
はじめに
こんにちは。Kagglerの 中間 と 若月 です。業務では主に人材領域でのレコメンドシステムの改善に取り組んでいます。
この記事では、レコメンドシステムにTwo-Towerモデルと近似最近傍探索による候補生成ロジックを導入することで、精度とコストを改善することに成功したので、その取り組みについて紹介します。
背景
導入したロジックについて説明する前に、まず既存のレコメンドシステムについて簡単に説明します。
既存のレコメンドシステムでは、ユーザとアイテムについてルールベースによる候補生成を行った後、機械学習モデルを用いてスコアを付与し、スコア順にユーザに推薦するアイテムを選択していました。
しかし、ルールベースによる候補生成はベースラインとしてはよいものの、性能改善には限界があり、ルールベースが複雑になればなるほど計算コストもかかるようになっていきます。
そこで、性能改善がしやすく計算コストも抑えられる候補生成アプローチとして、Two-Towerモデルと近似最近傍探索による候補生成ロジックを導入することにしました。
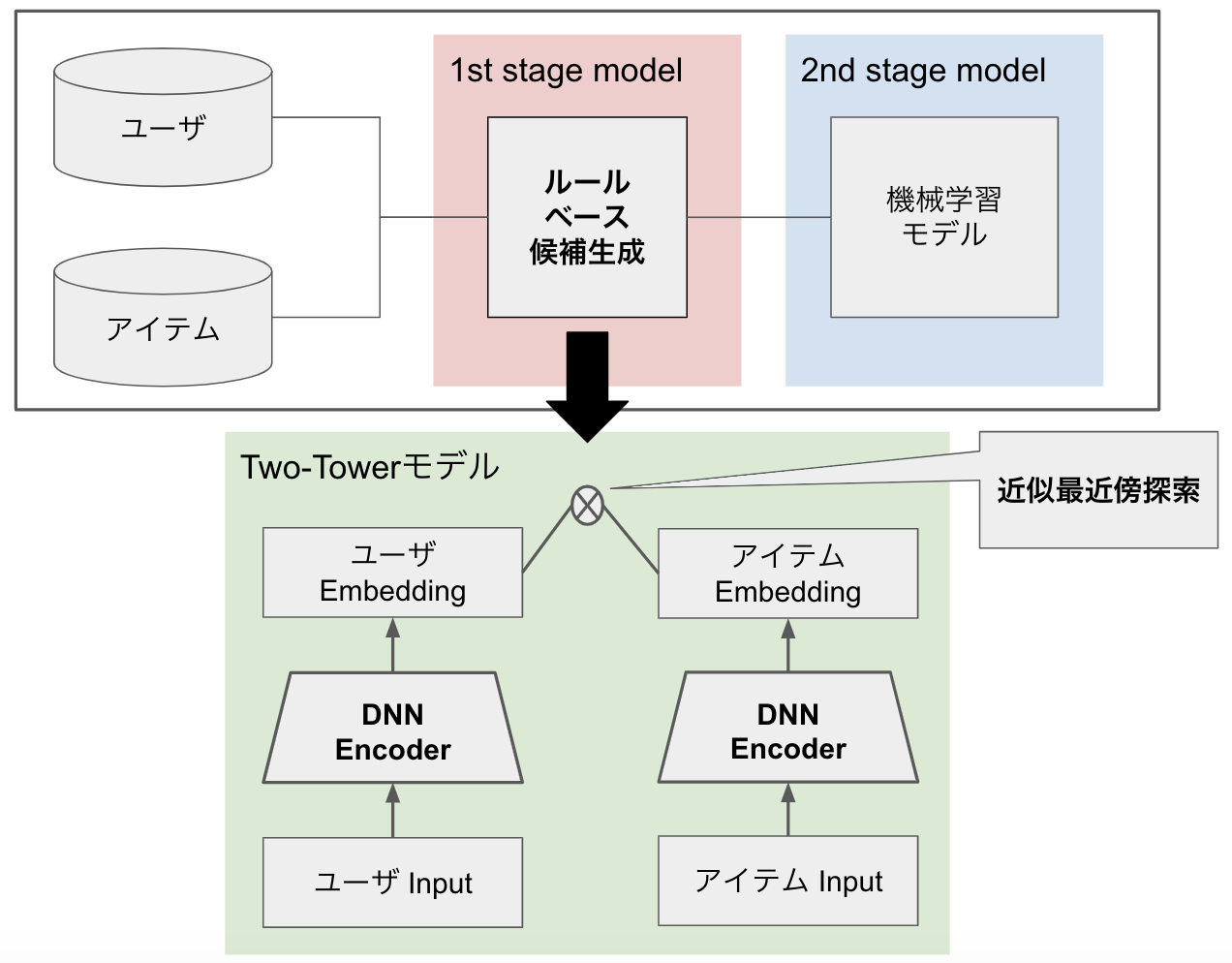
Two-Towerモデル
概要
Two-Towerモデルは、上記の図のように2つのDNN Encoderで構成されています。Two-Towerモデルの利点として、 Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations では、以下のように言及されています。
Most recently, two-tower neural networks, with towers referring to encoders based on deep neural network (DNN), attains growing interests, and are applied to tackle the challenge of cold-start issue of MF and multi-class extreme classification models. The basic idea is to further incorporate items’ content features through a multi-layer neural network that would generalize to fresh or tail items with no training data.
すなわち、Two-Towerモデルはユーザやアイテムの属性を加味したベクトルを生成することで、協調フィルタリングやMatrix Factorizationといったアプローチにおける問題点であるコールドスタート問題に対処することができます。自然言語や画像といった属性も加味しやすいので、性能改善の余地も大きいです。
以降では、実際の実装例について紹介します。
サンプルデータ
わかりやすくするため、以下のようなサンプルデータを準備しました。内容についてはコメントを参照してください。
# サンプルデータ
# (user|item)_num_xxはuserまたはitemの数値特徴量
# (user|item)_cat_xxはuserまたはitemのカテゴリ特徴量
# (user|item)_common_cat_xxはuserとitemでカテゴリ値が共通するカテゴリ特徴量(user側はrnkで順序に意味があるケース)
df = pd.DataFrame({
'item_num_1': [10, 100, 0, 10, 100, 0, 10, 100, 0, 10],
'item_cat_1': ['x', 'y', 'x', 'y', 'x', 'y', 'x', 'y', 'x', 'y'],
'item_common_cat_1': ['A', 'B', 'C', 'C', 'A', 'B', 'A', 'B', 'C', 'B'],
'user_num_1': [5, 8, 4, 1, 2, 4, 6, 9, 6, 2],
'user_cat_1': ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b'],
'user_common_cat_1_rnk_1': ['A', 'A', 'B', 'C', 'A', 'A', 'C', 'B', 'B', 'A'],
'user_common_cat_1_rnk_2': ['B', np.nan, np.nan, 'A', 'B', 'C', np.nan, 'C', 'A', 'C'],
'user_common_cat_1_rnk_3': ['C', np.nan, np.nan, np.nan, np.nan, 'B', np.nan, np.nan, np.nan, np.nan],
})
config
まず、実験管理がしやすいようにサンプルデータに対してconfigファイルを用意しました。
あくまでサンプルになりますが、ここではカテゴリ値のエンコーディングを行うカテゴリ特徴量と、モデルに関するパラメータ・特徴量を定義しています。
encoding_cat_features:
user_cat_1: ['user_cat_1']
item_cat_1: ['item_cat_1']
item_common_cat_1: [
'item_common_cat_1',
'user_common_cat_1_rnk_1',
'user_common_cat_1_rnk_2',
'user_common_cat_1_rnk_3',
]
model_config:
emb_size: 10
item_cat_hidden_size: 16
item_num_hidden_size: 16
user_cat_hidden_size: 16
user_num_hidden_size: 16
item_common_cat_1_col: 'item_common_cat_1'
item_num_cols: ['item_num_1']
item_cat_cols: ['item_cat_1']
user_common_cat_1_cols: [
'user_common_cat_1_rnk_1',
'user_common_cat_1_rnk_2',
'user_common_cat_1_rnk_3',
]
user_num_cols: ['user_num_1']
user_cat_cols: ['user_cat_1']
train_batch_size: 4
num_workers: 4
データの前処理
次に、データの前処理についてです。
DNNモデルを作成する際は、必要に応じて数値特徴量とカテゴリ特徴量に前処理をする必要があります。
今回は、以下のような前処理を行いました。
- 数値特徴量の前処理
sklearn.preprocessing.StandardScalerやsklearn.preprocessing.RobustScalerも試しましたが、np.log1pを適用して標準化の代わりとするパターンが一番性能が良かったです。総当たりで試してみて、一番性能が良いパターンを適用できると良さそうです。
def numerical_preprocess(df, num_cols):
"""対数変換しておく"""
for c in num_cols:
df[c] = np.log1p(df[c])
return df
- カテゴリ特徴量の前処理
- カテゴリ値のエンコーディングを行い、embeddingのsizeは下記のようにカテゴリ値のユニーク数に応じて決めるようにしました。このようにしておくことで、各カテゴリ特徴量について手動でembeddingのsizeを決める必要がなくなります。このあたりのパラメータチューニングをしないのであれば無難なやり方かと思います。
def define_cat_dim(dim: int, min_emb_size: int = 50):
"""
Rule of thumb to pick embedding size corresponding to dim.
ref: https://github.com/fastai/fastai/blob/master/fastai/tabular/model.py#L12-L16
"""
cat_dim = (dim + 1, min(min_emb_size, round(1.6 * dim**0.56))) # unknown: 0
return cat_dim
データセットの定義
データに前処理をした後は、データセットを定義します。
import torch
from torch.utils.data import Dataset
class TrainDataset(Dataset):
def __init__(self, cfg, df):
self.cfg = cfg
self.n = df.shape[0]
self.item_common_cat_1 = df[cfg["item_common_cat_1_col"]].fillna(0).values
self.item_num_features = df[cfg["item_num_cols"]].fillna(0).values
self.item_cat_features = df[cfg["item_cat_cols"]].fillna(0).values
self.user_common_cat_1 = df[cfg["user_common_cat_1_cols"]].fillna(0).values
self.user_num_features = df[cfg["user_num_cols"]].fillna(0).values
self.user_cat_features = df[cfg["user_cat_cols"]].fillna(0).values
def __len__(self):
return self.n
def __getitem__(self, item):
item_common_cat_1 = torch.tensor(self.item_common_cat_1[item], dtype=torch.long)
item_num_feature = torch.tensor(self.item_num_features[item], dtype=torch.float)
item_cat_feature = torch.tensor(self.item_cat_features[item], dtype=torch.long)
user_common_cat_1 = torch.tensor(self.user_common_cat_1[item], dtype=torch.long)
user_num_feature = torch.tensor(self.user_num_features[item], dtype=torch.float)
user_cat_feature = torch.tensor(self.user_cat_features[item], dtype=torch.long)
inputs = {
"item_num_feature": item_num_feature,
"item_cat_feature": item_cat_feature,
"item_common_cat_1": item_common_cat_1,
"user_num_feature": user_num_feature,
"user_cat_feature": user_cat_feature,
"user_common_cat_1": user_common_cat_1,
}
return inputs
モデル定義
次に、DNNのモデルを定義します。
本来のモデル定義を適宜書き換えていますが、大枠は変わりません。
import torch
import torch.nn as nn
class ItemEmbeddingModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.cat_emb = nn.ModuleList([nn.Embedding(x, y, padding_idx=0) for x, y in cfg["item_cat_dims"]])
n_cat_emb_out = sum([y for x, y in cfg["item_cat_dims"]])
self.cat_proj = nn.Sequential(
nn.Linear(n_cat_emb_out, cfg["item_cat_hidden_size"]),
nn.LayerNorm(cfg["item_cat_hidden_size"]),
)
self._init_weight(self.cat_proj)
self.num_emb = nn.Sequential(
nn.BatchNorm1d(len(cfg["item_num_cols"])),
nn.Linear(len(cfg["item_num_cols"]), cfg["item_num_hidden_size"]),
nn.BatchNorm1d(cfg["item_num_hidden_size"]),
nn.LeakyReLU(),
nn.Linear(cfg["item_num_hidden_size"], cfg["item_num_hidden_size"]),
nn.BatchNorm1d(cfg["item_num_hidden_size"]),
nn.LeakyReLU(),
)
self._init_weight(self.num_emb)
head_hidden_size = (
cfg["item_cat_hidden_size"]
+ cfg["item_num_hidden_size"]
+ cfg["item_common_cat_1"][1]
)
self.head = nn.Sequential(
nn.Linear(head_hidden_size, head_hidden_size),
nn.BatchNorm1d(head_hidden_size),
nn.LeakyReLU(),
nn.Linear(head_hidden_size, cfg["emb_size"]),
)
self._init_weight(self.head)
def _init_weight(self, module):
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def forward(
self,
num_features,
cat_features,
common_cat_1_embs
):
# num_embs
num_embs = self.num_emb(num_features)
# cat_embs
cat_embs = [emb_layer(cat_features[:, j]) for j, emb_layer in enumerate(self.cat_emb)]
cat_embs = torch.cat(cat_embs, 1)
cat_embs = self.cat_proj(cat_embs)
# concat_embs
concat_embs = torch.cat((num_embs, cat_embs, common_cat_1_embs), 1)
embs = self.head(concat_embs)
# normalized features
embs = embs / embs.norm(dim=-1, keepdim=True)
return embs
class UserEmbeddingModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.common_cat_1_weights = nn.Parameter(torch.tensor([1] * len(cfg["user_common_cat_1_cols"]), dtype=torch.float))
self.cat_emb = nn.ModuleList([nn.Embedding(x, y, padding_idx=0) for x, y in cfg["user_cat_dims"]])
n_cat_emb_out = sum([y for x, y in cfg["user_cat_dims"]])
self.cat_proj = nn.Sequential(
nn.Linear(n_cat_emb_out, cfg["user_cat_hidden_size"]),
nn.LayerNorm(cfg["user_cat_hidden_size"]),
)
self._init_weight(self.cat_proj)
self.num_emb = nn.Sequential(
nn.BatchNorm1d(len(cfg["user_num_cols"])),
nn.Linear(len(cfg["user_num_cols"]), cfg["user_num_hidden_size"]),
nn.BatchNorm1d(cfg["user_num_hidden_size"]),
nn.LeakyReLU(),
nn.Linear(cfg["user_num_hidden_size"], cfg["user_num_hidden_size"]),
nn.BatchNorm1d(cfg["user_num_hidden_size"]),
nn.LeakyReLU(),
)
self._init_weight(self.num_emb)
head_hidden_size = cfg["user_cat_hidden_size"] + cfg["user_num_hidden_size"] + cfg["item_common_cat_1"][1]
self.head = nn.Sequential(
nn.Linear(head_hidden_size, head_hidden_size),
nn.BatchNorm1d(head_hidden_size),
nn.LeakyReLU(),
nn.Linear(head_hidden_size, cfg["emb_size"]),
)
self._init_weight(self.head)
def _init_weight(self, module):
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def forward(
self,
num_features,
cat_features,
common_cat_1_embs,
common_cat_1_mask
):
# common_cat_1_embs
common_cat_1_embs = common_cat_1_embs.permute(1, 0, 2) # (n, bs, emb_size)
common_cat_1_weights = self.common_cat_1_weights.unsqueeze(-1).unsqueeze(-1).expand(common_cat_1_embs.size())
common_cat_1_weights = common_cat_1_weights * common_cat_1_mask.permute(1, 0).unsqueeze(-1).expand(common_cat_1_embs.size())
common_cat_1_sum_embs = (common_cat_1_weights * common_cat_1_embs).sum(dim=0)
common_cat_1_avg_embs = common_cat_1_sum_embs / ((self.common_cat_1_weights * common_cat_1_mask).sum(dim=1).unsqueeze(-1) + 1e-9)
# num_embs
num_embs = self.num_emb(num_features)
# cat_embs
cat_embs = [emb_layer(cat_features[:, j]) for j, emb_layer in enumerate(self.cat_emb)]
cat_embs = torch.cat(cat_embs, 1)
cat_embs = self.cat_proj(cat_embs)
# concat_embs
concat_embs = torch.cat((num_embs, cat_embs, common_cat_1_avg_embs), 1)
embs = self.head(concat_embs)
# normalized features
embs = embs / embs.norm(dim=-1, keepdim=True)
return embs
class TwoTowerModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.common_cat_1_emb = nn.Embedding(cfg["item_common_cat_1"][0], cfg["item_common_cat_1"][1], padding_idx=0)
self.item_emb_model = ItemEmbeddingModel(cfg)
self.user_emb_model = UserEmbeddingModel(cfg)
self.logit_scale = nn.Parameter(torch.ones([]) * 2.5)
def item_embs(self, inputs):
item_common_cat_1_emb = self.common_cat_1_emb(inputs["item_common_cat_1"])
item_embs = self.item_emb_model(
inputs["item_num_feature"],
inputs["item_cat_feature"],
item_common_cat_1_emb,
)
return item_embs
def user_embs(self, inputs):
user_common_cat_1_mask = inputs["user_common_cat_1"] != 0
user_common_cat_1_embs = self.common_cat_1_emb(inputs["user_common_cat_1"])
user_embs = self.user_emb_model(
inputs["user_num_feature"],
inputs["user_cat_feature"],
user_common_cat_1_embs,
user_common_cat_1_mask,
)
return user_embs
def forward(self, inputs):
item_embs = self.item_embs(inputs)
user_embs = self.user_embs(inputs)
logit_scale = self.logit_scale.exp()
logits = torch.matmul(user_embs, item_embs.T) * logit_scale
return logits
ItemEmbeddingModelとUserEmbeddingModelの2つのDNN Encoderがあり、それぞれアイテムとユーザの特徴量を入力として指定したsizeのembeddingを出力します。
TwoTowerModelはItemEmbeddingModelとUserEmbeddingModelで出力されたembeddingの類似度を計算するのみでなく、アイテムとユーザの間でカテゴリ値が共通するカテゴリ特徴量について、共通のembedding layerを持つようになっています。そして
CLIP
と同様に、logitsの計算の部分では温度付きの計算をするようにしています。
また(user|item)_common_cat_xxはuserとitemでカテゴリ値が共通するカテゴリ特徴量で、user側はrnkで順序に意味があるので、rnkごとのembeddingについて加重平均を取るようにするということもしています。
損失関数
ユーザとアイテムの対照学習を行うので、以下のような損失関数を使用します。
対照学習については、弊社の
こちらのブログ
で詳しく解説しています。
def contrastive_loss(logits):
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
学習
あとは学習を回すだけです。
ここまで見てきた実装もまとめると、以下のようになります。
# config
with open("config.yml") as f:
config = yaml.safe_load(f)
model_config = config["model_config"] # モデルと特徴量の定義パラメータ
encoding_cat_features = config["encoding_cat_features"] # エンコーディングするカテゴリ特徴量
# 数値特徴量の前処理(今回のサンプルデータには存在しないが前処理が必要でないembedding特徴量は前処理の対象から除外)
preprocess_item_num_cols = [c for c in model_config["item_num_cols"] if not c.find("_emb_") >= 0]
preprocess_user_num_cols = [c for c in model_config["user_num_cols"] if not c.find("_emb_") >= 0]
preprocess_num_cols = preprocess_item_num_cols + preprocess_user_num_cols
df = numerical_preprocess(df, num_cols=preprocess_num_cols)
# カテゴリ特徴量の前処理
encoding_cat_features_dict = {} # 予測用
for col, cols in encoding_cat_features.items():
# category encoding
categories = set()
for c in cols:
categories = categories | set(df[df[c].notnull()][c].values)
categories = list(sorted(categories))
encoding_cat_feature_dict = dict([(c, i + 1) for i, c in enumerate(categories)])
encoding_cat_features_dict[col] = encoding_cat_feature_dict
for c in cols:
df[c] = df[c].map(encoding_cat_feature_dict).fillna(0).astype(int).values
# define embedding size
model_config[col] = define_cat_dim(dim=len(categories))
# embedding size を item, user ごとに保持
model_config["item_cat_dims"] = [model_config[c] for c in model_config["item_cat_cols"]]
model_config["user_cat_dims"] = [model_config[c] for c in model_config["user_cat_cols"]]
# データセット定義
train_dataset = TrainDataset(model_config, df)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=model_config["train_batch_size"],
shuffle=True,
num_workers=model_config["num_workers"],
pin_memory=True,
drop_last=True,
)
# モデル学習(ここではloss算出まで)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = TwoTowerModel(model_config)
model.to(device)
model.train()
for step, inputs in enumerate(train_loader):
for k, v in inputs.items():
inputs[k] = v.to(device)
y_preds = model(inputs)
loss = contrastive_loss(y_preds)
ここまでが、今回導入したTwo-Towerモデルの実装の主な部分になります。
この実装紹介によって、Two-Towerモデル導入のハードルが少しでも下がれば幸いです。
近似最近傍探索
Two-Towerモデルの学習が完了した後は、類似したユーザとアイテムのembeddingが近い位置に配置されるようになっています。レコメンドシステム上での推論時には、各ユーザに対して、データベース内のすべてのアイテムから2nd stageモデルの推論対象となる類似したアイテムを取得する必要があります。
近似最近傍探索は、指定したベクトルに近いベクトルを高速に近似的に取得する方法です。近似最近傍探索を行うためのさまざまなライブラリが公開されています。どのライブラリも簡単に使用することができ、検索対象のベクトルのリストを入力してインデックスを構築し、その後、入力したベクトルに近いベクトルを高速に検索できます。 ANN Benchmarks では、再現率、検索速度、インデックスの構築速度などの観点で比較が行われています。今回のプロジェクトではこのベンチマークおよび実データでの比較に基づいて、 scann を採用しました。
以下はscannを使う部分のコード例です。
class ANNSearcher:
# https://github.com/google-research/google-research/blob/master/scann/docs/example.ipynb
def build(self, embeddings: np.ndarray) -> None:
MAX_NEIGHBORS = 2000 # reordering_num_neighbors should be greater than final_num_neighbors
num_datapoints = len(embeddings)
num_leaves = int(np.sqrt(num_datapoints)) # should be roughly the sqrt of the num of datapoints.
num_leaves_to_search = int(num_leaves * 0.2)
training_sample_size = int(num_datapoints * 0.9)
self.searcher = (
scann.scann_ops_pybind.builder(embeddings, 1000, "dot_product")
.tree(
num_leaves=num_leaves,
num_leaves_to_search=num_leaves_to_search,
training_sample_size=training_sample_size,
)
.score_ah(2, anisotropic_quantization_threshold=0.2)
.reorder(MAX_NEIGHBORS)
.build()
)
def search(self, embedding: np.ndarray, num_neighbors: int) -> tuple[np.ndarray, np.ndarray]:
if num_neighbors == 0:
return np.array([], dtype=np.int64), np.array([], dtype=np.float64)
idxs, similarities = self.searcher.search(embedding, final_num_neighbors=num_neighbors)
return np.array(idxs, dtype=np.int64), np.array(similarities, dtype=np.float64)
buildにアイテムのembeddingのリストを入力してインデックスをビルドし、searchにユーザのembeddingと取得したい近傍数を入力して近傍探索を行います。ユーザとアイテム間の類似度(=内積)も別の箇所で利用しているので、それも返すようにしています。
scannに与えるパラメータのチューニングは
ScaNN Algorithms and Configuration
を参考に行いました。
既存のレコメンドシステムでは、1日に1回のバッチ処理で全ユーザに対して推論を行い、推薦リストを生成しています。1st stageモデルをルールベースからTwo-Towerモデルに置き換えた後も同様のタイミングで推論を行うとし、1日に1回全ユーザと全アイテムのembeddingを更新します。既存のコードでは、すべてのアイテムの特徴量をnumpy配列としてメモリに読み込み、各ユーザごとにnumpyでフィルタリング処理を行っています。その部分を変更し、すべてのアイテムのembeddingを読み込み、インデックスを構築した後、各ユーザごとに近似最近傍探索によるフィルタリングの処理を行うようにします。実データに対しては、インデックスの構築は10秒程度で済み、1ユーザあたり1ミリ秒未満の速さで類似アイテムの検索ができました。
この改善により、既存のロジックと比較して、推薦の精度や効率性が向上しました。また、近似最近傍探索によるフィルタリング処理はルールベースでの処理と比べて大規模なデータセットに対してもスケーラブルであり、リアルタイムのレコメンドシステムにも適しています。
おわりに
最後まで読んでいただきありがとうございました。 膨大なユーザとアイテムを扱うレコメンドシステムにおいて、Two-Towerモデルと近似最近傍探索はとても有効であることがわかりました。
一緒に働きませんか?
当社では、様々な職種のエンジニアを新卒・中途ともに募集しております。ご興味のある方は、以下の採用ページをご覧ください。

最近は人材領域でのデータ周りの分析などを担当
中間康文
リクルートグループ新卒入社3年目。Kaggle Competitions & Notebooks Grandmaster。

最近は人材領域でのデータ周りの分析などを担当
若月良平
リクルートグループ新卒入社6年目。プログラミングのコンテストやスプラトゥーンが好き。Kaggle Competitions Master。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


