自己紹介
始めまして。今年度、株式会社リクルートにデータスペシャリストとして新卒入社しました澤邉裕紀、山根大輝と申します。 入社同期で複数本投稿予定の Recruit Data Blog の第3回目になります。
データスペシャリストとして入社すると、住まい、飲食などの事業領域ごとのチームに本配属される前に、同期全員でBootCampと呼ばれる研修を受けることになります。 入社してまずこのBootCampを走り切ることで、データ専門人材としての基礎を身につけることができます。
BootCampのコンテンツは様々ありますが、今回はそのなかでもGoogle Cloud Platform(以下、GCP)を題材としてクラウド、インフラ、CI/CDツールについて学ぶGCPハッカソンについてレポートします。
全体の流れ
GCPハンズオン
実際に2人チームに分かれて課題に取り組む前に、GCPに関する社外の方の講義を受け、Qwiklabsを利用したハンズオン形式で演習を行いました。 講義を受ける前は、「BigQueryで大規模データを簡単に取り出せて、GCPのクラウドを使うと簡単にインフラが作れる!」程度の理解でしたが、 BigQuery上でのSQLの書式やベストプラクティス、マイクロサービスの利点やよくある構成、GCPサービス(Cloud Storage、Cloud Run、Pub/Sub、Google Kubernetes Engine(GKE)など)を徹底的に解説していただき、大きな学びとなりました。 特に、サポート体制が完璧で、チャットでの質問に講師の方が丁寧に答えてくれるので、 疑問点をすぐに解消し、効果的な学びにつなげることができました。
GCPハッカソン
講義で学んだ内容を活かすため、2人チームに分かれたハッカソン形式で実践を行いました。 実践の内容は、GCPのサービスを組み合わせて作られたシステムを基に各々のチームが行いたい改良を施し、GCP上にデプロイしてみるというものでした。 与えられたシステムは、Webサイトに訪問したユーザが商品を閲覧した時に、別の商品を追加で推薦することを想定しており、次のような構成がされていました。
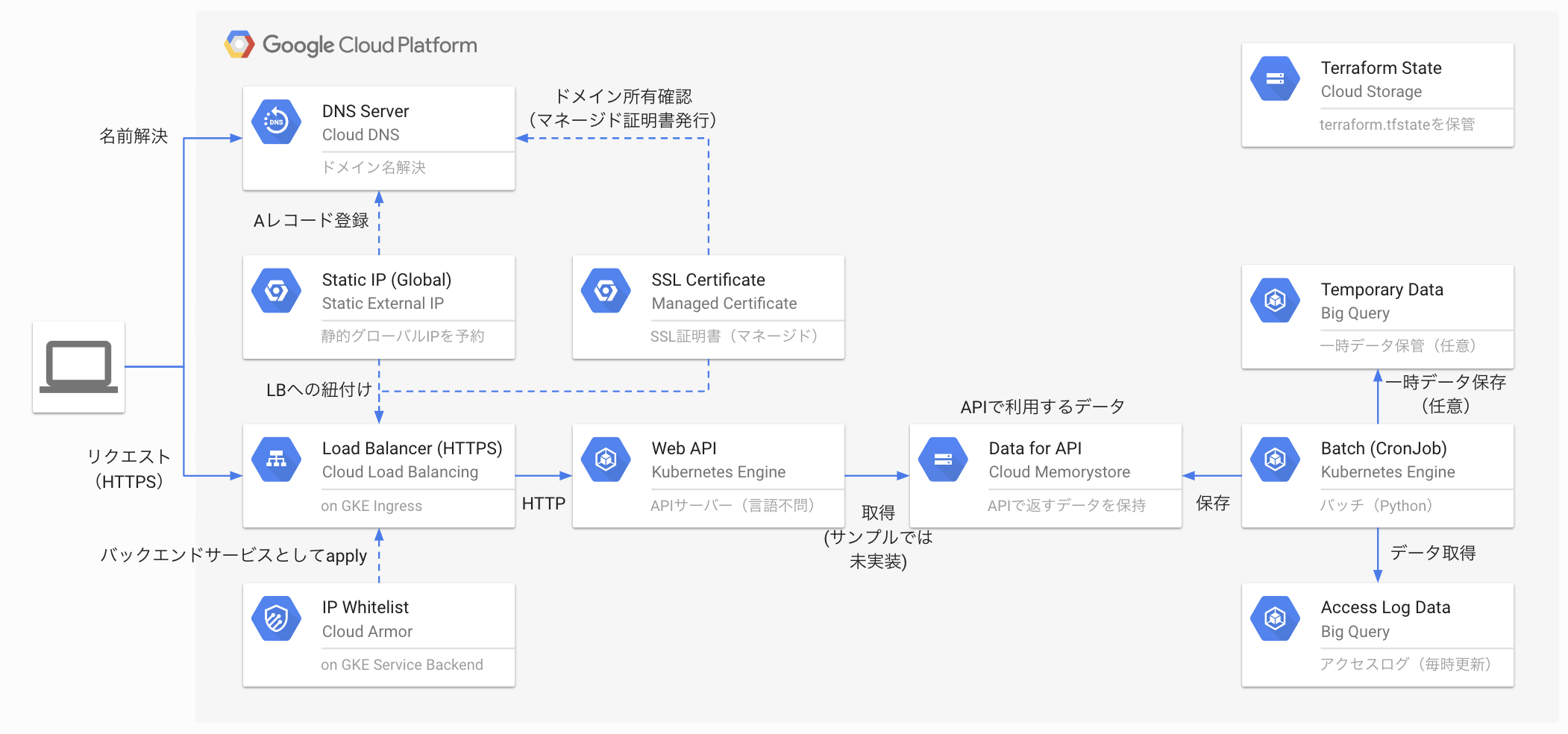
簡単に説明をすると、ユーザが本システムに対してアクセスをするとサーバーであるWeb APIが処理を受け付けます。 Web APIはユーザが閲覧した商品IDをクエリとしてData for API(Cloud Memorystore)から追加で推薦する商品のリストを受け取ります。 そして、その結果をユーザに返却し画面に表示するという仕組みです。
なお、ハッカソンではWeb APIとData for APIの通信部分は実装されていない状態で渡されるので、どのチームもまずはこの部分を修正し一度サービスを完成させてから、各々の興味に従って実装を行っていきました。 全部で14個のチームがあり全てを紹介することは難しいので、今回は澤邉と山根のチームがそれぞれどんなことに挑戦したのかを紹介していこうと思います。
負荷対策やってみた
山根のチームでは以下を満たすようなサーバーを作ることを目標にしました。
- 多くのユーザから大量のリクエスト(今回は1000リクエスト/秒とします)があっても耐えられる
- DoS攻撃(同一IPから大量のリクエストが送られてくる攻撃)を検知し対処できる
なぜこのような目標を立てたのかというと、サーバーダウンやDoS攻撃はサーバーの設計をしたことがない我々でもTwitterなどでよく耳にする話題で、中身を作ってみて少しでも対策をしている人たちの気持ちを理解できるようになろうと考えたためです。
ハッカソンでは次の4つのことに取り組んだので、順番に紹介していこうと思います。
- 負荷テスト
- Gunicornによる並列化
- キャッシュの利用
- DoS攻撃の検知と対策
①負荷テスト
最初にJMeterを使った負荷テストを行いました。 負荷テストとはシステムがどの程度の負荷に耐えられるのかを試験することで、JMeterは簡単な設定をするだけで特定のアドレスに対してリクエストを自動で投げることで負荷テストを行ってくれます。
※BootCamp時には、このJMeterを使って課題として渡されたシステムが初期設定でどの程度の負荷に耐えられるのかを試してみました。 ブログ執筆時にはBootCamp時の環境を利用することができなかったので、実際の様子をお見せできず申し訳ないのですが以下の画像のようにリクエストを大量に投げることができます。
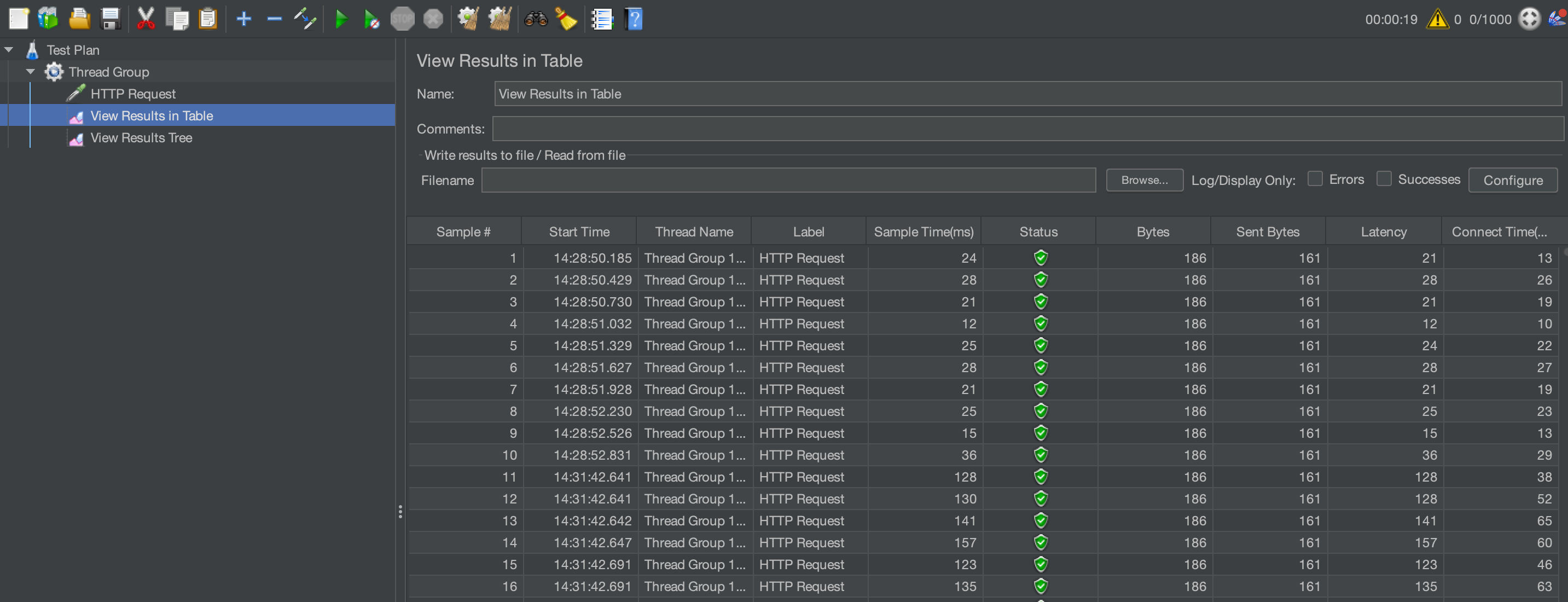
1秒間で1000リクエストを送ってみたところ、最初のシステムでは800リクエスト程度からエラーが返ってくることがわかりました。 つまり、仮に1秒間に800リクエスト以上のアクセスが発生するとこのシステムでは対処できないということになります。
※一応、大量のリクエストが来ると自動でスケールする仕組みはあるのですが、あまりに短期間で大量にリクエストがくると間に合わないようです
②Gunicornによる並列化
負荷テストの結果を受けて、負荷対策をすることにしました。 単純にデフォルトのPodの数を増やしても良かったのですが、それだと面白味がないのでソフト的に解決することを試みました。 具体的には、元々Flask単体でサーバーを立てていたところをGunicornを使ってFlaskを起動し、HTTPサーバーを立てるように変更しました。
元々のシステムではリクエストを処理するワーカーが1つであったため、複数のリクエストが同時に来ると捌ききれないということが起こっていました。 しかし、Gunicornを使ってサーバーを立てると複数のワーカーでリクエストを処理できるようになります。 Gunicornを導入すると、先ほどまでは800リクエストでダウンしてしまっていたサーバーが全てのリクエストを返せるようになりました。
ただ、レイテンシが上がってしまいサーバーダウンはしていないものの、実運用上は問題がありそうな結果になってしまいました。 結局のところ、Pod数=1ではソフト的に頑張ったとしても限界があったので、Pod数を増やすことによりこの問題を解決し、無事1000リクエスト/秒に耐えられるサーバーを構築することができました。 今回は大きな有効性はありませんでしたが、割り当てられたマシンリソースを使いきれていない時にはGunicornなどのソフト的な施策も役に立つ可能性があるという良い勉強になりました。
③キャッシュの利用
先ほどはワーカーやPodを増加させ、並列して処理できるリクエストの数を増やすことで、負荷対策を試みました。 ここでは、同じ商品IDのリクエストが複数きた時にレスポンスを高速化するために、サーバーの処理ではお馴染みのキャッシュを実装してみます。
※ただし、今回のシステムにおいて推薦商品リストを問い合わせる、Data for APIはMemorystore for Redisを使って実装されているので元から高速です。 そのため、キャッシュの実装は本来不要ですが、一般的なWeb開発では役立つ場面も多いので勉強のために実装をしています。
キャッシュは色々な方法を使って実現できますが、今回はメモリ上にデータを保存するため高速な読み書きができるデータベースRedisをFlask-Cachingを使ってサーバーと連携をさせることで実装しました。 Flask-Cachingはキャッシュに関する機能を非常に簡単に設定できます。 例えば、純粋にキャッシュを実装しようと思うと、
- Redisにリクエストされた商品IDに対する推薦商品リストがあるかをチェックし、結果が保存されていればその結果を返す
- 1でキャッシュがなければ、Data for APIから推薦商品リストを受け取りユーザーに返す。さらに、その結果をRedisに保存する
といった処理を書かなければなりません。 また、一定時間でキャッシュからデータを削除したい場合はそれも実装する必要があります。 しかし、Flask-Cachingを使うとこれが1行で書けてしまいます。 実際にWeb API内で実装したコードがこちらです。
@cache.cached(timeout=30)
def get_item2item_recommendation(item_id: int):
items_raw = fetch_from_memorystore(item_id)
items_str = items_raw.decode()
return items_str
@cache.cachedとデコレーターをつけるだけで、上記の1,2の処理は自動でやってくれます。 また、timeoutを引数で渡すとその時間だけデータを保持してくれるようになります。
さて、純粋な大量リクエストに対する負荷対策は終わったので、最後にDoS攻撃に対する対策を講じてみます。
④DoS攻撃の検知と対策
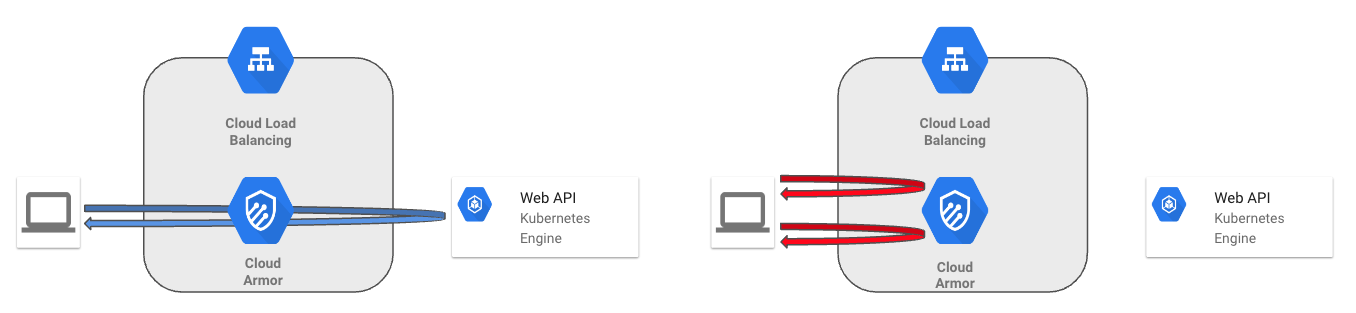
DoS攻撃は同じIPアドレスから沢山のリクエストを送ることで攻撃する手法です。 そのため、同じIPからのアクセスに制限をかけてしまえば対策ができそうです。 GCPにはCloud Armorという仕組みがあり、これを使うことでスロットル制限をかけることができます。 我々のチームでは1つのIPアドレスが連続して10回以上アクセスしてくることを禁止しました。 これによってDoS攻撃対策が完成しました。
開発環境を構築してみた
澤邉のチームでは、与えられたマイクロサービスをFlaskで書き換え、開発環境を追加することと、さらにAPI部分のfastAPIでの書き換えに挑戦しました。
特に、澤邉が取り組んだ開発環境の追加についてお話します。 具体的には、本番環境のドメインからサブドメインを切り、そこにアクセスすると開発版のサーバーに繋がるようにしました。
KubernetesとTerraformを組み合わせたインフラ記述や、DroneのファイルによるCI/CDの設定など、初めてのことが多かったですが、 メンターである先輩社員の助けもあり、なんとか走り切ることができました。
課題概観
課題では初めに3つのリポジトリが与えられます。 リポジトリは以下のように分けられていました。
-
Kubernetes(以下、K8s)で構成された必要最低限なWebAPIサーバー。
-
Terraformで記述されたクラウドのインフラ部分。
-
CronJobを実行するML部分。
このうち澤邉はK8s部分とTerraform部分を主に編集することとなりました。 なお、本来はDBなどすべての環境を複製し開発環境とすることが望ましいですが、時間の都合上ロードバランサ部分とAPIサーバー部分のみを複製しました。
開発用リソースの追加
課題で初めに与えられたK8sで記述されたリソースは本番環境用のみなので、まずはK8sで開発環境用のリソースを追加する必要があります。 K8sの概念すら知らない段階でのスタートだったので、初めはどこをいじれば良いのかも全く分からず… メンターさんに初歩の初歩から質問することで、何とか解決し、 開発用のK8sファイルを作成して、GCR(Google Container Registry)にコンテナをpublishし、GKE(Google Kubernetes Engine)にdeployすることでリソースを複製することができました。
工夫した点として、開発環境をGKEのK8s上でも分離するため、Namespaceを開発用と本番用で2つ用意することにしました。 Namespaceを分離することで、仮想的に環境を分け、NamespaceごとにPodやコンテナのリソースを制限したり 異なるNamespace以下で同じ名前のリソースが作れるようになる利点があります。
また、GCPのサービスの一つで、レイヤー7のロードバランサであるingressも複製することで、アクセスの入り口から環境を分離するようにしました。

Droneで開発環境をpublish/deployするように設定を変更
課題の時点では本番環境しか存在していなかったので、CI/CDツールであるDroneはmasterへのcommitで本番環境のpublish、タグ付きのcommitで本番環境のdeployが行われるよう設定されている状態でした。 このままだと新しく作成した開発環境に関してCI/CDが設定されていないので、開発環境については手動でpublish、deployを行わなくてはならなくなり面倒です。
そこで、開発環境も同じくcommit時にdeploy、publishされるよう変更しました。 具体的には.drone.ymlファイルを書き換え、developブランチにpushした際に、新しく追加した開発環境をGCRにコンテナとしてpublishする設定を行いました。 開発環境のdeployのタイミングは本来は本番環境と分けるべきですが、本番環境と同じく、タグをつけたcommitがpushされた際としました。 また、開発環境をpublish、deployするためのコマンドもシェルスクリプトで記述し、Droneからはこちらを実行するようにしました。
サブドメインの設定
開発環境のリソースにURLでブラウザからアクセスできるようにするため、開発環境のingressを作成し、ingressにサブドメインを設定しました。
ドメインの設定もGCPのGUI上で行うのではなく、Terraform上でDNSレコードの追加まで行いました。
具体的にはリソース文google_compute_global_addressでグローバルIPアドレスを追加し、 google_dns_record_setでDNSにAレコードを追加します。
resource "google_compute_global_address" "ingress-ip-stage" {
name = "ingress-ip-stage"
}
resource "google_dns_record_set" "a-stage" {
name = "stage.${data.google_dns_managed_zone.managed_zone.dns_name}"
managed_zone = data.google_dns_managed_zone.managed_zone.name
type = "A"
ttl = 300
rrdatas = [google_compute_global_address.ingress-ip-stage.address]
}
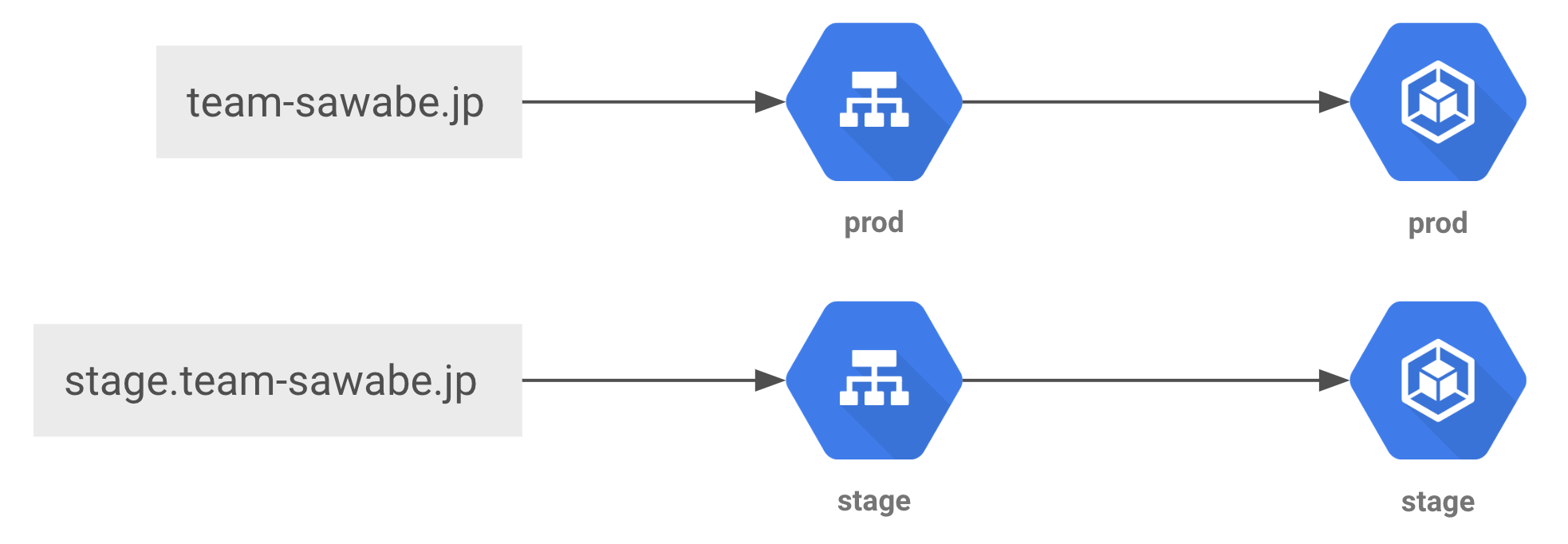
さらにK8sのcertificateやingressの設定ファイルでもstage版のIPアドレスを追加します。 TerraformとK8sの連携についても初めての挑戦でしたが、試行錯誤し何とか所望する実装を達成できました。 最終的には下の図のような構成となり(ドメインはイメージです)、開発用と本番用でそれぞれ別の環境にアクセスすることに成功しました。
まとめ
GCPハッカソンを通して、GCP、Kubernetes、Terraform、DroneをはじめとするインフラやCI/CDの知識をつけることができました。機械学習等の分野とは違い、体系的な教科書が少なく、1人では勉強しづらい部分であると感じていたので、研修という形で講義や質問を利用しつつ勉強ができる環境はとても貴重だったと思います。クラウドに関しても自分で試そうとするとどうしても費用がかかってしまうので、そこを研修という形で気兼ねなく自由に試せるのはとても楽しかったです!
最後に
ここまで読んでいただきありがとうございます。このような技術研修を行っている当社では新卒採用を行っています。 ご興味のある方は、以下の採用ページをご覧下さい。
===========================
===========================
次回は専門人材の心得・MVP研修についてです!お楽しみに!

データサイエンティスト
澤邉裕紀
新卒でリクルート入社。自動車領域でリコメンドやデータ分析を担当。

データサイエンティスト
山根大輝
新卒でリクルート入社。飲食領域を中心にリコメンド、数理最適化を担当。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら