
はじめに
機械学習エンジニアの荒居秀尚です。 この記事では、2021年10月に社内で実施したMLコンテストで参加者向けに作成したサンプルノートブックの用意の話をします。
本コンテストは、データ室内の社員向けに開催されたもので、サイト内の行動履歴データを利用した予測タスクに2日間で取り組んでもらう内容でした。
機械学習を使った予測モデルの作成は経験したことがないという方も参加する一方で、普段から業務でも機械学習をバリバリ使っていてKaggleなどにおいても日々研鑽を積んでいる社員も複数参加していたため、難しすぎず易しすぎないような内容に仕立て上げるように工夫を凝らす必要がありました。本記事ではその工夫について紹介させていただきます。
どんなタスク・データだったか
連載のこれまでの記事と被る点もありますが、コンテストで扱ったタスク・データについて紹介します。
今回のコンテストは、ユーザーの検索した条件とその結果表示されたアイテムの情報からユーザーがそのアイテムをクリックしたかどうかを予測するものでした。データとしては次のような形式のデータが与えられており、学習データにはクリックしたかどうかを示すフラグが目的変数として与えられていました。
| ID | ユーザーID | リクエスト時間 | 検索パラメータ | アイテムの情報1 | … | アイテムの情報N |
|---|---|---|---|---|---|---|
| 1 | ユーザーA | 2022-01-01 09:00:00 | 検索条件1&検索条件2&検索条件3 | aaa | … | xxx |
| 2 | ユーザーB | 2022-01-01 09:01:00 | 検索条件2&検索条件4 | bbb | … | yyy |
| 3 | ユーザーA | 2022-01-01 09:00:00 | 検索条件1&検索条件2&検索条件3 | aaa | … | yyy |
| 4 | ユーザーC | 2022-01-01 09:02:00 | 検索条件5&検索条件6 | ccc | … | zzz |
特徴的な点として、ユーザーID・リクエスト時間・検索パラメータが一致するレコードが必ず偶数含まれ、半分が正例でもう半分が負例になるようにデータセットが作られていました。
このようなデータ設計になった背景は ML Contest 2021 - データセット準備 に詳しく説明されています。
サンプルノートブックの作成
今回のコンテストでは、EDA(探索的データ分析)のノートブック、ベースラインのノートブック、そして一部のカラムに含まれていた日本語を扱うための自然言語処理に関するノートブックを作成しました。
自然言語処理のノートブックの内容は私が以前個人的に執筆した ブログ記事 の内容に近いものですので、ここではEDAのノートブックとベースラインのノートブックの作成についてかいつまんで説明をします。
EDAのノートブックの用意
EDAのノートブックを作る段階では、私自身が一切データに関して知識がない状態だったので、私がデータについて理解しモデリングの方針を立てた過程をそのまま言語化するようにしてノートブックを作成しました。
例えば検索パラメータは、
条件1=〇〇&条件2=XX&条件3=AA
のように複数の検索パラメータとその値が&で繋がれた文字列になっていましたが、それぞれのパラメータは記号で表現されており、その設定値もカテゴリIDなどになっていて容易には理解しづらいものでした。
そこで私は、仕様書を読んだり、実際のサービスを触ってみたりしてどの検索パラメータがサービスのどの項目に対応しているかを確認し、その内容をEDAのノートブックに書いておくことにしました。そうすることで、コンテストの参加者はパラメータの定義の確認に時間を取られることなく、モデリングに集中することができます。
また、分析の流れとしては、私が普段からKaggleなどの機械学習のコンテストに出るときに気をつけていることをそのまま実践するようにしました。今回のようなCV予測の問題設定でよくある課題として
- 正例と負例の比率が偏っている
- 偏りデータの問題設定となり、問題として難しくなる
- 学習データとテストデータの間で一部ユーザーに被りがある
- 学習データに入っていて、かつテストデータにも入っているユーザー群に対する予測しやすさと、どちらかにしか入っていないユーザー群に対する予測しやすさが異なるため、場合によっては別のモデルを作るなどした方がよい
- ユーザーごとのレコードが複数ある場合が多い
- 同一ユーザーのデータが学習データと検証データの両方に入らないように切り分けを行う必要がある場合が多い
- 時系列性が強い
- 検証データの切り分け方に気をつけないとリークが発生する可能性がある
- 場合によっては古いデータは捨ててしまった方がよい
といったものがあります。こうした課題があるかもしれないと念頭において、次のような事項はまず最初に確認するようにしました。
- 正例と負例の比率
- 学習データとテストデータのユーザーの被り
- ユーザーのユニーク数(Cardinality)
- ユーザーごとのレコード数
- ユーザーごとの正例・負例比率
- ユーザーごとのレコードの時間的な近さ
すると、「ユーザーごとに同じリクエスト時間を持つレコードが必ず複数あり、そのうち半分が必ず正例である」という性質がわかってきました。また、さらに深掘りをすると、「同じリクエスト時間に同じユーザーがリクエストしたレコードは必ず同じ検索パラメータを持っている」、ということもわかりました。
これを踏まえると、次のようなモデリング方針を立てることができます。
- 同じリクエスト時間、かつ同じ検索パラメータ、かつ同じユーザーIDを持ったレコードは、そのユーザーが検索をかけたときに同じ検索一覧画面に表出したアイテムを表している
- どちらか片方はユーザーによって選択され(CV)、もう片方は選択されなかった
- したがってそのようなペアの中でアイテムの特徴の差分を取ったり、アイテムの特徴と検索パラメータの一致度合いの差分を取ってペアごとに予測を立てたりするといい可能性がある
ベースラインのノートブックの用意
ベースラインのノートブックの作成において気をつけたのは、そのまま上から順に実行していけば提出まで行うことができるようになっていることと、EDAで得た知見を生かしていることです。
今回のコンテストは2日間しかないという非常に短期間のものだったため、最初の提出にかかる時間が長いことは致命的になってしまいます。最初の提出を用意する時間的・心理的コストは、普段から機械学習のコンテストに参加している人にとっても高いものであるため、それを取り払うために「とりあえず動くもの」をベースラインとして作成しました。
また、このような短期間のコンテストは普段から機械学習のコンテストによく参加して、汎用的なパイプラインを整えている人1が圧倒的に強いという傾向があります。今回はまったくの初心者という方も参加していたため、事前の用意の差であまりに大きな差がつきすぎるのを防ぐという意味合いもありました。
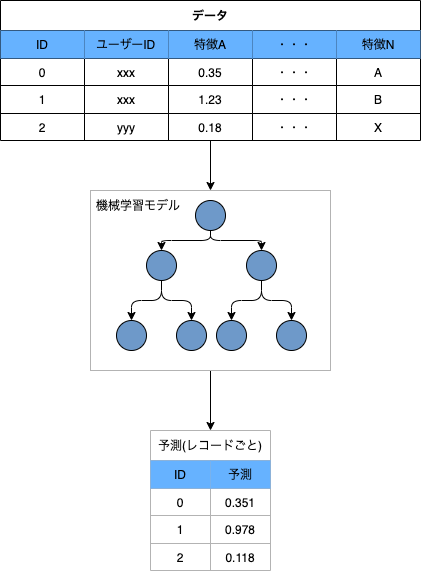
ベースラインのノートブックでは、まず一般的なテーブルデータに対して行われるように、レコードごとに特徴を作成し、レコードごとに予測を立てるようなモデリングを行いました。元のテーブルのカラムのうち数値のカラムはそのまま使い、カテゴリのカラムはLabel Encodingのみ施して特徴としました。また、検索パラメータも一部のパラメータは数値やカテゴリと解釈できるものがあったためそれらを抜き出して特徴化しました。検索パラメータはユーザーごとに異なるため、あるパラメータがユーザーの検索の中にあるとは限らないのですがその場合はシンプルに欠損として扱うようにしました。モデルとしては機械学習のコンテストや実務の現場でもよく用いられるLightGBM2を使い、検証データにおけるスコアを出しました。今回のコンテストの評価指標はROC-AUCだったのですが、この時点での検証データにおけるAUCはほぼ0.5程度とそのままでは分類が困難なことがわかります。
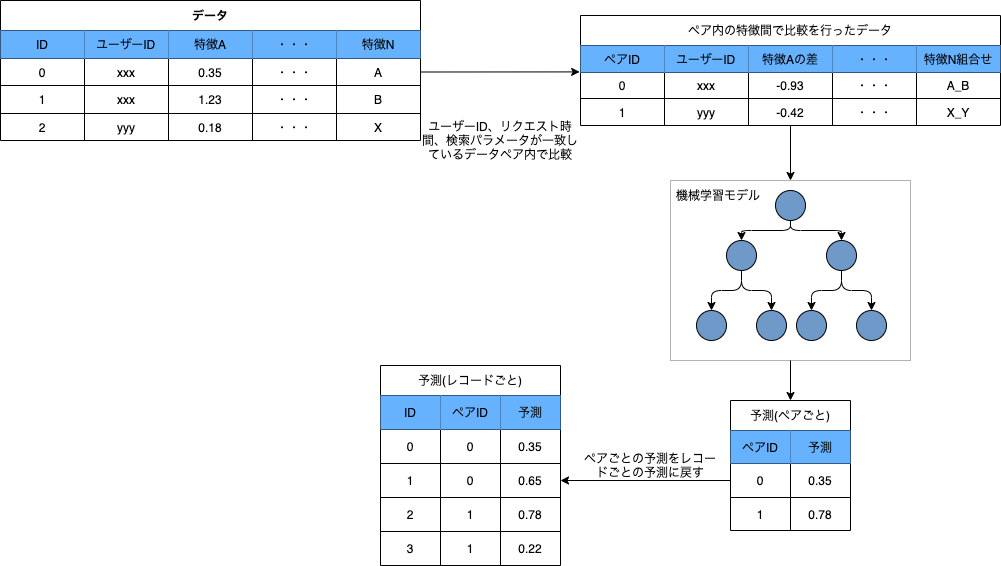
次に、EDAの結果を踏まえ、同じユーザーが同じリクエスト時間で、同じ検索パラメータを用いているレコードペアごとに比較をするようにしてペアごとに特徴を作成し、ペアごとに予測を行うようなモデリングも行いました。具体的には、0/1のフラグや数値変数は差分を取り、カテゴリ変数はペアの前にあるレコードの値と後にあるレコードの値を組み合わせて新しいカテゴリ変数を作るようにしました。また、検索パラメータ由来の特徴などペア内で共通しているものはそのまま残すようにしました。下のコードスニペットは、このペア比較の特徴生成コードを模擬したコードです。
def create_pair_comparison_features(df: pd.DataFrame) -> pd.DataFrame:
# フラグ系の特徴は0か1しかないため、差分を取っても問題ない
flg_columns = ["xxx_flg", "yyy_flg", ..., "zzz_flg"]
# 数値変数は差分をとるのがふさわしい
numerical_columns = ["num_xxx", "num_yyy", ..., "num_zzz"]
# カテゴリ変数はペアの前後で組み合わせて新しいカテゴリを作る
categorical_columns = ["cat_xxx", "cat_yyy", ..., "cat_zzz"]
# ペア内で共通の特徴
common_columns = ["common_xxx", "common_yyy", ..., "common_zzz"]
# 差分を取る系の特徴を作成
diff_feats = flg_columns + numerical_columns
aggregate_dict = {
key: lambda x: x.values[0] - x.values[1]
for key in diff_feats
}
diff_df = df.groupby(["ユーザーID", "リクエスト時間", "検索パラメータ"]).agg(
aggregate_dict)
# カテゴリ変数は組み合わせを作り新しいカテゴリ変数とする(Encodingは後で行う)
aggregate_dict = {
key: lambda x: str(x.values[0]) + "_" + str(x.values[1])
for key in categorical_columns
}
categorical_df = df.groupby(["ユーザーID", "リクエスト時間", "検索パラメータ"]).agg(
aggregate_dict)
# ペア内で共通の特徴は最初の一個を取る
aggregate_dict = {
key: lambda x: x.values[0]
for key in common_columns
}
common_df = df.groupby(["ユーザーID", "リクエスト時間", "検索パラメータ"]).agg(
aggregate_dict)
return diff_df.merge(
categorical_df, left_index=True, right_index=True
).merge(
common_df, left_index=True, right_index=True
)
また、ペア内でどちらか片方が必ず正例でもう片方が負例なことを考え、index順で並べたときに前にあった方のCVフラグを正解ラベルとして作成するようにしました3。
このような特徴/目的変数の作成の仕方を行ってから改めてペアごとにLightGBMで予測を行い、ペアごとに得られた結果の値そのものをペア内の並び順で前にあった方の予測値とし、ペア内の並び順で後ろにあった方の予測値はペアごとに得られた結果の値を1から引くことで得ます。
この、ペアごとに予測を行うようなモデリングによってAUCが15%ほど改善することができました。元々がほとんどランダムに予測しているのと変わらない結果だったことを踏まえるととても良い結果とは言い難いのですが、ベースラインとしては十分な性能です。
このようにナイーブなやり方と、EDAの結果得られた知見を踏まえたやり方の両方を載せることでしっかりとデータを見て知見を得ることの大事さを伝えられるようにしたことは、参加者からも概ね好評でした。
コード品質へのこだわり
今回ノートブックを作るにあたって、コードの品質については一定の注意を払っていました。というのも、このようなサンプルのコードはしばしばコンテストの枠を超えて利用されることもあるからです4。
具体的には、
- コードにはなるべく型ヒントをつける
- 変数への命名は、読んでパッと意味を理解できるように少し冗長であってもわかりやすい名前をつけるようにする
- 特徴量作成や、機械学習モデルの定義においては、拡張性が高くなるように抽象クラスを用意する
などの点に気をつけました。
「拡張性が高くなるように抽象クラスを用意する」とは、例えば特徴量作成においては次のような特徴量作成関数と、抽象クラスを用意しました5。
import logging
from typing import List, Optional, TypeVar
import pandas as pd
class AbstractFeatureTransformer:
def __init__(self):
self.name = self.__class__.__name__
def fit_transform(self, input_df: pd.DataFrame, y=None):
self.fit(input_df, y)
return self.transform(input_df)
def fit(self, input_df: pd.DataFrame, y=None):
pass
def transform(self, input_df: pd.DataFrame) -> pd.DataFrame:
raise NotImplementedError
Transformer = TypeVar("Transformer", bound=AbstractFeatureTransformer)
def extract_features(input_df: pd.DataFrame,
transformers: List[Transformer],
fit: bool = True,
logger: Optional[logging.Logger] = None):
feature_dfs = []
for transformer in transformers:
# timerはブロックの実行時間を計測するユーティリティ
with timer(f"Extract features with {transformer.name}", logger):
if fit:
feature_dfs.append(transformer.fit_transform(input_df))
else:
feature_dfs.append(transformer.transform(input_df))
all_features = pd.concat(feature_dfs, axis=1)
return all_features
新しい特徴を作成したい場合は、この抽象クラスを継承した特徴量作成クラスを実装します。
class Numericals(AbstractFeatureTransformer):
def transform(self, input_df: pd.DataFrame) -> pd.DataFrame:
cols = [pd.api.types.is_numeric_dtype(dtype) for dtype in input_df.dtypes]
return input_df.loc[:, cols]
class LabelEncoding(AbstractFeatureTransformer):
def __init__(self, columns: List[str]):
super().__init__()
self.le_columns = columns
self.encoders = {
column: LabelEncoder()
for column in self.le_columns
}
self.__is_fitted = False
def fit(self, input_df: pd.DataFrame, y: Optional[np.ndarray] = None):
for column in self.le_columns:
self.encoders[column].fit(input_df[column].fillna(""))
self.__is_fitted = True
def transform(
self,
input_df: pd.DataFrame,
y: Optional[np.ndarray] = None
) -> pd.DataFrame:
assert self.__is_fitted, "You need to call `fit` first."
encoded = {}
for column in self.le_columns:
encoded[column] = self.encoders[column].transform(
input_df[column].fillna(""))
return pd.DataFrame(encoded)
このような設計はJupyter Notebookを使ってモデリングを行う際はそこまで大きな効果は発揮しないこともあるのですが6、業務などで機械学習のパイプラインを実装しているときには重宝します。特徴量作成のまとまりがクラス単位で分割されるため、ある特徴を入れる入れないを設定ファイルで変更できるようになることや、新しい特徴作成を行う際に共通のインターフェースに則って実装を行うようになるのでコードのメンテナンスがしやすいといった利点があります。
モデルの方も同様に、勾配ブースティング木ベースのモデル(XGBoost, LightGBM, CatBoost)を統一的なインターフェースで扱えるようにしたラッパークラスを用意するような実装を行いました。
import lightgbm as lgb
class AbstractTreeModel:
def __init__(self, prediction_type="binary"):
self.model = None
self.prediction_type = prediction_type
def train(self,
params: dict,
X_train: pd.DataFrame,
y_train: np.ndarray,
X_val: pd.DataFrame,
y_val: np.ndarray,
train_weights: Optional[np.ndarray] = None,
val_weights: Optional[np.ndarray] = None,
train_params: Optional[dict] = None):
if train_params is None:
train_params = {}
model = self._train(
params,
X_train, y_train,
X_val, y_val,
train_weights, val_weights,
train_params)
self.model = model
return self
def _train(self,
params,
X_train,
y_train,
X_val,
y_val,
train_weights,
val_weights,
train_params):
raise NotImplementedError
def predict(self, X: pd.DataFrame) -> np.ndarray:
raise NotImplementedError
@property
def feature_names_(self):
raise NotImplementedError
@property
def feature_importances_(self):
raise NotImplementedError
def _check_if_trained(self):
assert self.model is not None, "You need to train the model first"
class LGBModel(AbstractTreeModel):
def _train(self,
params,
X_train, y_train,
X_val, y_val,
train_weights, val_weights,
train_params):
trn_data = lgb.Dataset(X_train, y_train, weight=train_weights)
val_data = lgb.Dataset(X_val, y_val, weight=val_weights)
model = lgb.train(params=params,
train_set=trn_data,
valid_sets=[trn_data, val_data],
**train_params)
return model
def predict(self, X: pd.DataFrame) -> np.ndarray:
self._check_if_trained()
return self.model.predict(X, num_iteration=self.model.best_iteration)
@property
def feature_names_(self):
self._check_if_trained()
return self.model.feature_name()
@property
def feature_importances_(self):
self._check_if_trained()
return self.model.feature_importance(importance_type="gain")
def get_tree_model(name: str) -> Type[AbstractTreeModel]:
DEFINED_MODELS = {
"lgb": LGBModel,
# 実装していない
# "xgb": XGBModel,
# "cat": CatBoostModel
}
model = DEFINED_MODELS.get(name)
if model is None:
raise ValueError(
"""Invalid model name: {}.
Pre-defined model names are as follows: {}""".format(
name,
",".join(DEFINED_MODELS.keys())
))
return model
このようにすることで学習用のコードを変更することなく、複数のモデルを扱うことができるようになります。このような実装上のテクニックは私自身が普段から機械学習を用いたプロダクト開発でも実践しており、特にチームで一つの機械学習パイプラインを作成していくときにコードの属人性を下げたり、拡張性を高く保ったりするのに役立っていると感じています。
終わりに
本記事では、社内で行われた機械学習コンテストで参加者に提供したノートブック作成における工夫について紹介しました。
丁寧さを心がけてサンプルノートブックの作成を行った甲斐もあり、参加者の方から概ね好評だったのですが、私個人としては反省すべき点もあったと考えています。今後の教訓として残すためにも最後にそれらについて触れて終わりたいと思います。
実は、ベースラインのノートブックは最初に提供した段階ではこちらの意図したスコアを再現することができないという問題があることがコンペ開始後に発覚しました。これは、コード中にバグを埋め込んでしまったため起きたものだったのですが、きちんとレビュー時間を取り第三者の目を入れる・コード完成後に改めて実行の確認をする、などの基本的なチェックにより防げるものだったと考えています。
幸い、バグについては早い段階で気づくことができ、修正したベースラインのノートブックを再配布することでリカバリができたのですが、サンプルノートブックのベースラインはコンテストのアウトカムに大きく影響を与えるものですので次はこのようなことがないようにサンプルノートブックの品質管理にしっかりと気をつけたいと思います。
今回、参加者から取ったアンケート結果を見ると、サンプルノートブックが良かったという意見を多数いただくことができました。サンプルノートブックは、コンテストを成り立たせる上で必須の要素ではないのですが、コンテスト全体の出来栄えに大きな影響を与える要素であることを強く認識することができましたので、今後も同様の機会があれば気合を入れて用意をしていこうと思います。
-
人によってはデータの形式を合わせてConfigファイルさえ書き換えれば学習から推論まで一気通貫で行うことができるようなパイプラインを用意している人もいます。 ↩︎
-
全てが正例になる/全てが負例になるといったことが起きないように、index順に並び替えてもペアの中で前にくるレコードのCVフラグの正例/負例比率は1:1になるようになっていました。 ↩︎
-
実際、私自身もKaggleで用いるコードの一部をいつでも参照できるようにしており、仕事において使える場面が出てきた際はコピペで用いることもあります。 ↩︎
-
atmaCupにおける初心者向け講座などを参考にさせていただきました。https://www.guruguru.science/competitions/16/discussions/95b7f8ec-a741-444f-933a-94c33b9e66be/ ↩︎
-
参加者の感想の中にはこの特徴量作成の関数・クラスは少し使いづらかったというものもありました。このあたりは反省点の一つです。 ↩︎

旅行・飲食・SaaSデータの分析・モデリングなど
Hidehisa Arai
新卒でリクルート入社。Kaggle Grandmaster。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


