はじめに
検索エンジニアリング1グループ(以下、検索1G)所属の安達です。 検索1Gは検索基盤を開発・運用するグループです。 今回、新たな検索基盤を開発し、本番リリースしたのでその事例について紹介します。
どんな検索基盤か
アーキテクチャ図は以下です。 検索1Gが管理しているリソースは、図中のSolrデータ更新バッチとフロントアプリケーションを除くすべてのリソースです。
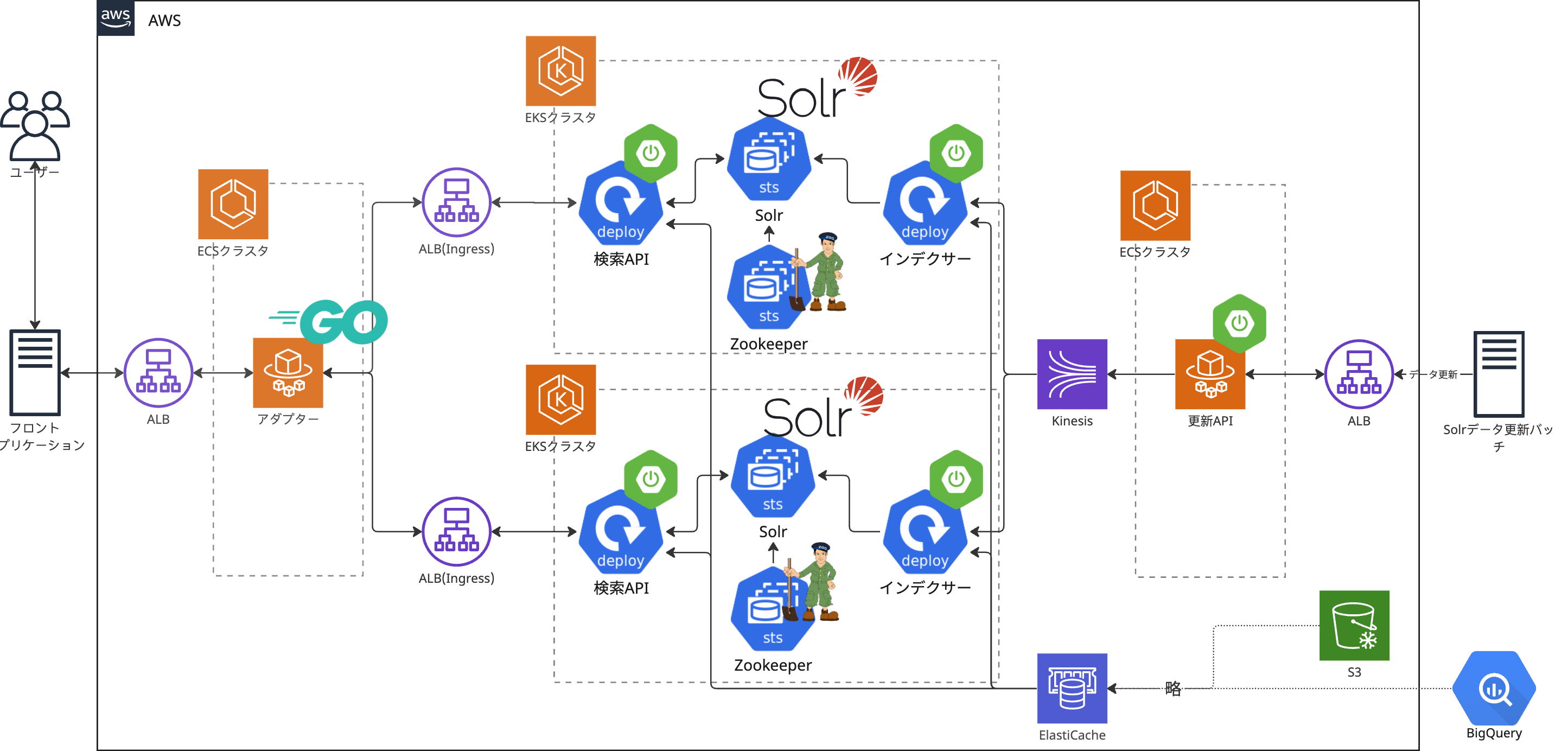
このシステムは大きく3つに分かれています。フロントアプリケーションとの接続を担う検索動線、検索に使われるデータの更新を担当するデータ更新導線、そして検索エンジンです。それぞれの構成について見ていきます。
検索導線
| コンポーネント | 役割 | 言語 | 実行環境 |
|---|---|---|---|
| アダプター | EKS上の検索APIへリクエストをルーティングする。通常時は何も処理をせず1つの検索APIにリクエストを流す。オンラインA/Bテスト実施時にはグループを振り分けし適切な検索APIにリクエストを振り分けできる。また、リクエストをミラーリングしサービスイン前の検索APIにも稼働中の検索APIリクエストと同じリクエストを横流ししテストできる。 | Go | ECS |
| 検索API | 検索ロジックの実装やSolrクエリを生成する。 | Kotlin(SpringBoot) | EKS |
データ更新導線
| コンポーネント | 役割 | 言語 | 実行環境 |
|---|---|---|---|
| 更新API | Solrデータ更新バッチからSolrデータ更新リクエストを受ける。そのSolrデータ更新リクエストはメッセージキューであるAmazon Kinesisへキューイングする。 | Java(SpringBoot) | ECS |
| Kinesis | Solrデータ更新リクエストをキューイングする。データ更新導線の可用性、スケーラビリティを向上させる。 | - | - |
| インデクサー | Kinesisからデータを取り出して、ElastiCacheからのデータとマージしたり整形したりしSolrにデータをインデキシングする。 | Java(SpringBoot) | EKS |
| ElastiCache | 検索ロジックに必要だがSolrデータ更新バッチから受け取るデータだけでは不十分な場合に、必要なデータをストアしておく。 | - | - |
| S3, BigQuery | ElastiCacheにストアする元となるデータ。 | - | - |
検索エンジン
| コンポーネント | 役割 | 実行環境 |
|---|---|---|
| Solr | 全文検索エンジン。検索APIからは検索リクエストを受け、インデクサーからはデータ更新リクエストを受ける。 | EKS |
| ZooKeeper | 構成管理やリーダー選出などSolrクラスタ管理、メタデータの保存と管理。 | EKS |
Solr+ZooKeeperのSolrCloud構成を採用しています。 SolrCloudは、Solrに分散機能を提供する構成で分散検索機能、インデックスのレプリケーション、自動フェイルオーバーとリカバリなどを提供します。 また、スケーラブルであり、新しいノードを追加することで容易に拡張できます。
SolrCloudについては こちらの記事 が参考になりましたので参照します。
なぜこの検索基盤か
既存システムやプロダクトも関係しますが、主要な理由としては拡張性と可用性の観点からこのアーキテクチャを選定しました。
拡張性
今後も継続的に検索改善を行う計画があり、この基盤では検索ロジックとSolrインデックスの改善が行いやすい構成になっています。
まず、検索導線に関しては検索APIの前段にアダプターを置くことで、検索APIを複数立ててアダプターによってリクエストを振り分けできA/Bテストを実施できます。 これにより自チームのみで検索改善できる範囲が広がり、例えば検索ロジックに閉じたA/Bテストなどは自チームのみで高速に開発できます。
データ更新導線に関してはメッセージキューであるKinesisに一度データを入れてしまえば、複数のEKSクラスタにそれぞれ構築されたSolrに対して同時にデータ更新できます。前述したアダプターがA/Bテストや負荷試験の際に適宜リクエストをそれぞれのEKSクラスタへ振り分けします。
また他チームが管理するSolrデータ更新バッチを修正せずともSolrインデックスの内容を変更することができるように、インデクサーがElastiCache、Kinesisの両方からデータを取得しマージしてSolrインデックスを作成できる構成をとっています。これによりステークホルダーが少なく高速に開発できる体制となりました。
可用性
この検索基盤は大規模プロダクトに投入される計画で、高い可用性が求められるため、それに応える構成になっています。
まず、全文検索エンジンとしてSolrCloudを選定しました。 ElasticsearchでなくSolrを選定した理由は、この検索基盤を導入するプロダクトが既存でSolrを利用しており移行のしやすさを優先したためです。 Elasticsearchを選定した場合、追加で機能差分調査や、検索クライアント開発工数、データ更新部分の開発工数等が発生したりする想定でした。
Solrの他の構成としてマスタースレーブ構成がありますがこちらは更新系でマスターノードが単一障害点になります。 SolrCloudであれば、更新を受けるリーダーノードが落ちたとしてもZooKeeperがよしなにリーダーを再選出してくれ更新系でも単一障害点がないです。 これにより、高い可用性を実現できます。
EKSを選定した理由は、KubernetesでSolrCloudの管理しやすくする Solr Operator が提供されているかつ、検索1Gの他の検索基盤でEKSの運用実績があるためです。
データ更新動線でデータ更新リクエストを一度Kinesisにキューイングしています。 これによりKinesisより先のインデクサーの処理遅延時や停止時にも、更新APIがリクエストを受けてKinesisまでデータを入れられます。 さらに、Kinesisにデータ更新リクエストが入っていれば、障害時やSolrバージョンアップ時などインデックス再作成したい時にリトライにより柔軟に実現できます。 今回のプロジェクトでは他チームの管理するSolrデータ更新バッチが失敗するとこのシステムだけでなく他のシステムにも影響がある可能性があったため、データ更新リクエストをそのままSolrへ送るのではなくKinesisを挟んだことは障害点が減り可用性観点でメリットがありました。
どのように導入したか
この検索基盤を導入する際の課題として、SolrCloudの運用実績が社内になく実際に開発・運用できるのか不確実性が高いということがありました。 そのために、他チームを巻き込んで開発する前に自チーム内でプロトタイプ開発をし、機能要件・非機能要件のテストを実施しました。 これは、プロジェクトとして走り出した後に、要件を実現できないと発覚して手戻りが発生しないようにするためです。
まず、テストするのに必要なコンポーネントである検索APIの検索ロジックの実装やSolrスキーマ・クエリの実装、データ更新部分(更新API,インデクサー)の実装をしました。
次に機能的要件としては、以前にこの検索基盤を導入する予定の画面に対してElasticsearchを利用して検証した検索ロジックがあり、その検索ロジックをSolrで実現できることが求められていました。先述したコンポーネントを利用してロジックを実装し実現できるとわかりました。
最後に非機能要件を満たすことを確認するために性能試験と耐障害性試験を行いました。 性能試験では、検索APIがSolrを利用して期待するスループット・レイテンシを実現できるか、更新API→Kinesis→インデクサー→Solrへのデータ更新が想定以上の遅延なく実現できるかを確認しました。 耐障害性試験では、SolrCloudに対してPodレベルやNodeレベルの障害を起こしてみて、期待通りにフェイルオーバーされ自動でリカバリされることを確認しました。
システムに問題がなかったため、他チームと実際に連携して本開発を進め、現在は本番環境で稼働しています。
おわりに
概要の紹介になりましたがSolrCloud on AWS EKSを使った検索基盤の導入事例の紹介をしました。 それぞれの技術の詳細については、別途紹介するかもしれません。
この検索基盤により高速に検索改善できる土壌ができたので、これからどんどん検索UI/UXを改善していく予定です。

ソフトウェアエンジニア(検索)
安達光太郎
2020年4月リクルート新卒入社。検索エンジニアリング1グループ所属。趣味はサーフィンとスノーボード、ポッドキャスト。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら