
はじめに
機械学習エンジニアの本田志温です。2020年新卒入社で、機械学習を用いたデータ施策や社内のデータ活用プラットフォームの開発を担当しています。
昨年12月に、機械学習の国際会議「Neural Information Processing Systems」に参加(オンライン)しました。数多くの興味深い研究に出会えたので、その一部を紹介するために筆を執りました。分量が多くなってしまったので、記事を前後編に分割し、前編となる本記事では学会全体と口頭発表について書きます。後編ではスポットライト発表、ポスター発表、チュートリアルについて書きます。
個々の論文を詳しく解説するよりも研究動向を概観することを優先して紹介するので、詳細に興味を持たれた方は原典をあたっていただくようお願いします。また、論文紹介で用いる図は断りのない限り論文から引用したものです。
全体について
論文紹介に入る前に、学会全体についてまとめます。今回は2020年に続くオンライン開催でした。既存データセットでの精度競争が飽和しつつある(例:ImageNet)ことを反映してか、新しく"Datasets & Benchmarks"というトラックが追加されました。メイントラックでも、既存のデータセットやベンチマークに対する問題提起をする論文が多く見られました。本記事でもいくつか取り上げます。
全体像
どのようなテーマの論文が採択されているのかを見るために、学会サイトで提供されていた論文マップを独断と偏見でグループ分けしてみました。
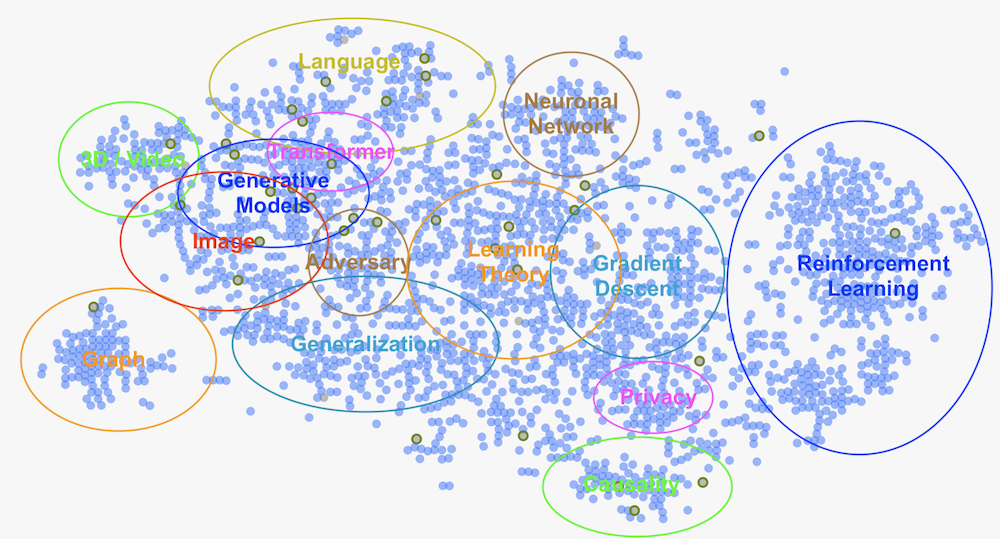
TransformerがLanguageとImageをまたぐような形で1つのクラスタを形成しているのが2021年らしいですね。
採択数
今年は9,122本が投稿され、そのうち2,344本が採択されました(採択率26%)。投稿数が前年から減少したのはここ数年で初めてでした。arXivに投稿される論文も2021年から減少に転じていますが、コロナ影響で研究活動が妨げられているのでしょうか。
査読品質の計測
今回のNeurIPSでは特別に、査読品質に関するおもしろい実験が行われていたので紹介します。
最近、「研究分野の急速な過熱のために査読の品質が落ちている」という言説を耳にするようになりました。これが本当なのかどうか調査するため、運営は投稿された論文の10%を独立した2つのチームに査読させ、判定がどのくらい一致するかを集計するという実験を実施しました。そして、その結果を前回の実験(2014年)と比較しました(詳しくは 公式ブログ を参照)。
不一致率は採択率によって変化する(下図; 同ブログより)ので、「与えられた採択率に従ってランダムに判定するベースライン」からの改善率で比較します。NeurIPS 2021のサンプル内での採択率は22.7%で、不一致率は23%でした。この採択率の下でランダムに選んだ場合の不一致率は35.1%なので、ランダムからの改善率は35%となります。
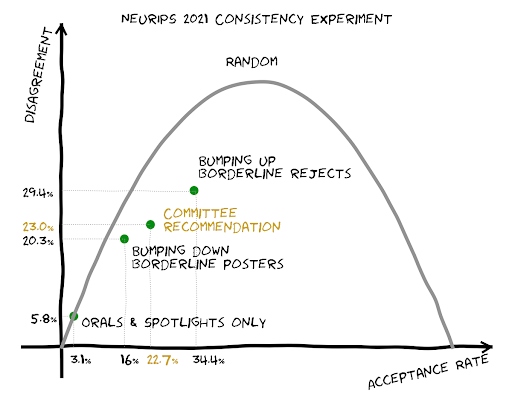
NeurIPS 2014における不一致率の改善率はというと、31%だったそうです。ということで、この実験からは査読品質が下がったという傾向を確認することはできませんでした。
ちなみに、「不採択となった論文をもう一度レビューすると採択される確率」は14.9%でした。
口頭発表
口頭発表には55本が採択されました。ここでは、個人的に興味を持った11本を紹介します。
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers
- 著者: Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, Zaid Harchaoui
- URL: https://proceedings.neurips.cc/paper/2021/hash/260c2432a0eecc28ce03c10dadc078a4-Abstract.html
AIが生成するテキストは繰り返しや論理的な誤りを含むことが知られています。しかし、こういった点を考慮して「人が書いたテキストとの近さ」を自動で評価する指標はありませんでした。現在もっとも広く使われている評価指標としてはパープレキシティ(perplexity)がありますが、これは言語モデルの性能評価であり、生成されたテキストの品質評価ではありません。
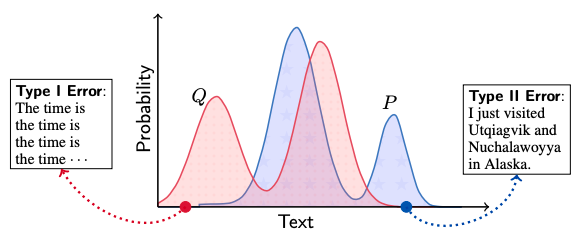
そこで本論文では、人が書いたテキストの分布 1をP、AIが生成したテキストの分布をQとおいて2種類の誤りについて考えます:
- 第一種の過誤(Type I Error): 人間らしくない文章を生成すること(
Pが小さいのにQが大きい部分) - 第二種の過誤(Type II Error): 人間らしい文章を生成しないこと(
Pが大きいのにQが小さい部分)
これらの両方を考慮することで、生成されたテキストの自然さと多様性を評価できます。
さて、2つの分布の差はKullback–Leiblerダイバージェンスで評価できますが、これらは分布の重なりがない部分で発散してしまいます。そこで、PとQを混合比λで混合した分布Rを考え、KL(Q|R)とKL(P|R)で「ソフトに」KLダイバージェンスを評価することにします。この2つの変数によって定義される点がλを0から1まで動かしたときに描く曲線(下図)の下部の面積を MAUVE と呼びます。これが本論文で提案する生成テキスト評価指標です。
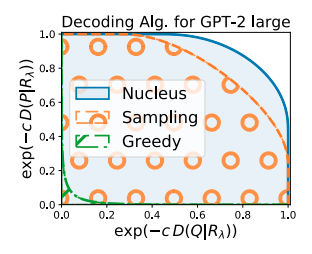
MAUVEの評価指標としての優位性は、人の評価との相関が既存の自動評価指標よりも高いという実験結果によって主張されています。実際、上図においても greedy < ancestral < nucleusというデコード時のアルゴリズムの性能の上下関係を正しく捉えられています。
Deep Reinforcement Learning at the Edge of the Statistical Precipice
- 著者: Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, Marc Bellemare
- URL: https://proceedings.neurips.cc/paper/2021/hash/f514cec81cb148559cf475e7426eed5e-Abstract.html
強化学習アルゴリズムの性能は点推定した結果(数回分のスコアの平均値や中央値)によって比較されることが一般的ですが、この方法では統計的な不確実性を考慮できません。しかも、近年はモデルを動かすための計算コストの増加により実験の回数自体も減少傾向にあり、不確実性が無視できない状況となっています。次の図は、いくつかの論文で報告されていた強化学習アルゴリズムの性能について、N=100のブートストラップ法によって推定された分布をプロットしたものです。どうやら報告値は「ラッキーな」ものであることが多いようです。
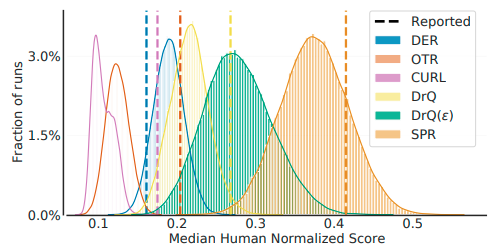
しかし、計算リソースが限られている中でむやみに実験回数を増やすことはできません。適度な回数で信頼性の高い評価をするために、本論文は3つの提言をしています。
- 点推定ではなく区間推定をすべし。上で見た通り、信頼区間を示すことは公平な比較のために重要です。論文では正規分布を仮定してブートストラップ法を用いています。
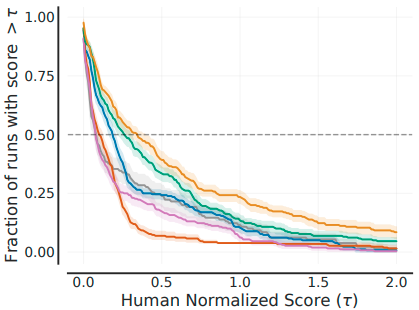
- 要約統計量だけではなく「性能のプロファイル」を出すべし。従来の「スコアの中央値を並べた表」では、分布の裾などの特徴が見えなくなってしまいます。著者らはプロファイルの一例として、横軸にスコア、縦軸にそのスコアを超えた試行の割合をプロットしたグラフ(下図)を提案しています。
- 序列を付けるときの要約統計量としてはIQMを使うべし。平均は外れ値に弱く、中央値はプロファイルのごく一部しか捉えられません(もし半数弱の試行が0点だったとしても中央値には影響しない)。一方、IQM2は分布の特性をよく表しながら信頼区間も狭く抑えられるという好ましい性質を持っています。
Alias-Free Generative Adversarial Networks
- 著者: Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, Timo Aila
- URL: https://proceedings.neurips.cc/paper/2021/hash/076ccd93ad68be51f23707988e934906-Abstract.html
StyleGAN2 の生成画像を注意深く観察すると、毛などのテクスチャが絶対座標に依存していることがわかります( 動画 で見るとわかりやすいです)。
本来は低解像度の特徴マップで顔が動いたら後段の特徴マップで目が追従し、さらに後段でまつげもそれに追従、というような階層関係を持っていてほしいのですが、ナイーブな生成器はある情報を乱用して階層をバイパスしてしまいます。その情報とは、アップサンプルと活性化のときに起こるエイリアシングによるアーティファクト3です。つまり、特徴マップの特定の座標ではエイリアシングによるアーティファクトが発生しており、それがテクスチャの生成に役立ってしまっているのです。
StyleGAN(2)のチームはこの問題を信号処理のテクニックで解決し、提案するネットワークをAlias-Free GAN(そして後にStyleGAN3)と名付けました。StyleGAN3は、特徴マップを連続信号として扱うようにダウンサンプリング層や活性化関数を再定義することでエイリアシングを防ぎます。例えばダウンサンプリング層なら、ローパスフィルタをかけてからダウンサンプルするといった具合です。これによって、テクスチャが絶対座標に依存してしまうが解決されました( 同動画 )。
さらに、学習した生成器の特徴マップを可視化してみると、StyleGAN2では見られなかった顔表面上の座標系のようなパターンが観察されました。これはまさに、最初に「持っていてほしい」と述べた階層構造です。

E(n) Equivariant Normalizing Flows
- 著者: Victor Garcia Satorras, Emiel Hoogeboom, Fabian Fuchs, Ingmar Posner, Max Welling
- URL: https://proceedings.neurips.cc/paper/2021/hash/21b5680d80f75a616096f2e791affac6-Abstract.html
短い割に難解なタイトルの論文ですが、本論文は一言で言うと「n次元座標を取り扱える生成モデル」を提案しています。主な実用先は分子(おのおの座標を持つ原子の集まり)なので、とりあえずは分子生成モデルだと理解して問題ありません。
さて、3次元以上の空間で座標を持つデータを生成しようとすると、2次元よりも自由度が大きいために生成モデルの学習が難しくなります。そこで、対称性に基づく何らかの制約を課したいという動機が生まれます。その制約というのが、タイトルにあるE(n)同変性(E(n) equivariance)です。ここで、E(n)(変換)とはn次元Euclid空間での等長変換(並進、回転、鏡映)のことです。同変性(equivariance)とは、入力にある変換を施したときに出力も同じように変換されることです。ちなみに、出力が変わらない場合は不変性(invariance)と呼びます。下図に2つの概念のイメージを描きました(筆者作成)。
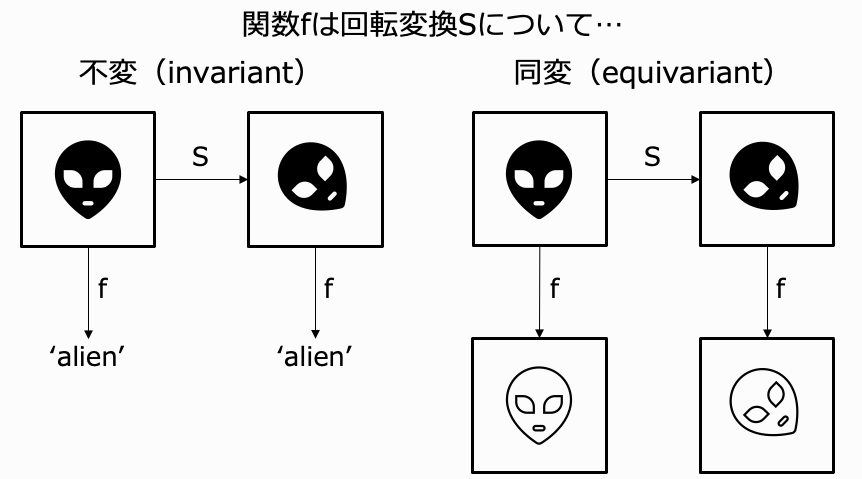
タイトルで次に出てくる正規化フロー(normalizing flow)は生成モデルの一種で、潜在変数とデータとの間を可逆な変換で繋いだものです。ここまで来てようやく、「この論文はE(n)同変な正規化フローを提案している」ということが説明できました。これ以上の手法の詳細に興味のある方は元論文か こちらのスライド 4をご参照ください。
最後に、潜在変数から徐々にノード(原子)の座標と特徴量を生成していく様子を示します。
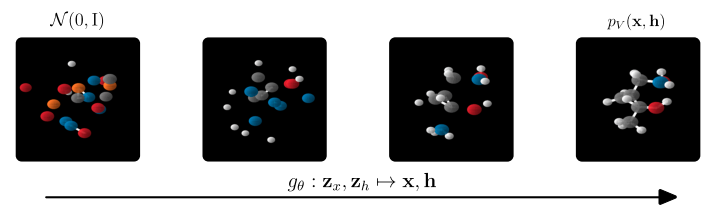
Unsupervised Speech Recognition
- 著者: Alexei Baevski, Wei-Ning Hsu, Alexis CONNEAU, Michael Auli
- URL: https://proceedings.neurips.cc/paper/2021/hash/ea159dc9788ffac311592613b7f71fbb-Abstract.html
従来の音声認識モデルの学習には音声データとその書き起こしのペアが必要なため、世界で話されている言語のごく一部にしか適用できませんでした。そこで著者らは、教師ラベルを使うことなく敵対的学習(adversarial training)で訓練できる音声認識モデル、wav2vec Unsupervised(wav2vec-U)を提案しました。このモデルは次のようにして訓練されます。
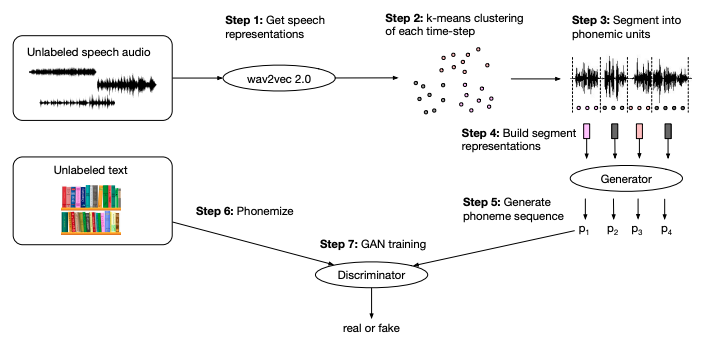
- 音声信号をwav2vec 2.0 5で埋め込む
- 1の埋め込みをk平均法でクラスタリング(結果は音素と対応)
- 2で得られたクラスタで元の音声信号を音素ごとに分割する
- 1の埋め込みを分割した単位ごとに集約し、音素の表現ベクトルを得る
- 4の音素表現から音素列を生成する
- (1とは無関係の)テキストを音素列に変換する
- 5の「生成された音素列」と6の「本物の音素列」とを識別器に分類させる(敵対的学習)
ここで、生成器と識別器はCNNで実装されています。
学習の結果、wav2vec-Uはタタール語やキルギス語といった低リソース言語において教師ありの手法に近い音素誤り率を達成しました。
Partial success in closing the gap between human and machine vision
- 著者: Robert Geirhos, Kantharaju Narayanappa, Benjamin Mitzkus, Tizian Thieringer, Matthias Bethge, Felix A. Wichmann, Wieland Brendel
- URL: https://proceedings.neurips.cc/paper/2021/hash/c8877cff22082a16395a57e97232bb6f-Abstract.html
画像系タスクのベンチマークでNNが人間を超えることはもはや珍しくありませんが、NNは分布外のデータ(OOD; out of distribution)に対してしばしば脆弱です。そこで著者らは、これまで提案されてきた「優れたモデル」たちがOODに対してどう振る舞うかを精査しました。
まず、OODに対する正解率という観点ではNNは人間にかなり近づいていると言えます。Noisy StudentやVision Transformerのように人間を超えるモデルも登場しています。
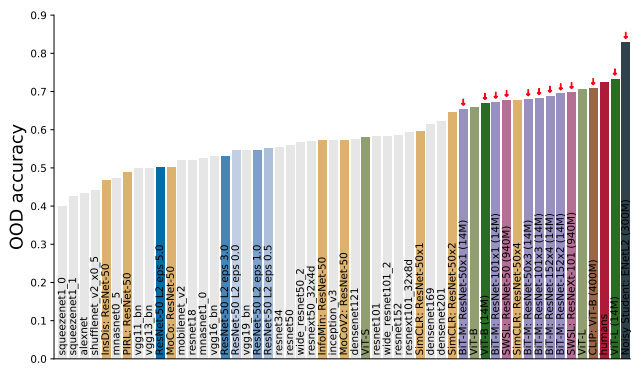
しかし、間違いのパターンが人に似ているかという観点ではまだ人間には及びません。
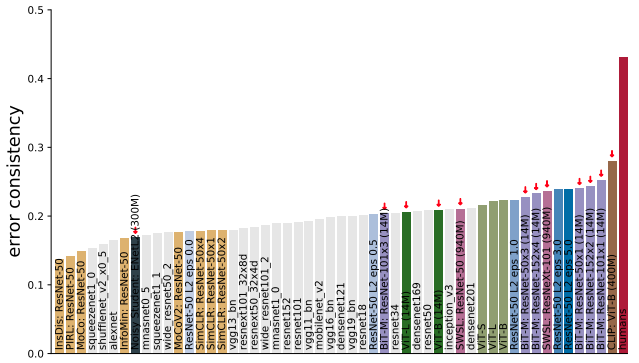
そして、いずれの観点でも、学習データが多いほど人間に近づくという傾向が見られました。大局的に見れば、学習方法(教師あり、自己教師など)やアーキテクチャよりもデータの量が効いているということが言えそうです。
また、CLIP 6はいずれの観点においても高いスコアを示しており、注目に値します。この要因はどこにあるのでしょうか?論文では次のように論じられています。
- 仮説1: 大量のデータで学習したから?―しかし、3億枚の画像で学習したNoisy Studentは間違いのパターンが人と似ていないので、これはおそらく違うでしょう。
- 仮説2: データの品質が良いから?―確かにNoisy Studentは疑似ラベルを使用していますし、ImageNetのラベルの6%は誤りという分析もあります。しかし、CLIPで生成したImageNetの疑似ラベルでResNetを訓練してもOODへの頑健性は向上しなかったので、これもおそらく違うでしょう。
- 仮説3: 画像とテキストのペアで学習しているから?―確かにViT-BのCLIPはOODに強いですが、ResNet-50のCLIPは弱いので、これだけでは説明できません。しかし、目的関数とアーキテクチャの組み合わせが要因となっている可能性は高いでしょう。
Learning Debiased Representation via Disentangled Feature Augmentation
- 著者: Jungsoo Lee, Eungyeup Kim, Juyoung Lee, Jihyeon Lee, Jaegul Choo
- URL: https://proceedings.neurips.cc/paper/2021/hash/d360a502598a4b64b936683b44a5523a-Abstract.html
深層学習モデルの予測はバイアス属性の影響を受けやすいことが知られています。バイアス属性というのは、例えば鳥にとっての「青空」のように、本当は無関係だが共起することが多いために予測に影響してしまう「見かけ上の相関」のことです。これに対処するためには、訓練データにバイアス属性と異なるサンプル(例:地上を歩く鳥)を多く含められればいいのですが、このようなデータを大量に集めるのは一般に困難です。
そこで著者らは、特徴量レベルでのデータ拡張を提案します。具体的な方法は次の通りです。まず、データの内在的な(intrinsic)特徴量とバイアス特徴量のそれぞれを扱うためのエンコーダと分類器を用意します。これを Namらの方法 で学習させると、内在的な特徴量とバイアス特徴量をうまく分離できます。そして、学習過程で2種類の特徴量のいずれか一方を他のサンプルと置き換えることで、バイアスに逆行する状況を再現できます。
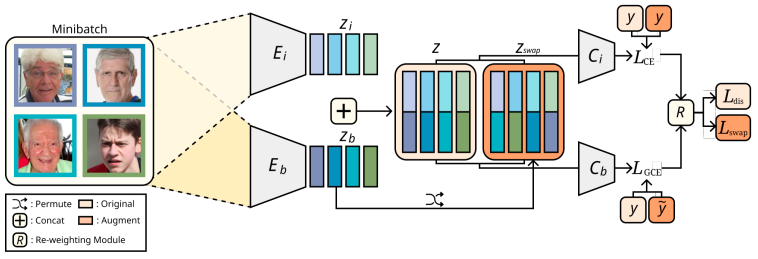
Retiring Adult: New Datasets for Fair Machine Learning
- 著者: Frances Ding, Moritz Hardt, John Miller, Ludwig Schmidt
- URL: https://proceedings.neurips.cc/paper/2021/hash/32e54441e6382a7fbacbbbaf3c450059-Abstract.html
近年需要が高まっている機械学習の公平性の研究では、UCI Adultというベンチマークがよく用いられます。これは1994年に行われたセンサスの結果を元にしたもので、年齢、職業、人種、性別などの14の特徴から、その人の年収が5万ドル以上であるかどうかを当てるタスクです。しかし、このデータセットには次のような問題点があります:
- 25歳以上の人しかいない
- 元のセンサスデータの情報を使い切れていない
- 5万ドルという閾値の選び方に任意性がある
そこで、元のセンサスの結果をたどることで、公平性に関するいろいろなタスクを導けるデータセット集として、Folktablesを作成しました。Folktablesは上記の問題を解決したほか、次のような利点を持っています:
- 年収の生の値、雇用状況や通勤手段といった多様な予測タスクを含む
- 年をまたいだ追跡が可能
- サンプルサイズが大きい
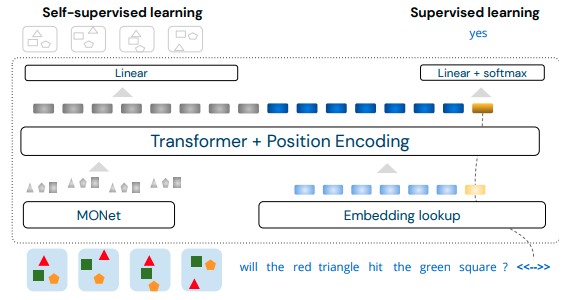
Attention over Learned Object Embeddings Enables Complex Visual Reasoning
- 著者: David Ding, Felix Hill, Adam Santoro, Malcolm Reynolds, Matt Botvinick
- URL: https://proceedings.neurips.cc/paper/2021/hash/4c26774d852f62440fc746ea4cdd57f6-Abstract.html
visual reasoningとは、与えられた画像の情報について質問に答えるタスク群のことです。例えば、次の画像について「大きい物体の数と光沢のある物体の数は等しいか?」といった質問がなされます。

このようなタスクは、画像から物体を認識するだけでなく、それらの関係を理解する必要があるため、一般的な画像認識タスクよりも一段階難しいとされています。他にも、複数の画像から因果関係を導いたり、力学系シミュレーションのような未来の予測を動画から行ったりといったタスクがあります。
本論文では、visual reasoningの様々なタスクを解けるシンプルなネットワークとして「ALOE(attention over learned object embeddings)」を提案します。図のように、ALOEは連続したフレームと質問文を入力として受け取ります。フレームはMONet6でオブジェクトに分け、質問文は埋め込んだ上で、両者をTransformerバックボーンに入力します。そして、出力が次のタイムフレームと質問への回答になるという仕組みです。
Learning to Draw: Emergent Communication through Sketching
- 著者: Daniela Mihai, Jonathon Hare
- URL: https://proceedings.neurips.cc/paper/2021/hash/39d0a8908fbe6c18039ea8227f827023-Abstract.html
従来のコミュニケーション創発(emergent communication)の研究は「文字列によるコミュニケーション」に関するものがほとんどでした。本論文では、文字のルーツが先史時代で壁画に描かれたような絵だったことを考慮して、「絵によるコミュニケーション創発」が可能かどうか実験によって調べました。
ゲームのルールは次の通りです。送信者Aは、自分が見ている画像をスケッチに表現します。受信者Bはスケッチを受け取り、候補画像のうちどれがAの見ているものかを推測します。画像は全く同じもの、あるいは同じクラスの別画像です。BがAに接触することはできません。
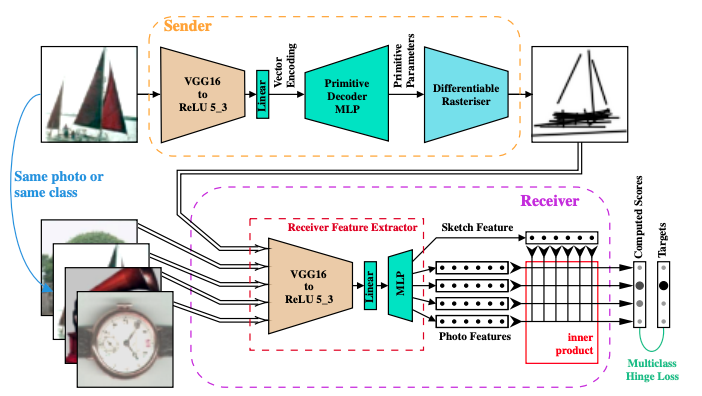
AとBはNNで実装されており、ゲームを通じて予測の間違いを最小化するように学習されます。
さて、スコアが収束するまでゲームを続けたところ、Aの描くスケッチは下図のようになりました。ナイーブにゲームを実行すると原型を留めないスケッチとなってしまいましたが、知覚損失(perceptual loss)を加えると解釈性が高くなりました(特に船の絵)。

Learning with Noisy Correspondence for Cross-modal Matching
- 著者: Zhenyu Huang, Guocheng Niu, Xiao Liu, Wenbiao Ding, Xinyan Xiao, Hua Wu, Xi Peng
- URL: https://proceedings.neurips.cc/paper/2021/hash/f5e62af885293cf4d511ceef31e61c80-Abstract.html
最近、自動収集によって得られた画像・テキストのペアからなる大規模データセットを使った研究が盛んになっていますが、このようなデータセットは概して多くのノイズを含みます。人は画像から自明に読み取れることをわざわざ書かないものです。

本論文ではこのようなノイズペアの検出に、NNの「学習過程の最初に典型パターンを学習し、その後ノイズに適合していく」という性質を用います。そして、検出されたノイズを修正することで、マルチモーダルなモデルの精度を改善することに成功しました。
おわりに
本記事では、NeurIPS 2021の学会全体と口頭発表について書きました。後編ではスポットライト発表、ポスター発表、チュートリアルについて書きます。お楽しみに。
一緒に働きませんか?
弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。

機械学習エンジニア
Shion Honda
好きな技術は深層学習、得意料理はベーグルです。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


