
はじめに
機械学習エンジニアの荒居秀尚です。2021年に入社したばかりの新卒で、機械学習モデリングや機械学習を用いたデータ施策におけるMLOps推進などに携わっています。
最近、担当案件で画像を扱っていたのもあり、画像を対象とした自己教師あり表現学習について調査していました。今回はその調査内容について紹介したいと思います。なお、この調査は文献調査と、実際に使ってみて案件への適用可能性を評価した実験とに分かれていますので、ブログの方も両方について触れようと思います。分量が多いため、自己教師あり学習の基礎の部分の紹介、具体的な手法の紹介、そして応用例の紹介の三部立ての構成になっています。
今回はまず自己教師あり学習の基礎の部分の解説を行っていこうと思います。
画像を対象とした自己教師あり表現学習
背景
近年、Deep Learningの技術発展やコンピュータの性能向上、フレームワークの充実などにより、画像を対象とした教師あり学習技術は飛躍的に発展しました。産業への応用も進み、自動運転・リモートセンシング・設備の外観検査・文書の電子化など、今では様々な領域で画像を用いた機械学習手法が活躍しています。
一方で、このように飛躍的な発展を遂げた結果、新たな課題も出てきています。その中で、とりわけ大きな問題として今でも研究の最先端で扱われているのが、「人手によるアノテーションが足らずボトルネックになってしまう」問題です。
教師あり学習はその名の通り、教師データ(データと教師ラベルのペア)を必要としますが、ラベルづけは人手で行う必要があります。このラベルづけの作業はアノテーションと呼ばれますが、非常に負荷が高い作業であり、多くの時間とコストがかかります。特に医用画像などラベルづけに専門知識を要するデータや、セグメンテーション(領域分割)など複雑なラベルが必要なタスクほどラベルは不足する傾向にありますが、アノテーションのコストが高いことによってそれらのデータ・タスクに教師あり学習を適用しづらい状況になりがちである、というのがこの「人手によるアノテーションが足らずボトルネックになってしまう」問題です。
この問題には、今も多くの研究者が様々なアプローチで取り組んでいます。今回紹介する、自己教師あり表現学習もこの問題に対処するためのアプローチとして有力視されているものの一つです。この記事では具体的な手法や、その理論的背景について解説を行なって行きますが、その前に自己教師あり表現学習の一般的な話について触れます。
表現学習
「自己教師あり表現学習」の中には「表現学習」という言葉が含まれています。まずは、この表現学習について簡単に説明します。
表現学習とは、“Representation Learning: A Review and New Perspective”1によれば、「分類器や他の予測器を構築する際に、予測に重要な情報を抽出しやすくするようにデータの表現を学習すること」を表します。
画像や自然言語の文章、音声といったデータはそれだけで大量の情報を含んでいますが、機械学習タスクにおいて必要になる情報というのはその中のごく一部です。例えば、音声認識のタスクにおいて背景の雑音の情報は不要ですし、画像中央に写っている木の種類を予測する物体認識のタスクにおいて、地面に落ちている葉っぱの数は不要な情報です。このように解きたい機械学習タスクを設定した場合に必要な情報というのはデータが保有している情報の一部ですので、データが、不必要な情報を削ぎ落としたような表現に変換されていた方が学習がうまく進みやすいです。
どのような情報が不必要か、というのはタスクによって異なるわけですが、よくある機械学習タスク2において必要となる情報には共通している部分が多く、逆に言えばどのような情報が不必要かという点でも共通部分は大きいです。したがって、よくある機械学習タスクにおいて有用な情報を残し他の不必要な情報を削ぎ落としたデータの表現が得られれば、様々な後流のタスクにその表現を活かせるのです。そのようなデータの表現を学習によって獲得しよう、というのが「表現学習」です。
表現学習の手法は数多く存在します。例えば、画像認識においては「ImageNetで学習された画像認識モデル」を目的のタスクに合わせて追加で学習することにより、必要なラベル量が少なくても良いモデルが得られることが広く知られていますが、これは画像認識モデルをImageNetで学習することで様々なタスクで役立つ表現を学習していることになるので、表現学習の一種と言えるでしょう。この場合はImageNetというデータセットに含まれる(画像, 教師ラベル)を利用しているため、「教師あり表現学習」になります。
今回紹介する自己教師あり学習も、様々なタスクで役立つ表現を学習するための方法の一つです。
自己教師あり学習
前節では、教師ありの表現学習について触れましたが、自己教師あり学習は教師なしの表現学習手法、すなわち教師ラベルを使うことなく様々なタスクに有用な表現を学習する手法です。しかし、「教師あり」という言葉が名前に入っているように、教師あり学習と同じように何らかの予測タスクを解くことでよい表現を獲得することを目指します。
自己教師あり学習では、実際に解きたいタスクの教師ラベルは用意しませんが、データそのものから作成できるラベルを用意し、それを予測する事前学習タスク(pretext task)を解きます。例えば、文章中の単語をランダムに選んでマスクしてしまい、周辺の単語からマスクされた単語を予測することで単語の表現を学習する、といったように入力データ(画像・自然言語・音声, etc.)と変換(e.g. 単語をマスクする)のみから作ることができるラベルを用いるのが自己教師あり学習です。
自然言語処理の世界では、2013年に発表されたWord2Vec3や2018年のBERT4など、画像(コンピュータビジョン)に先行して発展していましたが、画像においては最近まであまりいい表現が得られないなど課題が多い表現学習手法でした。しかし、近年、対照学習(Contrastive Learning)と呼ばれる方法論や、対照学習の課題を解決した発展手法の登場などにより、自己教師あり学習で学習した重み(ニューラルネットのパラメータのこと)を用いてわずかな教師ラベルのみ学習した後流のモデルが、大規模なデータセットで教師あり学習で学習したモデルに匹敵する性能を出すようになってきています。
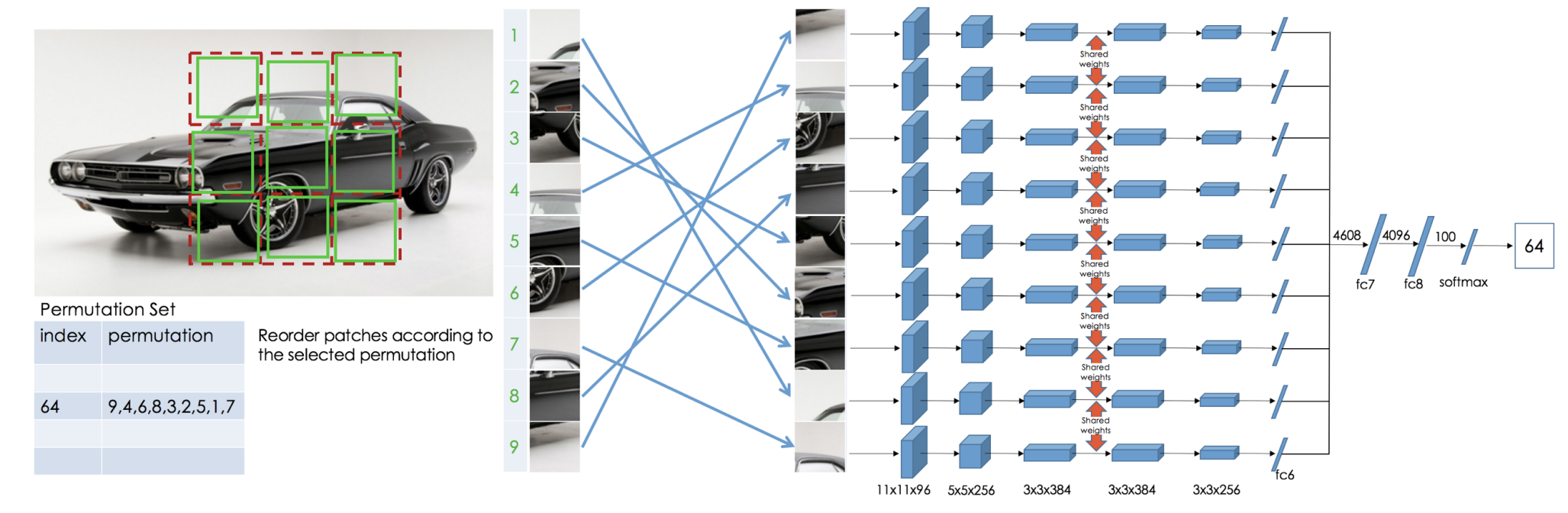
今回紹介する自己教師あり学習の手法は対照学習の隆盛以降のものになりますが、それ以前の手法には画像をパッチに切り出した上でランダムにパッチを並び替え、元のパッチの並びを予測するJigsaw Puzzle5や、カラー画像をグレースケール変換した上で色つけ問題を解くColorful Image Colorization6などがあります。
一方、対照学習やその発展手法では、画像にデータ拡張(Data Augmentation)をかけた上で、元の画像とデータ拡張後の画像の特徴表現が近くなるように学習を行います。対照学習ではさらに、元の画像とは異なる画像を負例として用い、元の画像と負例画像の特徴表現が離れるように学習を行います。
変換をかけたデータと元のデータを比較することで何を行っているのでしょうか?これは「ある変換をかけたときに、かけた変換に対して表現が不変である、という知識を与えている」ことに相当します。教師あり学習では、ラベルという形で人間の知識を与えていましたが、自己教師あり学習では変換を加えることで人間の知識をモデルに与えているのです。
画像の自己教師あり学習手法の部品となる技術
ここでは、画像の自己教師あり学習手法を構成する部品となる技術に紹介していきます。近年の自己教師あり学習手法は、複数の手法で効くとわかった要素を組み合わせることで発展してきています。したがって、部品単位で先に理解しておくことでそれぞれの手法に対する理解が進みやすくなります。
Siamese Architecture
対照学習やその発展手法では、元の画像とデータ拡張をかけた画像の特徴を比較するようにして学習を進めていきます。したがって、元の画像から特徴を抽出するニューラルネット(以降はEncoderと呼びます)と、データ拡張をかけた画像の特徴を抽出するEncoderが必要になってきます。
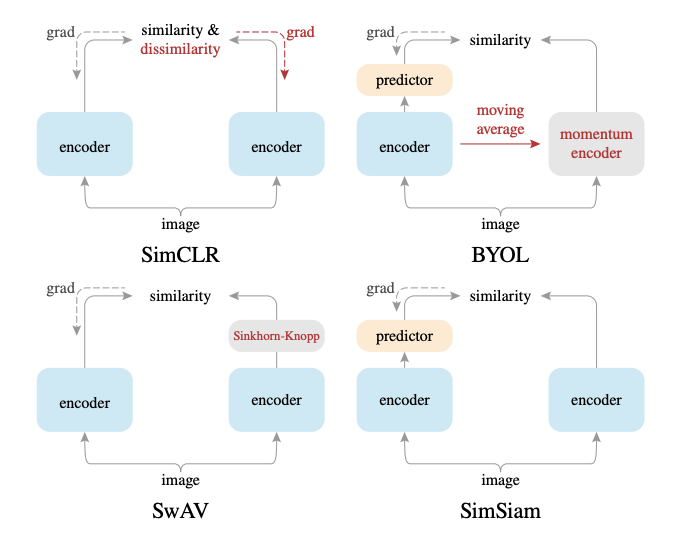
このように二つのEncoderを持つアーキテクチャをSiamese architecture(シャムアーキテクチャ)7と呼びます。Encoderには画像認識のモデルでよく用いられるようなResNet8などのアーキテクチャがよく用いられますが、ここでのポイントは二つのEncoderが用いられるということです。二つのEncoderは重みが共有されている、つまり全く同じものを使う場合もありますし、後述するように、片方のEncoderの重みがもう片方のEncoderの指数移動平均になっている場合もあります。
二つのEncoderを通して得られた特徴ベクトル(以降はEmbeddingと呼びます)はその後比較されます。ここで、単純に同じ画像に由来する特徴どうしを近づけるように学習をすると、どんな入力に対してもEncoderが同じ出力を返すようになる 崩壊(Collapse) と呼ばれる現象が起きてしまいます。近年の自己教師あり学習の手法は、この崩壊現象を起こさないような工夫を様々に凝らしています。これらの工夫をこの後紹介していきます。
Contrastive Loss
崩壊を防ぐ一つの工夫として、負例の利用があります。同じ画像に由来する二つの画像のEmbeddingを近づけるだけでなく、異なる画像に由来する二つのEmbeddingは遠ざけるように学習を行う、というものです。負例を利用して学習を行うものを対照学習(Contrastive Learning) と呼びます。
対照学習ではアンカーと呼ばれるサンプルと、アンカーサンプルと同じ画像に由来するサンプル(正例)、アンカーサンプルとは異なる画像に由来するサンプル(負例)が登場します。ここで、次のようにこれらのサンプルを表記することにします。
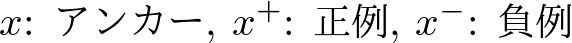
Contrastive Learningの目標は、任意のデータ点について次のような状態になるように、Encoderを学習することです。
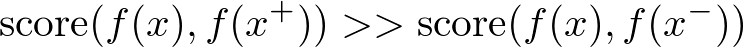
ただし、関数fはEncoderを表し、scoreは二つの特徴ベクトルの類似度を測る指標です。したがって上の式を言葉で表すならば、「アンカーサンプルと正例のEmbeddingの類似度が、アンカーサンプルと負例のEmbeddingの類似度と比べて遥かに大きい状態」ということになります。このような状態を目指すために、Contrastive LearningではInfoNCEと呼ばれる次のような損失関数やその亜種が用いられることが多いです。
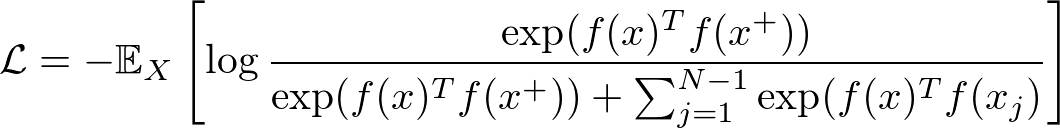
これは、先の類似性の指標として内積を用い、正例と負例を分類するようなsoftmax分類器用の損失関数とみなすことができます。式をじっくりと眺めてみると、この損失関数を小さくするためには、対数の中身を出来る限り大きくし1に近くなるようにする必要があることがわかります。対数の中身を大きくするには、分子を大きくしつつ、分母を小さくすればいいわけですから、アンカーと正例の内積が大きくなるようにしつつ、アンカーと負例の内積が小さくなるようにすればいいわけです。したがってInfoNCEの最小化をする事は、先に述べたContrastive Learningの目標と合致していることがわかります。
Data Augmentation
自己教師あり学習においてData Augmentationとは、表現がどのような変換に対して不変(invariant)であるか、という仮定をモデルに組み込む上でとても重要な要素です。SimCLR9では二つのEncoderに入力する画像に対してどのようなData Augmentationの組合せを用いると良いかを検証しています。
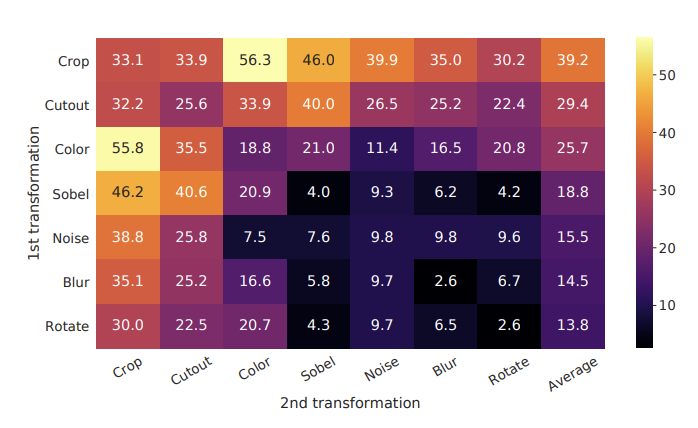

この検証では、Siamese architectureの片方にだけ常にData Augmentationをかけて学習を行い、Linear Evaluation10で評価を行っています。これによると、画像の一部を切り出すCropと画像の色を変化させるColor distortionの組合せが最終的なEmbeddingの質を最もよくする組合せだとわかりました。
当然ながら、タスク・データによっては有効なData Augmentationの組合せは異なる11はずですが、一般物体認識タスクにおいて自己教師あり表現学習や教師あり学習を行っていく上でこれは参考にすることができるでしょう。
Momentum Encoder
Siamese Architectureでは二つのEncoderを用いるという話を紹介しましたが、Momentum Encoderとはそのうち片方の重みについて、もう一つのEncoderの移動平均を取ったものを用いることを指します。数式で表せば、
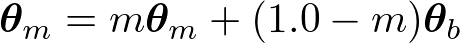
となります。ここで、添字がmのθがMomentum Encoderの重み(パラメータ)であり、添字がbのθがベースとなるEncoderの重みです。
PyTorchで実装してみた場合、以下のようにかなりシンプルに実装ができます。
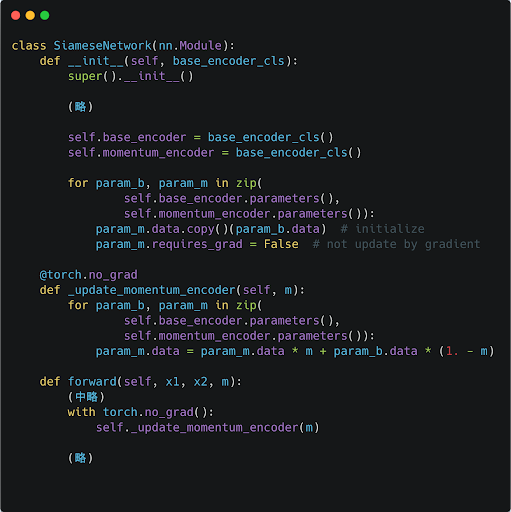
Momentum Encoderは、自己教師あり学習に限らず他の分野、例えば半教師あり学習手法であるMean Teacher12などでも用いられるような幅広い用途がある手法ですが、自己教師あり学習の文脈でもいくつかの手法の根幹をなすアイデアとなっています。
例えばMoCo13では、崩壊を防ぐために大量の負例をメモリバンクと呼ばれるバッファに入れておいて学習に利用しますが、負例全体に関してEncoderの重みを更新するのは計算量の関係で難しいため、負例サンプルからEmbeddingを得るためのEncoderとしてMomentum Encoderを用います。一方、BYOL14では負例を用いずに崩壊を防ぐために、Momentum Encoderが用いられています。この場合は、「片方のEncoderの出力がもう片方のEncoderの出力と大きく異なりすぎないようにしながらも異なってほしい」、というモチベーションでMomentum Encoderが使われています。
Clustering
対照学習が発展する以前から、Deep Learningとクラスタリングを組み合わせて表現学習を行うという試みは存在しました15。対照学習において、クラスタリングを用いるモチベーションには次のようなものがあります。
- インスタンス(サンプル)ごとに対比を行うやり方では、画像の局所的な特徴のみから対比ができてしまうため、画像全体の情報を用いなくても学習が進んでしまう。クラスタリングを行うやり方では、画像全体から得られる意味論的な構造を学習できる。
- インスタンスごとの対比を行う場合、意味的には本来似ているようなサンプルも負例として扱ってしまう。クラスタリングを行う場合、この問題を解決できる。
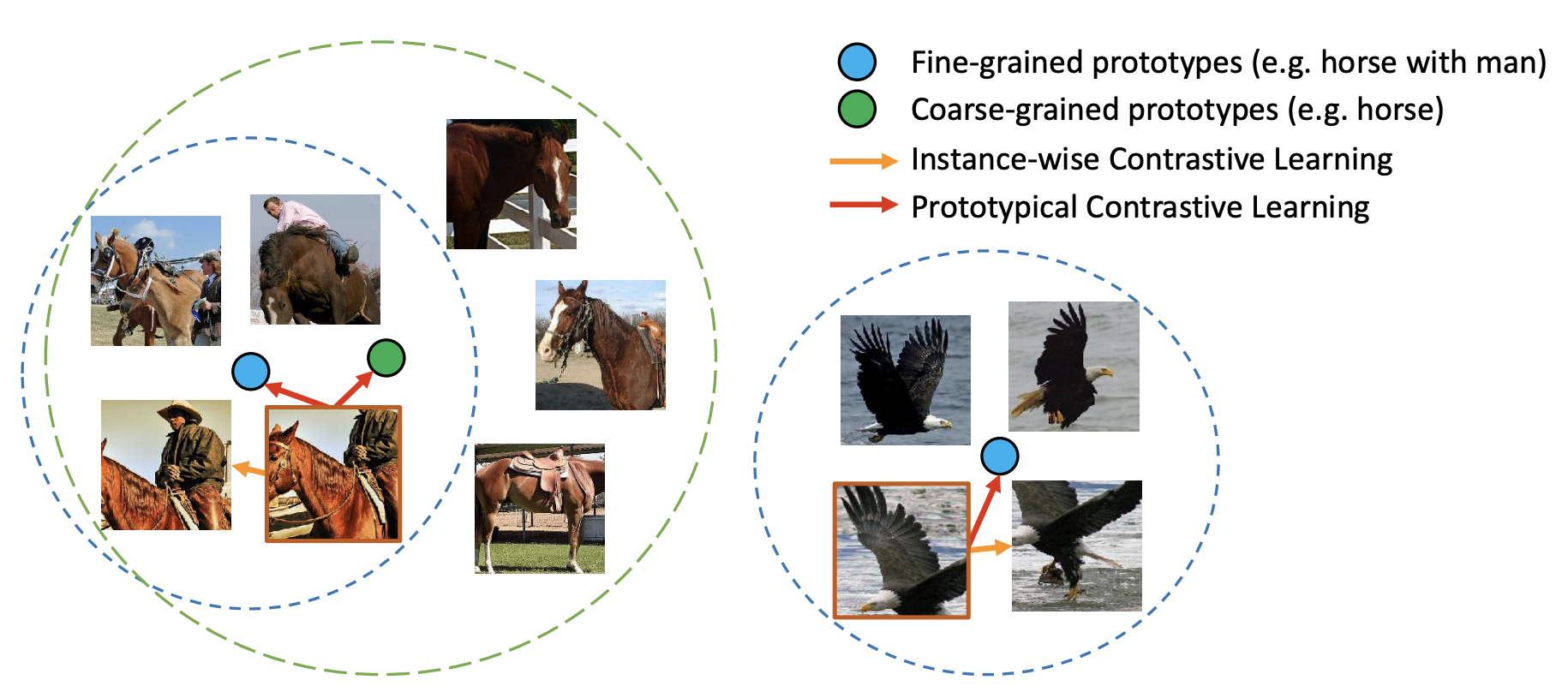
一般的な対照学習では、サンプルごとにEmbeddingを得た上でEmbeddingどうしで比較を行うように学習を行いますが、クラスタリングを用いる対照学習では、サンプルごとのEmbeddingをプロトタイプと呼ばれるクラスタ中心に近づけるようにしつつ、プロトタイプ間の類似度が下がるように学習を行っていきます。
上の図16はサンプルごと(Instance-wise)の対照学習とプロトタイプを用いる場合の対照学習の違いを表した模式図です。Instance-wiseの学習の場合、同じ画像由来の画像との類似度を高めるように学習が行われますが、プロトタイプを用いる場合は、クラスタ中心との類似度を高めるように学習が行われていく、という学習過程を表現しています。
Asymmetric Structure + Stop Gradient
対照学習の発展によって、画像に対する自己教師あり学習は大量のラベルなしデータがある場合に有効な手法となりました。しかし、対照学習は学習のために大量の負例を必要とし計算の負荷が大きかったり12、大きなバッチサイズを設定しないといけない8といった課題も出てきていました。
これを踏まえ、研究が進められた結果、近年では負例を必要としないで対照学習に比肩する性能を発揮できる手法が次々と提案されました。これらの手法では、Siamese Archtectureの二つのEncoderブランチを非対称な構造にすること、片方のブランチについては勾配逆伝播を止めてしまい別の方法で更新を行うことが崩壊を防ぐ上で有効であると紹介されています17。
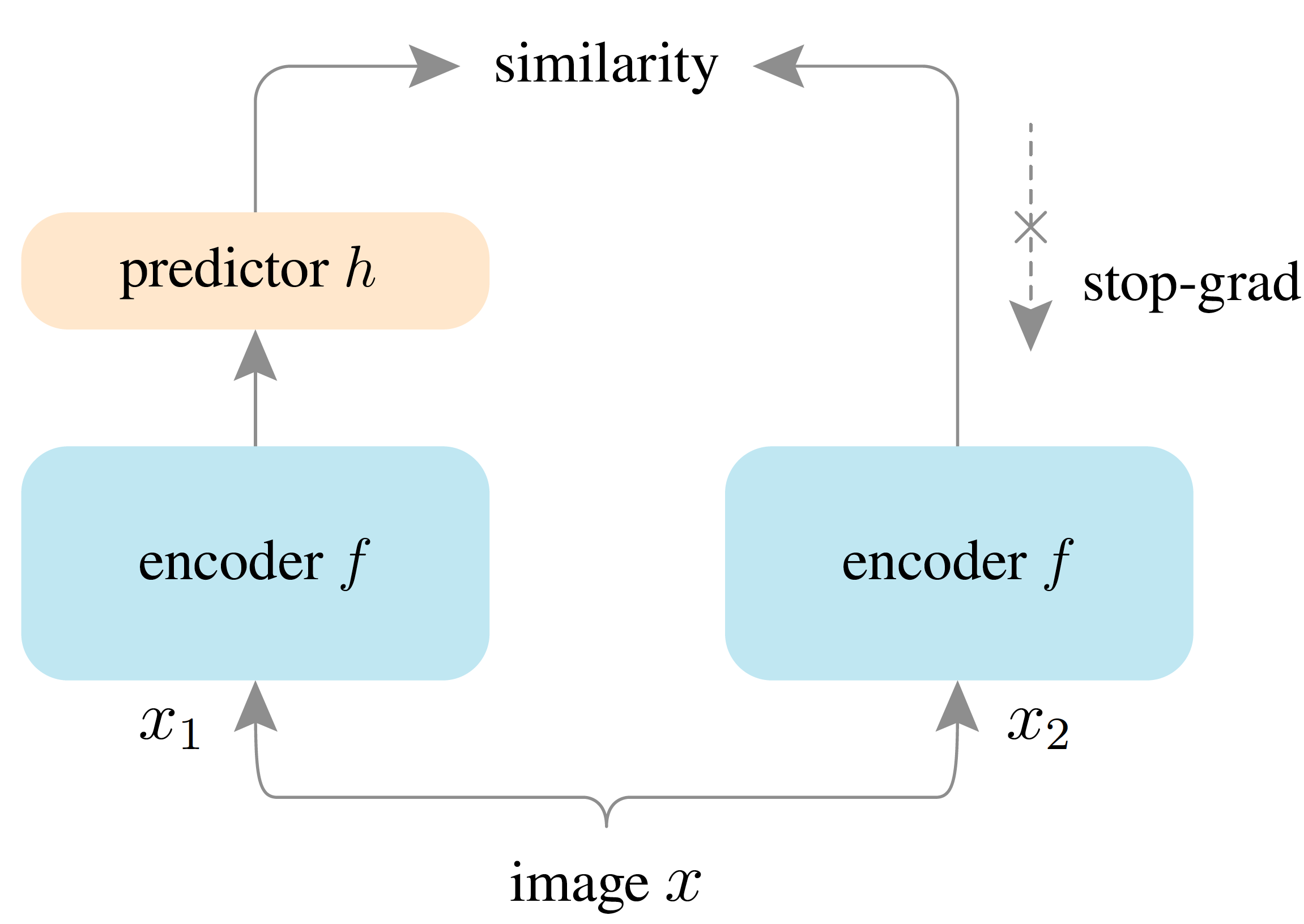
二つのEncoderを非対称な構造にする、とは上図のように片方のEncoderの出力をpredictorと呼ばれる別のニューラルネットワーク(通常はMLP)に通してから、もう一方のEncoderの出力のEmbeddingと比較するように学習することを表しています。また、predictorがない方は勾配を伝播させないことも重要だったとのことです。この場合、勾配が伝播されない方のEncoderはどのようにして学習するのか、と気になる方もいるかもしれませんが、
- 重みを共有したEncoderを両方に用いた上で、片方のEncoderを通ったデータに関しては勾配を計算しない
- 片方のEncoderはMomentum Encoderを使うようにして、直接の更新を避ける
の2パターンで学習が行われます。
なお、実装の上では、2つのバッチを受け取ったときに片方をPredictorがついている方のブランチに入れもう片方はStop Gradientが効いている方のEncoderに入れる、といったようにするのではなく下図のように、どちらのバッチも両方のブランチを通るようにします。
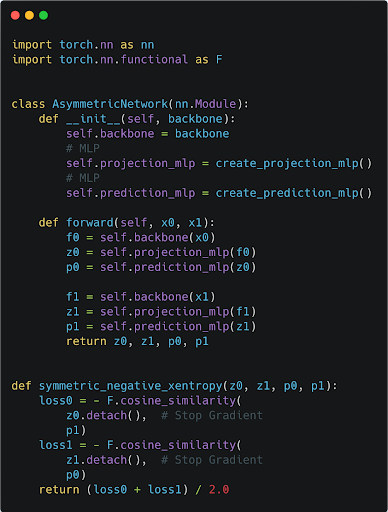
少しややこしいので、個別に解説をします。まず、forward()メソッドはx0とx1という2つのバッチを受け取ります。x1はx0に含まれる各データ点についてData Augmentationがかけられたものになっています。
# 入力は二つのバッチ
def forward(self, x0, x1):
...
この中では、二つのバッチをそれぞれEmbeddingに変換する処理が入っていますが、その時、projection_mlpの出力(Stop Gradientが入っている方のブランチの出力)とprediction_mlpの出力(Predictorがついている方のブランチの出力)を両方のバッチに対して計算しています。
def forward(self, x0, x1):
# バッチx0に関して2種類のEmbeddingを得たい
f0 = self.backbone(x0) # 畳み込みニューラルネットワークの出力
z0 = self.projection_mlp(f0) # Stop Gradientがある方のブランチの出力
p0 = self.prediction_mlp(z0) # Predictorの出力
# バッチx1に関して2種類のEmbeddingを得たい
f1 = self.backbone(x1) # 畳み込みニューラルネットワークの出力
z1 = self.projection_mlp(f1) # Stop Gradientがある方のブランチの出力
p1 = self.prediction_mlp(z1) # Predictorの出力
return z0, z1, p0, p1
そして損失関数を計算するときに、z0とp1、z1とp0を比較するように計算を行うことで、両方のバッチが両方のブランチを通って来るようにすることができます。これにより効率よく学習を行うことができます。
def symmetric_negative_xentropy(z0, z1, p0, p1):
loss0 = - F.cosine_similarity(
z0.detach(), # Stop Gradient
p1
)
loss1 = - F.cosine_similarity(
z1.detach(), # Stop Gradient
p0
)
return (loss0 + loss1) / 2.0
おわりに
ここまでの話をまとめます。
画像を扱う教師あり学習手法は近年大きく発展しましたが、その一方で膨大なデータに対して人間がアノテーションを行う時間的・金銭的コストが追いつかなくなってきています。これに対して、教師情報を用いずに画像の表現を学習することで、必要なラベルの数を大きく抑えることができる自己教師あり学習の手法が発展してきました。
初回の今回はこれまでに発展してきた自己教師あり学習手法の部品となっている様々なテクニックについて紹介しました。これらのテクニックを組み合わせることで、それぞれの自己教師あり学習手法を構成することができます。次回は様々な自己教師あり学習手法について紹介を行います。
We are Hiring!!
弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。
===========================
株式会社リクルート 中途採用サイト リクルート 学生向けキャリアサイト
===========================
-
Bengio, Yoshua, Aaron Courville, and Pascal Vincent. “Representation learning: A review and new perspectives.” IEEE transactions on pattern analysis and machine intelligence 35.8 (2013): 1798-1828. ↩︎
-
例えば画像であれば画像中の物体の種類を当てる「物体認識」、物体を囲う矩形の位置と種類を当てる「物体検出」、物体が占める領域と種類を当てる「領域分割」など ↩︎
-
Mikolov, Tomáš, Wen-tau Yih, and Geoffrey Zweig. “Linguistic regularities in continuous space word representations.” Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies. 2013. ↩︎
-
Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018). ↩︎
-
Noroozi, Mehdi, and Paolo Favaro. “Unsupervised learning of visual representations by solving jigsaw puzzles.” European conference on computer vision. Springer, Cham, 2016. ↩︎
-
Zhang, Richard, Phillip Isola, and Alexei A. Efros. “Colorful image colorization.” European conference on computer vision. Springer, Cham, 2016. ↩︎
-
Chen, Xinlei, and Kaiming He. “Exploring simple siamese representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. ↩︎
-
He, Kaiming, et al. “Deep residual learning for image recognition. CoRR abs/1512.03385 (2015).” (2015): 646-661. ↩︎
-
Chen, Ting, et al. “A simple framework for contrastive learning of visual representations.” International conference on machine learning. PMLR, 2020. ↩︎
-
学習された後のEncoderの重みを凍結した上で、最終層に一層だけ線形層をつけて学習を行い分類精度を評価すること。学習されたEncoderから得られるEmbedding空間でそれぞれの画像のクラスが線形分類しやすいようにクラスタに分かれていると分類精度も高くなるため、教師情報を与えずに学習したEmbeddingがどの程度後流のタスクに有用かを測る手法としてよく用いられる。 ↩︎
-
医用画像などにおいては一般物体認識のデータセットで学習された事前学習済み重みがあまり有効ではない、といった話もありドメインが大きく異なる場合にはこの方法論は通用しない可能性があります。 ↩︎
-
Tarvainen, Antti, and Harri Valpola. “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.” Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017. ↩︎
-
He, Kaiming, et al. “Momentum contrast for unsupervised visual representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. ↩︎
-
Grill, Jean-Bastien, et al. “Bootstrap your own latent: A new approach to self-supervised learning.” arXiv preprint arXiv:2006.07733 (2020). ↩︎
-
Caron, Mathilde, et al. “Deep clustering for unsupervised learning of visual features.” Proceedings of the European Conference on Computer Vision (ECCV). 2018. ↩︎
-
Li, Junnan, et al. “Prototypical contrastive learning of unsupervised representations.” arXiv preprint arXiv:2005.04966 (2020). ↩︎
-
Chen, Xinlei, and Kaiming He. “Exploring simple siamese representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. ↩︎

旅行・飲食・SaaSデータの分析・モデリングなど
Hidehisa Arai
新卒でリクルート入社。Kaggle Grandmaster。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


