
こんにちは、データエンジニアの龍野です。 私は現在、全社横断のデータ基盤「Knile」の開発を行っています。
自分のチームは Four Keys の計測をはじめとした DevOps の実践をし、積極的に Site Reliability Engineering (SRE) の推進も行なっています。その中で今回は、 SRE の中核を占める SLO についてのより深い理解を深めるためにチーム内で実施した SLO Workshop と、Workshop の中で自分たちが学んだ SLO のエッセンスを紹介いたします。
この記事が目指すもの
SRE 本
でも言われている通り(
こちら
のブログでも同様の言及があります)、SLOs are key to making data-driven decisions about reliability, they’re at the core of SRE practices(簡単に訳すと、「SLO は信頼性をデータドリブンに決めるためのキーであり、SRE のコアである」)と書いてあるくらい、SLO は SRE の概念で極めて重要なポジションを占めています、が SLO をいざ自分たちで設定・運用してみると色々な疑問が生じました。本ブログでそうした疑問の紹介や解決法を示すことで、以下のような課題を抱えている人たちの助けになれればと思っています。
- SLO という話をし始めたが漠然としている
- SLO を設定したが塩漬けになって動かせなくなっている人
- SLA / SLO / SLI の違いが分からない
- 社内に SRE の考え方をもっと根付かせたい
具体的に、この記事では下記に触れます。
- SLO Workshop の紹介と実施の Tips
- SLO Workshop から学んだ、SLA / SLO / SLI の定義・意義・設定方法の紹介
SLO Workshop
SLA / SLO / SLI の定義と SLO Workshop のきっかけ
元々の背景として自分たちは、社内プロダクトを展開していて SLO の設定などを行なっていましたが、 話していく中で SLO の設定方法やそもそも SLA と SLO の境目、SLI をどう設定すれば良いかというところが感覚的であるという課題感を持っていました。
そこで、SLA / SLO / SLI という用語に関しての認識を揃えようということで、 SRE 本 や、 Google Cloudのブログ などを参照しました。
その中で、SLA/SLO/SLI は次のように規定されます。
- SLA (Service Level Agreement): サービスレベル契約。ユーザーとの契約であり、これを割ったら罰金や払い戻しなどを行わないといけないライン。
- SLO (Service Level Objective): サービスレベル目標。ユーザーの体験を満たすために最低限必要とされるライン。
- SLI (Service Level Indicator): サービスレベル指標。サービスの動作を直接測定したもので、システムのプローブが成功した頻度として定義される。
概要としてはこのような違いがあります。しかし、実際にこれらの表現をみると
- SLA と SLO の違いって罰金があるかないか?
- 頻度ってあるけど頻度?別に「応答時間平均 XX ms 以内」とかでも良さそうじゃない?
- 結局どうやったら正しい SLO を設定できるの?
といった点に関しての明確な回答ができませんでした。
そんな中、上のブログのリンクにある SLO Workshop に出会いました。
SLO Workshop って何?
Google が公式に The Art of SLOs という資料を公開しています。 これは Google の Customer Reliability Engineer (CRE)のチームが作成した資料(※)で、具体的に社内や他の場所などでこうした Workshop を行うことで、SLO や SLI などの定義、設定方法といったものを学ぶことができるようになっています。また、Workshop 内では仮想のサービスを元に、実際に SLO を考えるということも行うため、知識だけでなくより実践的な SLO の理解と定着を行うことができます。
資料自体はかなり豊富で、実際の発表スライドやファシリテーター用・参加者用の資料がそれぞれ公開されています。 実際のタイムスケジュールや準備方法などについても丁寧に記載されているので、これだけで資料としては十分です(ただし資料は全て英語です)。
特に、この Workshop は中身を見てみると、SLO などの定義だけではなく
- なぜ、SLO が必要なのか
- SLI をどう設定すべきか
- 実際の SLO の見直し方
などを具体的に学ぶことができるもので、チームの課題感としてはピッタリでした。
(※)余談ですが、CRE のチームがなぜ SRE とかで使われる SLO の話を?と思う方もいるかもしれませんが、
Introducing Google Customer Reliability Engineering (CRE)
の The Customer Reliability Engineering mission の項目によると、CRE is what you get when you take the principles and lessons of SRE and apply them towards customers.「CRE は SRE の原理や教訓をカスタマーに適用する際に得るもの」であると言われています。なので、SRE の教訓を Workshop として公開するのは、まさに CRE の仕事というわけです。
実施目的
SLO Workshop を自グループで行う前に、まずはこの Workshop をなぜ行うのか、という部分を明確にしました。
- 自グループにおける SLA / SLO / SLI に関して、正しい知識を持つ
- 共通の見解を持つことで、 SRE に関して共通の認識を持って会話をできるようにする
- 結果として、今後の運用の方向性・改善方法やチームでの新規プロダクトの指標の設計に繋げる
事前準備
運営は 3 人で行い、1 時間 x 2 回程度実施しました。
- まず、SLO Workshop の資料を読んできて、各自 GitHub の Issue に分からないことや内容をメモする
- その上で、実際のフローを順番に洗いながら(資料のページ・参照部分など)不明なところ、言葉の定義を確認して全体の流れを明確にする
これを複数人でやっておくと、自分の曖昧なところもクリアになりますし、当日ファシリテートする場合にもお互いで助け合えるので会がスムーズになります。
実際の実施
当日のスケジュールは下記のように進めました。メンバーの予定や状況も加味して、スケジュールが後ろ倒しになっています。
10:00 Introduction
10:15 SLIs, SLOs and Error Budgets
11:15 Break
11:30 Developing SLOs and SLIs
12:30 Lunch
13:30 Practical Exercise
15:00 Break
15:15 Example Answer
15:30 Q&A Session
slack チャネルで話しながら上記の通り議事進行を行いました(アイコンは全部我が家のネコ写真に置き換えています)。
基本的に公式の資料を使いながらメインの人がファシリつつ、残りの人がファシリテーターの解説の補足や QA 回答を Slack でライブ回答していく方式を取りました。 こうした形式をとることで、話し手以外で逐次疑問を回収でき、時間通り進行していくのに効果的だったように感じます。
運営側は、
- 1 人目: Introduction〜SLIs, SLOs and Error Budgets
- 2 人目: Developing SLOs and SLIs
- 3 人目: Practical Exercise〜Example Answer
という分担で行いました。
Practical Exercise では実際に仮想サービスとユーザーのシナリオを元に SLO の設定を行います。参加者 3 人で 1 チーム、運営側がフォローする形で進めました。
最後にアンケートをとって終わりとしました。後日、我々の理解の定着のために、この Workshop のサマリを社内のドキュメントやブログに残しました。
SLO Workshop での学び
SLO Workshop を経験したことで学んだことについて、 SLO Workshop の中身を噛み砕いて書こうと思います。主に、SLO を設定するモチベーションや実際の設定方法を解説します。説明の観点から必ずしも SLO Workshop と全く同じ順番で説明していない点についてはご留意ください。また、例題の紹介はしますが、Practical Exercise〜Example Answer の内容に関してはネタバレになってしまうので本記事では詳細は触れません。
また、今回はいくつか SLO Workshop の内容や図を参照します。著作権に関しては The Art of SLOs のページ下部にある Creative Commons CC-BY-4.0 license に従います。
SLO の設定背景
そもそも、サービスは信頼性が大事というところから話は始まります。
例えば、どんなに素晴らしいサービスだったとしても頻繁にメンテナンスが起きたり、ページのロードに異常に時間がかかっていたりすると使いたいとはなりませんよね?
なので、サービスの信頼性が高いことというのはサービスが利用されるための必要条件となります。このサービスの信頼性を測るという意味から、サービスには SLO が必要とされています(またこの時、サービスの信頼性を測るためにシステムから取得可能な値として SLI が必要です)。
しかし、Dev からしてみると機能の開発はしたい、でも Ops の人からするとサービスを止めるような変なことをして欲しくない。こうして昔から Dev と Ops は反発がありました。SLO というのは、この信頼性の境界を定量的に定義することで、信頼性に対して開発チームと運用チームのインセンティブを一致させる ということが実現できるようになります。
つまり、SLO という基準を持つことで「もっとどんどん新機能を開発していこう」という開発に力点を置くべきなのか「もっと基盤の安定させるための開発を行おう」という運用に力点を置くのかといった意思決定のバランスを取れるようになることを目指します。
SLO が目指すもの
では、よく言われる SLA とは何が違うのでしょうか。SLA は基本的にユーザーとの契約に基づいてサービスがこの信頼性を回ったら返金対応などを行うという本当にサービス存続の最低ラインになります。
そのため、この基準さえ満たせばサービスとして十分であるというわけではありませんし、割ってから何かしら対応をするというのでは遅すぎます。SLA を割る前にユーザーの体験を損なわないような運用を行う必要があります。
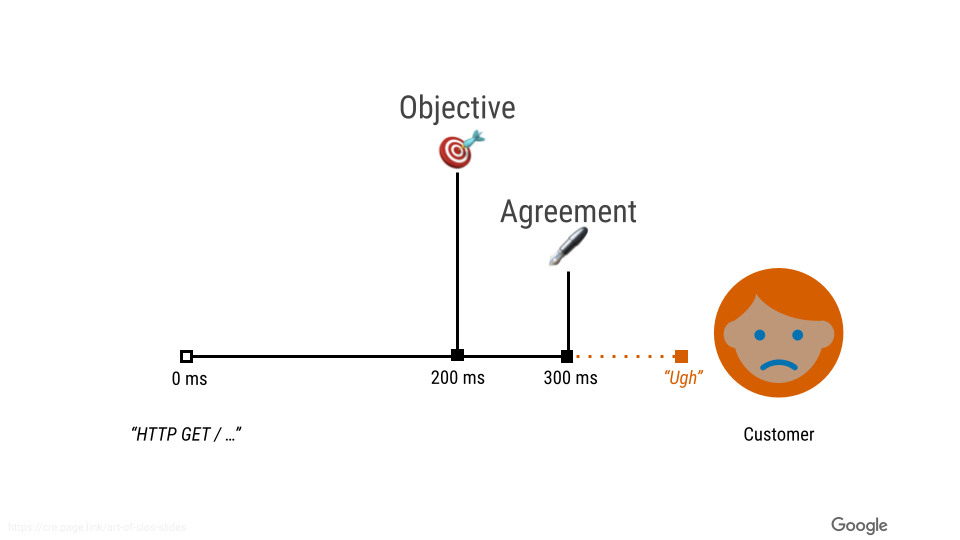
ではどうすれば良いでしょう。ここで出てくるのが SLO という考え方になります。SLO は定義上はそのサービスが目指す目標値になります。つまり、ここの水準を満たせば一般的なユーザー(極度なクレーマーとかは除く)にとっては満足であるという境界値になります。
じゃあ高く置けば良いのかというと、SLA/SLO は 100%に置けるかというと置けません。インターネットですらそもそも完全な 100%は無理ですよね?また、今はクラウドの上にサービスを構築するケースも多いと思いますが、GCP の Compute Engine(GCE)でさえ SLA は 22/02 時点で 99.5% です。
加えて、私たちの直感としても、100%の可用性は求めていません。今のインターネットのサービスを使っていて、たまに繋がらないといったことはしょっちゅう起こります。しかし、たった一度エラーが出てユーザーがそのサービスを使わないか、というとそんなことはありません。100%に届かないどこかに、ユーザーが許容できる範囲がありそうです。このユーザーの許容できる境界線というのが SLO となります。つまり、SLO は ユーザーがサービスを満足に使えるかどうかの閾値 に設定するべきです。
では、その閾値は果たしてどこなのでしょうか。Google が Cousera の講座で述べる Customer Reliability Engineeringの3原則 によると「ユーザーは期待している動作が行われない時に信頼性を毀損していると感じる」というものがあります。
つまり、SLO を設定する際は、ユーザーが実際にそのサービスに期待する動作はなんなのかということを考えて設定する必要があります。
Error Budgets
Error Budgets とは、許容できる信頼できなさ を定量化したものです。許容できる 信頼できなさとは何かというと、SLO がサービスの信頼性の閾値であるという前提に立って考えると、SLO をある一定期間で見て、あとどれくらいサービス稼働を棄損させても大丈夫かということを定量的にみたものと言い換えることができます。SLO を見る期間は週次の開発サイクルと合わせて 30 日ではなく、過去 4 週間ウィンドウで見ることが推奨されています。
例えば、28 日ウィンドウでサービス稼働率 99.9%を SLO と設定すると、28 day * 24 hour * 60 minutes * 0.001 % = 40.32 で約 40 分のダウンタイムが Error Budget として許容されます。基本的に Error Budget がゼロを破らない限りはサービスの SLO は守られます。
例えば、Error Budget を使うべき項目としては下記のようなものが挙げられます。
- 新機能リリース
- 計画的なシステム変更
- ハードウェア・ネットワークなどの回避できない障害
- 計画停止
- 危険な実験(カオスエンジニアリングとか)
このように、あとどれくらいのバジェットが残っているのかというのを把握することで、チームとしては新規開発など攻めを強化するか、信頼性をあげる守りの開発をすべきかという判断を定量的な判断軸を元に行うことができるようになります(つまり、Dev と SRE の共通インセンティブになります)
SLI の設計方法
さて、 SLO は ユーザーがサービスを満足に使えるかどうかの閾値 という話がありました。これを念頭に、SLO の元となる SLI をどう設定すべきかを考えていきます。
上記の説明に基づくと、SLI は、ユーザーとの満足度がきれいに切れるかどうかというラインが大事になります。つまり、SLI と user experience は線形でなければなりません。
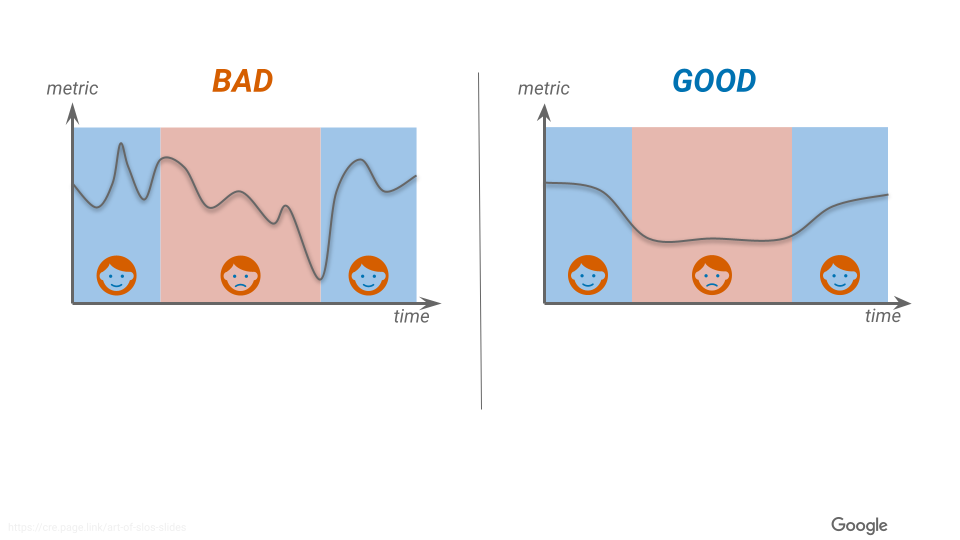
また、SLI は基本的にシステムで取得可能な SLI = 望ましいイベント / 全体のイベント となるのが好ましいとされています(つまり、必ず百分率で表現される)。こうすることで、閾値を明確にできるとともに、前項で説明した Error Budgets の概念を取り入れやすくするという点において非常に使いやすいものとなります。
この SLI をユーザーが実際にそのサービスに期待する動作のユーザージャーニー(シナリオ)に対して考えていく必要があります。だいたい、1 つのユーザージャーニーに対して 3-5 の SLI が好ましいとされています。
SLO の設計方法
さて、SLO を考えていきましょう。SLO は SLI を元に、ユーザーがサービスを満足に使えるかどうかの閾値に設定する必要があります。しかし、ユーザーの満足な閾値とはなんでしょう。ここで、Workshop の説明によると、「ユーザーの期待値は過去のパフォーマンスに関係する」とされています。
SLO ではないですが、例えば昔あった機能とかがなくなると、「前は当然この機能があったのに!」とかクレームが入りますよね?つまり、過去のパフォーマンスが良すぎると、ユーザーはそれを当然と思うようになります(そういった意味でも、SLO100%はユーザーの期待値を上げすぎてしまうという観点から、理想的な状況ではありません)。
そのため実際的には、 SLO は過去のパフォーマンスを元に達成可能なものを決める必要があります。サービスの過去のパフォーマンスというのは時々によって変化します。その中で、逐次的に SLO を見直すことでより理想的にビジネスに長期的に求められる SLO と現実的に達成可能な SLO のバランスを取り続ける必要があります。そのため、SLO というのは塩漬けするものではなく、過去の状況を元に直していくことが推奨されます。
実践 SLO 設定
この SLO Workshop では Fang Faction という架空のゲームで Loading a Profile Page というユーザージャーニー(つまり、ユーザーのプロファイル画面を表示するシナリオ)を元に、実際に SLO を立ててみるということを行います。ちなみに、実際の SLO Workshop ではこの Loading a Profile Page はすぐに解説をしてしまい、午後の Practical Exercise では同じゲームですが別のユーザージャーニーについてグループワークを行うという流れになります。
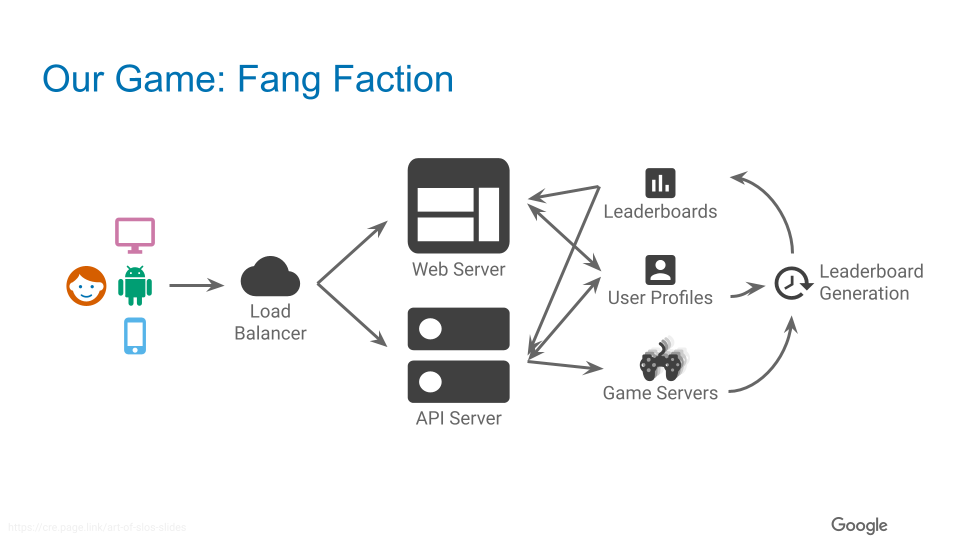
ゲームの構成自体はこんな感じで、ロードバランサがあり、後ろ側がバックエンドになっていて、その後ろで各マイクロサービスに振り分けられます。
ここでは、実際に Loading a Profile Page を元に簡単な SLO 設定方法の説明をします。
ユーザープロファイルのページのイメージはこのような感じになっています。
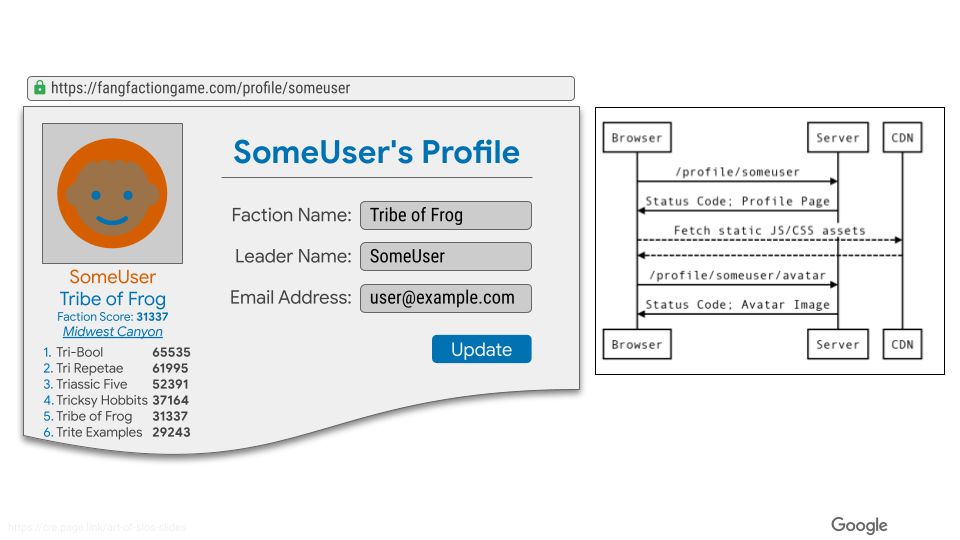
ユーザージャーニーの策定
ここではユーザーのプロファイルを見るとなった時のユーザーの流れ(=ユーザージャーニー)を考えます。ユーザーのプロファイルを見た時の期待の挙動はおそらくこのような手順になっているはずです。
- ある程度の時間でプロファイルページが読み込まれる
- アバター画像が表示される
- リーダーの名前、グループの名前とメールアドレスが表示される
- ユーザーの所属する地域のハイスコアが表示される
- CSS が読み込まれてページの体裁が整う
今回の処理の流れを先ほどの概要図に表すとこのような感じになっています(Web サーバからユーザプロファイルとリーダーボードにアクセスしています)。
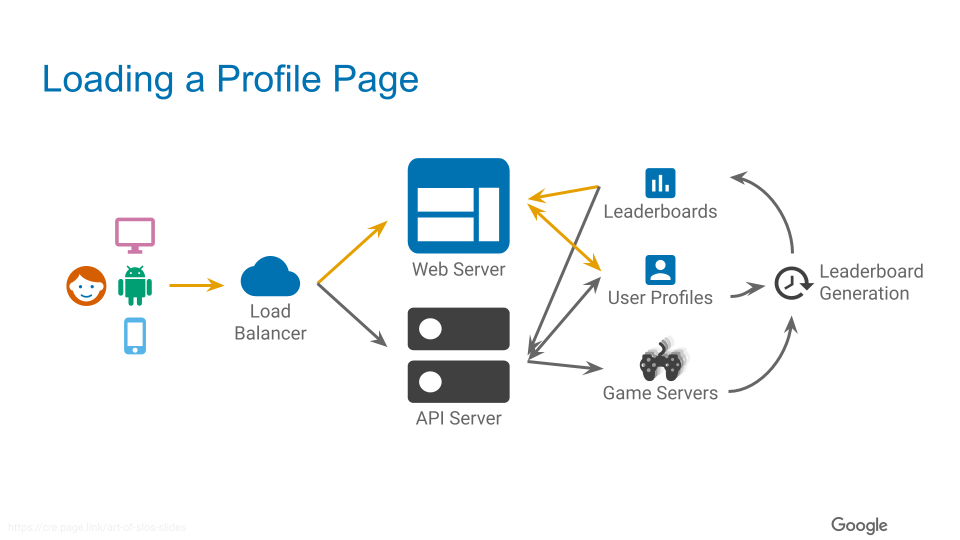
SLO / SLI の設定
さて、ではここから、どのような SLI を設定すれば良いでしょう??
SLI に関しては以下の候補(SLI Menu)が例として提示されています。
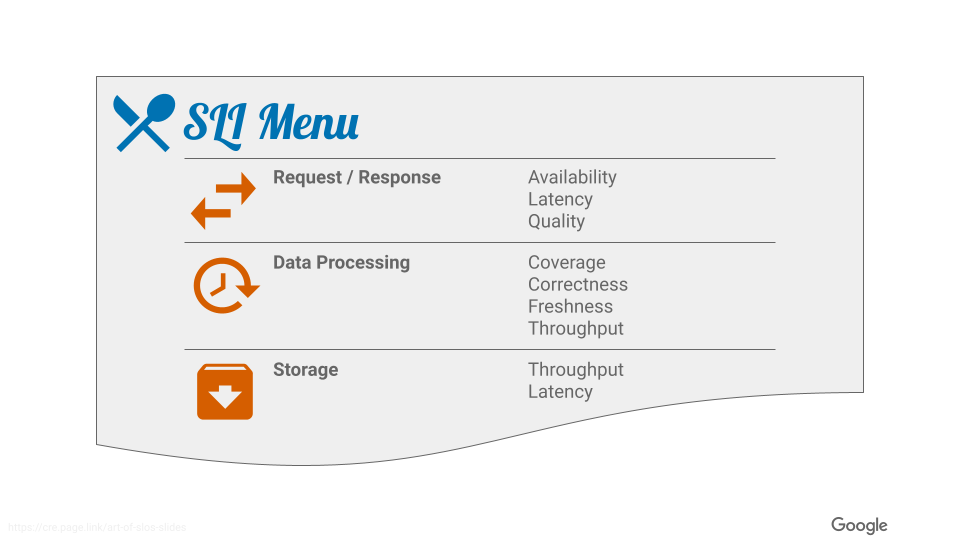
SLI を設定するときは、それぞれ下のことを念頭に置きましょう。
- ユーザーの期待動作(どのようにユーザーはサービスを使うか)
- 何を測ることがシステム上可能か
まず、この時にユーザーが期待するのが下記の 2 点で、ここからそれぞれの SLI を定めることができます
- プロフィールページが正しくロードできること → Availability
- プロフィールページが早くロードできること → Latency
ではこの Availability と Latency を具体的にブレイクダウンしていきましょう
- プロフィールページが正しくロードできる (Availability)
- 正しくロードできるとは何か → Get method で
/profile/{user}か/profile/{user}/avatarにリクエストの 2XX, 3XX or 4XX (429 を除く) の割合 - どこでそれが記録されるか → ロードバランサ
- 正しくロードできるとは何か → Get method で
- プロフィールページが早くロードできる (Latency)
- 早いとは何か・いつからいつまでを記録するか → Get method で
/profile/{user}か/profile/{user}/avatarのリクエストのレスポンスが X ms 以内の割合 - どこでそれが記録されるか → ロードバランサ
- 早いとは何か・いつからいつまでを記録するか → Get method で
実際にそれぞれのメトリクス定義を考えてまとめてみると、このようになります。

まとめると、このような順番で SLI を設定していきましょう
- SLI 指標に繋がる期待動作の定義 (What)
- どうやってそれを指標として測るか (How)
- どこで / いつそれを指標として測るか (Where/When)
SLI / SLO の見直し
さて、これで SLI/SLO を設定できました、めでたしめでたし…というわけには行かず、その後このゲームでは障害が発生します。
カスタマーサポートからの連絡によると、実際にユーザーの画面はロードされていたが何も表示されていないということでした。つまり、サーバからのレスポンスが空だったのです (The Art of SLOs – Participant Handbook p.24)。
たしかに、前項で設定した SLI ではコンテンツの中身を全く見ていなかったので、このような中身が空という事象を検知できていませんでした。それを踏まえて Availability の SLI をこのように修正しました。
- プロフィールページが正しくロードできる
- ロードできるとは何か → Get method で
/profile/{user}か/profile/{user}/avatarにリクエストの 2XX, 3XX or 4XX (429 を除く) の割合 - どこでそれが記録されるか → ロードバランサ
- ロードできるとは何か → Get method で
- プロファイルページの中身が正しく表示される
- どうやって判定するか → Get method で
/profile/prober_userにリクエストを投げた時に正常なコンテンツが全て返却される - どれくらいの間隔で記録するか → 5s
- どうやって判定するか → Get method で
最終的にまとめた図はこのようになります。

SLI を考慮した外観はこのような感じになります。
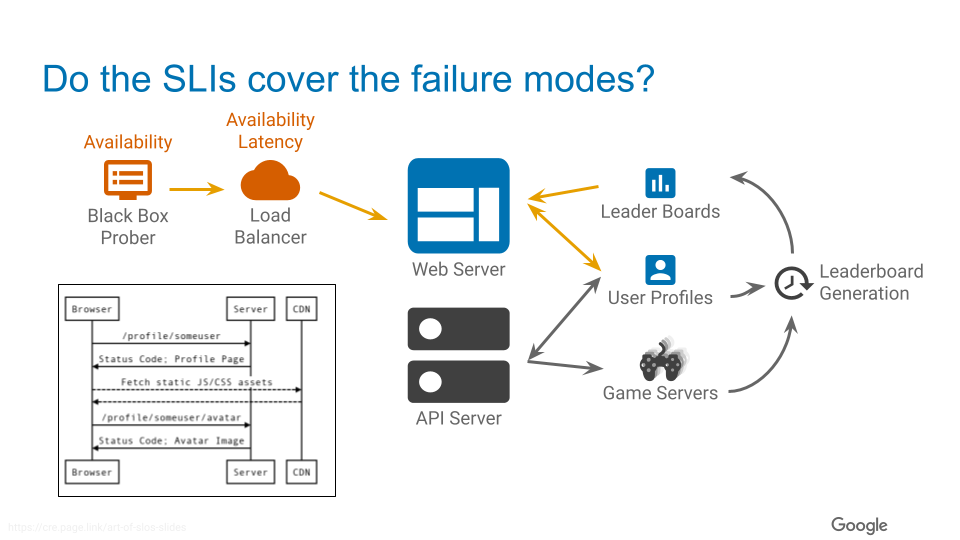
SLO に関しては実際の過去の実績を見て、妥当なラインを定めます。これも単一の正解があるわけではないですが、過去の数値の中でよりブレがない値を採用しましょう。過去のデータはこのようになっています。
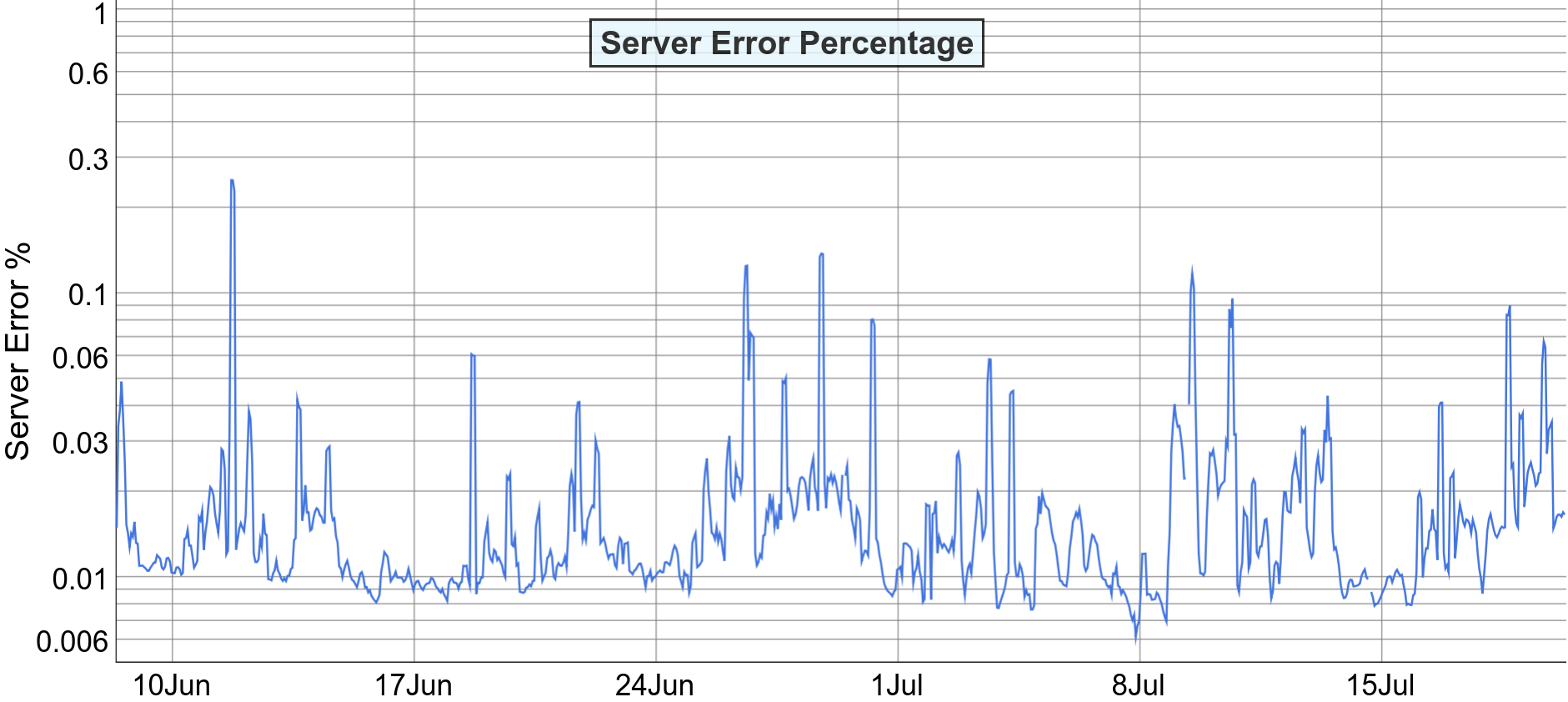
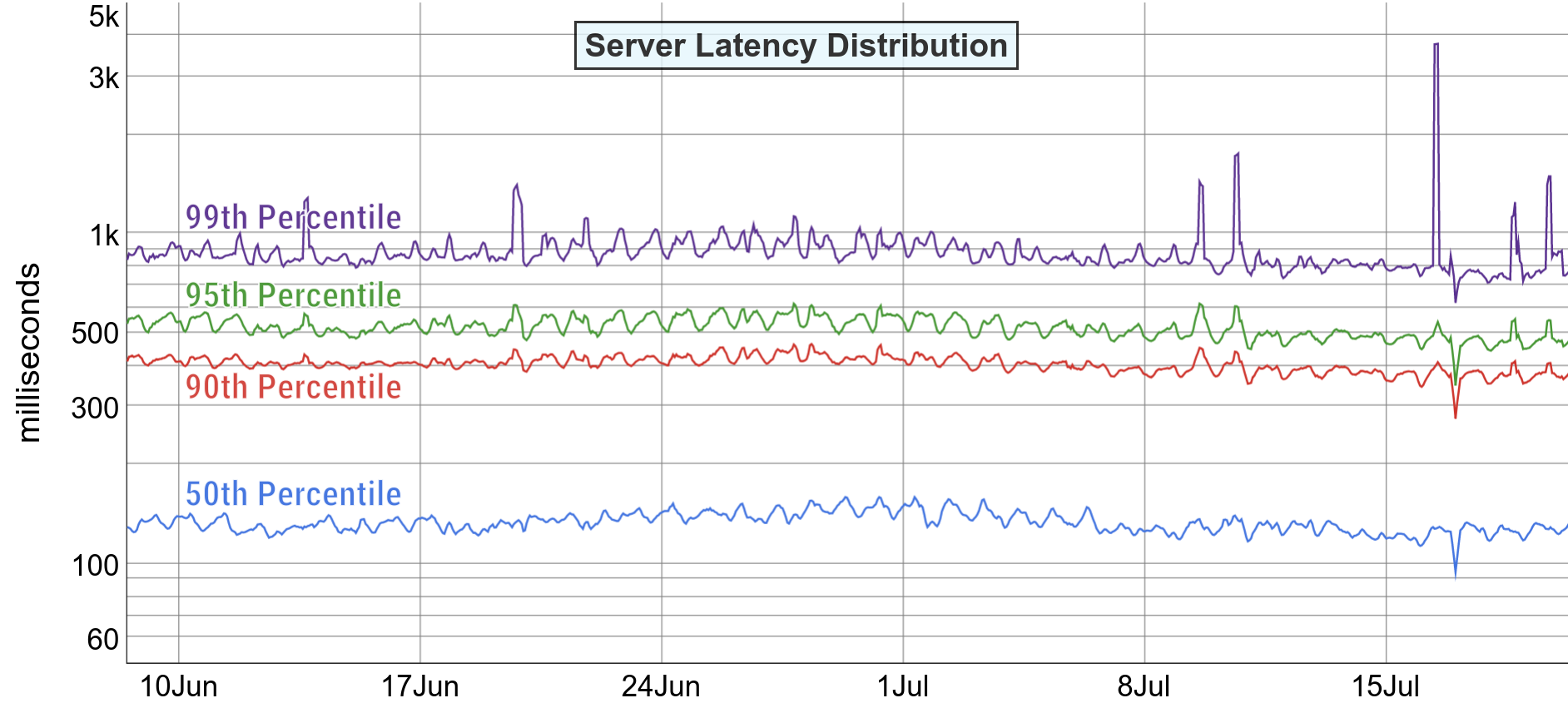
これらの SLI を過去の実績をもとに考えて、最終的な SLO はこのように定めました (The Art of SLOs – Slides p.69)。
| サービス | SLOの種類 | SLOの定義 |
|---|---|---|
| プロファイルページ | Availability | 過去28日間で99.95%の成功率 |
| プロファイルページ | Latency | 過去28日間で500ms以内のレスポンスが全体の90%以上 |
はい、これで一通り SLI / SLO の設定を行うことができました。この例題からも分かる通り、SLI/SLO はユーザーのサービスの利用法を深く考え、設定していく必要があります。また、最初の想定の SLI ではサービスの信頼性を拾いきれない場合も発生するので、その場合は柔軟に指標を見直し、改善を続けていくことが求められます。
まとめ
SLO とはなんでしょう?自分の大枠としての理解は「開発と運用のバランスを取るために、ユーザーのサービス満足度を維持することを境界とした指標」です。
この指標を導入することで、
- サービス自体の意思決定を定量的に行いやすくなる
- チャレンジを計画的にできるようになる(リスクの高い機能のリリースが戦略的に行えるようになる) といったメリットがあります。
自分自身、SLA / SLO / SLI という単語に対する理解は極めて曖昧でした。 上記の説明に基づくと SLI に関して「障害対応を障害発生から X 時間以内に行う」という設定の仕方は
- サービス側でハンドリングできない
- バジェットという概念に換算できない
ために、SLI の定義からはずれてしまうことが分かります(運用の観点としては適切ですが)。また、本来的には、カスタマーのユーザージャーニーに基づいて必要な SLI を定めるところから始めるべきです。
このように、SLO Workshop を行うことで、SLO がただの言葉通りの「サービスレベル目標」という意味を超えて、 サービスを最大限よりよく運用し、継続的な開発を定量的に行っていくというもっと大きな重要な意味を持った指標であることが分かると思います。
こうした認識をチーム内で揃えていくことで、チーム全体が SLO という指標を的確に理解し、チームの中でも同じ目線で会話ができるようになりました。
もしこの記事を読んで、SLO の認識が甘かったなと思う人は、この記事だけでなく是非チームで SLO Workshop をやってみてください。このブログでも簡単に説明はしましたが、実際にチームでこうした知識を共有し、Practice Exercise などを通じて自身でも SLO / SLI を考えていくことで自分たちの SLO 運用方法を見直すきっかけにもなるのではないかと期待しています。
参考資料
- Four Keys 〜自分たちの開発レベルを定量化してイケてる DevOps チームになろう〜
- これからはじめる 実践 SRE / SLO の監視をやってみよう
- B. Beyer et al., Site Reliability Engineering (O’Reilly, 2016)
- SRE の基本(2021 年版): SLI、SLA、SLO の比較
- The Art of SLOs
- Introducing Google Customer Reliability Engineering (CRE)
- Compute Engine Service Level Agreement (SLA)
一緒に働きませんか?
弊社では、事業を加速させるデータプロダクトの開発を始めとする様々な職種のエンジニアを募集しています。 興味のある方は以下の採用ページからご応募頂いたり、お気軽に私の Twitter (@sh_tatsuno) にご連絡をいただければと思います。
===========================
===========================

Knile データエンジニア
Sho Tatsuno
実家の猫を溺愛している
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


