
はじめに
機械学習エンジニアの荒居秀尚です。2021年新卒入社で、機械学習モデリングや機械学習を用いたデータ施策におけるMLOps推進などに携わっています。
最近、担当案件で画像を扱っていたのもあり、画像を対象とした自己教師あり表現学習について調査していました。今回はその調査内容について紹介したいと思います。なお、この調査は文献調査と、実際に使ってみて案件への適用可能性を評価した実験とに分かれていますので、ブログの方も両方について触れようと思います。
分量が多いため、自己教師あり学習の基礎の部分の紹介、具体的な手法の紹介、そして応用例の紹介の三部立ての構成になっています。
前回の記事 では、自己教師あり学習が近年大きく発展している背景と、画像を対象とした自己教師あり学習の部品となる技術の紹介を行いました。それを踏まえ、今回は具体的な手法について紹介を行います。
おさらい
代表的手法の紹介に入る前に、一般的な枠組みについておさらいします。自己教師あり表現学習の目標は、様々なタスクに対して有用なデータの表現(Embedding)を作成するような特徴抽出器(Encoder)を、教師ラベルを用いずに学習させることでした。
下の図は、近年の研究に多く見られる自己教師あり学習の一般的な枠組みを図として表したものです。細かい点においてはこの図にない要素があったり、逆にこの図にある要素とは異なる部分もあったりするのですが、多くの研究がこの枠組みに乗った形で新しい手法を提案しています。
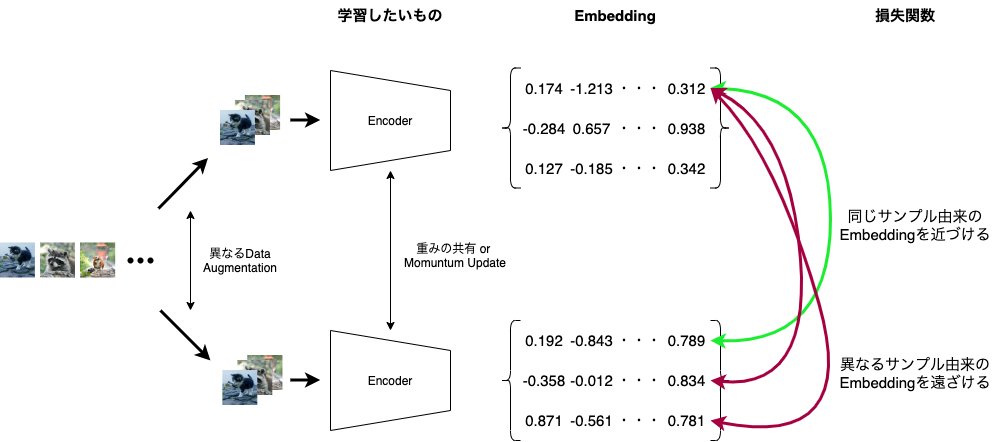
この図を見ながら、おさらいをします。
まず、学習に用いられるデータに様々な変換(Data Augmentation)を施します。この際、互いに異なる2パターンの変換が各画像に施されるようにします。
続いて、Encoderに変換後のデータを通し、Embeddingを得ます。変換されたデータは各画像につき2つずつあるため、Encoderも2つ用意します(Siamese Architecture)。これらのEncoderは重みを共有しているか、片方の重みがもう片方の重みの指数移動平均になっている(Momentum Encoder)ことが一般的です。
最後に、2つのEncoderから得られたEmbeddingを比較するような損失関数を用いて損失を計算し、損失を最小化するようにEncoderの重みを学習します。この際に、同じサンプルから得られたEmbeddingどうしを近づけるようにするのですが、それだけだと全てのサンプルに対してEncoderの出力が同じになる崩壊と呼ばれる現象が起きやすくなってしまいます。
これを防ぐため、異なるサンプルから得られたEmbedding(負例)どうしを遠ざけるようにするのが、対照学習と呼ばれる手法です。一方、対照学習は一般にバッチサイズを大きくしないといけないという問題が指摘されていることもあり、近年はその他の工夫によって負例を用いずに崩壊を起こさないような学習を進める手法も提案されています。
代表的手法の紹介
前回の記事 では、Siamese ArchitectureやContrastive Lossなど、画像の自己教師あり表現学習の部品となるような技術についての紹介を行いました。今回は、自己教師あり学習の各手法を紹介していきますが、それぞれの手法を要素に分解してみると前回の記事で紹介した部品の組み合わせになっていることがわかるかと思います。
MoCo
| 項目名 | |
|---|---|
| 論文 | He, Kaiming, et al. “Momentum contrast for unsupervised visual representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. |
| 発表年 | 2019 |
| 会議 | CVPR2020 |
| 研究機関 | Facebook AI Research |
| 著者 | Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick |
MoCoはFacebook AI Research1から2019年に提案された手法で、対照学習によって画像のEmbeddingの近さを測るプロセスを一種の辞書引きのようなものと捉える考え方に立っています。MoCoでは、一方のEncoderの出力を辞書引きのクエリ(q)と見たて、もう一方のEncoderを動的な辞書のようなものだと捉えます。
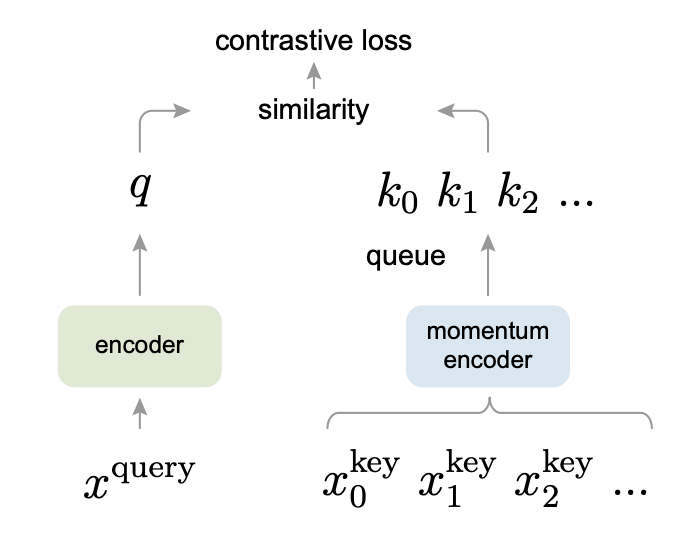
辞書の役割のEncoderにサンプルを入れて得られるEmbeddingが辞書のキー(k)となり、辞書の値(value)はそれぞれのサンプルの元となったオリジナルのサンプルです。
MoCoで特徴的な点をあげるとするならば、負例をキューに入れることで計算の効率化を測っている点でしょう。なぜこのような仕組みを用いているかを説明するために対照学習における一般的な負例の扱い方を二つ紹介します。
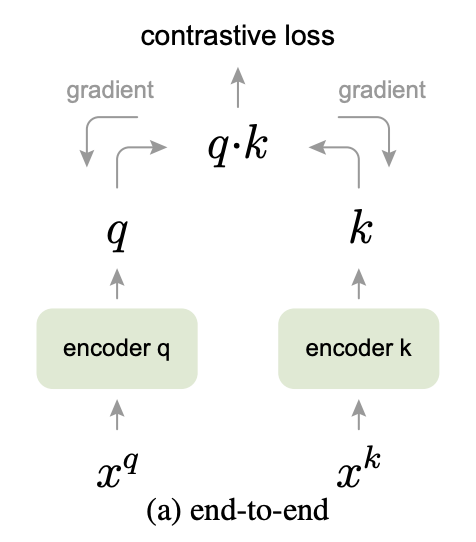
まず、論文中でend-to-endと呼ばれている方法についてです。この方法では、2つのEncoderの出力はどちらも学習に用いられます。この場合、同じバッチ内にあるサンプルが負例にあたります。
今、バッチ内のあるサンプルに注目した場合、同じバッチ内にある他のサンプルは別のデータ由来のサンプルとなります。これらを負例として扱うのがこのアプローチですが、バッチサイズが負例の数を決めてしまうため、負例を多くして学習を効率よく行うためにはバッチサイズを大きくする必要があります。
バッチサイズは際限なく大きくできるわけではなく、学習に用いるデバイスのメモリのサイズに依存してしまうことがこの手法の問題点として指摘されています。
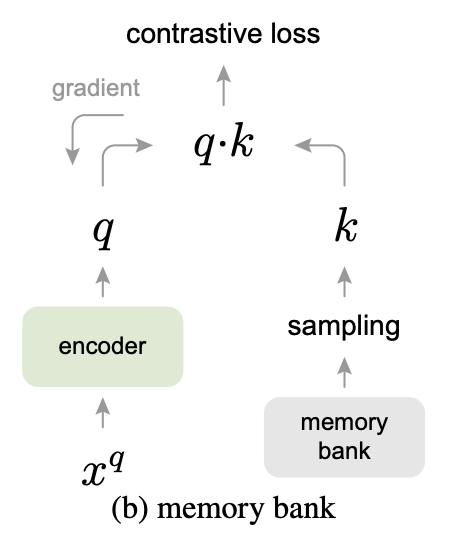
一方、論文中でMemory bankと呼ばれるアプローチでは、データセット内の全サンプルのEmbeddingを保持しておき、学習時にはそこからランダムにサンプリングをすることで負例を得ます。このやり方では、負例の数はバッチサイズによらず大きくできるというのがメリットですが、メモリバンク内のEmbeddingの更新は負例としてサンプルされたときに行われるのが一般的なため、学習が進んだEncoderの出力するEmbeddingとの一貫性が低くなりやすいという欠点もあります。
さて、MoCoのやり方はこれら二つのアプローチのちょうど中間のようなものになっています。MoCoでは、負例の数をバッチサイズによらない大きさにしたいため、負例を貯めておくキューを用います。キューには負例のEmbeddingが格納されています。
毎ステップ学習が進むたびに、バッチをMomentum Encoderに通して得たEmbeddingが得られるため、それをキューに追加し同じ分だけキューからサンプルを取り除いていきます。こうすることで、メモリバンクの問題として挙げられていた、学習が進んだEncoderの出力するEmbeddingと負例のEmbeddingの一貫性が低くなりやすいという問題を解消することができます。
MoCoの論文ではend-to-endアプローチ、memory bankアプローチと比較して、それぞれの手法を用いた場合の負例の数とLinear Classification Protocolにおけるaccuracyの関係を示しています。これによると、end-to-endとMoCoは同じ負例の数でほぼ同等のaccuracyを達成できる一方で、end-to-endではミニバッチのサイズに負例の数がキャップされてしまうため、負例の数が1024より大きい場合は検証できなかったと報告されています。一方、メモリバンクを用いたアプローチでは負例の数は大きくできる一方で、end-to-endやMoCoに対してaccuracyが劣るという結果になっています。
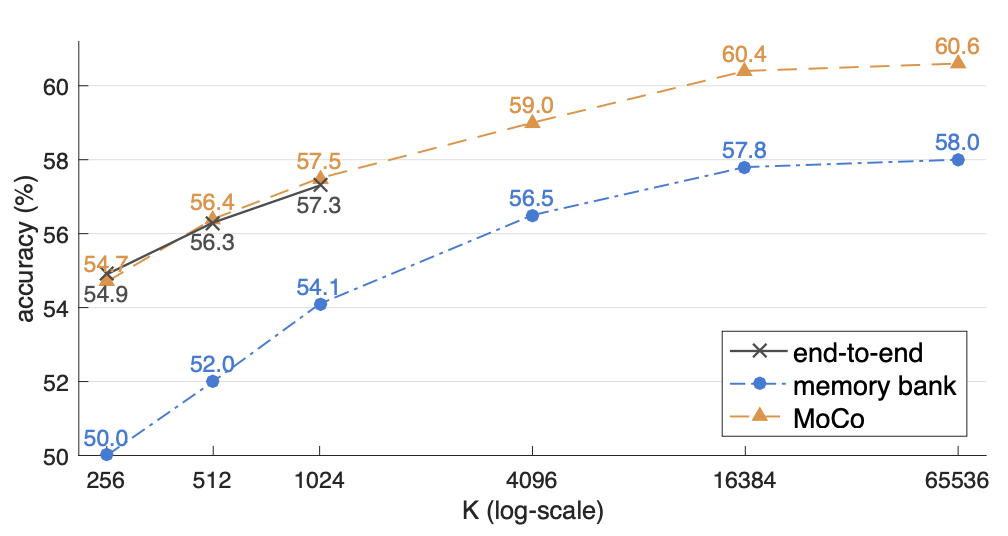
MoCoはレポジトリ2もよく整備されており実装もわかりやすいため一見の価値があります。負例をキューに保持する部分などは概念的に少しわかりづらい点もあるため、実装も是非参照してみてください。
SimCLR
| 項目名 | |
|---|---|
| 論文 | Chan, Ting, et al. “A simple framework for contrastive learning of visual representations.” International conference on machine learning. PMLR, 2020. |
| 発表年 | 2020 |
| 会議 | ICML2020 |
| 研究機関 | Google Research |
| 著者 | Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton |

SimCLRは、それまでの自己教師あり表現学習手法が過度に複雑であると指摘し、シンプルなアプローチでも性能の高い表現学習を行うことができることを示した論文です。SimCLRはまた、性能向上をするにあたって寄与した3つの要素について丁寧に紹介しており、その後の様々な手法の発展にも影響を与えました。
SimCLRについては論文以外にも公式のブログ3が非常に簡潔にまとめていますのでぜひ参照してみてください。
まずはSimCLRがどのような手法なのか簡単に説明します。これまで紹介した手法と同様に、SimCLRはまずデータをランダムに選び出し、変換を施します。このとき、変換は
- Random Crop
- Random Color Distortion
- Gaussian Blur
の内の2つを組み合わせたものが用いられます。2通りの組み合わせによって同じ画像を変換し、同じ画像に由来する2つの画像を作成します。
続いて、SimCLRはResNetをベースとした畳み込みニューラルネットワークを用いて画像の表現を得ます。同じ画像由来の画像が2セットあるので、SimCLRが独特なのはこの後に全結合層を用いて画像の表現にさらに非線形変換をかけることです。
最後に、Contrastive Lossを最小化するように勾配降下法によってEncoderとその後に続く全結合層の重みを更新していきます。全体としてみると、MoCoの節で紹介したend-to-endなアプローチとなっており、バッチ内の他のサンプルを負例とみなして学習を行います。
SimCLRは次の3つの要素が、性能向上に大きく寄与したと報告しています。
- 画像に施す変換の「組み合わせ」
- Encoderの後に続く、非線形の全結合層(
projection) - スケールアップ(バッチサイズ、ネットワークのサイズ、学習のエポック数などを大きくすること)
それぞれについて簡単に説明します。
画像に施す変換の「組み合わせ」の重要性
まず、画像に施す変換の「組み合わせ」についてですが、この内容は 前回の記事 でも紹介したものになります。
SimCLRの論文では、Data Augmentationの組み合わせの効果を測るために次のような手順で実験を行っています。
- データセット内には異なるアスペクト比の画像が含まれるため、全画像についてCropとResizeを行う
- Crop・Cutout・Color distiortion・Sobel filtering・Gaussian Noise・Gaussian Blur・Rotateの中から重複を許して2種類を選び組み合わせを作る
- SimCLRの片方のEncoderでは2で作成した変換をかけた画像を、もう片方には無変換の画像を入力して学習を行う
- 学習後のEmbeddingを用いてlinear evaluation protocolで評価を行う

この結果は次の図のようになったと報告されています。
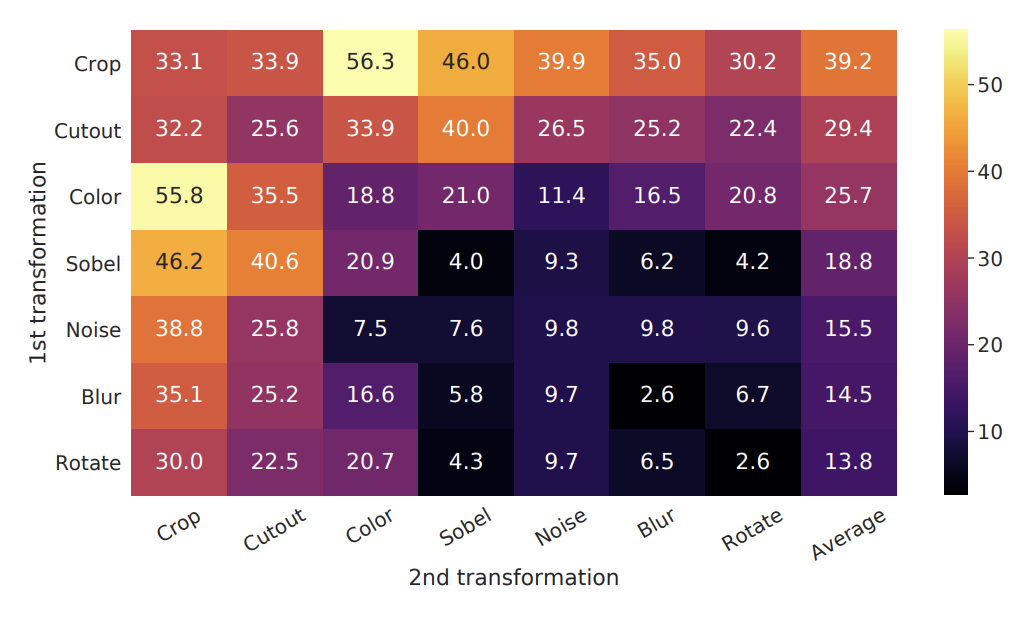
この図を見ると、組み合せの選び方が非常に重要であることがわかります。CropとColor Distortionの組み合わせはLinear Evaluationで56.3%というスコアを出している一方で、一番低いGaussian BlurとRotateという組み合わせは2.6%と、一番いい組み合わせと一番悪い組み合わせの差は50%以上にもなっています。
CropとColor Distortionの組み合わせについてですが論文中では、Crop単体だと同じ画像由来の画像ペアは色の配合が類似しているので正例を当てる事前学習タスクが簡単に行えるようになってしまい、よい表現を学習することにつながりづらいので色を変化させることが重要であると説明されています。
Encoderの後に続く、非線形の全結合層の重要性
SimCLRで特徴的な点として、Encoderの後にprojection headと呼ばれる全結合層を導入していることが挙げられます。下の図は、このprojection headについてハイパーパラメータを変更しながら、linear evaluationにおける結果を計測し比較したものです。
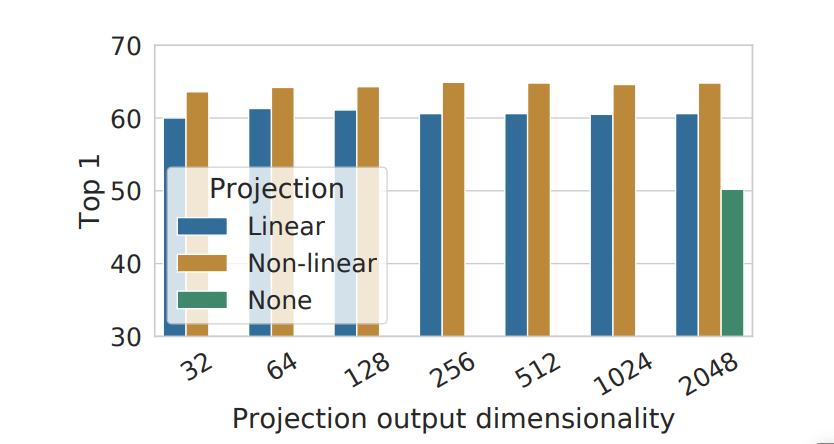
この図を見ると、projection headの次元は最終的な結果に大きな変化を及ぼさない一方で、非線形なprojection headがあることが重要であることがわかります。非線形なprojection headは線形なprojection headに比べて3%程度、projection headを用いない場合と比べて10%以上もlinear evaluationの結果がよくなると論文中では報告されています。
この結果は、その後の他の手法にも影響を与えており、例えばMoCoの改良として提案されたMoCo v24でも採用されています。
スケールアップの重要性
SimCLRの論文では、モデルのパラメータ数やバッチサイズ、学習のエポック数などを増やした場合のlinear evaluationの結果についても検証を行い、次のような結果を報告しています。
- モデルのパラメータ数が多い場合、最終的な結果がよくなる傾向にある。これは教師あり学習の場合でも同じであるが、教師あり学習と比べてモデルのパラメータ数を増やしたときの性能向上の度合いが大きい
- バッチサイズやエポック数を増やすことも最終的な結果の向上につながる。特にエポック数が少ない時はバッチサイズの大きさの差による性能差が顕著に現れる。バッチサイズを増やすこともエポック数を増やすことも、モデルに与える負例の数を増やすことにつながる。
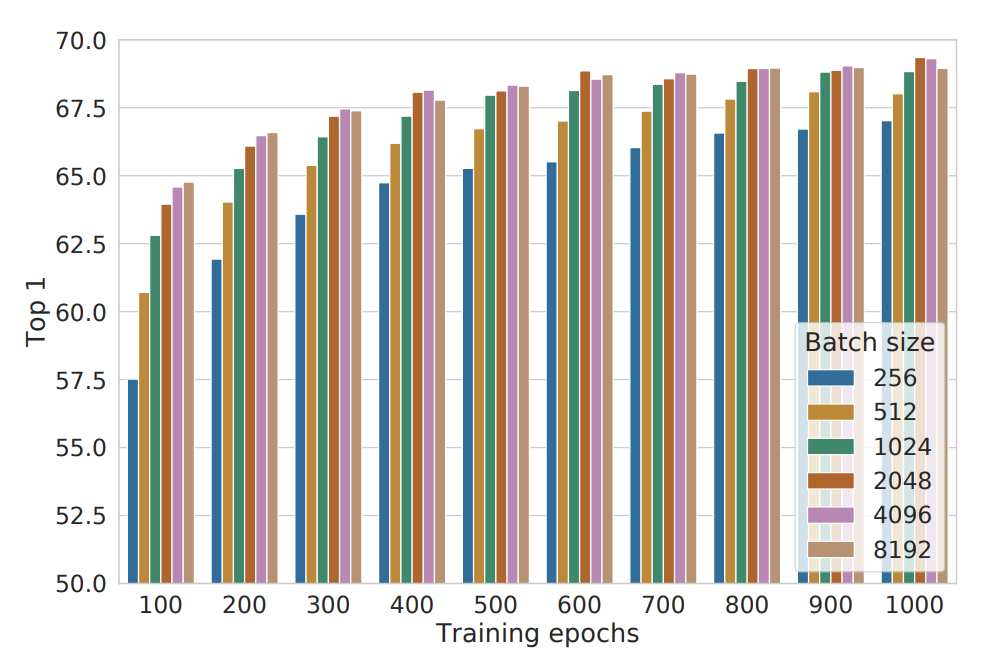
上の図を見ると、確かにエポック数もバッチサイズもlinear evaluationの結果に大きな影響を及ぼしていることがわかります。この結果をみると検証が行われているバッチサイズは最小で256であり、8192まで試していることがわかりますが、このような巨大なバッチサイズによる実験は大きなvRAMを持ったGPUではないと行えないため、学習に大量の計算資源を要すると、後続の研究から批判される結果にもつながりました。
SwAV
| 項目名 | |
|---|---|
| 論文 | Caron, Mathilde, et al. “Unsupervised learning of visual features by contrasting cluster assignments.” Advances in Neural Information Processing Systems 33 (2020): 9912-9924. |
| 発表年 | 2020 |
| 会議 | NeurIPS2020 |
| 研究機関 | Facebook AI Research |
| 著者 | Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand Joulin |
SwAVは既存の手法が大量の画像ペアの比較を行わないと学習が行えない点に問題意識を持ち、似ている特徴を持つ画像をクラスタリングを用いて5グループとして扱って画像ペアの比較を避けることでこの問題を回避した手法です。

SwAVでは、他の手法と同様に一つの画像に2通りのData Augmentationを適用して同じ画像由来の2つの画像を作成します。これらをEncoderに入力して得られたEmbeddingをクラスタリングを用いて、固定された数のグループのいずれかに割り当てます。2枚のクラスタ割り当てを入れ替えて擬似的な目的変数として入れ替えられたクラスタラベルを予測する問題を解くことで、同じ画像由来の画像ペアのクラスタ割り当てが同じになるように学習をしていきます。
より正確に言えば、SwAVではEncoderの出力zとK個のプロトタイプベクトルと呼ばれるベクトル{C1, ..., CK}のマッチングを行うことでコード(q)と呼ばれるEmbeddingを作成します。2つのEncoderそれぞれについてコードを計算し、それらのコードを入れ替えてzを用いてもう一方のEncoderの出力から作成したqを予測するのがSwAVの学習法です。この時プロトタイプベクトルとマッチングを行う部分がクラスタリングを行っている処理に相当します。他のクラスタリングベースの手法では、ネットワークの学習とクラスタリング処理が分けられている一方で、SwAVではネットワークの学習と切り分けずにクラスタリングを行うことからSwAVではこの方法をオンラインクラスタリングと呼んでいます。
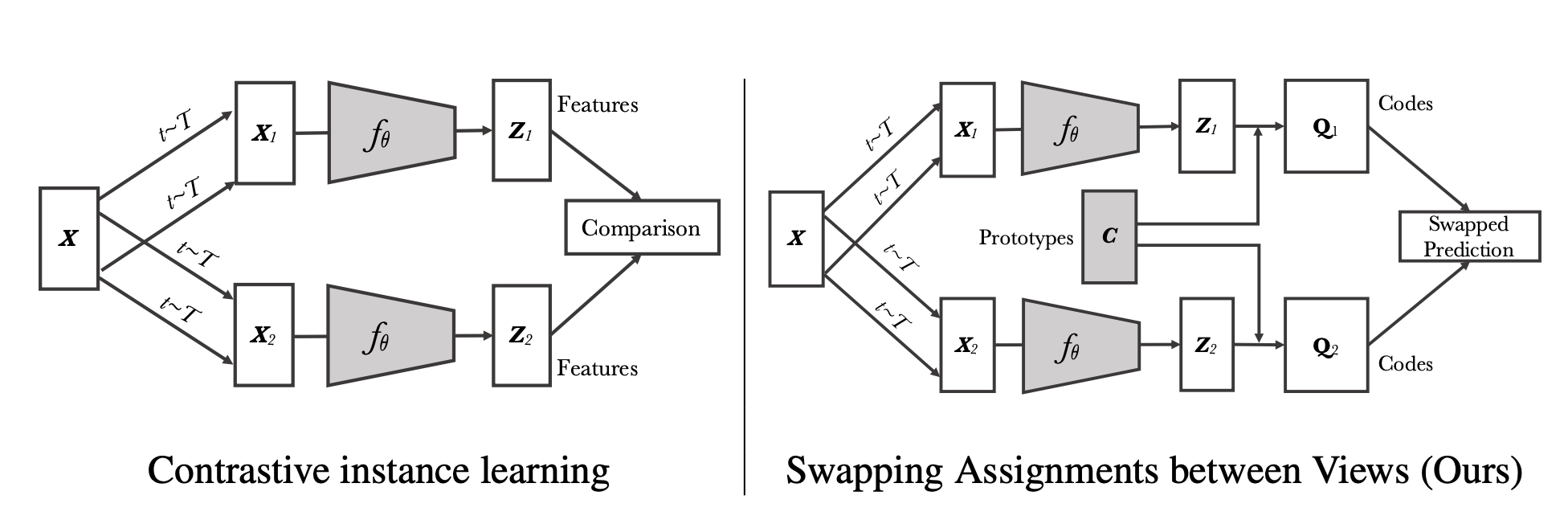
上の図では、一般的な画像ごとの比較を行う対照学習とSwAVの比較をしています。Embeddingを2つのEncoderから得るところまでは共通していますが、SwAVの方では事前に用意されたプロトタイプ(図中のC)と、Embeddingの間のマッチングを取るようになっている部分が特徴的です。なお、色がついている部分は学習できる部分となっているため、プロトタイプベクトルも学習するパラメータの一種です。
さて、オンラインクラスタリングについてですが、次のような最適化問題を考えます。
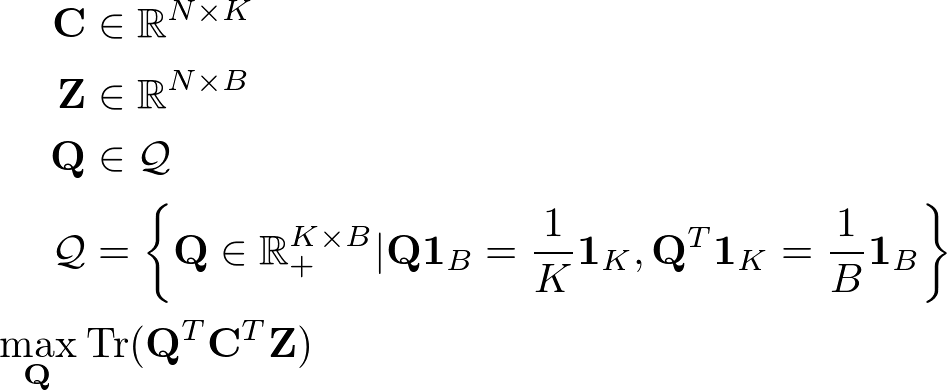
いま、CはN×Kの行列で、N次元のプロトタイプベクトルをK個集めたものになっています。ZはN×Bの行列でN次元のEmbeddingをバッチサイズB分集めたものになっています。Qはコードと呼ばれるK×Bの行列でバッチ内のサンプルそれぞれについての各クラスタへの割り当てを表しています。Qは、正の実数の値を取るようになっているため、概念的には各クラスタへの寄与率のようなものがバッチ内のそれぞれのサンプルに付与されているようなものと考えることができます。
Qには制約条件があり、各行の列方向の和が1/Kになるように、各列の行方向の和が1/Bになるようになっています。これは、各クラスタにバッチ内の各サンプルが等分に割り当てられるような制約条件と考えることができます。この制約がない場合、全てのサンプルが同じクラスタに割り当てられてしまうような解が出てくるようになってしまいます。
さて、上記の最適化問題の目的関数を眺めるとCの転置とZの行列積が行われていることがわかります。これはプロトタイプCとEmbeddingZの間の類似度を計算していることに相当します。その後、その類似度行列とクラスタ割り当てを表すコード行列Qの転置の間で行列積を計算しその跡を計算して、それを最大化するようにQのパラメータを調整していくのがこの最適化問題です。

この目的関数を最大化するような問題を解くとどうなるかを上の図を見ながら考えていきます。いま、最適化問題を解く段階で類似度行列の要素は全て定数だと考えることができます。したがって調整ができる要素はQの各要素です。コード行列と類似度行列の行列積の対角成分の各要素を大きくしようとすると、コード行列上で赤い丸をつけた要素の値を大きくすればいいことがわかります。このようにして、クラスタ割り当てを決める問題を最大化問題と置き換えることができました。
この問題はSinkhorn-Knoppアルゴリズムと呼ばれるアルゴリズムで近似的に高速6に解くことが出来ることが知られて7おり、SwAVでもSinkhorn-Knoppアルゴリズムによってこの最適化問題を解くことで、コードQをバッチ毎に求めています。
バッチごとにコードが得られたあと、SwAVでは2つのEncoderから得られたコードを入れ替え次のような損失関数を最小化するように学習が行われます。
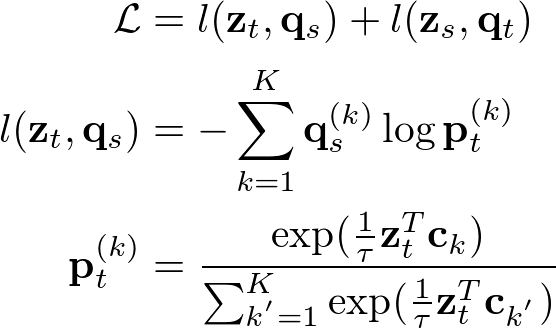
添字tとsは2つあるEncoderのそれぞれを指しています。第二式は、コードqのk番目の要素を正解ラベルとし、pのk番目の要素を予測したラベルとしたときの交差エントロピー誤差になります。そして、pのk番目の要素とはEmbedding zとk番目のプロトタイプ cの類似度を0から1の値になるようにスケーリングしたものとなります。
この損失関数を最小化していくと、同じ画像由来の2つのEmbeddingのクラスタ割り当てが近くなるようになるので、画像の類似性を表現したEmbeddingが得られるようになります。
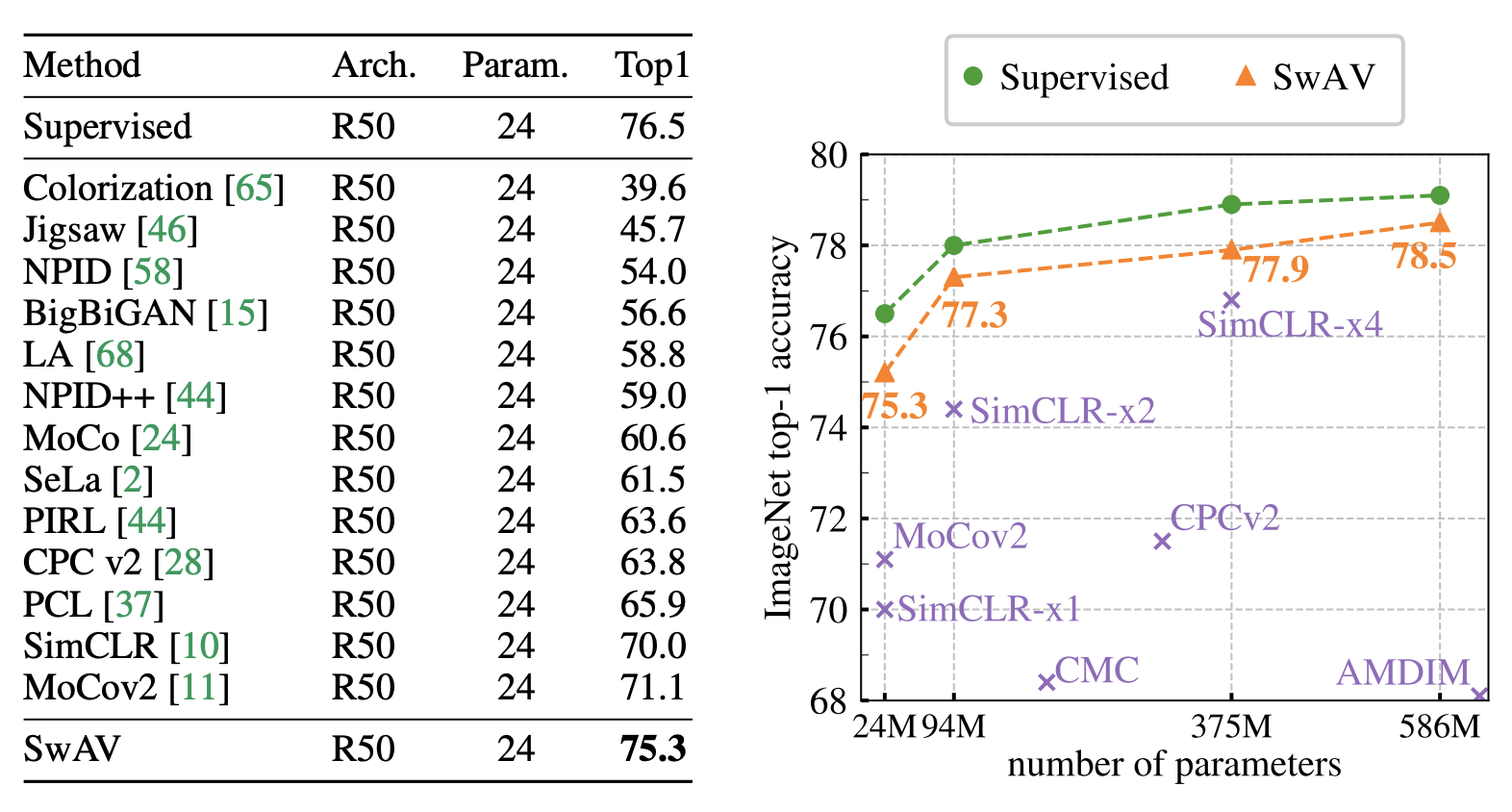
SwAVはMoCo、SimCLRなどと比べても学習によって得られたEmbeddingの性能が高いことが報告されています。下の図表は、Linear EvaluationによりSwAVと他の手法の比較を行ったものですが、SwAVはEmbeddingの学習に教師ラベルを用いずに教師あり学習のTop1 Accuracyに近い性能を発揮できていることがわかります。
SwAVではその他にも半教師あり学習や物体検出などにおいても良い結果が得られたことが報告されています。また、SimCLRなどと比べてもバッチサイズを小さくできることが挙げられています。
ただし、SwAVではバッチサイズを小さくしすぎてプロトタイプの数よりバッチ内のサンプルの数が少なくなってしまうと、バッチ内の各サンプルを各クラスタに均等に割り当てるという制約が満たせなくなってしまうという問題が起きます。これを回避するために、SwAVでは小さいバッチサイズで学習を行う場合はMoCoのように過去のバッチから得られた特徴を保存しておき、クラスタ割り当てを決める際にはそれらの過去のバッチの特徴を利用しています。
BYOL
| 項目名 | |
|---|---|
| 論文 | Chen, Xinlei, and Kaiming He. “Exploring simple siamese representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. |
| 発表年 | 2020 |
| 会議 | NeurIPS2020 |
| 研究機関 | DeepMind, Imperial College |
| 著者 | Xinlei Chen, Kaiming He |
BYOLは、それまでの他の手法が崩壊を防ぐために大量の負例を用いなければならないことを指摘して、負例を使用しない方法で崩壊を防ぐことが実験的にできることを示した手法です。
BYOLも他の手法と同じく2つのEncoderを用いますが、それぞれをOnlineネットワーク、Targetネットワークと読んでおり、Targetネットワークの方はOnlineネットワークの方の重みの指数移動平均をとったMomentum Encoderになっています。
BYOLがその他の手法と異なっている点として、prediction headと呼ばれる全結合層がOnlineネットワークの出力層として足されており、非対称なアーキテクチャになっていることが挙げられます。このprediction headの存在が崩壊の防止に寄与しているのではないか、という仮説がBYOLの論文中では紹介されています。実際、このprediction headを外した場合は崩壊が起きてしまうことが報告されています。
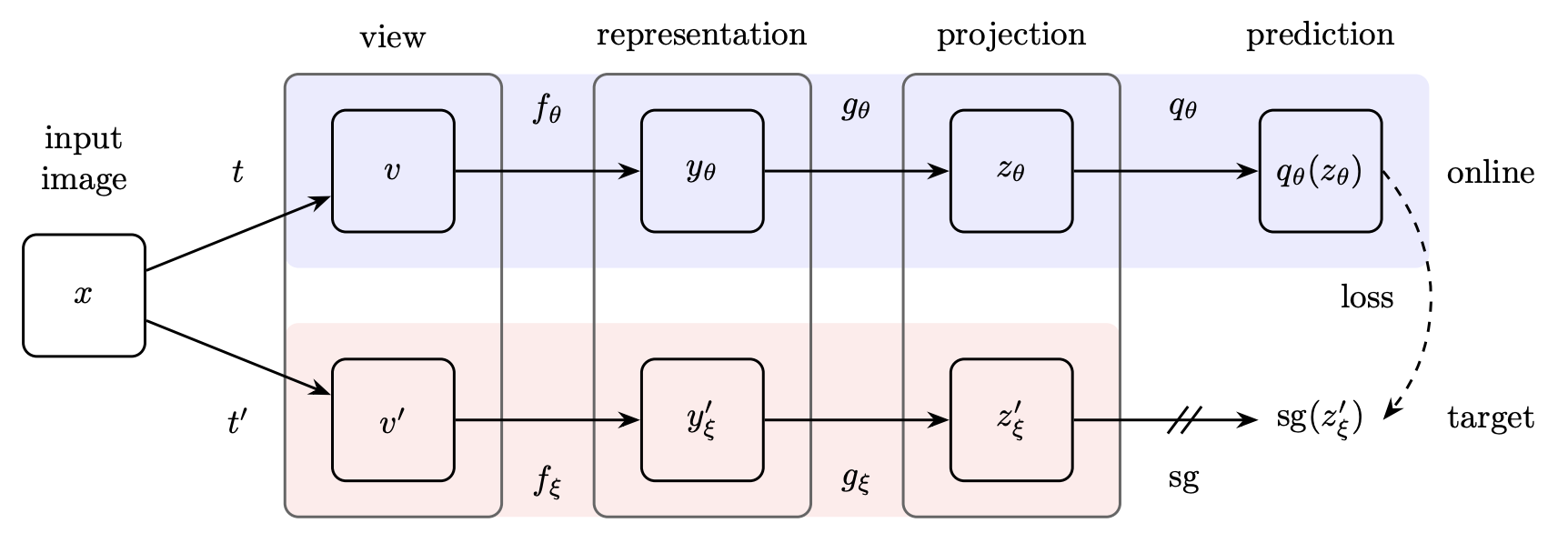
BYOLの学習プロセスはMomentum Encoderを用いていることを除いては他の手法とほとんど変わらないですが、このMomentum Encoderの利用こそが重要であると述べられています。OnlineネットワークにMomentum Encoderの出力を予測させるように学習をすることで、OnlineネットワークがよりよいEmbeddingを出力できるようになる、というのがBYOLのアイデアの核となる部分です。
Onlineネットワークを学習し、そのネットワークの重みをTargetネットワークに反映することを繰り返すことで性能が向上していくことを指して、“Bootstrapping”8と呼んでいるわけです。
BYOLは負例を用いない手法のため、対照学習においてよく用いられるInfoNCEやそれと類似した損失関数は用いません。その代わりに、Onlineネットワークの出力(上の図のqθ(zθ))とTargetネットワークの出力(上の図のz'ξ)をそれぞれ標準化した上でそれらの間の平均二乗誤差を損失関数として用いています。
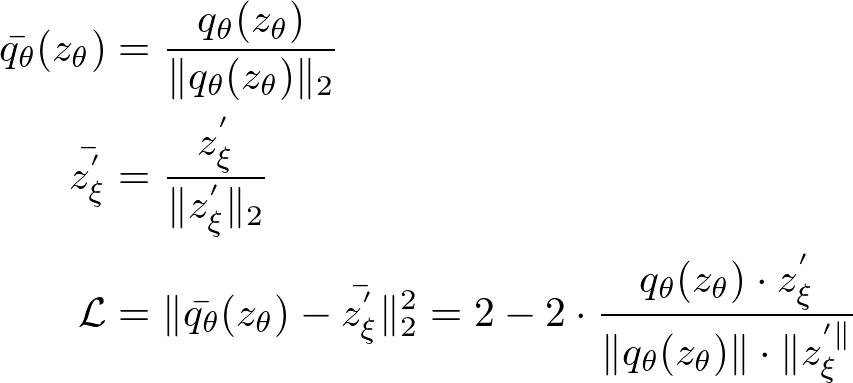
BYOLはLinear Evaluationや半教師あり画像分類などの設定でMoCoやSimCLRよりも高い正解率を出したほか、物体検出・領域分割などの他の画像に関するタスクにおいてもMoCoやSimCLRを上回る性能が発揮されたことが報告されています。
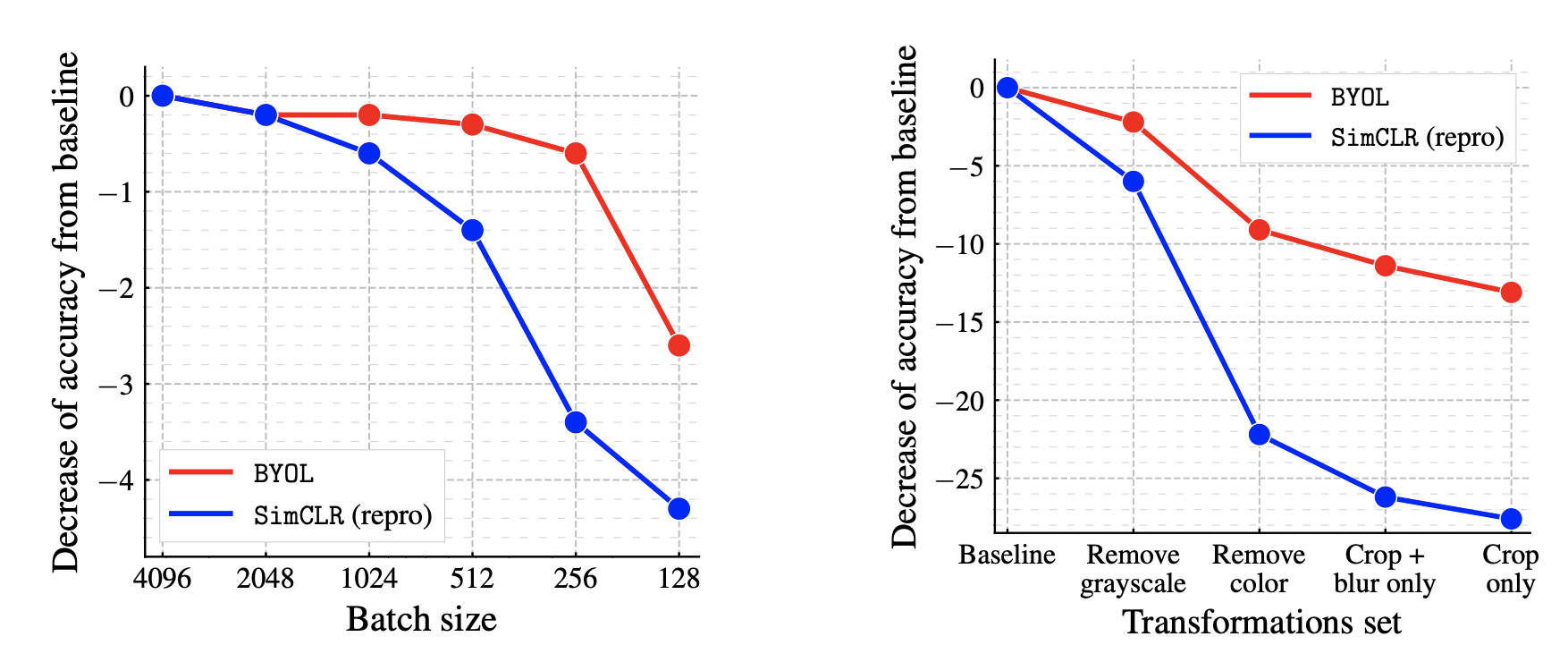
また、BYOLはSimCLRに対する優位点としてバッチサイズや画像に対するData Augmentationの選択に対して、ロバストな結果が得られることを報告しています。
下の図は、バッチサイズを変更したときのベースラインからの性能劣化の具合をSimCLRとBYOLで比較したものですが、確かにBYOLの方が性能劣化の度合いが低くロバストになっていることがわかります。特に、Data Augmentationの組み合わせを変えた場合の性能劣化はSimCLRと比べても遥かに小さく、BYOLの利便性を示した結果となっています。
SimSiam
| 項目名 | |
|---|---|
| 論文 | Chen, Xinlei, and Kaiming He. “Exploring simple siamese representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. |
| 発表年 | 2021 |
| 会議 | CVPR2021 |
| 研究機関 | Facebook AI Research |
| 著者 | Xinlei Chen, Kaiming He |
SimSiamはそれまでの代表的手法それぞれについて簡潔にまとめた上で、崩壊という現象に注目し、それまでの手法が崩壊を防ぐために加えてきた工夫を用いなくても、Asymmetric StructureとStop Gradientという2つの工夫さえあれば、それまでの手法に比肩する性能が出せることを主張した論文です。
SimSiamの面白いところは、“SimCLR without negatives” (負例を使わないSimCLR)、“SwAV without online clustering” (オンラインクラスタリングをしないSwAV)、“BYOL without the momentum encoder” (Momentume Encoderを使わないBYOL)のようにそれまでの各手法の核心に近い部分をあえて抜いているところです。
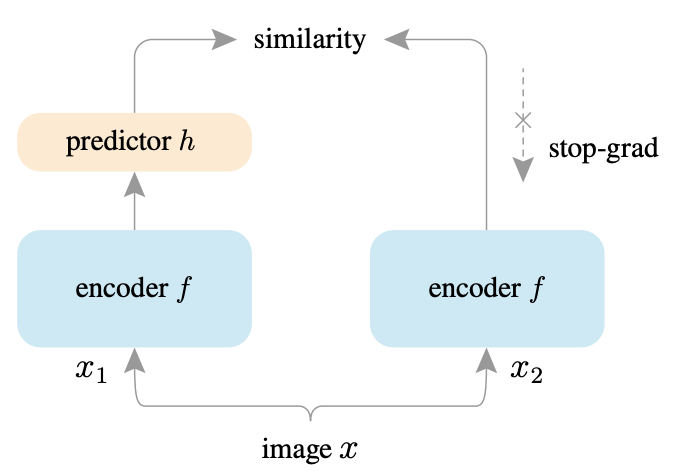
SimSiamの提案するアーキテクチャや学習方法はBYOLと類似しており、大きな差は
- SimSiamではMomentum Encoderを用いていない
- SimSiamではBYOLとは異なる損失関数を用いている
の二点のみです。上図のpredictorの出力をp、encoderの出力をzとしたとき、SimSiamの損失関数は以下のようになります。
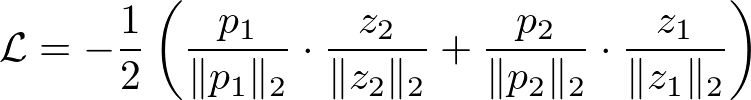
これはp1とz2の間のCosine類似度とp2とz1の間のCosine類似度を高めることに相当するため、同じ画像由来の2つの画像についてEmbeddingが近くなるように学習させることを意味します。一点重要なのが、損失関数の計算時にz1、z2の方については勾配を伝えないような操作(Stop-gradient)を行うことです。
これは損失の計算時にはz1とz2は定数として扱われることを意味しています。このStop Gradientの効果は絶大で、Stop Gradientがある場合とない場合で比較をすると、Stop Gradientを用いない場合、すぐに崩壊が起きてしまい、後流のLinear Evaluationタスクの性能が全く上がらないという結果になってしまうことが報告されています。
下の図はStop Gradientがある場合とない場合を比較したものですが、Stop Gradientがない場合はtraining lossがすぐに-1(最小値)まで落ちる一方で、出力の標準偏差がほぼ0に近い値をとっている(=常に同じ出力が出るようになっている)ことや、EmbeddingをkNNで分類したり、Linear Evaluationを行った結果がほぼ0に近いことがわかります。

また、著者らはpredictorを加えて非対称な構造にすることの効果についても検証を行っています。下の図は、predictorを加えた場合、predictorを乱数で初期化したまま固定した場合、学習を行った場合(学習率の調整の有る無しで2パターン)で比較をしたものですが、predictorがない場合はほとんどLinear Evaluationの結果が0に近く学習がうまくいっていないことがわかります。

SimSiamの強みの一つはBYOLと同じくバッチサイズを大きくしなくても学習ができる、というものです。既に紹介したようにSimCLRやMoCoなど負例との比較を行いながら学習を行うことで崩壊を防ぎます。負例との比較は負例の数が多い方がよいのですが、全ての負例との比較を行うのは不可能なため、SimCLRなどはバッチを大きく取り、バッチ内の他のサンプルを負例として扱うということは既に紹介した通りです。
しかし、これによりSimCLRなどで良い性能を出すためには非常に大きなバッチサイズで学習を回す必要があり計算資源を多く必要とするという問題が生じました。SimSiamはこの点を克服し、小さなバッチサイズでも良い性能を得ることができることを示しています。
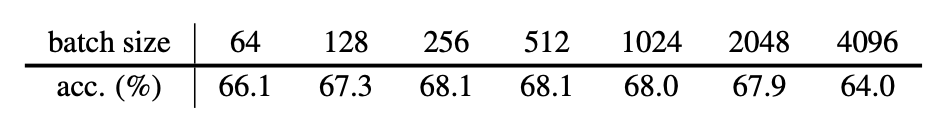
上の表はバッチサイズを変更しながらSimSiamの学習を100エポック分行い、得られたEmbeddingをLinear Evaluationで評価したものですが、SimCLRと比べてもバッチサイズを大きくすることによる性能向上の幅が小さく、小さいバッチサイズでも良い結果が得られることを示しています。
DINO
| 項目名 | |
|---|---|
| 論文 | Caron, Mathilde, et al. “Emerging properties in self-supervised vision transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021. |
| 発表年 | 2021 |
| 会議 | ICCV2021 |
| 研究機関 | Facebook AI Research, Inria, Sorbonne University |
| 著者 | Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jegou, Julien Mairal, Piotr Bojanowski, Armand Joulin |
近年のComputer Visionの発展において特筆すべきこととしてVision Transformer9の隆盛が挙げられるでしょう。Computer VisionにおいてもTransformerが有用であったという発見は多くの研究者を魅了し、Vision Transformerは現在も精力的に研究が進められている分野の一つとなっています。
DINOはVision Transformerに対する利用を念頭に提案された手法です。DINOはBYOLに類似した手法ですが、BYOLにおいて重要とされていたpredictorが用いられておらず、その代わり崩壊を防ぐためにcenteringとsharpeningと呼ばれる工夫が施されています。

DINOの学習プロセスはこれまでに紹介した自己教師あり学習手法と類似していると同時に、蒸留と呼ばれる技術とも似ていると論文中では述べられています。蒸留は元々は、モデルの予測性能を維持したままモデルのサイズを圧縮する方法として提案されたものですが、最近はその他にもラベルありデータに加えて大量のラベルなしデータを用いることで、モデルの予測性能を向上させるような目的にも用いることができることがわかっています10。
DINOではこの蒸留という技術に着想を得て11学習を行います。蒸留では元のネットワーク(Teacher Network)と、学習を行っていくネットワーク(Student Network)が登場し、Teacher Networkの出力をStudent Networkのラベルとして学習を行います。DINOでは、2つのEncoderがそれぞれTeacher NetworkとStudent Networkになっています。
通常の蒸留ではTeacher Network側は学習済みのモデルのため重みの更新が行われることはありませんが、DINOではTeacher Networkに相当するネットワークはMomentum Encoderを用いたものになっています。
また、先述したとおりDINOでは、centeringとsharpeningというEncoderの出力に施されています。Student Networkでは、sharpeningのみが適用されTeacher Networkでは両方が用いられています。それぞれの処理がどのようなものかを見てみようと思います。
まずsharpeningですが、これはsoftmax関数に温度パラメータというものを導入したものになっています。具体的には、Student NetworkをgθsとしたときにStudent Networkの出力Ps(x)のi次元の要素は次のようになります。
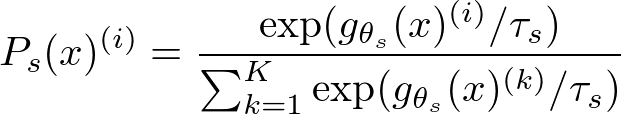
この処理を加えると、モデルの出力はどれかの次元に偏ることになります。ここで負例を使わないで学習をしているときに崩壊がどのようにして起きるのかについて考えてみると、
- どのような入力であっても出力されるEmbeddingが一様である
- Embeddingのなかで常に一つの次元だけが高い値を取り続ける
という場合があります。sharpeningを加えると、前者の崩壊の仕方を防ぐことができます。
一方centeringはモデルの出力の各次元に同じバイアス項を足す処理であり、sharpeningとは逆の効果を持つ処理になります。これは逆に、後者の崩壊の仕方を防ぐことができます。 Teacher Networkに対してcenteringとsharpeningを併用することで、両方の崩壊のモードの発生を防ぎつつTeacher Networkの出力の安定性をあげることができると論文中では述べられています。
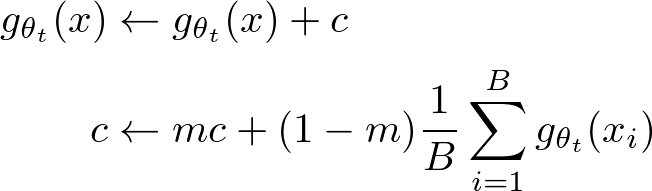
centeringで足されるバイアス項はEmbeddingのバッチ内平均の指数移動平均となっています。
DINOはそれまでの手法と比べてもLinear Evaluationなどで高い性能を誇っているだけではなく、Vision Transformerと組み合わせて用いた場合に興味深い結果が得られることも報告されています。
まず、DINOを用いて学習されたVision TransformerのSelf Attentionは教師ラベルを用いずに学習がなされているにもかかわらず、画像中の物体に関して領域分割することができます。

下の図は教師ありで学習したVision TransformerのSelf Attentionによる領域分割とDINOによる領域分割を比べたものですが、教師ありのものに比べてDINOの方がはっきりと物体を分割していることがわかります。

また、DINOによって学習されたEmbeddingは特に教師情報を与えていなくてもクラスタを形成するため、kNNなど単純な手法でも高い分類性能を発揮するほか、画像検索(Image Retrieval)やコピー検出などのタスクにも用いることができると述べられています。

おわりに
今回は、画像に対する自己教師あり学習の代表的な手法の紹介を行いました。画像に対する自己教師あり学習の手法は近年急激に発展している分野のため2021年初に出た論文がSoTAを主張した数ヶ月後にその手法を超える新手法が提案される、といったような状況になっておりここで紹介した手法もすぐに過去のものになってしまうかもしれません。
画像に対する自己教師あり学習は、大量のラベルを必要とするという、深層学習の弱点を克服できる可能性のある有望な技術ですので今後も引き続き注視していきたいと思います。
We are Hiring!!
弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。
===========================
===========================
-
2022年1月現在だとMeta AI Researchに改名されています ↩︎
-
https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html ↩︎
-
Chen, Xinlei, et al. “Improved baselines with momentum contrastive learning.” arXiv preprint arXiv:2003.04297 (2020). ↩︎
-
同様に画像ペアごとの比較による学習(instance-wise comparison)を避けクラスタリングを用いている先行手法としてPCL(Li, Junnan, et al. “Prototypical contrastive learning of unsupervised representations.” arXiv preprint arXiv:2005.04966 (2020).)が挙げられますが、PCLの課題意識はやや異なり、「画像ごとの比較による手法は画像全体のセマンティクスを使った学習を行いづらい」「画像ごとの比較は意味的に本来似ているようなペアも負例として扱ってしまう」という問題を挙げています。PCLにはEnd-to-endな学習ができず時間がかかるという難点があり、SwAVでもその点が問題として指摘されています。 ↩︎
-
そもそも高速である上にGPUを使って計算の高速化を行えるというのが魅力的です。 ↩︎
-
Cuturi, Marco. “Sinkhorn distances: Lightspeed computation of optimal transport.” Advances in neural information processing systems 26 (2013). ↩︎
-
BYOLは"Bootstrap Your Own Latent"の頭文字を取った名前となっています。Bootstrappingは様々な分野で用いられる多義語ですが、一般的には「外部からの入力を必要とせずに継続し発展するプロセス」のことを指します。https://en.wikipedia.org/wiki/Bootstrapping ↩︎
-
Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020). ↩︎
-
Xie, Qizhe, et al. “Self-training with noisy student improves imagenet classification.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020. ↩︎
-
DINOという名称は"self DIstilation with NO labels"、すなわち「ラベルを用いない自己蒸留」という意味の一文から取られています。自己蒸留とはStudent NetworkとTeacher Networkに同じアーキテクチャが用いられている場合を指します。 ↩︎

旅行・飲食・SaaSデータの分析・モデリングなど
Hidehisa Arai
新卒でリクルート入社。Kaggle Grandmaster。
この記事をシェア
<一緒に働きませんか?>
ここまで読んでくださりありがとうございます。
データ推進室で一緒に働いてくださる方を募集中ですので、ご興味がある方は以下をご覧ください。
▼キャリア採用にご興味がある方向け
- データ推進室 | 株式会社リクルート キャリア採用特設ページ
- カジュアル面談をご希望の方はこちら
- イベント等情報配信をご希望の方(メルマガ登録)はこちら


