
はじめに
こんにちは!
2021年4月にデータスペシャリストとして新卒入社しました高橋寛武と申します。
今回は、11月中旬に終了したkaggleのchaii - Hindi and Tamil Question Answeringというコンペティションにソロで参加して943チーム中12位を獲得することができたので、取り組みなどをご紹介しようと思います。今回のコンペティションでは11位までが金メダルだったため、本当にあと一歩足りなかったのですが、金メダル獲得に何が足りなかったのかという観点も合わせてご紹介できればと考えています。(金メダルを獲得できていれば、初めてのソロでの金メダルということになり、kaggle grandmasterに大きく近づくことができました、、泣)
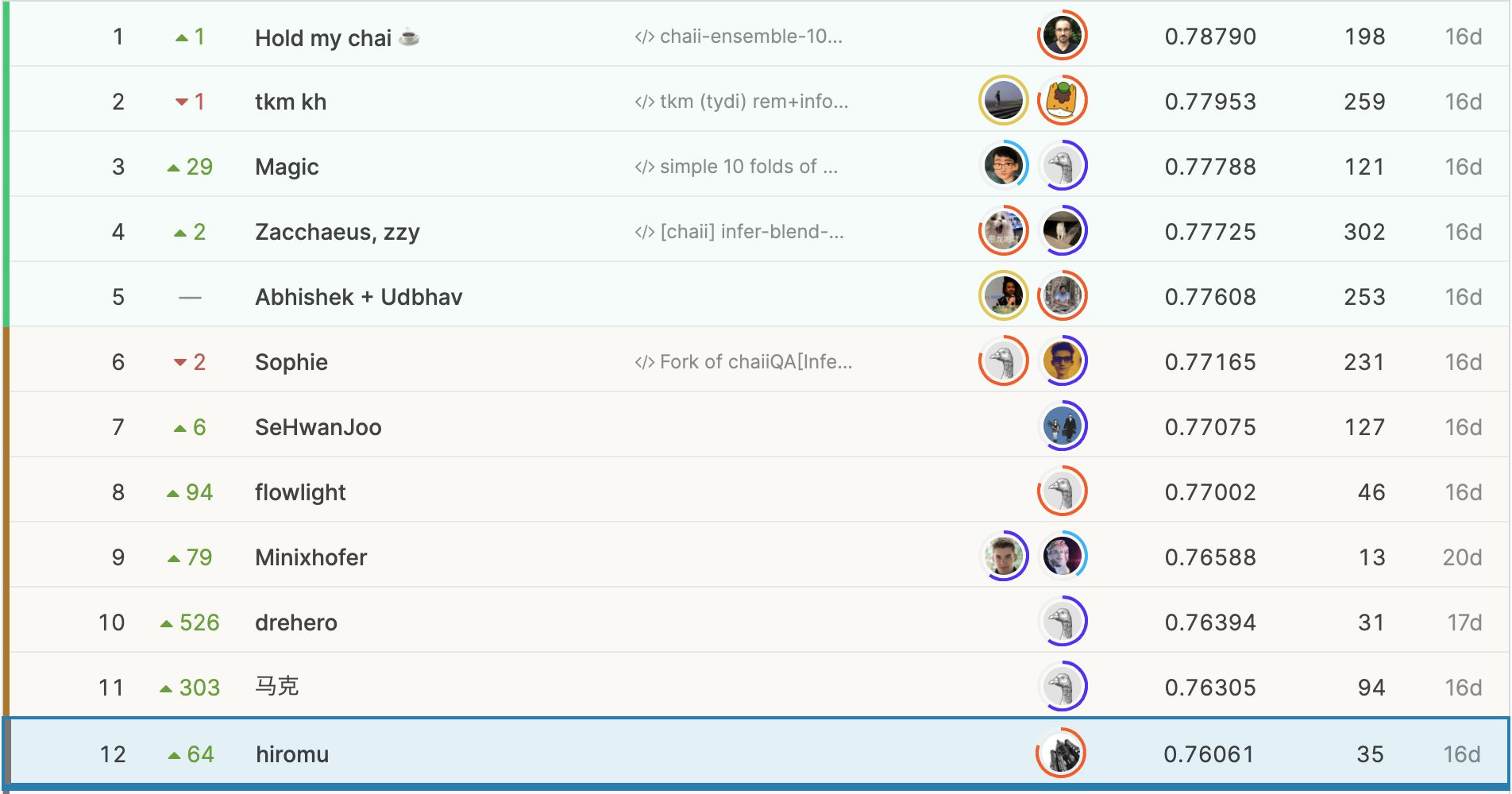
順位の右に表示されている数値が、参加中に確認できる順位と最終順位がどれくらい違ったかを表しています。500位以上上がっている人がいることから分かる通り、変動が大きく難しいコンペティションでしたが、なんとか上位に食い込むことができました。
- コンペティションURL: https://www.kaggle.com/c/chaii-hindi-and-tamil-question-answering
- kaggleに投稿した解法: https://www.kaggle.com/c/chaii-hindi-and-tamil-question-answering/discussion/288058
コンペティションについて
参加しようと思ったきっかけ
私は、過去に自然言語処理のコンペティションで上位入賞したことがあり、このコンペティションにも興味を持ちました。しかし、データを見ると全く読めない言語(ヒンディー語、タミル語)が表示されており、どうやってアプローチしていけばいいのかと困惑したことを覚えています。(参加チームが1000チームに満たなかったのは、他の人も同じような感想を持ったからかもしれません。)
過去にkaggleで開催された自然言語処理のコンペティションは、ほぼ全て( 2020のJigsawコンペティション を除く)が英語を対象にしたものであり、英語以外の特定の言語だけを扱うコンペティションは今回が初めてでした。なぜ、英語以外を扱うコンペが開催されたのか不思議に思い、 コンペティションの説明ページ を確認しました。
その内容を要約すると、
ヒンディー語とタミル語は、人口が世界で2番目に多いインドで話されているため話者が多いが、英語と比べると言語モデルの性能が低く、ウェブアプリケーションなどにも十分に応用できていないというのが現状である。そのため、このコンペティションを通じて参加者が優れたモデルを作成することができれば、多くの人のウェブ体験を向上させることができます。
というものでした。私は参加するコンペティションを選ぶ際に自分の取り組みが多くの人の役に立つものなら嬉しいと思っていたことや英語以外の言語でも今までの経験が応用できるのか気になったということもあり、参加することを決めました。
- kaggle profile: https://www.kaggle.com/hiromoon166
タスク
今回のコンペティションのタスクは、ヒンディー語とタミル語が混在したデータに対する質問応答という内容でした。二つの言語が混在している理由については明確には述べられていませんでしたが、少し調べてみると、インドでは公用語はヒンディー語とされているものの、タミル語を含む多くの言語が用いられていることがわかりました。このような事情から、インドのウェブサービスでは多言語に対応する必要があり、今回のコンペティションでも複数の言語を扱うことにしたのかなと推測しています。
ここで扱う質問応答とは、文章とその文章に関係する質問が与えられ、その答えに該当する箇所を文章の中から抜き出すという形式のものです。質問応答というと、質問と答えのペアで学習を行い、似たような質問には同じ答えを返すような仕組みをイメージされる方もいらっしゃるかもしれませんが、今回のタスクのように文章から答えを抜き出す形で学習を行うことでより柔軟に質問のニュアンスなども考慮した答えを選択できるという利点があると考えられます。
提供されたデータ
提供されたデータはWikipediaの記事に関するもので、今回のコンペティションのために新しく作成されたものでした。ただし、訓練用として提供されたデータの件数は他のkaggleのコンペティションと比べると極端に少なく、1,114件のみでした。(なぜ、これほどまでにデータが少なかったのかという点は明記されていませんでしたが、今回のデータはWikipediaの記事に対して、ネイティブスピーカーが質問を考え、その質問の答えとなる箇所を人手で作成したとのことで、手間とコストがかかるものだったことが関係してそうです。)
実際のところ、このデータだけで安定した学習を行うことは難しいため、参加者自身が使えそうなデータセットを見つけて活用することが強く推奨されているという点が他のコンペティションと大きく異なりました。
以下が実際に提供されたデータの一例です。
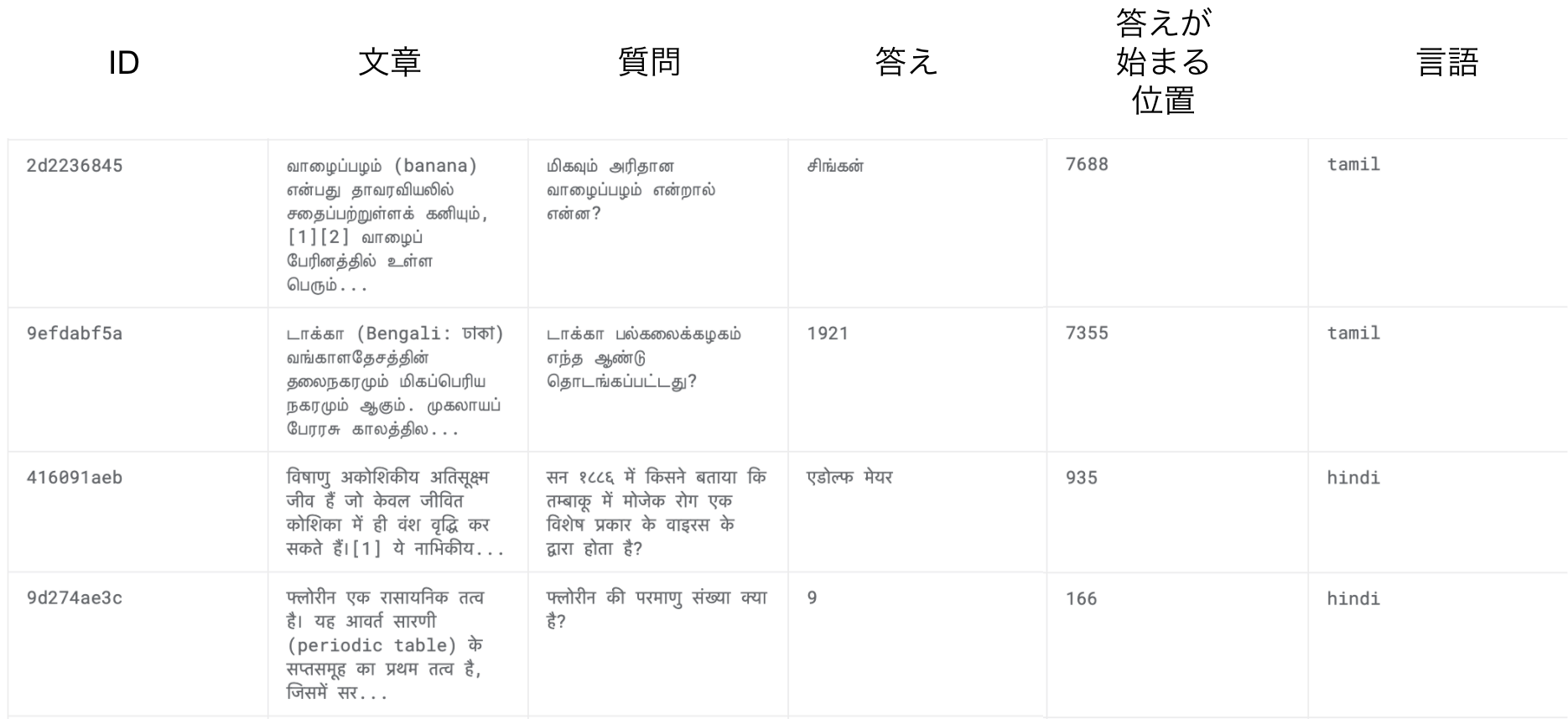
このデータには、さらに2点注意しなければならないことがありました。
- 答えに関して:訓練用として提供されたデータは1人のアノテータ(答えだと思う箇所を決める人)が作成したものですが、最終的な評価に使われるテストデータでは3人のアノテータによって作成されており、質の違いがありました。
- 答えが始まる場所に関して:これは答えが文章の中で最初に出現する位置になっていました。そのため、中には質問の答えとして適当ではない位置が指定されている場合があるため、学習時のノイズになる可能性がありました。
1に関しては、訓練データとテストデータに違いがあるという見方をすると、他のコンペティションでもみられるものかと思います。この注意点に対しては、後ほど紹介するアンサンブルを行うことで、ある程度対応できるだろうと考えていました。
2に関しては、正直なところ、時間が足りず何も対応策を考えられませんでした。他のチームは、モデルが答えだと予測した箇所を用いて修正する方法などを試していたそうですが、結果としてはこの部分で大きく差をつけられたわけではなかったです。
評価指標
予測の評価には、 Word-level Jaccard Score という指標が用いられました。この指標は、答えに含まれている単語と予測に含まれている単語を用いて、以下のように計算することができます。
def jaccard(str1, str2):
a = set(str1.lower().split())
b = set(str2.lower().split())
c = a.intersection(b)
return float(len(c)) / (len(a) + len(b) - len(c))
# 答え
answer = '11 सितम्बर 1895'
# 予測
pred = '23 सितम्बर 1895'
# Word-level Jaccard Score
jaccard(answer, pred) # 2 / 4 = 0.5
上記のコードで行っていることは単純で、答えと予測で共通している単語の個数(सितम्बर, 1895の2つ)を答えと予測に含まれるユニークな単語の個数(11, 23, सितम्बर, 1895の4つ)で割っているだけです。予測に含まれる単語が、答えに含まれていないとスコアが低下してしまうため、後処理で答えになり得ない記号を除いたりや予測の長さに制約を設けたりすることが多いです。
解法の紹介
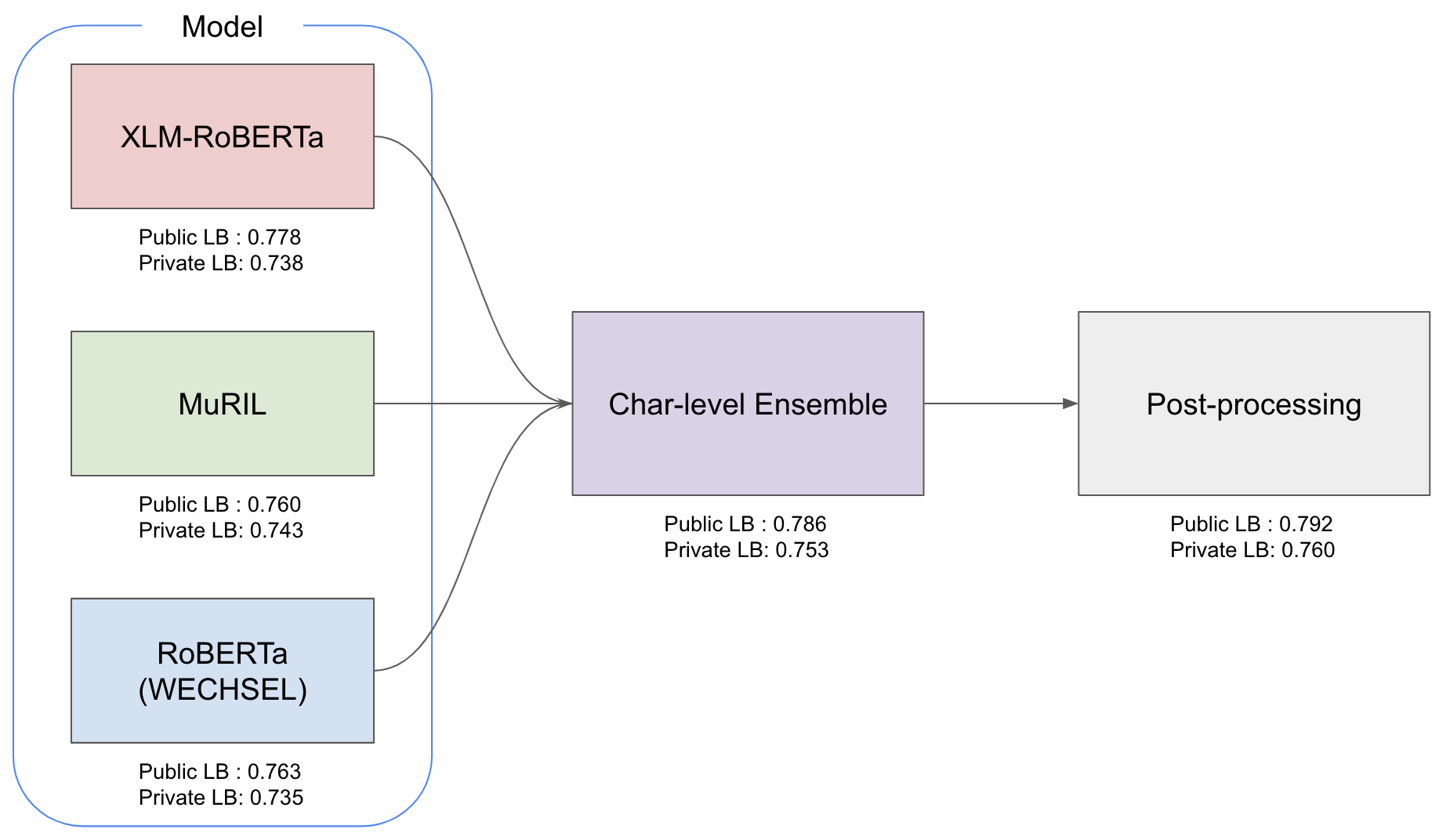
これが私の解法のパイプライン図になります。形としては、かなりシンプルで3つのモデルを作成し、出力をアンサンブルして、後処理を加えたものを最終予測としています。以降では、これらのコンポーネントについて説明していきます。
モデル
モデルに関しては、XLM-RoBERTa, MuRIL, RoBERTa(WECHSEL)の3つを用いました。パイプライン図のPublic LB1: xxxと書いてある部分が参加中に確認することができたスコアなのですが、XLM-RoBERTaが強いことがわかります。XLM-RoBERTaはRoBERTaというモデルを多言語に対応させたものであり、過去のコンペティションでも高性能だったため、今回のコンペティションでも大半の参加者が使用していました。そのため、公開されていたコードのほとんどはXLM-RoBERTaを使用していたのですが、Discussionという掲示板のようなところでは、MuRIL(インドの言語に特化した多言語モデル)やWECHSEL(英語で学習された通常のRoBERTaなどを効率的に他言語に対応させる手法)も有用そうであるという情報が共有されていました。
様々なモデルを組み合わせた方が安定した結果が得られると考え、これらのモデルを採用したことが順位変動が大きい中でも生き残ることができた要因の1つだと思います。特にMuRILは、Private LB2: xxxと書いている最終評価に用いられるスコアを見てもらうとわかるのですが、XLM-RoBERTaを超えるスコアを出していて、このモデルを採用するかどうかが重要だったようです。
- XLM-RoBERTa: https://arxiv.org/abs/1911.02116
- MuRIL: https://arxiv.org/abs/2103.10730
- WECHSEL: https://openreview.net/forum?id=JcfISE1-u4
1 参加期間中に確認できる、テストデータの一部で評価された順位表
2 コンペティション終了後に確認できる、Publicに含まれないテストデータで評価された順位表(これが最終順位になります)
アンサンブル
他のコンペティションと同様に、複数のモデルの結果を組み合わせるアンサンブルは重要でした。しかし、今回のコンペティションでは、答えに該当する部分を抜き出すというタスクの性質上、少し工夫が必要でした。具体的なアンサンブルの方法に入る前に、まずはどのようにモデルが答えとして抜き出す部分を決めるのかを紹介しようと思います。
下の図が、文章からモデルの予測を得るまでの流れを示したものです。(簡略化のため訓練に使った文章に対して予測しています)
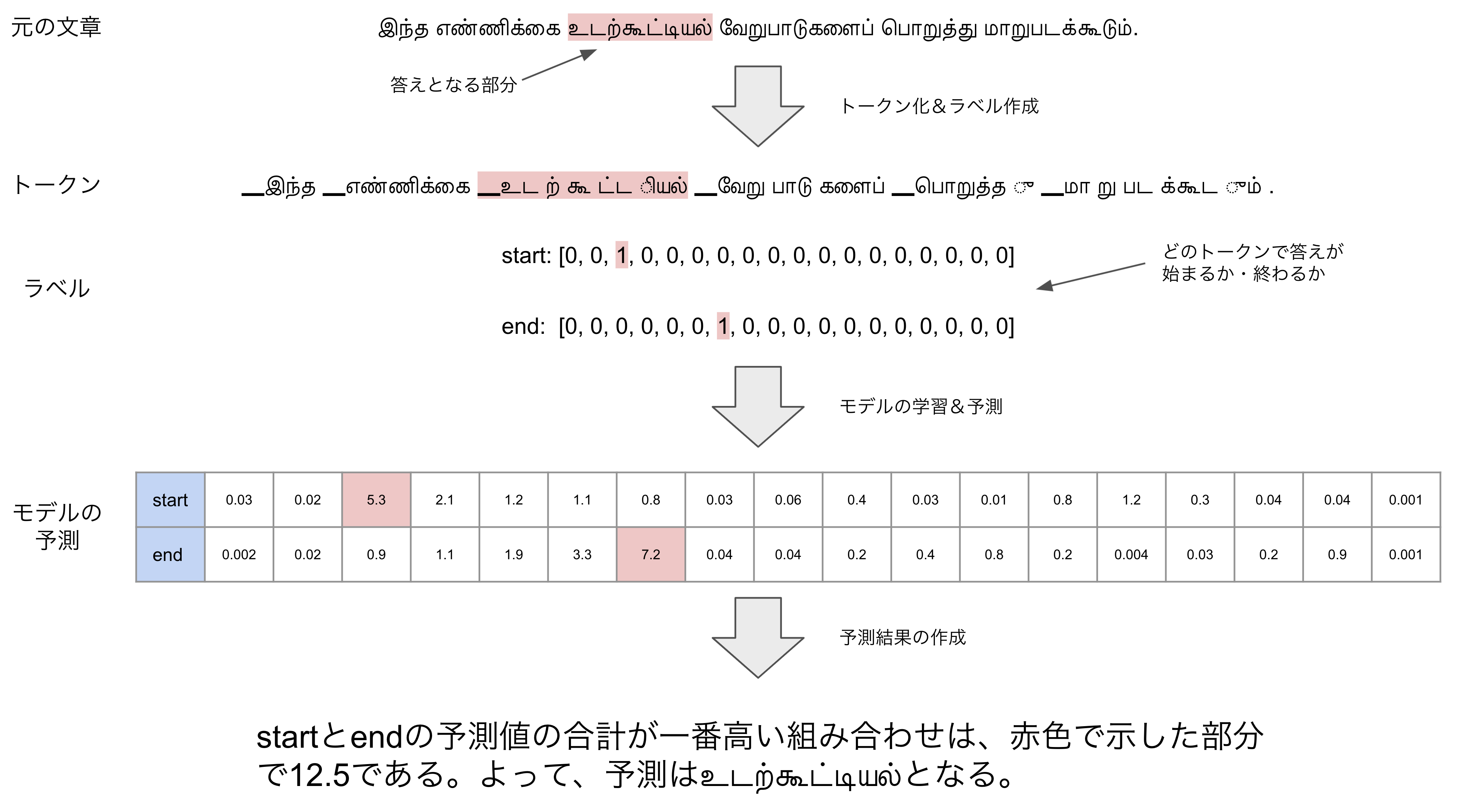
まずは、トークナイザーを用いて文章をトークン単位に分割します。そして、それぞれのトークンが答えの始まりであるかどうか・終わりであるかどうかでラベルを作成し、学習します。すると、予測結果としては、それぞれのトークンが答えの始まりである度合い・終わりである度合いを得ることができます。最後に、合計が最大になる組み合わせを見つけて、その間に含まれるトークンを予測結果とします。
アンサンブルに工夫が必要だったという話に戻ると、その理由はトークナイザーを用いて文章をトークン単位に分割する部分にあります。モデルによって同じ文章であっても、分割する場所が異なってしまうため、単純に予測値の平均をとるような形ではアンサンブルができません。

この問題を解決するために、過去のコンペティションの解法を読んでいたところTweet Sentiment Extractionの 7位の解法 で紹介されているアンサンブルの手法が使えそうだということに気づきました。手法としては、非常にシンプルでトークン単位ではなく文字単位で予測値を扱うというものになります。(あるトークンの予測値が0.2の場合、そのトークンに含まれている全ての文字の予測値を0.2にする。)この手法を用いることで、分割される位置に左右されず、予測値の平均を採用するという形のアンサンブルができました。
後処理
近年の自然言語処理に関するコンペティションでは、モデルの予測結果にルールベースなどで処理を加える後処理が重要な役割を果たすことが多くなっています。このコンペティションも例外ではなく、後処理を工夫することで大きくスコアを伸ばすことができました。
後処理でスコアが伸びるということ自体は、開催期間中に公開されていたのですが、内容は予測が記号で始まったり、終わったりする場合には削除するといったシンプルな内容でした。そこで、最後の週末にモデルの予測と答えの違いをひたすら見比べて、何かしらのルールで対応できないか調査しました。その結果、デーヴァナーガリー数字というヒンディー語で用いられている数字しか予測に含まれていない場合に、普通の数字に変換することで正解になるケースが多いことに気づきました。(例:१९४५ → 1945)
他にも、xxxx (xxxxのように括弧が閉じられていないケースでは、(xxxxの部分を削除する処理も追加しましたが、スコアアップの大半は数字の変換によるものでした。
金メダル獲得に何が足りなかったのか
使用した外部データが足りなかった
私は、公開されていたコードでよく使われていた外部データしか使用しなかったのですが、1,2,5位のチームはTyDi QAというデータセットを用いて、モデルの精度を大きく向上させていました。TyDi QAには、11種類の言語が含まれているのですが、特にヒンディー語・タミル語とある程度似ているベンガル語・テルグ語のデータが効いたそうです。このデータセットは、発表論文のタイトルにも書いてあるように、多言語の質問応答用のベンチマークとして発表されており、このコンペティションのデータ作成の際に参考にしたとの言及がありました。また、XLM-RoBERTaの論文には、他の言語も含めて学習した方が精度が良くなるといった記述があったので、解法を読んでとても納得しました。
- TyDi QA: https://arxiv.org/abs/2003.05002
Trust Public LB
他のコンペティションでは、Trust CV3と言われることが多いですが、このコンペティションではPublic LBのスコアを信じた方が良かったそうです。理由としては、提供された訓練データの件数が少なく、手元で検証に用いることができるデータ数が少ないこと、そして手元のデータでは、答えが1人のアノテータによって作成されたものでノイズがあるということでした。私も、この点は認識していたつもりでしたが、Public LBだけを信じることはできませんでした。。。2位のチームは、手元で検証することはせずに全部のデータで学習していて、アンサンブルにも多くのモデルを組み込めていたのが印象的でした。
3 訓練データの一部を検証データとして評価した、手元で確認することができるスコア
SQuAD2.0での事前学習
公開されていたコードで使用されていたXLM-RoBERTaはSQuAD2.0という質問応答のデータセットで事前学習されたものでした。なので、この事前学習をMuRILやRemBERTなどのモデルにも適応することでスコアが伸ばせたそうです。3位のチームは、SQuAD2.0で事前学習したMuRILのみを用いていて、アンサンブルもしていないとのことだったので、とても衝撃を受けました。今後のコンペティションでも、fine-tuningするタスクと似た形のタスクで事前学習するということは意識したいと思いました。
おわりに
最後までお読みいただきありがとうございました。
結果としては、あと一歩で金メダルというところで非常に悔しい思いをしましたが、その分何が足りなかったのか考えるきっかけになり、学びも多かったです。次こそは、個人参加で金メダルが取れるよう、引き続き頑張っていきます。
一緒に働きませんか?
リクルートというと、業務時間中にkaggleができるというイメージはあまりないかもしれませんが、実はチャレンジミッションという制度を活用することで取り組むことが可能です。弊社では期初に業務として取り組むことをミッションとして設定するのですが、その際に業務の10%をチャレンジミッションという形で自分の上司と相談の上、比較的自由にテーマや目標を決めて設定することができます。
さらに、kaggle grandmaster, masterが複数人在籍しており、kaggle部という部活も存在しています。kaggle部では月に一度LT会を開催し、知見を共有し合っています。自分が参加していないコンペティションの感想や解法を聞くことができるので、非常に勉強になる場だと感じています。
弊社では、様々な職種のエンジニアを新卒・中途ともに募集しております。ご興味のある方は、以下の採用ページをご覧ください。

Airペイ、Airレジなどを扱うSaaS領域でモデル作成やデータ分析を担当
高橋寛武
新卒でリクルートに入社。kaggle master(自然言語処理のコンペティションが得意)
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


