械学習を適用してみた」だけでは科学的な発見を先送りする「科学的負債(scientific debt)8」だとし、物理の研究に機械学習を適用する際の姿勢に警鐘を鳴らしています。
おわりに
本記事では、NeurIPS 2021のスポットライト発表、ポスター発表、そしてチュートリアルについて書きました。
一緒に働きませんか?
弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。
-
データの従う分布が複数のモードを持つとき(多峰性)、生成器が一部のモードを無視してしまうこと。例えば、MNISTのデータにおいて特定の数字の画像ばかり生成してしまうようなことがあります。 ↩︎
-
Frechét Inception Distance。生成画像の品質の評価指標で、低い方が良いとされています。 ↩︎
-
例えば、Kataokaらの Pre-training without Natural Images 。 ↩︎
-
クライアントサイドのデータを中央のサーバに集約することなく、分散させた状態で機械学習を行う方法。プライバシー保護の観点で近年注目を集めています。 ↩︎
-
画像認識でよく用いられるImageNet事前学習済みモデル。事前学習の効率がよく、下流タスクでの性能も良いとされています。 ↩︎
-
StyleGAN2のデータ拡張に工夫を加えて学習効率を改善したもの。 ↩︎
-
自己教師学習の一種で、ペアになるサンプルどうしは近い表現に、非ペアのサンプルどうしは異なる表現になるようにモデルを学習させる方法。ここでは例えば、VATTを通した後の表現が「ピアノを演奏している動画」と「ピアノの音」では近くなるように、「ピアノを演奏している動画」と「人の話し声」では遠くなるように学習させています。 ↩︎
-
ソフトウェア開発において機械学習は「技術的負債(technical debt)」になりやすいと言われています。 ↩︎

機械学習エンジニア
Shion Honda
好きな技術は深層学習、得意料理はベーグルです。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


